
MapReduce詳解
MapReduce簡介
- MapReduce是一種分散式計算模型,是Google提出的,主要用於搜尋領域,解決海量資料的計算問題。
- MR有兩個階段組成:Map和Reduce,使用者只需實現map()和reduce()兩個函式,即可實現分散式計算。
MapReduce做什麼
MapReduce擅長處理大資料,它為什麼具有這種能力呢?這可由MapReduce的設計思想發覺。MapReduce的思想就是“分而治之”。
(1)Mapper負責“分”,即把複雜的任務分解為若干個“簡單的任務”來處理。“簡單的任務”包含三層含義:
一是資料或計算的規模相對原任務要大大縮小;二是就近計算原則,即任務會分配到存放著所需資料的節點上進行計算;三是這些小任務可以平行計算,彼此間幾乎沒有依賴
(2)Reducer負責對map階段的結果進行彙總。至於需要多少個Reducer,使用者可以根據具體問題,通過在mapred-site.xml配置檔案裡設定引數mapred.reduce.tasks的值,預設值為1。
一個比較形象的語言解釋MapReduce:
我們要數圖書館中的所有書。你數1號書架,我數2號書架。這就是“Map”。我們人越多,數書就更快。
現在我們到一起,把所有人的統計數加在一起。這就是“Reduce”。
Hadoop中的MapReduce框架
一個MapReduce作業通常會把輸入的資料集切分為若干獨立的資料塊,由Map任務以完全並行的方式去處理它們。
框架會對Map的輸出先進行排序,然後把結果輸入給Reduce任務。通常作業的輸入和輸出都會被儲存在檔案系統中,整個框架負責任務的排程和監控,以及重新執行已經關閉的任務。
通常,MapReduce框架和分散式檔案系統是執行在一組相同的節點上,也就是說,計算節點和儲存節點通常都是在一起的。這種配置允許框架在那些已經存好資料的節點上高效地排程任務,這可以使得整個叢集的網路頻寬被非常高效地利用。
從Map,Reduce,Shuffle理解
總體步驟

Map階段包括:
第一讀資料:從HDFS讀取資料
1、問題:讀取資料產生多少個Mapper??
Mapper資料過大的話,會產生大量的小檔案,由於Mapper是基於虛擬機器的,過多的Mapper建立和初始化及關閉虛擬機器都會消耗大量的硬體資源;
Mapper數太小,併發度過小,Job執行時間過長,無法充分利用分散式硬體資源;
2、Mapper數量由什麼決定??
(1)輸入檔案數目
(2)輸入檔案的大小
(3)配置引數
這三個因素決定的。
涉及引數:
mapreduce.input.fileinputformat.split.minsize //啟動map最小的split size大小,預設0
mapreduce.input.fileinputformat.split.maxsize //啟動map最大的split size大小,預設256M
dfs.block.size//block塊大小,預設64M
計算公式:splitSize = Math.max(minSize, Math.min(maxSize, blockSize));
例如預設情況下:例如一個檔案800M,Block大小是128M,那麼Mapper數目就是7個。6個Mapper處理的資料是128 * 6 = 728M,1個Mapper處理的資料是32M;
再例如一個目錄下有三個檔案大小分別為:5M10M 150M 這個時候其實會產生四個Mapper處理的資料分別是5M,10M,128M,22M。
Mapper是基於檔案自動產生的,如果想要自己控制Mapper的個數???
