
Kafka跨叢集同步工具——MirrorMaker
MirrorMaker是為解決Kafka跨叢集同步、建立映象叢集而存在的;下圖展示了其工作原理。該工具消費源叢集訊息然後將資料重新推送到目標叢集。
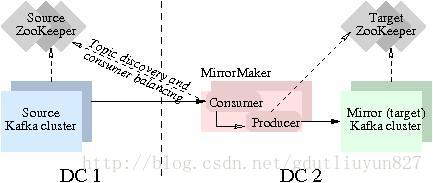
MirrorMaker使用方式
啟動mirror-maker程式需要一個或多個consumer配置檔案、一個producer配置檔案是必須的其他引數是可選的。
kafka-run-class.sh kafka.tools.MirrorMaker –consumer.config sourceCluster1Consumer.config –consumer.config sourceCluster2Consumer.config –num.streams 2 –producer.config targetClusterProducer.config –whitelist=”.*”
主要引數說明:
1. –consumer.config:消費端相關配置檔案
2. –producer.config:生產端相關配置檔案
3. –num.streams: consumer的執行緒數
4. –num.producers: producer的執行緒數
5. –blacklist,–whitelist:同步topic的黑白名單,符合java正則表示式形式
consumer.config配置檔案說明
#消費者叢集通過連線Zookeeper來找到broker。
#zookeeper連線伺服器地址
zookeeper.connect=zk01:2181,zk02:2181 producer.config配置檔案說明
#指定kafka節點列表,用於獲取metadata,不必全部指定
#需要kafka的伺服器地址,來獲取每一個topic的分片數等元資料資訊。
metadata.broker.list=kafka01:9092,kafka02:9092,kafka03:9092
#生產者生產的訊息被髮送到哪個block,需要一個分組策略。
#指定分割槽處理類。預設kafka.producer.DefaultPartitioner,表通過key雜湊到對應分割槽
#partitioner.class=kafka.producer.DefaultPartitioner
#生產者生產的訊息可以通過一定的壓縮策略(或者說壓縮演算法)來壓縮。訊息被壓縮後傳送到broker叢集,
#而broker叢集是不會進行解壓縮的,broker叢集只會把訊息傳送到消費者叢集,然後由消費者來解壓縮。
#是否壓縮,預設0表示不壓縮,1表示用gzip壓縮,2表示用snappy壓縮。
#壓縮後訊息中會有頭來指明訊息壓縮型別,故在消費者端訊息解壓是透明的無需指定。
#文字資料會以1比10或者更高的壓縮比進行壓縮。
compression.codec=none
#指定序列化處理類,訊息在網路上傳輸就需要序列化,它有String、陣列等許多種實現。
serializer.class=kafka.serializer.DefaultEncoder
#如果要壓縮訊息,這裡指定哪些topic要壓縮訊息,預設empty,表示不壓縮。
#如果上面啟用了壓縮,那麼這裡就需要設定
#compressed.topics=
#這是訊息的確認機制,預設值是0。在面試中常被問到。
#producer有個ack引數,有三個值,分別代表:
#(1)不在乎是否寫入成功;
#(2)寫入leader成功;
#(3)寫入leader和所有副本都成功;
#要求非常可靠的話可以犧牲效能設定成最後一種。
#為了保證訊息不丟失,至少要設定為1,也就
#是說至少保證leader將訊息儲存成功。
#設定傳送資料是否需要服務端的反饋,有三個值0,1,-1,分別代表3種狀態:
#0: producer不會等待broker傳送ack。生產者只要把訊息傳送給broker之後,就認為傳送成功了,這是第1種情況;
#1: 當leader接收到訊息之後傳送ack。生產者把訊息傳送到broker之後,並且訊息被寫入到本地檔案,才認為傳送成功,這是第二種情況;#-1: 當所有的follower都同步訊息成功後傳送ack。不僅是主的分割槽將訊息儲存成功了,
#而且其所有的分割槽的副本數也都同步好了,才會被認為發動成功,這是第3種情況。
request.required.acks=0
#broker必須在該時間範圍之內給出反饋,否則失敗。
#在向producer傳送ack之前,broker允許等待的最大時間 ,如果超時,
#broker將會向producer傳送一個error ACK.意味著上一次訊息因為某種原因
#未能成功(比如follower未能同步成功)
request.timeout.ms=10000
#生產者將訊息傳送到broker,有兩種方式,一種是同步,表示生產者傳送一條,broker就接收一條;
#還有一種是非同步,表示生產者積累到一批的訊息,裝到一個池子裡面快取起來,再發送給broker,
#這個池子不會無限快取訊息,在下面,它分別有一個時間限制(時間閾值)和一個數量限制(數量閾值)的引數供我們來設定。
#一般我們會選擇非同步。
#同步還是非同步傳送訊息,預設“sync”表同步,"async"表非同步。非同步可以提高發送吞吐量,
#也意味著訊息將會在本地buffer中,並適時批量傳送,但是也可能導致丟失未傳送過去的訊息
producer.type=sync
#在async模式下,當message被快取的時間超過此值後,將會批量傳送給broker,
#預設為5000ms
#此值和batch.num.messages協同工作.
