
基於Keras的attention實戰
要點:
該教程為基於Kears的Attention實戰,環境配置:
Wn10+CPU i7-6700
Pycharm 2018
python 3.6
numpy 1.14.5
Keras 2.0.2
Matplotlib 2.2.2
強調:各種庫的版本型號一定要配置對,因為Keras以及Tensorflow升級更新比較頻繁,很多函式更新後要麼更換了名字,要麼沒有這個函數了,所以大家務必重視。
相關程式碼我放在了我的程式碼倉庫裡哈,歡迎大家下載,這裡附上地址:基於Kears的Attention實戰
筆者資訊:Next_Legend QQ:1219154092 人工智慧 自然語言處理 影象處理 神經網路
——2018.8.21於天津大學
一、導讀
最近兩年,尤其在今年,注意力機制(Attention)及其變種Attention逐漸熱了起來,在很多頂會Paper中都或多或少的用到了attention,所以小編出於好奇,整理了這篇基於Kears的Attention實戰,本教程僅從程式碼的角度來看Attention。通過一個簡單的例子,探索Attention機制是如何在模型中起到特徵選擇作用的。
二、程式碼實戰(一)
1、匯入相關庫檔案
import numpy as np
from attention_utils import get_activations, get_data
np.random.seed(1337 2、資料生成函式
def get_data(n, input_dim, attention_column=1):
"""
Data generation. x is purely random except that it's first value equals the target y.
In practice, the network should learn that the target = x[attention_column].
Therefore, most of its attention should be focused on the value addressed by attention_column.
:param n: the number of samples to retrieve.
:param input_dim: the number of dimensions of each element in the series.
:param attention_column: the column linked to the target. Everything else is purely random.
:return: x: model inputs, y: model targets
""" 3、模型定義函式
將輸入進行一次變換後,計算出Attention權重,將輸入乘上Attention權重,獲得新的特徵。
def build_model():
inputs = Input(shape=(input_dim,))
# ATTENTION PART STARTS HERE
attention_probs = Dense(input_dim, activation='softmax', name='attention_vec')(inputs)
attention_mul =merge([inputs, attention_probs], output_shape=32, name='attention_mul', mode='mul')
# ATTENTION PART FINISHES HERE
attention_mul = Dense(64)(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model4、主函式
if __name__ == '__main__':
N = 10000
inputs_1, outputs = get_data(N, input_dim)
m = build_model()
m.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print(m.summary())
m.fit([inputs_1], outputs, epochs=20, batch_size=64, validation_split=0.5)
testing_inputs_1, testing_outputs = get_data(1, input_dim)
# Attention vector corresponds to the second matrix.
# The first one is the Inputs output.
attention_vector = get_activations(m, testing_inputs_1,
print_shape_only=True,
layer_name='attention_vec')[0].flatten()
print('attention =', attention_vector)
# plot part.
import matplotlib.pyplot as plt
import pandas as pd
pd.DataFrame(attention_vector, columns=['attention (%)']).plot(kind='bar',
title='Attention Mechanism as '
'a function of input'
' dimensions.')
plt.show()
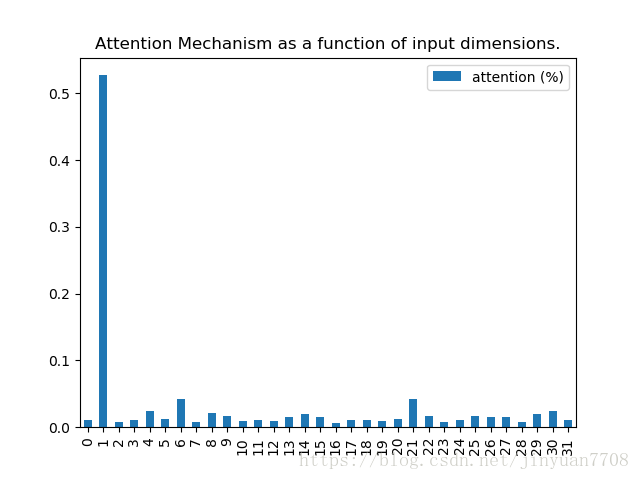
5、執行結果
程式碼中,attention_column為1,也就是說,label只與資料的第1個特徵相關。從執行結果中可以看出,Attention權重成功地獲取了這個資訊。
三、程式碼實戰(二)
1、匯入相關庫檔案
from keras.layers import merge
from keras.layers.core import *
from keras.layers.recurrent import LSTM
from keras.models import *
from attention_utils import get_activations, get_data_recurrent
INPUT_DIM = 2
TIME_STEPS = 20
# if True, the attention vector is shared across the input_dimensions where the attention is applied.
SINGLE_ATTENTION_VECTOR = False
APPLY_ATTENTION_BEFORE_LSTM = False
2、資料生成函式
def attention_3d_block(inputs):
# inputs.shape = (batch_size, time_steps, input_dim)
input_dim = int(inputs.shape[2])
a = Permute((2, 1))(inputs)
a = Reshape((input_dim, TIME_STEPS))(a) # this line is not useful. It's just to know which dimension is what.