就如上面,5M,10M的資料很快處理完了,128M要很長時間;這個就需要通過引數的控制來調節Mapper的個數。
減少Mapper的個數的話,就要合併小檔案,這種小檔案有可能是直接來自於資料來源的小檔案,也可能是Reduce產生的小檔案。
設定合併器:(set都是在hive指令碼,也可以配置Hadoop)
設定合併器本身:
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
set hive.merge.mapFiles=true;
set hive.merge.mapredFiles=true;
set hive.merge.size.per.task=256000000;//每個Mapper要處理的資料,就把上面的5M10M……合併成為一個
一般還要配合一個引數:
set mapred.max.split.size=256000000 // mapred切分的大小
set mapred.min.split.size.per.node=128000000//低於128M就算小檔案,資料在一個節點會合並,在多個不同的節點會把資料抓過來進行合併。
Hadoop中的引數:可以通過控制檔案的數量控制mapper數量
mapreduce.input.fileinputformat.split.minsize(default:0),小於這個值會合並
mapreduce.input.fileinputformat.split.maxsize 大於這個值會切分
第二處理資料:
Partition說明
對於map輸出的每一個鍵值對,系統都會給定一個partition,partition值預設是通過計算key的hash值後對Reduce task的數量取模獲得。如果一個鍵值對的partition值為1,意味著這個鍵值對會交給第一個Reducer處理。
自定義partitioner的情況:
1、我們知道每一個Reduce的輸出都是有序的,但是將所有Reduce的輸出合併到一起卻並非是全域性有序的,如果要做到全域性有序,我們該怎麼做呢?最簡單的方式,只設置一個Reduce task,但是這樣完全發揮不出叢集的優勢,而且能應對的資料量也很受限。最佳的方式是自己定義一個Partitioner,用輸入資料的最大值除以系統Reduce task數量的商作為分割邊界,也就是說分割資料的邊界為此商的1倍、2倍至numPartitions-1倍,這樣就能保證執行partition後的資料是整體有序的。
2、解決資料傾斜:另一種需要我們自己定義一個Partitioner的情況是各個Reduce task處理的鍵值對數量極不平衡。對於某些資料集,由於很多不同的key的hash值都一樣,導致這些鍵值對都被分給同一個Reducer處理,而其他的Reducer處理的鍵值對很少,從而拖延整個任務的進度。當然,編寫自己的Partitioner必須要保證具有相同key值的鍵值對分發到同一個Reducer。
3、自定義的Key包含了好幾個欄位,比如自定義key是一個物件,包括type1,type2,type3,只需要根據type1去分發資料,其他欄位用作二次排序。
環形緩衝區
Map的輸出結果是由collector處理的,每個Map任務不斷地將鍵值對輸出到在記憶體中構造的一個環形資料結構中。使用環形資料結構是為了更有效地使用記憶體空間,在記憶體中放置儘可能多的資料。
這個資料結構其實就是個位元組陣列,叫Kvbuffer,名如其義,但是這裡面不光放置了資料,還放置了一些索引資料,給放置索引資料的區域起了一個Kvmeta的別名,在Kvbuffer的一塊區域上穿了一個IntBuffer(位元組序採用的是平臺自身的位元組序)的馬甲。資料區域和索引資料區域在Kvbuffer中是相鄰不重疊的兩個區域,用一個分界點來劃分兩者,分界點不是亙古不變的,而是每次Spill之後都會更新一次。初始的分界點是0,資料的儲存方向是向上增長,索引資料的儲存方向是向下增長Kvbuffer的存放指標bufindex是一直悶著頭地向上增長,比如bufindex初始值為0,一個Int型的key寫完之後,bufindex增長為4,一個Int型的value寫完之後,bufindex增長為8。
