
Memcached分散式佈置方案--一致性Hash分佈機制及其改進
一致性Hash分佈簡介
在伺服器數量不發生改變時,普通的Hash分佈可以很好地運作。當伺服器的數量發生改變時,問題就出來了,試想,增加一臺伺服器時,同一個key經過Hash之後,與伺服器取模的結果跟沒增加伺服器之前的結果會不一樣,這就導致之前儲存的資料丟失。為了把丟失的資料減少到最少,可以採用一致性hash演算法。
一致性hash演算法分為6個步驟:
步驟1:
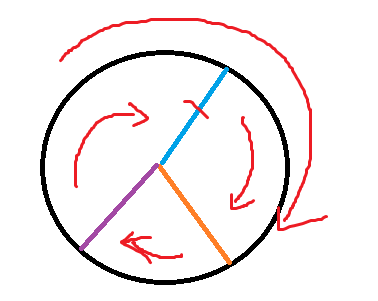
將一個32位整數0~2^32 -1想象成一個環,將0作為圓環的頭,2^32 -1作為圓環的尾,把它連線起來。當然這只是想象。

步驟2:
通過Hash函式把key處理成整數。
function mHash($key){
$md5 $key1 = mHash("key1");
$key2 = mHash("key2");
$key3 = mHash("key3");
$key4 = mHash("key4");把key處理成整數後,就可以在環中找到一個位置與之對應,如下圖
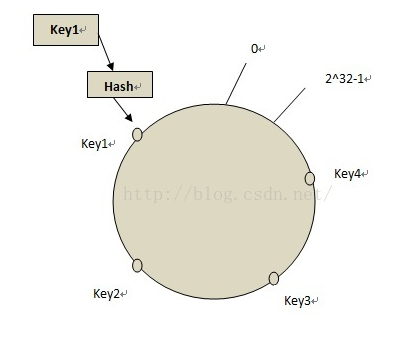
步驟3:
把memcached群對映到環上,使用Hash函式處理伺服器所使用的IP地址。
假如有3臺伺服器,分別使用IP(127.0.0.1),IP(127.0.0.2),IP(127.0.0.3),使用下面的方法對映到環上。
$server1 = mHash("127.0.0.1");
$server2 = mHash("127.0.0.2");
$server3 = mHash("127.0.0.3");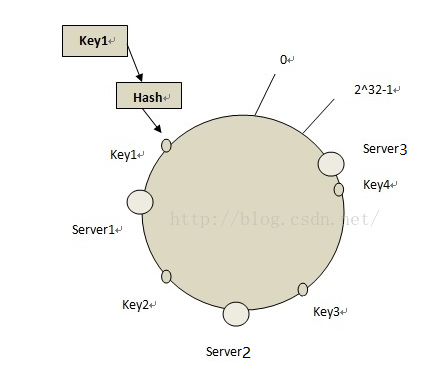
步驟4:把資料對映 到伺服器上
沿著環順時針方向的key出發,知道遇到下一個伺服器為止,把key對應的資料儲存到這個伺服器上。根據上面的方法,key4和key3儲存到server2上,key2儲存到server1上,key1儲存到server3上。
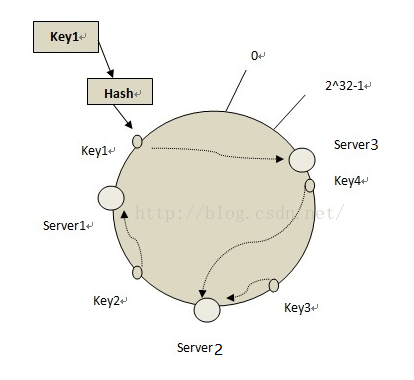
步驟5:移除伺服器
考慮一下,如果server2伺服器崩潰了,那麼受最大影響的僅是沿著server2逆時針出發直到下一個伺服器之間的資料,也就是對映到server2上的那些資料。然後依照規則,將server2伺服器上的資料移植下一個伺服器上即可。
在上例中,需要進行變動的有key3和key4對應的資料,把這些資料重新對映到server1上即可。
步驟6:新增伺服器。
再考慮一下,如果要新增一個伺服器server4,用之前的方法把它對映到key3和key4之間,這時受到的影響是沿著server4逆時針出發直至遇到下一個伺服器之間的資料,把這些資料重新對映到server4上即可。
在這裡僅需要變動的只有key4對應的資料,將其重新對映到server4上即可。
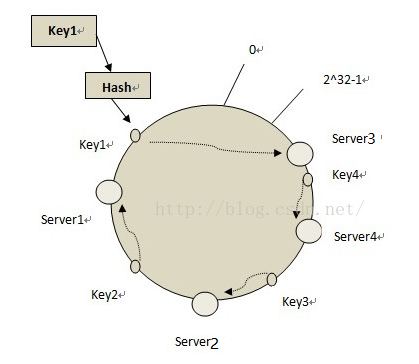
使用PHP實現一致性Hash分佈演算法的程式碼如下:(注:個人理解所編寫,並不權威)
<?php
class FlexiHash
{
private $serverList = array();//儲存伺服器列表
private $isSorted = FALSE;//記錄伺服器列表是否已經排過序
/*新增伺服器*/
function addServer($server){
$hash = $this->mHash($server);
if(!isset($this->serverList[$hash])){
$this->serverList[$hash] = $server;
}
$this->isSorted = FALSE;
return TRUE;
}
/*移除伺服器*/
function removeServer($server){
$hash = $this->mHash($server);
if(isset($this->serverList[$hash])){