queue.buffering.max.ms = 5000
#非同步情況下,快取中允許存放訊息數量的大小。
#在async模式下,producer端允許buffer的最大訊息量
#無論如何,producer都無法儘快的將訊息傳送給broker,從而導致訊息在producer端大量沉積
#此時,如果訊息的條數達到閥值,將會導致producer端阻塞或者訊息被拋棄,預設為10000條訊息。
queue.buffering.max.messages=20000
#如果是非同步,指定每次批量傳送資料量,預設為200
batch.num.messages=500
#在生產端的緩衝池中,訊息傳送出去之後,在沒有收到確認之前,該緩衝池中的訊息是不能被刪除的,
#但是生產者一直在生產訊息,這個時候緩衝池可能會被撐爆,所以這就需要有一個處理的策略。
#有兩種處理方式,一種是讓生產者先別生產那麼快,阻塞一下,等會再生產;另一種是將緩衝池中的訊息清空。
#當訊息在producer端沉積的條數達到"queue.buffering.max.meesages"後阻塞一定時間後,
#佇列仍然沒有enqueue(producer仍然沒有傳送出任何訊息)
#此時producer可以繼續阻塞或者將訊息拋棄,此timeout值用於控制"阻塞"的時間
#-1: 不限制阻塞超時時間,讓produce一直阻塞,這個時候訊息就不會被拋棄
#0: 立即清空佇列,訊息被拋棄
queue.enqueue.timeout.ms=-1
#當producer接收到error ACK,或者沒有接收到ACK時,允許訊息重發的次數
#因為broker並沒有完整的機制來避免訊息重複,所以當網路異常時(比如ACK丟失)
#有可能導致broker接收到重複的訊息,預設值為3.
message.send.max.retries=3
#producer重新整理topic metada的時間間隔,producer需要知道partition leader
#的位置,以及當前topic的情況
#因此producer需要一個機制來獲取最新的metadata,當producer遇到特定錯誤時,
#將會立即重新整理
#(比如topic失效,partition丟失,leader失效等),此外也可以通過此引數來配置
#額外的重新整理機制,預設值600000
topic.metadata.refresh.interval.ms=60000其他重要說明
同步資料如何做到不丟失
- 首先發送到目標叢集時需要確認:request.required.acks=1
- 傳送時採用阻塞模式,否則緩衝區滿了資料丟棄:queue.enqueue.timeout.ms=-1
- 傳送失敗後重試次數設定無限大:message.send.max.retries=1000000000
如何同步到多個目標叢集
consumer.config配置檔案中group.id設定為不同就可以同步到多個地方,原理就是consumer-group之間可以消費同樣的資料
相關推薦
Kafka跨叢集同步工具——MirrorMaker
MirrorMaker是為解決Kafka跨叢集同步、建立映象叢集而存在的;下圖展示了其工作原理。該工具消費源叢集訊息然後將資料重新推送到目標叢集。 MirrorMaker使用方式 啟動mirror-maker程式需要一個或多個consu
使用EMR Spark Relational Cache跨叢集同步資料
Relational Cache相關文章連結: 使用Relational Cache加速EMR Spark資料分析
Kafka 跨集群同步方案
技術 工程師 51cto buffers 狀況 指定 out shadow 編譯 該方案解決Kafka跨集群同步、創建Kafka集群鏡像等相關問題,主要使用Kafka內置的MirrorMaker工具實現。 Kafka鏡像即已有Kafka集群的副本。下圖展示如何使用Mirr
kafka學習小結(springboot2+kafka組成叢集模式3同步非同步模式)
接著上一篇補充 官網上關於這一塊迷迷糊糊的看不懂,自己總結了下其中的差異: 我們一般沒做特殊處理的就是同步模式,生產者傳送訊息,然後交給消費者,這裡面我們也可以對訊息的結果進行處理,防止訊息丟失 kafkademo中,修改REST介面如下:
zookeeper-kafka(叢集版)安裝部署以及java呼叫工具類
Kafka安裝部署文件 ■ 文件版本 V1.0 ■ 作業系統 CentOS Linux release 7.3.1611
JDK5新特性之線程同步工具類(三)
string 兩個人 exec random 主線程 一個人 exce print exchange 一. Semaphore Semaphore能夠控制同一時候訪問資源的線程個數, 比如: 實現一個文件同意的並發訪問數. Semaphore實現的功能就類似廁全部5個坑
Rsync數據同步工具應用指南
