
目標檢測論文整理
最近開始看一些object detection的文章,順便整理一下思路。排版比較亂,而且幾乎所有圖片都是應用的部落格或論文,如有侵權請聯絡我。
文章閱讀路線參考
目前已完成的文章如下,後續還會繼續補充(其中加粗的為精讀文章):
- RCNN
- Overfeat
- MR-CNN
- SPPNet
- Fast RCNN
- A Fast RCNN
- Faster RCNN
- FPN
- R-FCN
- Mask RCNN
- YOLO
- YOLO 9000
- YOLO v3
- SSD
- DSSD
- R-SSD
- RetinaNet(focal loss)
- DSOD
- Cascade R-CNN
(待續)
吐槽一下,部落格園的markdown竟然沒有補齊功能,我還是先在本地補全再傳上來吧。。。
Histogram of Gradient (HOG) 特徵
在深度學習應用之前,影象的特徵是人工定義的具有魯棒性的特徵,如SIFT,HOG等,下面簡要介紹一下HOG。
8x8畫素框內計算方向梯度直方圖: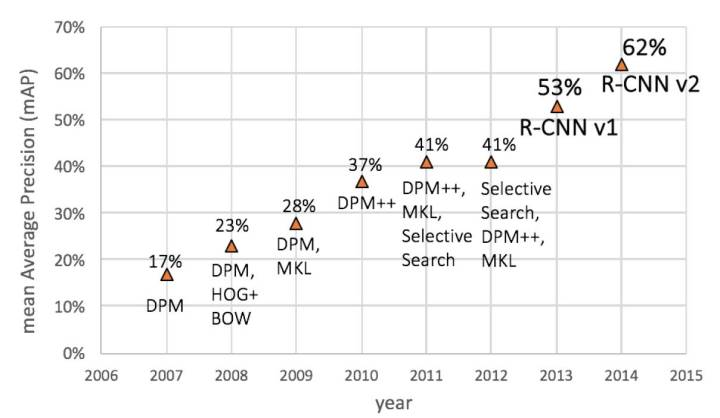
HOG Pyramid
特徵金字塔,對於不同大小的物體進行適應,設計尺度不變性特徵

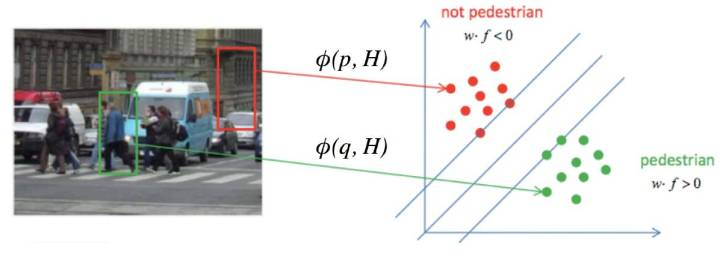
HOG特徵 -> SVM分類
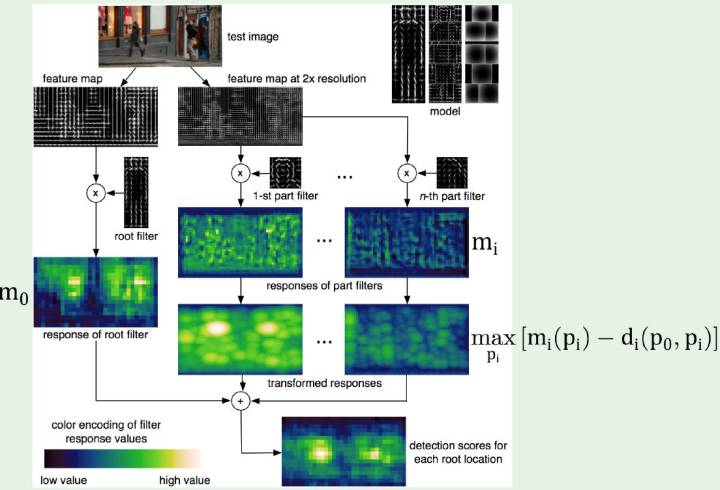
DPM模型 Deformable Part Model
加元件組合的HOG特徵, 元件間計算彈性得分,優化可變形引數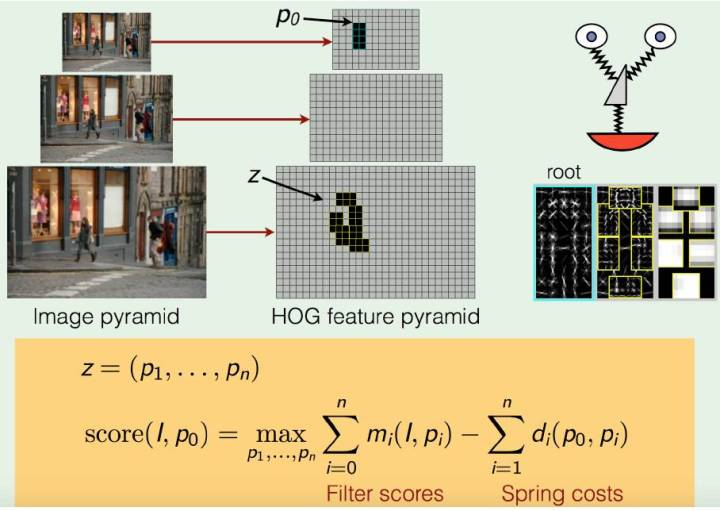
如果沒有彈性距離,就是BoW (Bag of Word)模型, 問題很大, 位置全部丟失:

n個元件的DPM計算流程:
Selective Search 思想
過分割後基於顏色紋理等相似度合併,
然後,過分割、分層合併、建議區域排序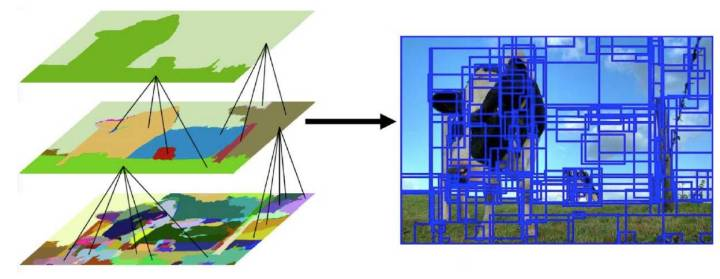
基於Selective Search + DPM/HoG + SVM的物體識別
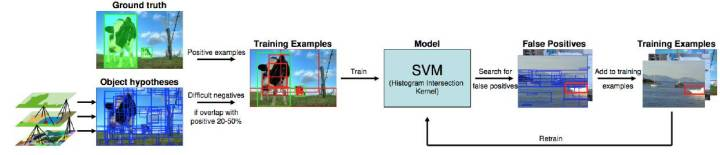
此時的框架就是RCNN的雛形,因為DPM就是基本由RBG和他導師主導,所以大神就是大神。
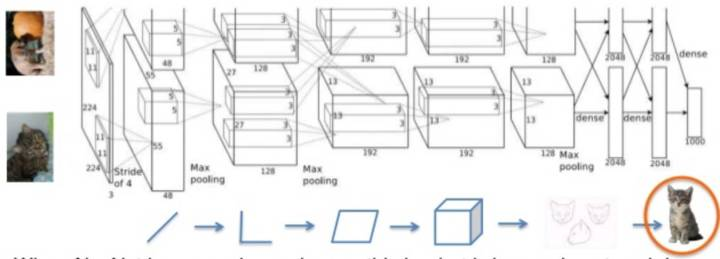
AlexNet的影象分類(深度學習登場)
2012年AlexNet贏得LSVRC的ImageNet分類競賽。深度CNN結構用來影象特徵提取。
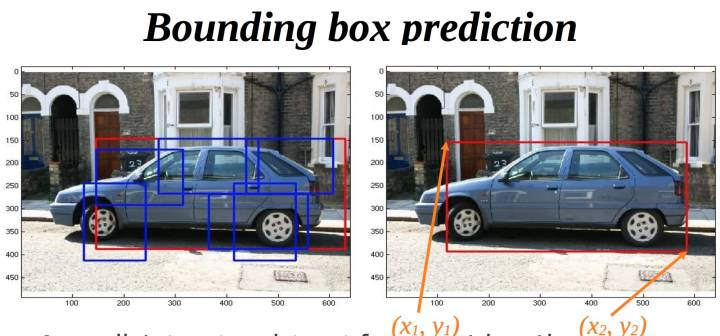
bounding-box regression 框迴歸
BBR 在DPM時代就和SVM分類結合,一般直接使用線性迴歸,或者和SVR結合