索引是對在kvbuffer中的鍵值對的索引,是個四元組,包括:value的起始位置、key的起始位置、partition值、value的長度,佔用四個Int長度,Kvmeta的存放指標Kvindex每次都是向下跳四個“格子”,然後再向上一個格子一個格子地填充四元組的資料。比如Kvindex初始位置是-4,當第一個鍵值對寫完之後,(Kvindex+0)的位置存放value的起始位置、(Kvindex+1)的位置存放key的起始位置、(Kvindex+2)的位置存放partition的值、(Kvindex+3)的位置存放value的長度,然後Kvindex跳到-8位置,等第二個鍵值對和索引寫完之後,Kvindex跳到-12位置。
第三寫資料到磁碟
Mapper中的Kvbuffer的大小預設100M,可以通過mapreduce.task.io.sort.mb(default:100)引數來調整。可以根據不同的硬體尤其是記憶體的大小來調整,調大的話,會減少磁碟spill的次數此時如果記憶體足夠的話,一般都會顯著提升效能。spill一般會在Buffer空間大小的80%開始進行spill(因為spill的時候還有可能別的執行緒在往裡寫資料,因為還預留空間,有可能有正在寫到Buffer中的資料),可以通過mapreduce.map.sort.spill.percent(default:0.80)進行調整,Map Task在計算的時候會不斷產生很多spill檔案,在Map Task結束前會對這些spill檔案進行合併,這個過程就是merge的過程。mapreduce.task.io.sort.factor(default:10),代表進行merge的時候最多能同時merge多少spill,如果有100個spill個檔案,此時就無法一次完成整個merge的過程,這個時候需要調大mapreduce.task.io.sort.factor(default:10)來減少merge的次數,從而減少磁碟的操作;
Spill這個重要的過程是由Spill執行緒承擔,Spill執行緒從Map任務接到“命令”之後就開始正式幹活,乾的活叫SortAndSpill,原來不僅僅是Spill,在Spill之前還有個頗具爭議性的Sort。
Combiner存在的時候,此時會根據Combiner定義的函式對map的結果進行合併,什麼時候進行Combiner操作呢???和Map在一個JVM中,是由min.num.spill.for.combine的引數決定的,預設是3,也就是說spill的檔案數在預設情況下由三個的時候就要進行combine操作,最終減少磁碟資料;
減少磁碟IO和網路IO還可以進行:壓縮,對spill,merge檔案都可以進行壓縮。中間結果非常的大,IO成為瓶頸的時候壓縮就非常有用,可以通過mapreduce.map.output.compress(default:false)設定為true進行壓縮,資料會被壓縮寫入磁碟,讀資料讀的是壓縮資料需要解壓,在實際經驗中Hive在Hadoop的執行的瓶頸一般都是IO而不是CPU,壓縮一般可以10倍的減少IO操作,壓縮的方式Gzip,Lzo,BZip2,Lzma等,其中Lzo是一種比較平衡選擇,mapreduce.map.output.compress.codec(default:org.apache.hadoop.io.compress.DefaultCodec)引數設定。但這個過程會消耗CPU,適合IO瓶頸比較大。
Shuffle和Reduce階段包括:
一、Copy
1、由於job的每一個map都會根據reduce(n)數將資料分成map 輸出結果分成n個partition,所以map的中間結果中是有可能包含每一個reduce需要處理的部分資料的。所以,為了優化reduce的執行時間,hadoop中是等job的第一個map結束後,所有的reduce就開始嘗試從完成的map中下載該reduce對應的partition部分資料,因此map和reduce是交叉進行的,其實就是shuffle。Reduce任務通過HTTP向各個Map任務拖取(下載)它所需要的資料(網路傳輸),Reducer是如何知道要去哪些機器取資料呢?一旦map任務完成之後,就會通過常規心跳通知應用程式的Application Master。reduce的一個執行緒會週期性地向master詢問,直到提取完所有資料(如何知道提取完?)資料被reduce提走之後,map機器不會立刻刪除資料,這是為了預防reduce任務失敗需要重做。因此map輸出資料是在整個作業完成之後才被刪除掉的。