rsync 文件同步 1、Rsync數據同步工具應用指南簡介Rsync的特性:Rsync的工作方式:Rsync命令同步選項參數:本地主機模式示例遠程RPC模式示例簡介 Rsync是一款開源的、快速的、多功能的、可實現全量及增量的本地或遠程數據同步備份的優秀工具。可使本地和遠程兩臺或多臺主機之間的
Linux下同步工具inotify+rsync使用詳解
server linux 通道 主機 Linux下同步工具inotify+rsync使用詳解 Posted on 2014-12-12 | In Linux | 9 | Visitors 4381. rsync1.1 什麽是rsyncrsync是一個遠程數據同步工具,可通過LAN/WAN
rsync - 遠程同步工具
靈活 col -c bash round rec 刪除 ria let 一直沒有對這個命令太有深入的理解 簡介 rsync 即 remote sync,一個遠程與本地文件同步工具。rsync 使用的算法能夠最小化所需復制的數據,因為它只移動那些修改了的文件。 rsync 是
愚公oracle數據庫同步工具
開發環境 follow 物化視圖 中斷 影響 簡潔 時間 trac 工具 最近,利用一些時間對oracle數據庫實時同步工具做了一些調研分析,主要關註了linkedin的databus和阿裏的yugong兩個中間件,其中databus需要在每個待同步的表上增加額外的列和觸發
Rsync同步工具
數據 系統運維 同步工具 rsync配置文件:/etc/rsyncd.conf ###安裝rsync後系統默認不存在rsyncd.conf 需要自己創建。[[email protected]/* */ ~]# cat /etc/rsyncd.conf##rsyncd.conf s
阿裏mysql同步工具otter的docker鏡像
開發 參數 https 測試的 ont git mys mysq http https://github.com/dearplain/otter_manager https://github.com/dearplain/otter_node 本人開發的小巧d
Linux系統備份還原工具4(rsync/數據同步工具)
nor 出現問題 tab mman 文件格式 部署 ubunt 數據 logs rsync即是能備份系統也是數據同步的工具。 在Jenkins上可以使用rsync結合SSH的免密登錄做數據同步和分發。這樣一來可以達到部署全命令化,不需要依賴任何插件去實現。 命令參考:h
rsync同步工具的配置與使用
www allow 目錄 /etc/ 工作方式 日誌 echo als errors 一、什麽是rsync?rsync是一款開源的,快速的,多功能的,可實現全量及增量的本地或遠程數據同步備份的優秀工具。 rsync官網 http://rsync.samba.org/
rsync文件同步工具
rsync1.rsyncrsync命令是一個遠程數據同步工具,可通過LAN/WAN快速同步多臺主機間的文件。rsync使用所謂的“rsync算法”來使本地和遠程兩個主機或者本機目錄之間的文件達到同步,這個算法只傳送兩個文件的不同部分,而不是每次都整份傳送,因此速度相當快。2.rsync命令格式rsync [o
linux同步工具rsync?
linux同步工具rsync?linux同步工具rsync一、rsync命令rsync命令是一個遠程數據同步工具,可通過LAN/WAN快速同步多臺主機間的文件。rsync使用所謂的“rsync算法”來使本地和遠程兩個主機之間的文件達到同步,這個算法只傳送兩個文件的不同部分,而不是每次都整份傳送,因此速度相當快
MySQL5.6參數binlog-do-db和log-slave-updates跨庫同步註意事項
fec oca 6.2 warnings 混合 urn 1-1 esc master MySQL5.6.20上在master主庫配置文件/etc/my.cnf裏指定數據庫同步到slave從庫上使用參數binlog-do-db log-slave-updates 註意事項:
rsync同步工具介紹與使用
多選 文件信息 工具 源文件 指定 應用 表示 logs 快速 一、rsync同步工具介紹與使用 rsync命令是一個遠程數據同步工具,可通過LAN/WAN快速同步多臺主機間的文件。rsync使用所謂的“rsync算法”來使本地和遠程兩個主機之間的文件達到同步,這個算法只傳
Linux文件同步工具-rsync
監聽端口 屬於 auth delete ret 日誌 roo delet sta Linux文件同步工具-rsync 安裝包 yum install -y rsync rsync常用選項 -a:歸檔模式,表示遞歸方式傳輸文件,並保持所有屬性;通-rlptgoD;-r:同
開源數據同步工具:Lsyncd部署實錄
lsyncd[root@king02 ~]# yum install -y xinetd [root@king02 ~]# yum install rsync [root@king02 ~]# vi /etc/xinetd.d/rsync # default: off # description: The