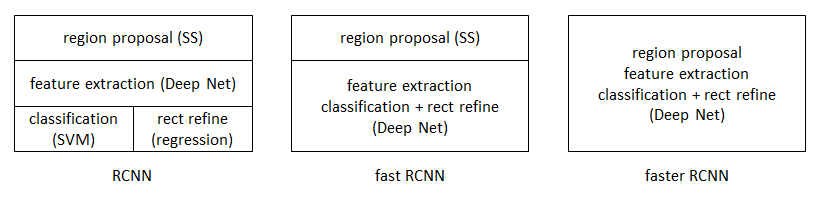
RCNN: Rich feature hierarchies for accurate object detection and semantic segmentation
RCNN作為深度學習用於目標檢測的開山之作,可以看出是基於Selective Search + DPM/HoG + SVM框架,只不過將是將手工特徵轉變為CNN提取特徵,本文主要貢獻如下:
- CNN用於object detection
- 解決資料集不足的問題
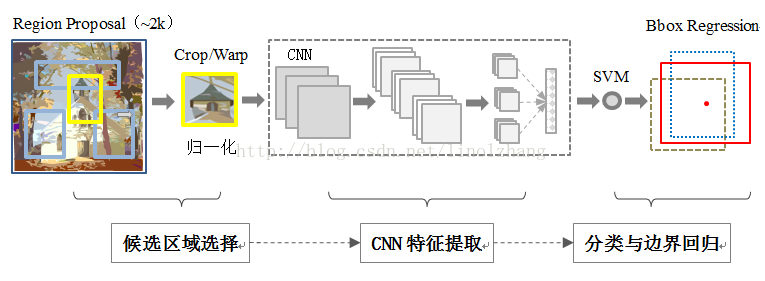
主要流程如下:
regional preposals(selective research)
CNN feature extraction
SVM Classification
NMS
bounding-box regression(BBR)
為啥能work?
- 優秀的目標檢測框架,region proposal 和 regression offset降低了目標檢測的難度,
- 強大的CNN特徵提取器,代替傳統的已經到瓶頸的手工特徵
- 遷移訓練降低了對資料集的要求
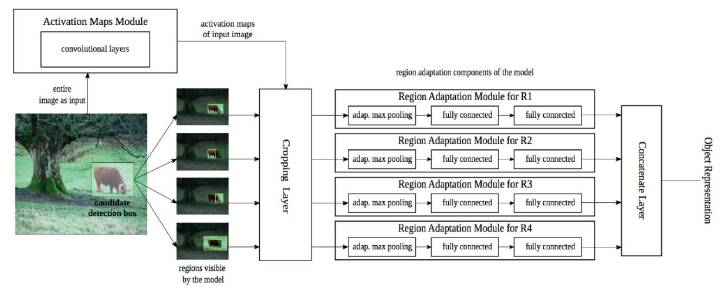
MR-CNN:Object detection via a multi-region & semantic segmentation-aware CNN model
Multi-Region的提出, 開始對Box進一步做文章, 相當於對Box進一步做增強,希望改進增強後的效果,主要改善了部分重疊交叉的情況。

特徵拼接後使得空間變大,再使用SVM處理, 效果和R-CNN基本類似.
OverFeat:Integrated Recognition, Localization and Detection using Convolutional Networks
不得不說雖然OverFeat在但是比賽成績不是太好,但是它的思想還是很有啟發性的。
OverFeat直接拋棄了Selective Search,採用CNN上slide windows來進行框推薦,並且把Bounding box Regression整合一起使用全連線層搞定, 解決了後面一端的問題(取代了SVM分類器和BBR線性迴歸器),這個思想影響了後來的Fast RCNN。是第一個End to End 的目標檢測模型,模型雖然簡陋,但是可以驗證網路強大的擬合能力注意整合目標檢測的各項功能(分類,迴歸)。
亮點:
- 先用CNN得到feature map再做slide windows推薦區域,避免了特徵重複計算。
- 設計了End to End模型,方便優化和加快檢測速度
- 設計全卷積網路,並進行多尺度影象訓練
- maxpool offset(沒有Fast RCNN的ROI Pooling自然)
為啥能work?