unset($this->serverList[$hash]);//unset只是銷燬了某個變數,並不會重建陣列索引
}
$this->isSorted = FALSE;
return TRUE;
}
/*根據值查詢所在伺服器*/
function lookup($key){
$hash = $this->mHash($key);
/*將陣列按鍵由小到大排序*/
if(!$this->isSorted) {
ksort($this->serverList);
$this->isSorted = TRUE;
}
/*由於陣列是按鍵由小到大排列的,如果$hash小於等於陣列的鍵,則返回該鍵的value,即伺服器IP*/
foreach($this->serverList as $pos => $server) {
if($hash <= $pos) {
return $server;
}
}
/*如果上述遍歷沒有找到合適的值,則返回第一個*/
return $this->serverList[current(array_keys($this->serverList))];
}
/*hash函式*/
function mHash($key){
$md5 = substr(md5($key),0,8);
$seed = 31;
$hash = 0;
for($i = 0; $i < 8; $i++){
$hash = $hash*$seed + ord($md5{$i});
$i++;
}
return $hash & 0x7FFFFFFF;
}
}
?>測試程式碼:
<?php
$hserver = new FlexiHash();
$hserver -> addServer("127.0.0.1");
$hserver -> addServer("127.0.0.2");
$hserver -> addServer("127.0.0.3");
$hserver -> addServer("127.0.0.4");
$hserver -> addServer("127.0.0.5");
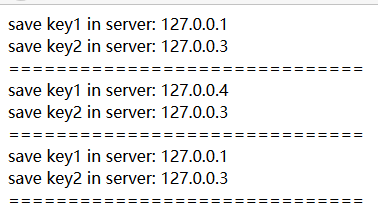
echo "save key1 in server: " . $hserver->lookup("key1")."<br>";
echo "save key2 in server: " . $hserver->lookup("key2")."<br>";
echo "=============================="."<br>";
$hserver->removeServer("127.0.0.1");
echo "save key1 in server: " . $hserver->lookup("key1")."<br>";
echo "save key2 in server: " . $hserver->lookup("key2")."<br>";
echo "=============================="."<br>";
$hserver->addServer("127.0.0.1");
echo "save key1 in server: " . $hserver->lookup("key1")."<br>";
echo "save key2 in server: " . $hserver->lookup("key2")."<br>";
echo "=============================="."<br>";
?>執行結果如下:
注:關於雜湊演算法,讀者可以自己編寫自己的,也可以運用PHP自帶函式或方法。
例如:一個比較簡單的
echo sprintf('%u',crc32("test"));一致性hash分佈優化
上述方法的缺點如下:
- 伺服器算出的mhash(),並不均勻,就會出現,資料分配不均的現象。
- 移除一個伺服器後,會將此伺服器的資料,全部轉移至下一個伺服器,並不能將其分擔給其餘伺服器。
解決方法:
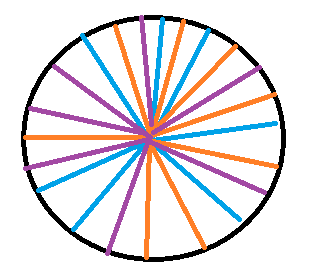
建立若干的虛擬節點,這樣,done掉一臺伺服器的話,資料會近似均勻的分給其他幾臺伺服器。
