
使用EMR Spark Relational Cache跨叢集同步資料
Relational Cache相關文章連結:
背景
Relational Cache是EMR Spark支援的一個重要特性,主要通過對資料進行預組織和預計算加速資料分析,提供了類似傳統資料倉庫物化檢視的功能。除了用於提升資料處理速度,Relational Cache還可以應用於其他很多場景,本文主要介紹如何使用Relational Cache跨叢集同步資料表。
通過統一的Data Lake管理所有資料是許多公司追求的目標,但是在現實中,由於多個數據中心,不同網路Region,甚至不同部門的存在,不可避免的會存在多個不同的大資料叢集,不同叢集的資料同步需求普遍存在,此外,叢集遷移,搬站涉及到的新老資料同步也是一個常見的問題。資料同步的工作通常是一個比較痛苦的過程,遷移工具的開發,增量資料處理,讀寫的同步,後續的資料比對等等,需要很多的定製開發和人工介入。基於Relational Cache,使用者可以簡化這部分的工作,以較小的代價實現跨叢集的資料同步。
下面我們以具體示例展示如何通過EMR Spark Relational Cache實現跨叢集的資料同步。
使用Relational Cache同步資料
假設我們有A,B兩個叢集,需要把activity_log表的資料從叢集A同步到叢集B中,且在整個過程中,會持續有新的資料插入到activity_log表中,A叢集中activity_log的建表語句如下:
CREATE TABLE activity_log (
user_id STRING,
act_type STRING,
module_id INT,
d_year INT)
USING JSON
PARTITIONED BY (d_year)
插入兩條資訊代表歷史資訊:
INSERT INTO TABLE activity_log PARTITION (d_year = 2017) VALUES("user_001", "NOTIFICATION", 10), ("user_101", "SCAN", 2)
為activity_log表建一個Relational Cache:
CACHE TABLE activity_log_sync
REFRESH ON COMMIT
DISABLE REWRITE
USING JSON
PARTITIONED BY (d_year)
LOCATION "hdfs://192.168.1.36:9000/user/hive/data/activity_log"
AS SELECT user_id, act_type, module_id, d_year FROM activity_log
REFRESH ON COMMIT表示當源表資料發生更新時,自動更新cache資料。通過LOCATION可以指定cache的資料的儲存地址,我們把cache的地址指向B叢集的HDFS從而實現資料從叢集A到叢集B的同步。此外Cache的欄位和Partition資訊均與源表保持一致。
在叢集B中,我們也建立一個activity_log表,建立語句如下:
CREATE TABLE activity_log (
user_id STRING,
act_type STRING,
module_id INT,
d_year INT)
USING JSON
PARTITIONED BY (d_year)
LOCATION "hdfs:///user/hive/data/activity_log"
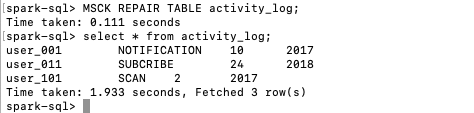
執行MSCK REPAIR TABLE activity_log自動修復相關meta資訊,然後執行查詢語句,可以看到在叢集B中,已經能夠查到之前叢集A的表中插入的兩條資料。

在叢集A中繼續插入新的資料:
INSERT INTO TABLE activity_log PARTITION (d_year = 2018) VALUES("user_011", "SUBCRIBE", 24);
然後在叢集B中執行MSCK REPAIR TABLE activity_log並再次查詢activity_log表,可以發現數據已經自動同步到叢集B的activity_log表中,對於分割槽表,當有新的分割槽資料加入時,Relational Cache可以增量的同步新的分割槽資料,而不是重新同步全部資料。
如果叢集A中activity_log的新增資料不是通過Spark插入的,而是通過Hive或其他方式外部匯入到Hive表中,使用者可以通過REFRESH TABLE activity_log_sync語句手工或通過指令碼觸發同步資料,如果新增資料是按照分割槽批量匯入,還可以通過類似REFRESH TABLE activity_log_sync WITH TABLE activity_log PARTITION (d_year=2018)語句增量同步分割槽資料。
Relational Cache可以保證叢集A和叢集B中activity_log表的資料一致性,依賴activity_log表的下游任務或應用可以隨時切換到叢集B,同時使用者也可以隨時將寫入資料到叢集A中activity_log表的應用或服務暫停,指向叢集B中的activity_log表並重啟服務,從而完成上層應用或服務的遷移。完成後清理叢集A中的activity_log和activity_log_sync即可。
總結
本文介紹瞭如何通過Relational Cache在不同大資料叢集的資料表之間同步資料,非常簡單便捷。除此之外,Relational Cache也可以應用到很多其他的場景中,比如構建秒級響應的OLAP平臺,互動式的BI,Dashboard應用,加速ETL過程等等,之後我們也會和大家分享在更多場景中Relational Cache的最佳實踐。
作者:開源大資料EMR
原文連結
本文為雲棲社群原創內容,未經