可以看出OverFeat將不同的兩個問題物體分類和位置迴歸採用了兩個分支網路,共用前面的CNN特徵表述,而CNN提取的特徵正如OverFeat所言,是一種類似於SIFT,HOG等人工描述子的一種穩定的描述子(底層抽象),可以用於構建不同的任務(高層表述),也就是模型為什麼能work的原因。
SPPNet
R-CNN和Overfeat都存在部分多尺度,重疊效果的問題。 某種意義上, 應對了HoG特徵, 這樣對於物體來說類似BoW模型, 我們知道DPM裡面,是帶有元件空間分佈的彈性得分的, 另外也有HoG Pyramid的思想。 如何把Pyramid思想和空間限制得分加入改善多尺度和重疊的效果呢? MR-CNN裡面嘗試了區域增強, Overfeat裡面嘗試了多尺度輸入。 但是效果都一般。 這裡我們介紹另外一個技術Spatial Pyramid Matching, SPM,是採用了空間尺度金字塔的特點。和R-CNN相比做到了先特徵後區域, 和Overfeat相比自帶Multi-Scale。
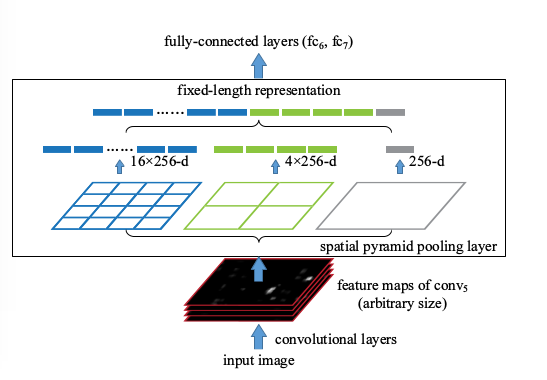
SPP pooling layer 的優勢:
- 解決了卷積層到全連線層需要固定圖片大小的問題,方便多尺度訓練。
- 能夠對於任意大小的輸入產生固定的輸出,這樣使得一幅圖片的多個region proposal提取一次特徵成為可能。
- 進一步強調了CNN特徵計算前移, 區域處理後移的思想, 極大節省計算量
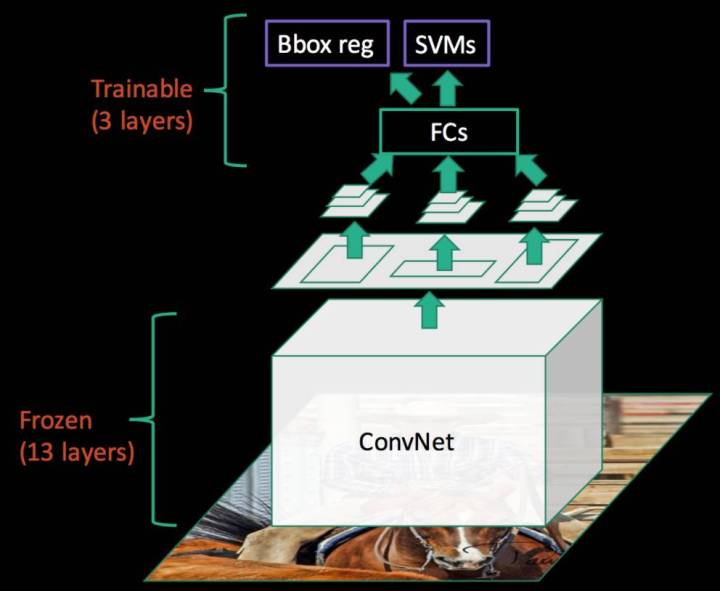
也能看出文章還是強呼叫CNN做特徵的提取,還是用的BBR和SVM完成迴歸和分類的問題
Fast RCNN
可以看出Fast RCNN結合了OverFeat和Sppnet的實現,打通了高層表述和底層特徵之間的聯絡

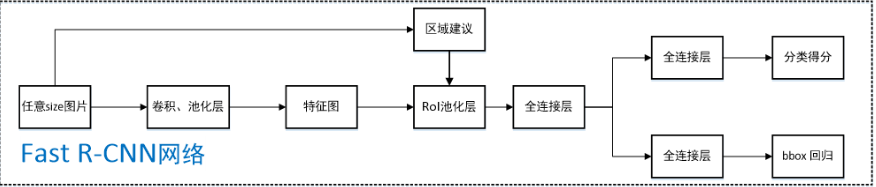
主要流程:
任意size圖片輸入CNN網路,經過若干卷積層與池化層,得到特徵圖;
在任意size圖片上採用selective search演算法提取約2k個建議框;
根據原圖中建議框到特徵圖對映關係,在特徵圖中找到每個建議框對應的特徵框【深度和特徵圖一致】,並在RoI池化層中將每個特徵框池化到H×W【VGG-16網路是7×7】的size;
固定H×W【VGG-16網路是7×7】大小的特徵框經過全連線層得到固定大小的特徵向量;
將上一步所得特徵向量經由各自的全連線層【由SVD分解實現(全連線層加速)】,分別得到兩個輸出向量:一個是softmax的分類得分,一個是Bounding-box視窗迴歸;
利用視窗得分分別對每一類物體進行非極大值抑制剔除重疊建議框
其中ROI POOL層是將每一個候選框對映到feature map上得到的特徵框經池化到固定的大小,其次用了SVD近似求解實現全連線層加速。
這裡需要注意的一點,作者在文中說道即使進行多尺度訓練,map只有微小的提升,scale對Fast RCNN的影響並不是很大,反而在測試時需要構建影象金字塔使得檢測效率降低。這也為下一步的多尺度改進埋下了伏筆。
為啥能更好的work?
也是結合了OverFeat的和SPPnet的work,同時規範了正負樣本的判定(之前由於SVM和CNN對區域樣本的閾值劃分不同而無法統一網路,當然這只是其中的一個原因。更多的估計是作者當時沒想到),將網路的特徵抽取和分類迴歸統一到了一個網路中。
A Fast RCNN: Hard Positive Generation via Adversary for Object Detection
這篇論文是對,CMU與rbg的online hard example mining(OHEM)改進,hard example mining是一個針對目標檢測的難例挖掘的過程,這是一個更充分利用資料集的過程。實際上在RCNN訓練SVM時就已經用到,但是OHEM強調的是online,即如何在訓練過程中選擇樣本。同期還有S-OHEM的改進。