實現方式:
<?php
class FlexiHash
{
private $serverList = array();//儲存伺服器虛擬節點
private $isSorted = FALSE;//記錄伺服器列表是否已經排過序
protected $_mul = 64;//每臺伺服器分成64個虛節點
/*新增伺服器*/
function addServer($server){
for($i=0; $i<$this->_mul; $i++) {
$node = $server.'-'.$i;//給虛節點起名字
if(!isset($this->serverList[$this->mHash($node)])){
$this->serverList[$this->mHash($node)] = $server;
}
}
$this->isSorted = FALSE;
return TRUE;
}
/*移除伺服器的所有虛擬節點*/
function removeServer($server){
foreach($this->serverList as $key=>$value) {
if($this->serverList[$key] == $server){
unset($this->serverList[$key]);
}
}
$this->isSorted = FALSE;
return TRUE;
}
/*根據值查詢所在伺服器*/
function lookup($key){
$hash = $this->mHash($key);
/*將陣列按鍵由小到大排序*/
if(!$this->isSorted) {
ksort($this->serverList);
$this->isSorted = TRUE;
}
/*由於陣列是按鍵由小到大排列的,如果$hash小於等於陣列的鍵,則返回該鍵的value,即伺服器IP*/
foreach($this->serverList as $pos => $server) {
if($hash <= $pos) {
return $server;
}
}
/*如果上述遍歷沒有找到合適的值,則返回第一個*/
return $this->serverList[current(array_keys($this->serverList))];
}
/*hash函式*/
function mHash($key){
$md5 = substr(md5($key),0,8);
$seed = 31;
$hash = 0;
for($i = 0; $i < 8; $i++){
$hash = $hash*$seed + ord($md5{$i});
$i++;
}
return $hash & 0x7FFFFFFF;
}
function getAllServers(){
return $this->serverList;
}
}
?>測試:
<?php
$hserver = new FlexiHash();
$hserver -> addServer("127.0.0.1");
$hserver -> addServer("127.0.0.2");
$hserver -> addServer("127.0.0.3");
$hserver -> addServer("127.0.0.4");
$hserver -> addServer("127.0.0.5");
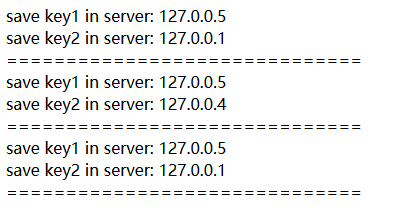
echo "save key1 in server: " . $hserver->lookup("key1")."<br>";
echo "save key2 in server: " . $hserver->lookup("key2")."<br>";
echo "=============================="."<br>";
$hserver->removeServer("127.0.0.1");
echo "save key1 in server: " . $hserver->lookup("key1")."<br>";