a = Dense(TIME_STEPS, activation='softmax')(a)
if SINGLE_ATTENTION_VECTOR:
a = Lambda(lambda x: K.mean(x, axis=1), name='dim_reduction')(a)
a = RepeatVector(input_dim)(a)
a_probs = Permute((2, 1), name='attention_vec')(a)
output_attention_mul = merge([inputs, a_probs], name='attention_mul', mode='mul')
return output_attention_mul
def model_attention_applied_after_lstm():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
lstm_units = 32
lstm_out = LSTM(lstm_units, return_sequences=True)(inputs)
attention_mul = attention_3d_block(lstm_out)
attention_mul = Flatten()(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
def model_attention_applied_before_lstm():
inputs = Input(shape=(TIME_STEPS, INPUT_DIM,))
attention_mul = attention_3d_block(inputs)
lstm_units = 32
attention_mul = LSTM(lstm_units, return_sequences=False)(attention_mul)
output = Dense(1, activation='sigmoid')(attention_mul)
model = Model(input=[inputs], output=output)
return model
4、主函式
if __name__ == '__main__':
N = 300000
# N = 300 -> too few = no training
inputs_1, outputs = get_data_recurrent(N, TIME_STEPS, INPUT_DIM)
if APPLY_ATTENTION_BEFORE_LSTM:
m = model_attention_applied_before_lstm()
else:
m = model_attention_applied_after_lstm()
m.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
print(m.summary())
m.fit([inputs_1], outputs, epochs=1, batch_size=64, validation_split=0.1)
attention_vectors = []
for i in range(300):
testing_inputs_1, testing_outputs = get_data_recurrent(1, TIME_STEPS, INPUT_DIM)
attention_vector = np.mean(get_activations(m,
testing_inputs_1,
print_shape_only=True,
layer_name='attention_vec')[0], axis=2).squeeze()
print('attention =', attention_vector)
assert (np.sum(attention_vector) - 1.0) < 1e-5
attention_vectors.append(attention_vector)
attention_vector_final = np.mean(np.array(attention_vectors), axis=0)
# plot part.
import matplotlib.pyplot as plt
import pandas as pd
pd.DataFrame(attention_vector_final, columns=['attention (%)']).plot(kind='bar',
title='Attention Mechanism as '
'a function of input'
' dimensions.')
plt.show()
相關推薦
AngularJS進階(三十九)基於專案實戰解析ng啟動載入過程
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
AngularJS進階 三十九 基於專案實戰解析ng啟動載入過程
基於專案實戰解析ng啟動載入過程 前言 在AngularJS專案開發過程中,自己將遇到的問題進行了整理。回過頭來總結一下angular的啟動過程。 下面以實際專案為例進行簡要講解。 1.載入ng庫 &
基於OpenLayers實戰地理資訊系統(離線地圖,通過基站轉經緯度,Quartz深入,軌跡實戰)
我這裡有套課程想和大家分享,需要的朋友可以加我qq和我聯絡。QQ2059055336. 一、本課程是怎麼樣的一門課程(全面介紹) 1.1、課程的背景 OpenLayers是一個用於開發WebGIS客戶端的JavaScript包。 地理地圖眾多方案實現的對比:
基於OpenLayers實戰地理資訊系統視訊
看到大家都在找尋關於基於Openlayers實戰地理資訊系統的視訊,小編在此共享,但是由於可能會涉及版權的問題,請勿廣泛傳播,謝謝!我將視訊上傳到了360雲盤上,需要的朋友請留言... 第一講:概述 第二講:龐雜的GIS體系概覽 第三講:專案快速實戰
電子書 flaskweb開發:基於Python的Web應用開發實戰.pdf
商業 機器 免費 影評 而且 視頻軟件 python程序 規範 初級 作為PythonWeb開發的微框架,Flask獨樹一幟。它不會強迫開發者遵循預置的開發規範,為開發者提供了自由度和創意空間。 《圖靈程序設計叢書·Flask Web開發:基於Python的Web應用開