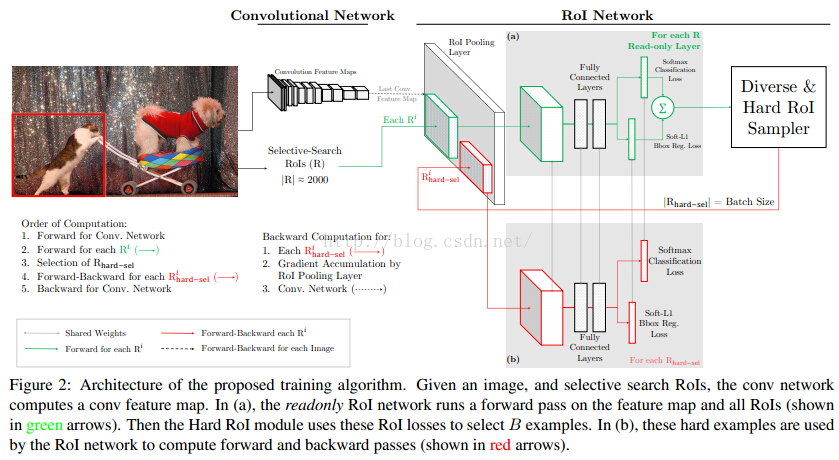
而隨著但是GAN的火熱,A-Fast-RCNN嘗試生成hard example(使用對抗網路生成有遮擋和有形變的兩種特徵,分別對應網路ASDN和ASTN)
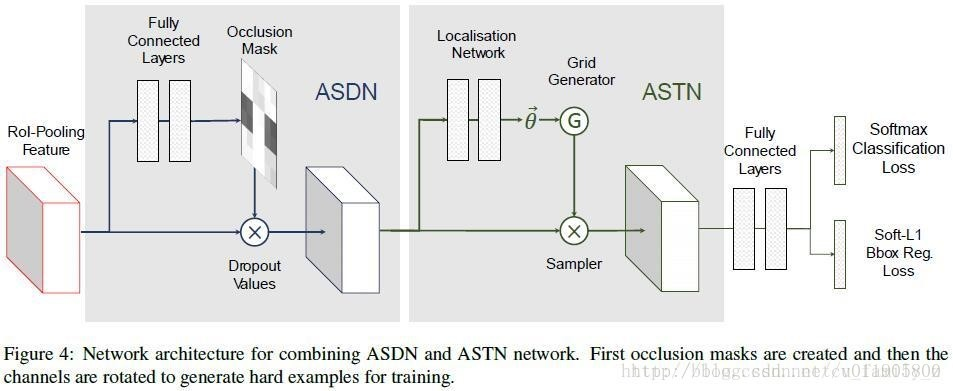
結論如下:
ASTN 和 隨機抖動(random jittering)做了對比,發現使用AlexNet,mAP分別是58.1%h和57.3%,使用VGG16,mAP分別是69.9%和68.6%,ASTN 的表現都比比隨機抖動效果好。作者又和OHEM對比,在VOC 2007資料集上,本文方法略好(71.4% vs. 69.9%),而在VOC 2012資料集上,OHEM更好(69.0% vs. 69.8%)。gan用於目標檢測還沒有很好的idea,這篇論文相當於拋磚引玉了。
同時需要注意的一個問題,網路對於比較多的遮擋和形變情況識別情況更好;但是對於正常目標的特徵抽象能力下降,所以有時候創造難例也要注意樣本的數量。下面是一些由於遮擋原因造成的誤判。

Faster RCNN:Towards Real-Time Object Detection with Region Proposal Networks
這篇文章標誌著two-stage目標檢測的相對成熟,其主要改進是對候選區域的改進,將候選區域推薦整合進了網路中。
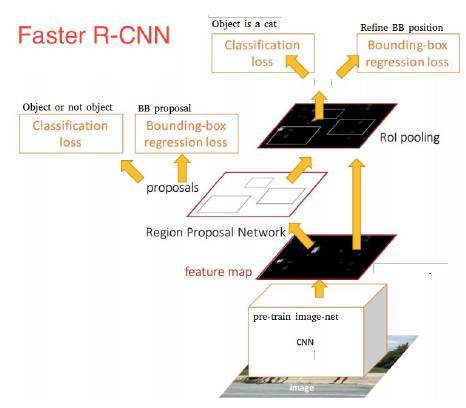
結合後面的一系列文章,可以馬後炮一下它的缺點:
- 雖然Faster RCNN已經共享了絕大部分卷積層運算,但是RoI之後還有部分ConvNet的計算,有沒有可能把ROI之上的計算進一步前移? 請看R-FCN
- Faster RCNN還是沒有很好的解決多尺度問題,如何解決,請看FPN
YOLO:You Only Look Once
作者的論文簡直是一股論文界的泥石流,作者本身是一個喜歡粉紅小馬的大叔,萌萌噠。實際上YOLO一直髮展到v3都是簡單粗暴的目標檢測方法,雖然學術界模型繁雜多樣,但是在實際應用工業應用上YOLO絕對是一個首選的推薦。YOLO v1版本現在看來真是簡單粗暴,也印證了網路抽象的強大之處。可以看出作者沒有受到太多前輩的影響,將物件檢測重新定義為單個迴歸問題,直接從影象畫素到邊界框座標和類概率(當然這也是一個缺少座標約束也是一個缺點)。

YOLO的明顯缺點,如多尺度問題,密集物體,檢測框耦合,直接回歸座標等在yolo 9000中也做了比較好的改進。
SSD:Single Shot MultiBox Detector
SSD作為one stage的代表模型之一,省去了判斷推薦候選區域的步驟(實際上可以認為one-stage就是以feature map cell來抽象代替ROI Pooling功能) ,雖然SSD和Faster RCNN在Anchor box上一脈相承,但是Faster RCNN卻還是有一個推薦候選區域(含有物體的區域)的監督部分(注意後面其實也是整合到了最終Loss中),因此one-stage優勢是更快,而含有區域推薦的two-stage目前是更加準確一些。(更看好one-stage,其實區域推薦不太符合視覺系統,但是可以簡化目標檢測問題),主要貢獻:
- 用多尺度feature map來預測,也生成了更多的default box
- 檢測框對每一類物件產生分數(低耦合,對比yolo)

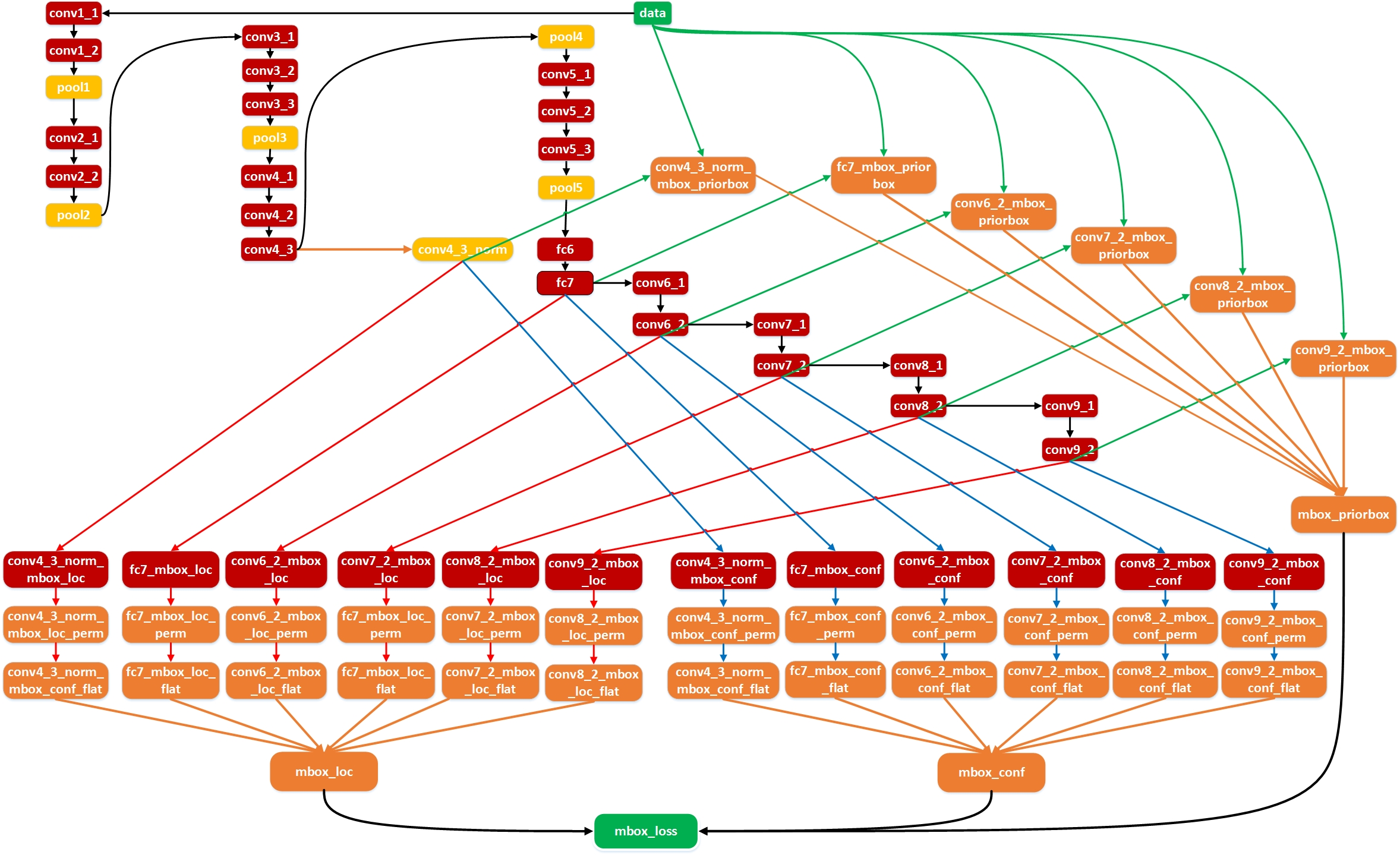
缺點:
- 底層feature map高階語義不足 (FPN)
- 正負樣本影響 (focal loss)
- feature map抽象分類和迴歸任務只用了兩個卷積核抽象性不足(DSSD)
為啥能更好的工作?