2、reduce程序啟動資料copy執行緒(Fetcher),通過HTTP方式請求maptask所在的TaskTracker獲取maptask的輸出檔案。由於map通常有許多個,所以對一個reduce來說,下載也可以是並行的從多個map下載,那到底同時到多少個Mapper下載資料??這個並行度是可以通過mapreduce.reduce.shuffle.parallelcopies(default5)調整。預設情況下,每個Reducer只會有5個map端並行的下載執行緒在從map下資料,如果一個時間段內job完成的map有100個或者更多,那麼reduce也最多隻能同時下載5個map的資料,所以這個引數比較適合map很多並且完成的比較快的job的情況下調大,有利於reduce更快的獲取屬於自己部分的資料。 在Reducer記憶體和網路都比較好的情況下,可以調大該引數;
3、reduce的每一個下載執行緒在下載某個map資料的時候,有可能因為那個map中間結果所在機器發生錯誤,或者中間結果的檔案丟失,或者網路瞬斷等等情況,這樣reduce的下載就有可能失敗,所以reduce的下載執行緒並不會無休止的等待下去,當一定時間後下載仍然失敗,那麼下載執行緒就會放棄這次下載,並在隨後嘗試從另外的地方下載(因為這段時間map可能重跑)。reduce下載執行緒的這個最大的下載時間段是可以通過mapreduce.reduce.shuffle.read.timeout(default180000秒)調整的。如果叢集環境的網路本身是瓶頸,那麼使用者可以通過調大這個引數來避免reduce下載執行緒被誤判為失敗的情況。一般情況下都會調大這個引數,這是企業級最佳實戰。
二、MergeSort
1、這裡的merge和map端的merge動作類似,只是陣列中存放的是不同map端copy來的數值。Copy過來的資料會先放入記憶體緩衝區中,然後當使用記憶體達到一定量的時候才spill磁碟。這裡的緩衝區大小要比map端的更為靈活,它基於JVM的heap size設定。這個記憶體大小的控制就不像map一樣可以通過io.sort.mb來設定了,而是通過另外一個引數 mapreduce.reduce.shuffle.input.buffer.percent(default 0.7f 原始碼裡面寫死了) 來設定,這個引數其實是一個百分比,意思是說,shuffile在reduce記憶體中的資料最多使用記憶體量為:0.7 × maxHeap of reduce task。JVM的heapsize的70%。記憶體到磁碟merge的啟動門限可以通過mapreduce.reduce.shuffle.merge.percent(default0.66)配置。也就是說,如果該reduce task的最大heap使用量(通常通過mapreduce.admin.reduce.child.java.opts來設定,比如設定為-Xmx1024m)的一定比例用來快取資料。預設情況下,reduce會使用其heapsize的70%來在記憶體中快取資料。假設 mapreduce.reduce.shuffle.input.buffer.percent 為0.7,reducetask的max heapsize為1G,那麼用來做下載資料快取的記憶體就為大概700MB左右。這700M的記憶體,跟map端一樣,也不是要等到全部寫滿才會往磁碟刷的,而是當這700M中被使用到了一定的限度(通常是一個百分比),就會開始往磁碟刷(刷磁碟前會先做sortMerge)。這個限度閾值也是可以通過引數 mapreduce.reduce.shuffle.merge.percent(default0.66)來設定。與map 端類似,這也是溢寫的過程,這個過程中如果你設定有Combiner,也是會啟用的,然後在磁碟中生成了眾多的溢寫檔案。這種merge方式一直在執行,直到沒有map端的資料時才結束,然後啟動磁碟到磁碟的merge方式生成最終的那個檔案。
這裡需要強調的是,merge有三種形式:1)記憶體到記憶體(memToMemMerger)2)記憶體中Merge(inMemoryMerger)3)磁碟上的Merge(onDiskMerger)具體包括兩個:(一)Copy過程中磁碟合併(二)磁碟到磁碟。
(1)記憶體到記憶體Merge(memToMemMerger) Hadoop定義了一種MemToMem合併,這種合併將記憶體中的map輸出合併,然後再寫入記憶體。這種合併預設關閉,可以通過mapreduce.reduce.merge.memtomem.enabled(default:false)