echo "save key2 in server: " . $hserver->lookup("key2")."<br>";
echo "=============================="."<br>";
$hserver->addServer("127.0.0.1");
echo "save key1 in server: " . $hserver->lookup("key1")."<br>";
echo "save key2 in server: " . $hserver->lookup("key2")."<br>";
echo "=============================="."<br>";
//var_dump($hserver->getAllServers());
?>執行結果:
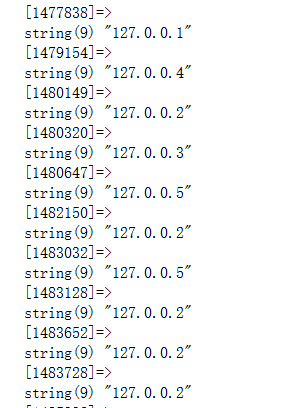
再看伺服器的分佈情況:
相關推薦
Memcached分散式佈置方案--一致性Hash分佈機制及其改進
一致性Hash分佈簡介 在伺服器數量不發生改變時,普通的Hash分佈可以很好地運作。當伺服器的數量發生改變時,問題就出來了,試想,增加一臺伺服器時,同一個key經過Hash之後,與伺服器取模的結果跟沒增加伺服器之前的結果會不一樣,這就導致之前儲存的資料丟失。為
redis叢集方案-一致性hash演算法
前奏 叢集的概念早在 Redis 3.0 之前討論了,3.0 才在原始碼中出現。Redis 叢集要考慮的問題: 節點之間怎麼據的同步,如何做到資料一致性。一主一備的模式,可以用 Redis 內部實現的主從備份實現資料同步。但節點不斷增多,存在多個 master 的時候,
Redis分散式部署,一致性hash;分散式與快取佇列
最近研究redis-cluster,正好搭建了一個環境,遇到了很多坑,系統的總結下,等到redis3 release出來後,換掉memCache 叢集. 轉載請註明出處哈:http://hot66hot.iteye.com/admin/blogs/2050676 一:關於redis cluster 1
搞懂分散式技術11:分散式session解決方案與一致性hash
session一致性架構設計實踐 原創: 58沈劍 架構師之路 2017-05-18 一、緣起 什麼是session? 伺服器為每個使用者建立一個會話,儲存使用者的相關資訊,以便多次請求能夠定位到同一個上下文。 Web開發中,web-server可以自動為同
訊息中介軟體(一)分散式系統事務一致性解決方案大對比,誰最好使?(轉)
原文轉載至:https://blog.csdn.net/lovesomnus/article/details/51785108 在分散式系統中,同時滿足“一致性”、“可用性”和“分割槽容錯性”三者是不可能的。分散式系統的事務一致性是一個技術難題,各種解決方案孰優孰劣? 在OLTP系統領域,
分散式演算法(一致性Hash演算法)
一、分散式演算法 在做伺服器負載均衡時候可供選擇的負載均衡的演算法有很多,包括: 輪循演算法(Round Robin)、雜湊演算法(HASH)、最少連線演算法(Least Connection)、響應速度演算法(Response Time)、加權法
python分散式事務方案(二)基於訊息最終一致性
python分散式事務方案(二)基於訊息最終一致性 上一章採用的是tcc方案,但是在進行批量操作時,比如說幾百臺主機一起分配策略時,會執行很長時間,這時體驗比較差。 由於zabbix隱藏域後臺,而這個慢主要是集中在呼叫zabbix介面,這裡我們就基於訊息最終一致性來進行優化 訊息一致性方案是通過
分散式事務最終一致性常用方案
目前的應用系統,不管是企業級應用還是網際網路應用,最終資料的一致性是每個應用系統都要面臨的問題,隨著分散式的逐漸普及,資料一致性更加艱難,但是也很難有銀彈的解決方案,也並不是引入特定的中介軟體或者特定的開源框架能夠解決的,更多的還是看業務場景,根據場景來給出解決方案。根據
阿里P8架構師談:分散式資料庫資料一致性的原理、與技術實現方案!