SSD的出現對多尺度目標檢測有了突破性進展,利用卷積層的天然金字塔形狀,設定roi scale讓底層學習小物體識別,頂層學習大物體識別
FPN:feature pyramid networks
SSD網路引入了多尺度feature map,效果顯著。那Faster RCNN自然也不能落後,如何在Faster RCNN中引入多尺度呢?自然有FPN接面構
同時FPN也指出了SSD因為底層語義不足導致無法作為目標檢測的feature map
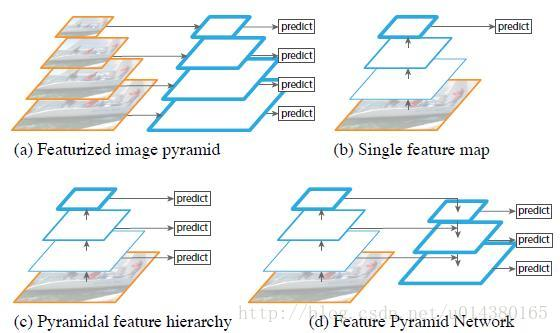
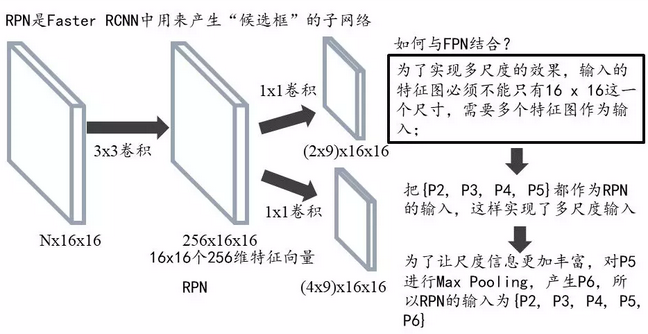
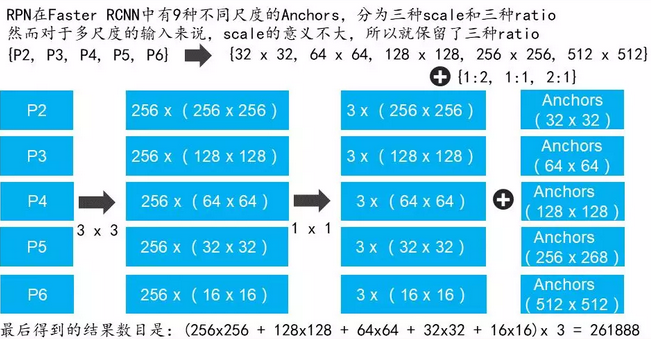
注意原圖的候選框在Faster RCNN中只固定對映到同一個ROI Pooling中,而現在如果某個anchor和一個給定的ground truth有最高的IOU或者和任意一個Ground truth的IOU都大於0.7,則是正樣本。如果一個anchor和任意一個ground truth的IOU都小於0.3,則為負樣本。
本文演算法在小物體檢測上的提升是比較明顯的,另外作者強調這些實驗並沒有採用其他的提升方法(比如增加資料集,迭代迴歸,hard negative mining),因此能達到這樣的結果實屬不易。
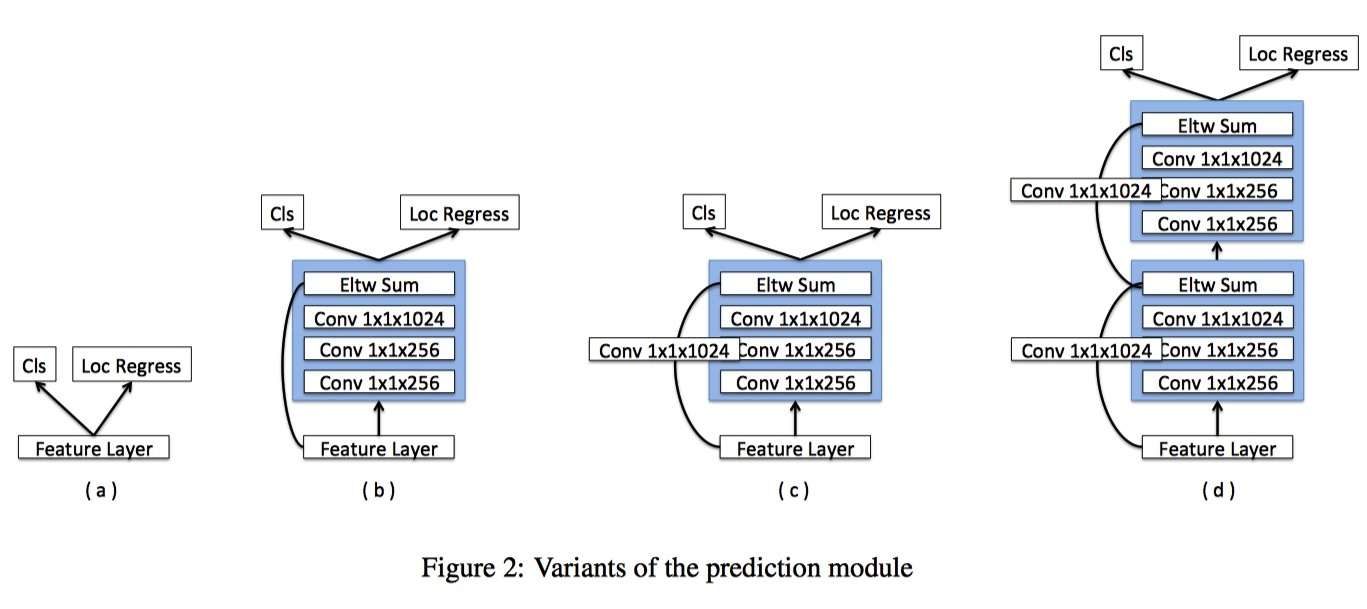
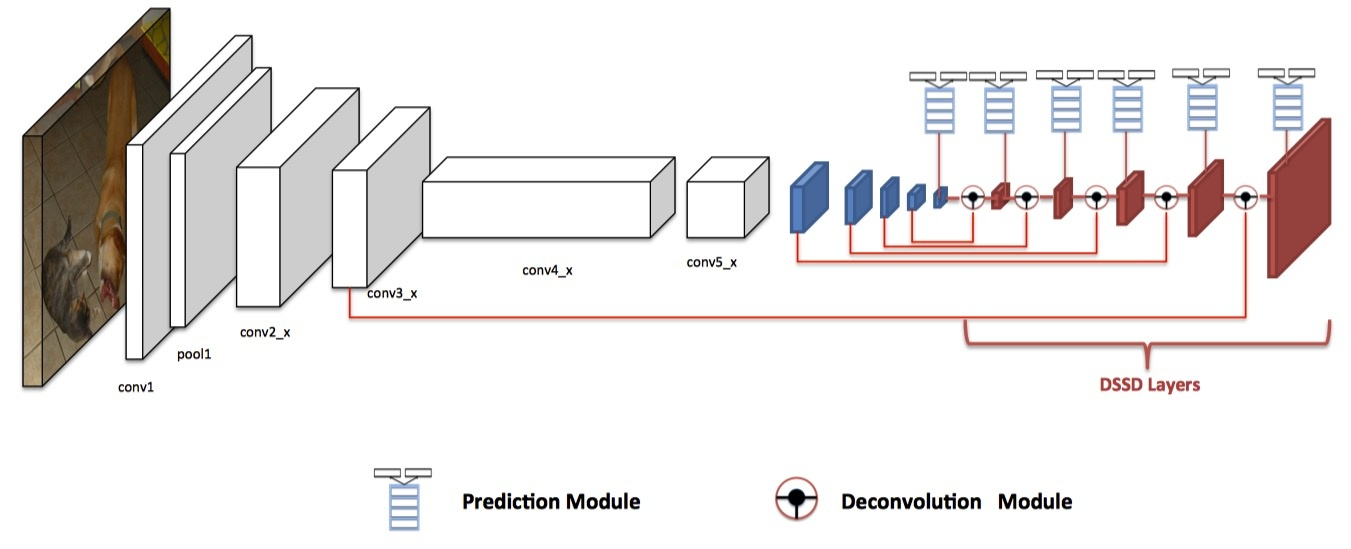
DSSD:Deconvolutional Single Shot Detector
一個SSD上移植FPN的典型例子,作者主要有一下改動:
- 將FPN的Upsampling變成deconv
- 複雜了高層表述分支(分類,迴歸)網路的複雜度
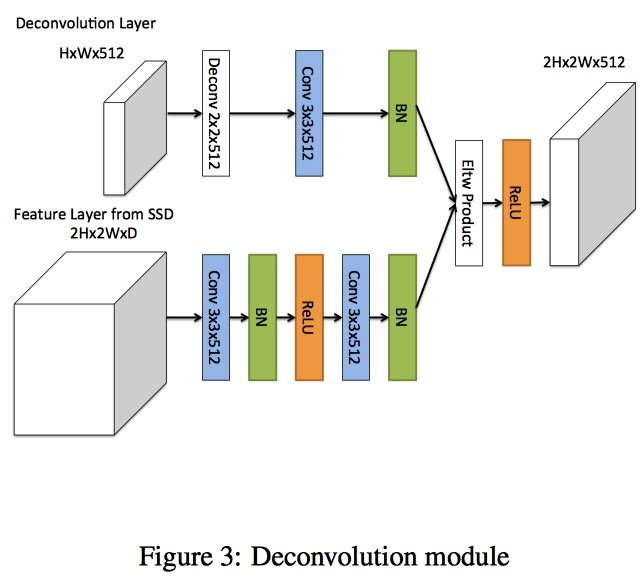
R-SSD:Enhancement of SSD by concatenating feature maps for object detection
本文著重討論了不同特徵圖之間的融合對SSD的影響(水論文三大法寶),這篇論文創新點不是太多,就不說了
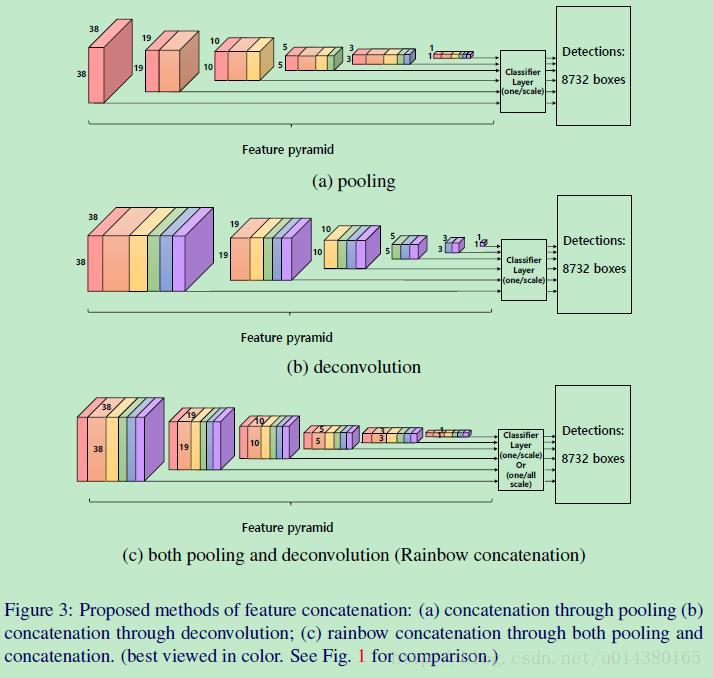
DSOD: Learning Deeply Supervised Object Detectors from Scratch
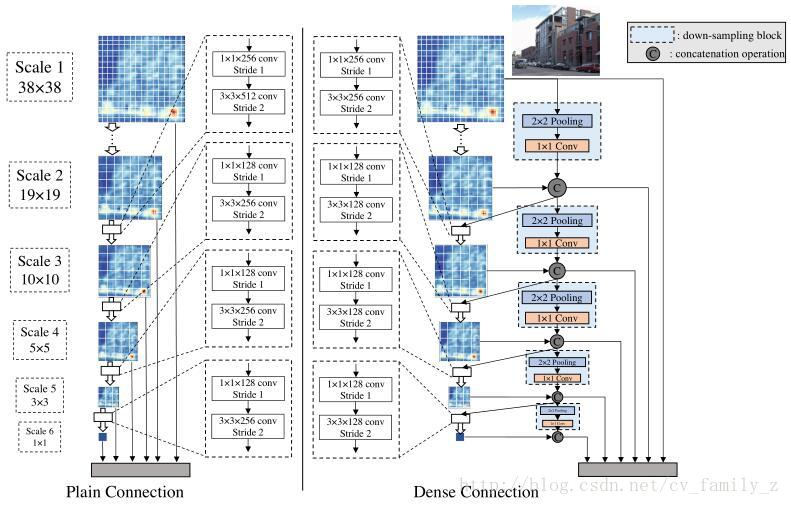
這篇文章的亮點:
- 提出來了不需要預訓練的網路模型
- DSOD實際上是densenet思想+SSD,只不過並不是在base model中採用densenet,而是密集連線提取default dox的層,這樣有一個好處:通過更少的連線路徑,loss能夠更直接的監督前面基礎層的優化,這實際上是DSOD能夠直接訓練也能取得很好效果的最主要原因,另外,SSD和Faster RCNN直接訓練無法取得很好的效果果然還是因為網路太深(Loss監督不到)或者網路太複雜。
- Dense Prediction Structure 也是參考的densenet
- stem能保留更多的資訊,好吧,這也行,但是對效果還是有提升的。

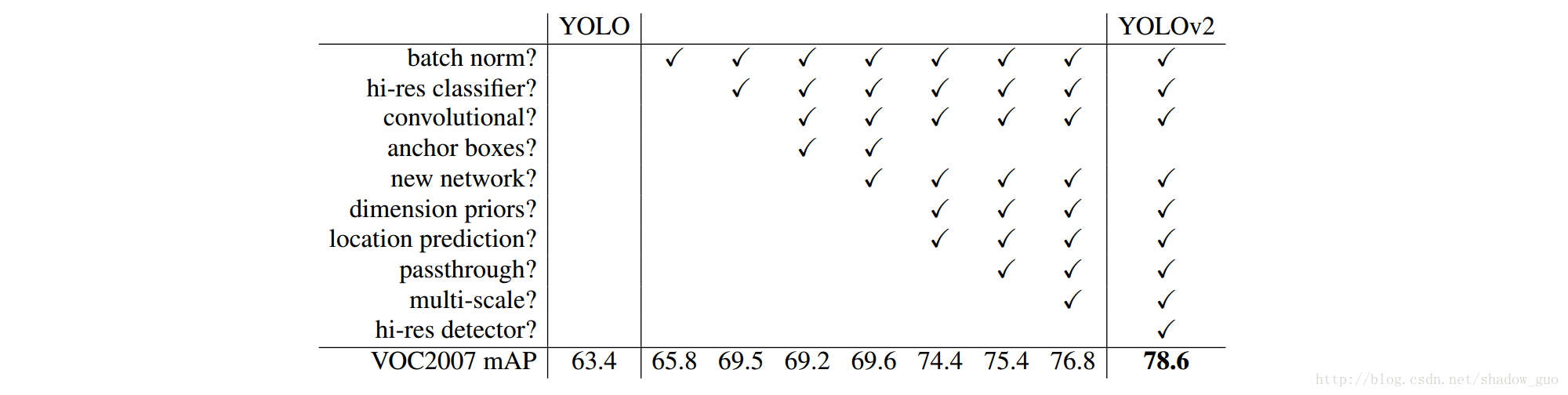
YOLO 9000:Better, Faster, Stronger
很喜歡這個作者的論文風格,要是大家都這麼寫也會少一點套路,多一點真誠。。。。文章針對yolo做了較多的實驗和改進,簡單粗暴的列出每項改進提升的map。這個建議詳細的看論文。下面列舉幾個亮點:
- 如何用結合分類的資料集訓練檢測的網路來獲得更好的魯棒性
- 將全連線層改為卷積層並結合了細粒度資訊(passthrough layer)
- Multi-Scale Traning