Android實戰簡易教程-第二十六槍(基於ViewPager實現微信頁面切換效果)
stat addview data android tid des viewpage 聊天 == 1.頭部布局文件top.xml:<?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:and
【推薦系統實戰】:C++實現基於用戶的協同過濾(UserCollaborativeFilter)
color style popu ted std 相似度 abi ear result 好早的時候就打算寫這篇文章,可是還是參加阿裏大數據競賽的第一季三月份的時候實驗就完畢了。硬生生是拖到了十一假期。自己也是醉了。。。找工作不是非常順利,希望寫點東西回想一下知識。然後再
Linux實戰第五篇:RHEL7.3下Nginx虛擬主機配置實戰(基於別名)
虛擬主機 nginx個人筆記分享(在線閱讀):http://note.youdao.com/noteshare?id=05daf711c28922e50792c4b09cf63c58PDF版本下載http://down.51cto.com/data/2323313本文出自 “人才雞雞” 博客,請務必保留此出處
機器學習之分類問題實戰(基於UCI Bank Marketing Dataset)
表示 般的 機構 文件 cnblogs opened csv文件 mas htm 導讀: 分類問題是機器學習應用中的常見問題,而二分類問題是其中的典型,例如垃圾郵件的識別。本文基於UCI機器學習數據庫中的銀行營銷數據集,從對數據集進行探索,數據預處理和特征工程,到學習
selenium自動化實戰-基於python語言(二: 編寫腳本)
獲取 pat 打開 border 命令 需要 框架 attribute 一個 上一篇文章說到顯示等待和隱式等待語句,我們繼續學習下面的命令方法。 8. 定位一組元素 這裏書上是自己寫了一個頁面代碼,通過訪問本地這個頁面來舉例。但我覺得找一個現有的頁面自己琢磨更有意思,而且
下載基於大數據技術推薦系統實戰教程(Spark ML Spark Streaming Kafka Hadoop Mahout Flume Sqoop Redis)
大數據技術推薦系統 推薦系統實戰 地址:http://pan.baidu.com/s/1c2tOtwc 密碼:yn2r82課高清完整版,轉一播放碼。互聯網行業是大數據應用最前沿的陣地,目前主流的大數據技術,包括 hadoop,spark等,全部來自於一線互聯網公司。從應用角度講,大數據在互聯網領域主
基於ASP.NET WebAPI OWIN實現Self-Host項目實戰
hosting 知識 工作 develop plist 簡單 eba 直接 sock 引用 寄宿ASP.NET Web API 不一定需要IIS 的支持,我們可以采用Self Host 的方式使用任意類型的應用程序(控制臺、Windows Forms 應用、WPF 應
nginx基於域名的虛擬主機配置實戰
linux背景: 在www虛擬主機站點基礎上新增一個bbs虛擬主機站點。1 備份配置文件[[email protected]/* */ conf]# pwd /application/nginx/conf [[email protected]/* */ conf]#
基於centos7.3安裝部署jewel版本ceph集群實戰演練
集群 ceph 一、環境準備安裝centos7.3虛擬機三臺由於官網源與網盤下載速度都非常的慢,所以給大家提供了國內的搜狐鏡像源:http://mirrors.sohu.com/centos/7.3.1611/isos/x86_64/CentOS-7-x86_64-DVD-1611.iso在三臺裝好的
企業實戰-實現基於LVS負載均衡集群的電商網站架構
企業實戰 lvs lnmp 實現LVS-DR工作模式:環境準備:一臺centos系統做DR、兩臺實現過基於LNMP的電子商務網站機器名稱IP配置服務角色備註lvs-serverVIP:172.17.252.110DIP:172.17.250.223負載均衡器開啟路由功能(VIP橋接)rs01RIP
企業實戰(4)-實現基於Haproxy負載均衡集群的電子商務網站架構
haproxy keepalived 企業實戰:逐步實現企業各種情景下的需求企業情景四:隨著公司業務的發展,公司負載均衡服務已經實現四層負載均衡,但業務的復雜程度提升,公司要求把mobile手機站點作為單獨的服務提供,不在和pc站點一起提供服務,此時需要做7層規則負載均衡,運維總監要求,能否用一種服務
iKcamp|基於Koa2搭建Node.js實戰(含視頻)? 代碼分層
如果 讓我 span module input 數據 listen else nod 視頻地址:https://www.cctalk.com/v/15114923889408 文章 在前面幾節中,我們已經實現了項目中的幾個常見操作:啟動服務器、路由中間件、Get 和 Po
Linux實戰第八篇:CentOS7.3下Nginx虛擬主機配置實戰(基於端口)
基於 sub 主機配置 centos7.3 entos ada .com 版本 fad 個人筆記分享(在線閱讀): http://note.youdao.com/noteshare?id=9a8b56ec54800ccf197eb6c23de55a85&sub=2E3048
PK2153-BAT大牛親授 基於ElasticSearch的搜房網實戰
height ear 希望 data- arch http package support nta PK2153-BAT大牛親授 基於ElasticSearch的搜房網實戰 新年伊始,學習要趁早,點滴記錄,學習就是進步! 隨筆背景:在很多時候,很多入門不久的朋友都會問
基於Storm構建實時熱力分布項目實戰
解析 cat django ron 優化 Redis分布式 java並發編程 body code 詳情請交流 QQ 709639943 01、基於Storm構建實時熱力分布項目實戰 02、以慕課網日誌分析為例 進入大數據 Spark SQL 的世界 03、Spri