開啟,當map輸出檔案達到mapreduce.reduce.merge.memtomem.threshold時,觸發這種合併。
(2)記憶體中Merge(inMemoryMerger):當緩衝中資料達到配置的閾值時,這些資料在記憶體中被合併、寫入機器磁碟。閾值有2種配置方式:
配置記憶體比例:前面提到reduceJVM堆記憶體的一部分用於存放來自map任務的輸入,在這基礎之上配置一個開始合併資料的比例。假設用於存放map輸出的記憶體為500M,mapreduce.reduce.shuffle.merge.percent配置為0.66,則當記憶體中的資料達到330M的時候,會觸發合併寫入。
配置map輸出數量: 通過mapreduce.reduce.merge.inmem.threshold配置。在合併的過程中,會對被合併的檔案做全域性的排序。如果作業配置了Combiner,則會執行combine函式,減少寫入磁碟的資料量。
(3)磁碟上的Merge(onDiskMerger):
(3.1)Copy過程中磁碟Merge:在copy過來的資料不斷寫入磁碟的過程中,一個後臺執行緒會把這些檔案合併為更大的、有序的檔案。如果map的輸出結果進行了壓縮,則在合併過程中,需要在記憶體中解壓後才能給進行合併。這裡的合併只是為了減少最終合併的工作量,也就是在map輸出還在拷貝時,就開始進行一部分合並工作。合併的過程一樣會進行全域性排序。
(3.2)最終磁碟中Merge:當所有map輸出都拷貝完畢之後,所有資料被最後合併成一個整體有序的檔案,作為reduce任務的輸入。這個合併過程是一輪一輪進行的,最後一輪的合併結果直接推送給reduce作為輸入,節省了磁碟操作的一個來回。最後(所以map輸出都拷貝到reduce之後)進行合併的map輸出可能來自合併後寫入磁碟的檔案,也可能來及記憶體緩衝,在最後寫入記憶體的map輸出可能沒有達到閾值觸發合併,所以還留在記憶體中。
每一輪合併不一定合併平均數量的檔案數,指導原則是使用整個合併過程中寫入磁碟的資料量最小,為了達到這個目的,則需要最終的一輪合併中合併儘可能多的資料,因為最後一輪的資料直接作為reduce的輸入,無需寫入磁碟再讀出。因此我們讓最終的一輪合併的檔案數達到最大,即合併因子的值,通過mapreduce.task.io.sort.factor(default:10)來配置。
如上圖:Reduce階段中一個Reduce過程 可能的合併方式為:假設現在有20個map輸出檔案,合併因子配置為5,則需要4輪的合併。最終的一輪確保合併5個檔案,其中包括2個來自前2輪的合併結果,因此原始的20箇中,再留出3個給最終一輪。
三、Reduce函式呼叫(使用者自定義業務邏輯)
1、當reduce將所有的map上對應自己partition的資料下載完成後,就會開始真正的reduce計算階段。reducetask真正進入reduce函式的計算階段,由於reduce計算時肯定也是需要消耗記憶體的,而在讀取reduce需要的資料時,同樣是需要記憶體作為buffer,這個引數是控制,reducer需要多少的記憶體百分比來作為reduce讀已經sort好的資料的buffer大小??預設用多大記憶體呢??預設情況下為0,也就是說,預設情況下,reduce是全部從磁碟開始讀處理資料。可以用mapreduce.reduce.input.buffer.percent(default 0.0)(原始碼MergeManagerImpl.java:674行)來設定reduce的快取。如果這個引數大於0,那麼就會有一定量的資料被快取在記憶體並輸送給reduce,當reduce計算邏輯消耗記憶體很小時,可以分一部分記憶體用來快取資料,可以提升計算的速度。所以預設情況下都是從磁碟讀取資料,如果記憶體足夠大的話,務必設定該引數讓reduce直接從快取讀資料,這樣做就有點Spark Cache的感覺;
2、Reduce在這個階段,框架為已分組的輸入資料中的每個 <key, (list of values)>對呼叫一次 reduce(WritableComparable,Iterator, OutputCollector, Reporter)方法。Reduce任務的輸出通常是通過呼叫 OutputCollector.collect(WritableComparable,Writable)寫入檔案系統的。Reducer的輸出是沒有排序的。