- Dimension Clusters
- darknet-19更少的引數
- Direct locaion prediction對offset進行約束

R-FCN:Object Detection via Region-based Fully Convolutional Networks
本文提出了一個問題,base CNN網路是為分類而設計的(pooling 實際上是反應了位置的不變性,我一張人臉圖片只要存在鼻子,兩隻眼睛,分類網路就認為它是人臉,這也就是Geoffrey Hinton 在Capsule中吐槽卷積的缺陷),而目標檢測則要求對目標的平移做出準確響應。Faster RCNN是通過ROI pooling讓其網路學習位置可變得能力的,再次之前的base CNN還是分類的結構,之前講過R-FCN將Faster RCNN ROI提取出來的部分的卷積計算共享了,那共享的分類和迴歸功能的卷積一定在劃分ROI之前,那麼問題來了,如何設計讓卷積對位置敏感?
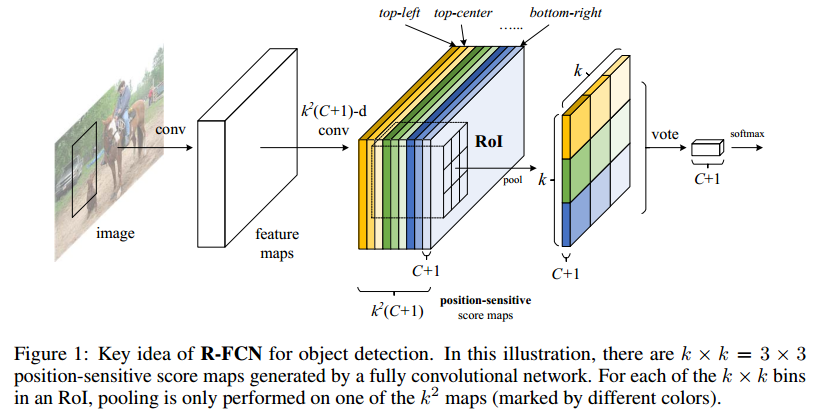
主要貢獻:
- 將用來回歸位置和類別的卷積前置共享計算,提高了速度。
- 巧妙設計score map(feature map)的意義(感覺設計思想和yolo v1最後的全連線層一樣),讓其何以獲得位置資訊,之後在經過ROI pooling和vote得到結果
為啥能work?
實際上rfcn的feature map設計表達目標檢測問題的方式更加抽象(ROI pool前的feature map中每一個cell的channel代表定義都很明確),loss在監督該層時更能通過論文中關於ROI pool和vote設計,在不同的channel上獲得高的響應,這種設計方式可能更好優化(這個是需要大量的實驗得出的結論),至於前面的resnet-base 自然是抽象監督,我們本身是無法理解的,只是作為fintuning。實際上fpn的loss監督也是非常淺和明確的,感覺這種可以理解的優化模組設計比較能work。
這篇文章實際上提供了另外一個角度,之前一直認為Single stage detector結果不夠好的原因是使用的feature不夠準確(使用一個位置上的feature),所以需要Roi Pooling這樣的feature aggregation辦法得到更準確的表示。但是這篇文章基本否認了這個觀點,提出Single stage detector不好的原因完全在於:
極度不平衡的正負樣本比例: anchor近似於sliding window的方式會使正負樣本接近1000:1,而且絕大部分負樣本都是easy example,這就導致下面一個問題:gradient被easy example dominant的問題:往往這些easy example雖然loss很低,但由於數 量眾多,對於loss依舊有很大貢獻,從而導致收斂到不夠好的一個結果。
所以作者的解決方案也很直接:直接按照loss decay掉那些easy example的權重,這樣使訓練更加bias到更有意義的樣本中去。很直接地,如下圖所示:
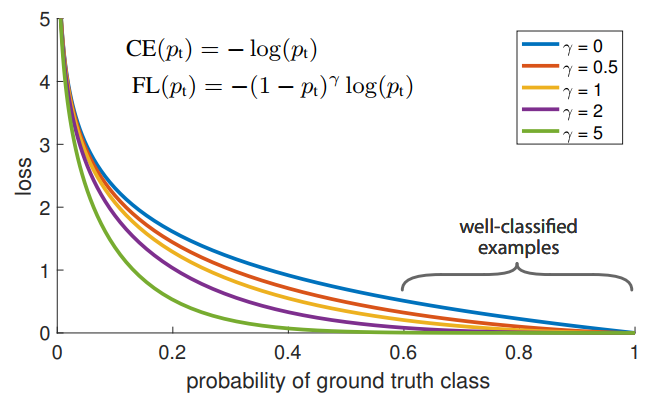
實驗中作者比較了已有的各種樣本選擇方式:- 按照class比例加權重:最常用處理類別不平衡問題的方式
- OHEM:只保留loss最高的那些樣本,完全忽略掉簡單樣本
OHEM+按class比例sample:在前者基礎上,再保證正負樣本的比例(1:3)
Focal loss各種吊打這三種方式,coco上AP的提升都在3個點左右,非常顯著。值得注意的是,3的結果比2要更差,其實這也表明,其實正負樣本不平衡不是最核心的因素,而是由這個因素匯出的easy example dominant的問題。
RetinaNet 結構如下
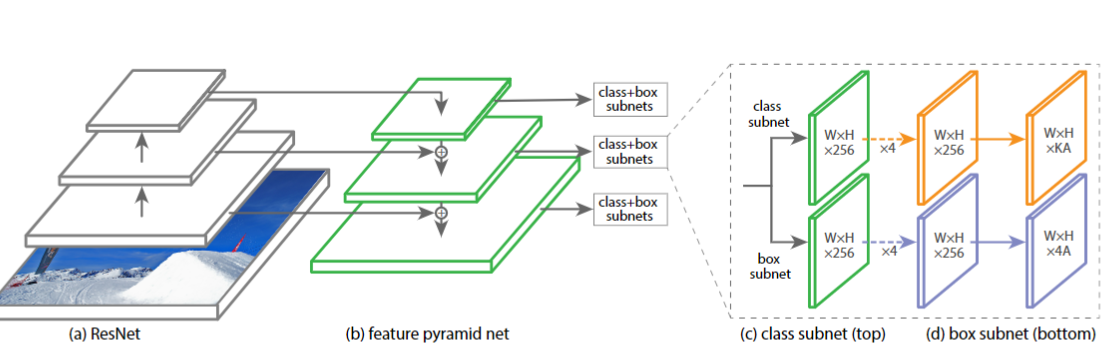
實際上就是SSD+FPN的改進版
