
分散式快取--系列1 -- Hash環/一致性Hash原理
當前,Memcached、Redis這類分散式kv快取已經非常普遍。從本篇開始,本系列將分析分散式快取相關的原理、使用策略和最佳實踐。
我們知道Memcached的分散式其實是一種“偽分散式”,也就是它的伺服器結點之間其實是相互無關聯的,之間沒有網路拓撲關係,由客戶端來決定一個key是存放到哪臺機器。
具體來講,假設我有多臺memcached伺服器,編號分別為m0,m1,m2,…。對於一個key,由客戶端來決定存放到哪臺機器,那最簡單的hash公式就是 key % N,其中N是機器的總數。
但這有個問題,一旦機器數變少,或者增加機器,N發生變化,那之前存放的資料就全部無效了。因為你按照新的N值取模計算出的機器編號,和當時按舊的N值取模算出的機器編號肯定是不等的,也就意味著絕大部分快取會失效。
這個問題的解決辦法就是用1種特別的Hash函式,儘可能使得,增加機器/減少機器時,快取失效的數目降到最低,這就是Hash環,或者叫一致性Hash。
有興趣朋友可以關注公眾號“架構之道與術”, 獲取最新文章。
或掃描如下二維碼:

Hash環
上面說的Hash函式,只經過了1次hash,即把key hash到對應的機器編號。
而Hash環有2次Hash:
(1)把所有機器編號hash到這個環上
(2)把key也hash到這個環上。然後在這個環上進行匹配,看這個key和哪臺機器匹配。
具體來講,如下:
假定有這樣一個Hash函式,其值空間為(0到2的32次方-1) ,也就是說,其hash值是個32位無整型數字 ,這些數字組成一個環。
然後,先對機器進行hash(比如根據機器的ip),算出每臺機器在這個環上的位置; 再對key進行hash,算出該key在環上的位置,然後從這個位置往前走,遇到的第一臺機器就是該key對應的機器,就把該(key, value) 儲存到該機器上。
如下圖所示:
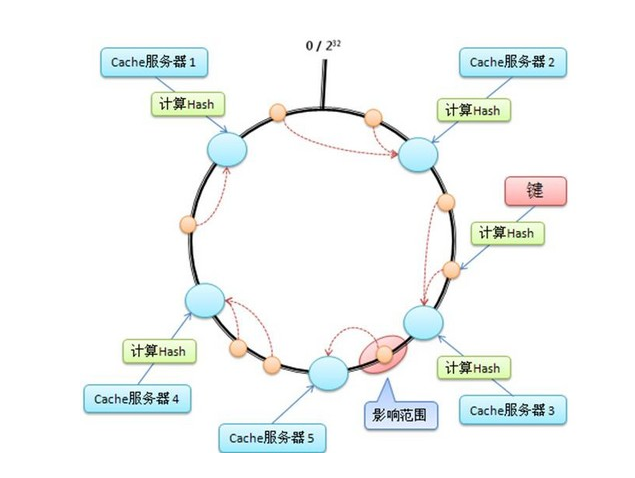
首先計算出每臺Cache伺服器在環上的位置(圖中的大圓圈);然後每來一個(key, value),計算出在環上的位置(圖中的小圓圈),然後順時針走,遇到的第1個機器,就是其要儲存的機器。
這裡的關鍵點是:當你增加/減少機器時,其他機器在環上的位置並不會發生改變。這樣只有增加的那臺機器、或者減少的那臺機器附近的資料會失效,其他機器上的資料都還是有效的。
資料傾斜問題
當你機器不多的時候,很可能出現幾臺機器在環上面貼的很近,不是在環上均勻分佈。這將會導致大部分資料,都會集中在某1臺機器上。
為了解決這個問題,可以引入“虛擬機器器”的概念,也就是說:1臺機器,我在環上面計算出多個位置。怎麼弄呢? 假設用機器的ip來hash,我可以在ip後面加上幾個編號, ip_1, ip_2, ip_3, .. 把1臺物理機器生個多個虛擬機器器的編號。
資料首先對映到“虛擬機器器上”,再從“虛擬機器器”對映到物理機器上。因為虛擬機器器可以很多,在環上面均勻分佈,從而保證資料均勻分佈到物理機器上面。
ZK的引入
上面我們提到了伺服器的機器增加、減少,問題是客戶端怎麼知道呢?
一種笨辦法就是手動的,當伺服器機器增加、減少時候,重新配置客戶端,重啟客戶端。
另外一種,就是引入ZK,伺服器的節點列表註冊到ZK上面,客戶端監聽ZK。發現結點數發生變化,自動更新自己的配置。
當然,不用ZK,用一個其他的中心結點,只要能實現這種更改的通知,也是可以的。