效能調優
如果能夠根據情況對shuffle過程進行調優,對於提供MapReduce效能很有幫助。相關的引數配置列在後面的表格中。
一個通用的原則是給shuffle過程分配儘可能大的記憶體,當然你需要確保map和reduce有足夠的記憶體來執行業務邏輯。因此在實現Mapper和Reducer時,應該儘量減少記憶體的使用,例如避免在Map中不斷地疊加。
執行map和reduce任務的JVM,記憶體通過mapred.child.java.opts屬性來設定,儘可能設大記憶體。容器的記憶體大小通過mapreduce.map.memory.mb和mapreduce.reduce.memory.mb來設定,預設都是1024M。
map優化
在map端,避免寫入多個spill檔案可能達到最好的效能,一個spill檔案是最好的。通過估計map的輸出大小,設定合理的mapreduce.task.io.sort.*屬性,使得spill檔案數量最小。例如儘可能調大mapreduce.task.io.sort.mb。
map端相關的屬性如下表:
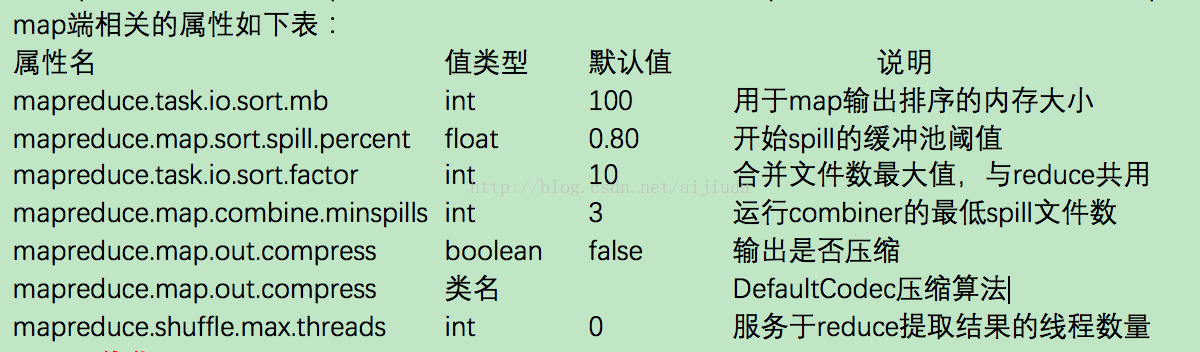
reduce優化
在reduce端,如果能夠讓所有資料都儲存在記憶體中,可以達到最佳的效能。通常情況下,記憶體都保留給reduce函式,但是如果reduce函式對記憶體需求不是很高,將mapreduce.reduce.merge.inmem.threshold(觸發合併的map輸出檔案數)設為0,mapreduce.reduce.input.buffer.percent(用於儲存map輸出檔案的堆記憶體比例)設為1.0,可以達到很好的效能提升。在2008年的TB級別資料排序效能測試中,Hadoop就是通過將reduce的中間資料都儲存在記憶體中勝利的。
reduce端相關屬性:

通用優化
Hadoop預設使用4KB作為緩衝,這個算是很小的,可以通過io.file.buffer.size來調高緩衝池大小。
參考連結:
相關推薦
大數據入門第七天——MapReduce詳解
使用 sys distrib sent 作業 asi users tor war 一、概述 1.map-reduce是什麽 Hadoop MapReduce is a software framework for easily writing applica
大數據入門第七天——MapReduce詳解(下)
nbsp targe input pre 切片 入門 技術 log 過程 一、mapTask並行度的決定機制 1.概述 一個job的map階段並行度由客戶端在提交job時決定 而客戶端對map階段並行度的規劃的基本邏輯為: 將待處理數據執行邏輯
大數據入門第八天——MapReduce詳解(三)
大數 blog eve 分享圖片 shuf open src hid span 1/mr的combiner 2/mr的排序 3/mr的shuffle 4/mr與yarn 5/mr運行模式 6/mr實現join 7/mr全局圖
MapReduce 詳解
宣告: https://blog.csdn.net/shujuelin/article/details/79119214 上面這篇部落格真的寫得很好,可以點選進去看 MapReduce是一個分散式運算程式的程式設計框架,是使用者開發"基於hadoop的資料分析應用" MapReduce
hadoop2-MapReduce詳解
本文是對Hadoop2.2.0版本的MapReduce進行詳細講解。請大家要注意版本,因為Hadoop的不同版本,原始碼可能是不同的。 以下是本文的大綱: 1.獲取原始碼2.WordCount案例分析3.客戶端原始碼分析4.小結5.Mapper詳解 5.1.map輸入 5.2.map輸出 5
【MapReduce詳解及原始碼解析(一)】——分片輸入、Mapper及Map端Shuffle過程
title: 【MapReduce詳解及原始碼解析(一)】——分片輸入、Mapper及Map端Shuffle過程 date: 2018-12-03 21:12:42 tags: Hadoop categories: 大資料 toc: true 點選檢視我的部落格:Josonlee’
MapReduce詳解!詳解!詳解!