Cascade R-CNN Delving into High Quality Object Detection
相關推薦
目標檢測論文整理
最近開始看一些object detection的文章,順便整理一下思路。排版比較亂,而且幾乎所有圖片都是應用的部落格或論文,如有侵權請聯絡我。 文章閱讀路線參考 目前已完成的文章如下,後續還會繼續補充(其中加粗的為精讀文章): RCNN Overfeat MR-CNN SPPNet Fast RCNN A
Faster R-CNN:利用區域提案網路實現實時目標檢測 論文翻譯
Faster R-CNN論文地址:Faster R-CNN Faster R-CNN專案地址:https://github.com/ShaoqingRen/faster_rcnn 摘要 目前最先進的目標檢測網路需要先用區域提案演算法推測目標位置,像SPPnet1和Fast R-CNN2
顯著目標檢測論文(二) —— FASA: Fast, Accurate, and Size-Aware Salient Object Detection
當初讀這篇論文的時候, 第一感覺是寫的很難讀懂, 倒不是說演算法思想層面的東西難懂, 而是英文語法層面很難準確理解一句話的含義. 在這裡對論文思路做一個梳理. 本文的目標是清楚地描述論文的核心思想, 但又不陷入翻譯論文的套路. 如有一些不合適的觀點, 還請各位看
目標檢測論文Cascade R-CNN: Delving into High Quality Object Detection
轉自:https://zhuanlan.zhihu.com/p/36095768 Cascade R-CNN: Delving into High Quality Object Detection 論文連結:https://arxiv.org/abs/1712.00726 程式碼連結:htt
CVPR2018 目標檢測演算法總覽(最新的目標檢測論文)
CVPR2018上關於目標檢測(object detection)的論文比去年要多很多,而且大部分都有亮點。從其中挑了幾篇非常有意思的文章,特來分享,每篇文章都有詳細的部落格筆記,可以點選連結閱讀。 1、Cascaded RCNN 論文:Cascade R-CNN De
基於神經網路的目標檢測論文之神經網路基礎:神經網路的優化方法
注:本文源自本人的碩士畢業論文,未經許可,嚴禁轉載! 原文請參考知網:知網地址 本章節有部分公式無法顯示,詳見原版論文 2.4 神經網路的優化方法 2.4.1 過擬合與規範化 物理學家費米曾說過,如果有四個引數,我可以模擬一頭大象,而如果有五個引數,我還能讓他卷
基於神經網路的目標檢測論文之目標檢測系統:實時路況檢測系統的設計與實現
注:本文源自本人的碩士畢業論文,未經許可,嚴禁轉載! 原文請參考知網:知網地址 第五章 實時路況檢測系統的設計與實現 物體識別技術被廣泛應用於人們的生產生活中。隨著深度學習與雲端計算的飛速發展,帶動了物體識別技術產生質的飛躍。高解析度影象和檢測的實時性要求越來越
SSD目標檢測論文簡讀
本文簡單綜合性地介紹一下SSD,SSD文章內容資訊較多,若有失誤之處,望能熱心指出,感謝. SSD框架介紹: 演算法的主網路結構是VGG16,將兩個全連線層改成卷積層(Conv6與Conv7)再增加4個卷積層構成網路結構。然後對6個特徵圖使用3*3卷積濾波器(k*
目標檢測論文閱讀:Relation Networks for Object Detection
Relation Networks for Object Detection 論文連結:https://arxiv.org/abs/1711.11575 程式碼連結:暫無,尚不清楚是否會公開 這個是CVPR 2018的文章,雖然並沒有什麼巧妙的設
目標檢測論文閱讀:Cascade R-CNN: Delving into High Quality Object Detection