背景 可用性(Availability)和一致性(Consistency)是分散式系統的基本問題,先有著名的CAP理論定義過分散式環境下二者不可兼得的關係,又有神祕的Paxos協議號稱是史上最簡單的分散式系統一致性演算法並獲得圖靈獎,再有開源產品ZooKeeper實現的Z
分散式系統中的一致性hash初探
在分散式式系統中,為了分散訪問壓力,每個模組需要由多個節點組成叢集,共同來提供服務,客戶端根據一定的負載均衡策略來訪問叢集的各個節點,由此引入了一些問題,如在訪問壓力增大的情況需要要增加節點,或是叢集其中的一個節點突然掛掉,如何將原有節點上的請求壓力重新負載到新的節點叢集上。 我們常用的負載均衡策略
分散式一致性hash演算法
寫在前面 在學習Redis的叢集內容時,看到這麼一句話:Redis並沒有使用一致性hash演算法,而是引入雜湊槽的概念。而分散式快取Memcached則是使用分散式一致性hash演算法來實現分散式儲存。所以就專門學習了一下 什麼是分散式?什麼是一致性?什麼是雜湊? 1
一致性 Hash 演算法(分散式或均衡演算法)
簡介: 一致性雜湊演算法在1997年由麻省理工學院提出的一種分散式雜湊(DHT)實現演算法,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性雜湊修正了CARP使用的簡單雜湊演算法帶來的問題,使得分散式雜湊(DHT)可以在P
一致性 Hash 演算法學習(分散式或均衡演算法)
簡介: 一致性雜湊演算法在1997年由麻省理工學院提出的一種分散式雜湊(DHT)實現演算法,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性雜湊修正了CARP使用的簡單雜湊演算法帶來的問題,使得分散式雜湊(DHT)可以在P2P環境中真
分散式快取--系列1 -- Hash環/一致性Hash原理
當前,Memcached、Redis這類分散式kv快取已經非常普遍。從本篇開始,本系列將分析分散式快取相關的原理、使用策略和最佳實踐。 我們知道Memcached的分散式其實是一種“偽分散式”,也就是它的伺服器結點之間其實是相互無關聯的,之間沒有網路拓撲關係,
redis分散式一致性hash演算法
當我們在部署redis節點時,使用者連結redis儲存資料會通過hash演算法來定位具體連結那個redis節點,在redis節點數量沒有改變的前提下,之前的使用者通過hash演算法會固定的連結某一臺redis節點,但是若此時我們增加了redis節點,使用者再次
redis 一致性hash ,分散式儲存
轉自:http://my.oschina.net/zhenglingfei/blog/405622 今天請教jedis跟shareJedis有啥區別,某神答曰:shareJedis是切片的,將例項作為一致性Hash,分散式儲存,感覺好高大上就在網上找了下,趕腳下面說的很不錯
用sharding技術來擴充套件你的資料庫(hash分佈擴充套件,一致性雜湊)
EMC中國研究院大資料組研究員 郭小燕 摘要: 本部分首先簡單介紹sharding系統的基本架構,然後重點介紹sharding機制中常用的三種表資料劃分方法。 一. 資料劃分演算法 1. Sharding 系統的基本結構 上節我們說到Sharding可以簡單定義為將大資料庫分佈到多個物理節點上的
22、資料分佈演算法:hash+一致性hash+redis cluster的hash slot
1、redis cluster介紹 (1)自動將資料進行分片,每個master上放一部分資料 (2)提供內建的高可用支援,部分master不可用時,還是可以繼續工作的在redis cluster架構下,每個redis要放開兩個埠號,比如一個是6379,另外一個就是加10000的埠號,比如1637
訊息中介軟體(一)分散式系統事務一致性解決方案大對比,誰最好使?
在分散式系統中,同時滿足“一致性”、“可用性”和“分割槽容錯性”三者是不可能的。分散式系統的事務一致性是一個技術難題,各種解決方案孰優孰劣? 在OLTP系統領域,我們在很多業務場景下都會面臨事務一致性方面的需求,例如最經典的Bob給Smith轉賬的案例。傳統的企業開發,
保證分散式系統資料一致性的6種方案
編者按:本文由「高可用架構後花園」群討論整理而成。 有人的地方,就有江湖 有江湖的地方,就有紛爭 問題的起源 在電商等業務中,系統一般由多個獨立的服務組成,如何解決分散式呼叫時候資料的一致性? 具體業務場景如下,比如一個業務操作,如果同時呼叫服務 A、B、C,需要滿足要麼同時成功;要麼同時失敗。A