理解 MapReduce 執行過程 以統計檔案中 單詞出現的個數為例 一共三個檔案 1.以整個檔案的角度進行圖解 ( 每個方塊就是一個檔案) 2.根據程式碼進行圖解 放上程式碼,僅供參考 WCMapper.java public class WCM
MapReduce詳解
MapReduce簡介 MapReduce是一種分散式計算模型,是Google提出的,主要用於搜尋領域,解決海量資料的計算問題。 MR有兩個階段組成:Map和Reduce,使用者只需實現map()和reduce()兩個函式,即可實現分散式計算。 MapReduce做什麼
MapReduce:詳解Shuffle過程
/** * author : 冶秀剛 * mail : [email protected] */ Shuffle過程是MapReduce的核心,也被稱為奇蹟發生的地方。要想理解MapReduce, Shuffle是必須要了解的。我看
Hadoop核心元件—MapReduce詳解
Hadoop 分散式計算框架(MapReduce)。 MapReduce設計理念: - 分散式計算 - 移動計算,而不是移動資料 MapReduce計算框架 步驟1:split split切分Blo
hadoop之mapreduce詳解(基礎篇)
本篇文章主要從mapreduce執行作業的過程,shuffle,以及mapreduce作業失敗的容錯幾個方面進行詳解。 一、mapreduce作業執行過程 1.1、mapreduce介紹 MapReduce是一種程式設計模型,用於大規模資料集(大於1TB)的並行運
hadoop之mapreduce詳解(進階篇)
上篇文章hadoop之mapreduce詳解(基礎篇)我們瞭解了mapreduce的執行過程和shuffle過程,本篇文章主要從mapreduce的元件和輸入輸出方面進行闡述。 一、mapreduce作業控制模組以及其他功能 mapreduce包括作業控制模組,程式設計模型,資料處理引擎。這裡我們重點闡述
hadoop之mapreduce詳解(優化篇)
一、概述 優化前我們需要知道hadoop適合幹什麼活,適合什麼場景,在工作中,我們要知道業務是怎樣的,能才結合平臺資源達到最有優化。除了這些我們當然還要知道mapreduce的執行過程,比如從檔案的讀取,map處理,shuffle過程,reduce處理,檔案的輸出或者
mapreduce shuffle 和sort 詳解
改變 struct 堆內存 傳輸 工具 默認 臨時 arc 快速排序 MapReduce 框架的核心步驟主要分兩部分:Map 和Reduce。當你向MapReduce 框架提交一個計算作業時,它會首先把計算作業拆分成若幹個Map 任務,然後分配到不同的節點上去執
Hadoop學習筆記:MapReduce框架詳解
object 好的 單點故障 提高 apr copy 普通 exce 代表性 開始聊mapreduce,mapreduce是hadoop的計算框架,我學hadoop是從hive開始入手,再到hdfs,當我學習hdfs時候,就感覺到hdfs和mapreduce關系的緊密。這個
Hadoop學習之路(二十三)MapReduce中的shuffle詳解
就是 多個 流程 http cer 分開 分享圖片 數據分區 bsp 概述 1、MapReduce 中,mapper 階段處理的數據如何傳遞給 reducer 階段,是 MapReduce 框架中 最關鍵的一個流程,這個流程就叫 Shuffle 2、Shuffle: 數
MapReduce編程模型詳解(基於Windows平臺Eclipse)
lib read 找到 lin @override ext logs 設置 otf 本文基於Windows平臺Eclipse,以使用MapReduce編程模型統計文本文件中相同單詞的個數來詳述了整個編程流程及需要註意的地方。不當之處還請留言指出。 前期準備 hadoop集群
MapReduce-shuffle過程詳解
等待 通知 10個 線程數 硬盤 res .sh 現在 溢出 Shuffle map端 map函數開始產生輸出時,並不是簡單地將它寫到磁盤。這個過程很復雜,它利用緩沖的方式寫到內存並出於效率的考慮進行預排序。每個map任務都有一個環形內存緩沖區用於存儲任務輸出。在默認
MapReduce和spark的shuffle過程詳解
存在 位置 方式 傳遞 第一個 2個 過濾 之前 第三方 面試常見問題,必備答案。 參考:https://blog.csdn.net/u010697988/article/details/70173104 mapReducehe和Spark之間的最大區別是前者較偏向於離
MapReduce工作機制詳解
memory 傳遞 等待 mapper 臨時文件 相等 water tsp 以及 1.MapTask工作機制整個Map階段流程大體如上圖所示。簡單概述:input File通過split被邏輯切分為多個split文件,通過Record按行讀取內容給map(用戶自己實現的)進