Cascade R-CNN: Delving into High Quality Object Detection 樣本減少引發的過擬合 在train和inference使用不一樣的閾值很容易導致mismatch(這一點在下面會有解釋) 作者為
目標檢測論文閱讀:Deformable Convolutional Networks
ans 過程 上層 適合 其他 簡易 基礎上 可能 代碼 https://blog.csdn.net/qq_21949357/article/details/80538255 這篇論文其實讀起來還是比較難懂的,主要是細節部分很需要推敲,尤其是deformable的卷積如何實
2016CVPR目標檢測論文簡介
目標檢測的指標: 1)識別精度 2)識別效率 3)定位準確性 CVPR2016專題: CVPR/ICCV目標檢測最新論文 2016年的CVPR目標檢測(這裡討論的是2D的目標檢測)的方法主要是 基於CNN的框架,代表性的工作有 Res
目標檢測論文閱讀:RFB Net
Receptive Field Block Net for Accurate and Fast Object Detection 1. Background 這篇論文要解決的問題很簡單,作為單階段的檢測方法,它試圖尋找速度和精度之間的平衡,就像之前很多sing
2018 2D目標檢測論文跟蹤
CVPR2018Cascade R-CNN: Delving into High Quality Object Detection, Zhaowei Cai, Nuno VasconcelosRelat
目標檢測論文回顧
看了一段時間的目標檢測的論文,在這裡寫個文章總結一下吧。不一定理解正確,如有問題,歡迎指正。 1、RCNN RCNN是基於selective search(SS) 搜尋Region proposal(RP),然後對每個RP進行CNN的Inference,
【顯著性目標檢測】CVPR2018 顯著性檢測領域論文整理解讀(Salient Object Detection)
前言:CVPR2018會議論文集已經公示(CVPR2018全部論文集連結),本文對顯著性目標檢測領域的6篇進行了整理,將這幾篇論文的主體思想彙總起來,供大家一起學習。 一、論文列表: 1.《Flow Guided Recurrent Neural Enc
【目標檢測】Cascade R-CNN 論文解析
都是 org 檢測 rpn 很多 .org 實驗 bubuko pro 目錄 0. 論文鏈接 1. 概述 @ 0. 論文鏈接 Cascade R-CNN 1. 概述 ??這是CVPR 2018的一篇文章,這篇文章也為我之前讀R-CNN系列困擾的一個問題提供了一個解決方案
經典論文重讀---目標檢測篇(二):Fast RCNN
核心思想 RCNN的缺點 R-CNN is slow because it performs a ConvNet forward pass for each object proposal, without sharing computation. SPPnet的缺
經典論文重讀---目標檢測篇(一):RCNN
核心思想 Since we combine region proposals with CNNs, we call our method R-CNN: Regions with CNN features. 即將生成proposal的方法與cnn提取特徵進行結合
==1==rcnn/fast_rcnn/faster_rcnn/mask_rcnn (目標檢測與目標例項分割 論文理解)
@TOC 原文連結 mask_rcnn paper 原文連結 r_cnn 原文連結 fast_rcnn 原文連結 FPN opencv 4.0 程式碼-mask_rcnn 深度學習筆記1 R_CNN 說明 Ross Girshick 2014年提出的,第一次用CNN卷