目標檢測論文回顧
看了一段時間的目標檢測的論文,在這裡寫個文章總結一下吧。不一定理解正確,如有問題,歡迎指正。
1、RCNN
RCNN是基於selective search(SS) 搜尋Region proposal(RP),然後對每個RP進行CNN的Inference,這個演算法比較直接。
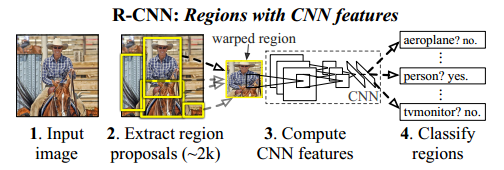
框架應該也挺容易看明白的。
SS對每幅圖片提取大約2K個RP,然後對RP進行推理。
2、SPPNET
RCNN的計算很多是沒有必要的,因為框有重疊啊,既然被計算過,何必再有讓別的框再計算呢?於是Computation Sharing開始了。

conv5以前的計算,對於一幅圖片只需要一次進行。
另外,SPPNET主要有三個貢獻:
(1)SPP可以產生固定大小的特徵,這使得輸入圖片可以是任意大小的。為什麼呢?作者發現,在CNN當中,其實出了全連線以外,其他的層基本不需要固定大小。既然如此,那就讓全連線之前的計算適應任何尺寸吧,只要在到達全連線的時候,讓它固定尺寸就好啦!怎麼做呢?就是圖中的SPP。將影象以不同的pooling步長,得到固定長度的pooling結果。
(2)SPP使用多水平的空間bins,同時保持滑動窗的大小不變,這樣可以對目標的變形比較魯棒。
(3)得益於多變的輸入影象尺寸,SPP可以做到不同尺度的Pooling。
問題:SPPNet仍然是多部訓練的,主要原因是:SPP層是多尺度的,對於後面傳過來的梯度來說,它計算梯度時涉及到的Receptive Field比較大,計算很慢。而且後面使用的分類器是SVM,應該來說是比較耗時的吧。其實SPPNET訓練時,是先用SS找到RP,然後輸入前面層,把特徵存起來,然後在把特徵載入進來輸入後面層,前面層的訓練和後面層的訓練是分離的。
fast RCNN
這篇文章就是針對SPPNET中的問題做的,主要貢獻有:
提出了ROIPooling。這個ROIPooling其實就是SPP的簡化版。SPP不是使用了金字塔,導致梯度傳遞困難嗎?那就只用一層的金字塔吧。不行,還得換個名字,那就叫ROIPooling。使用了ROIPooling後,得到的也是一個統一尺寸的特徵,梯度也沒有以前那樣涉及到的感受野那麼大,所以前後就可以連起來訓練了。
多工Loss。以前SPPNET不是Bounding Box(BB)迴歸和分類是分離的嗎?這裡就用一個多工的Loss吧。而且分類器也不要SVM這麼複雜了,只需要Softmax。
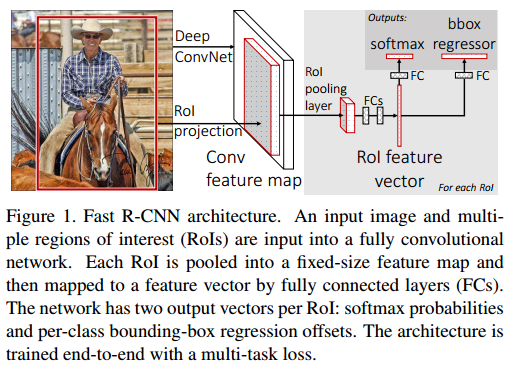
問題:這個也其實有問題的,你看SS在裡面不是一直沒有參與學習嗎?而且SS好像是離線計算的吧?(這個需要再考證一下。)還有一個重要的問題是,後面的BB迴歸和分類網路再強,你也是受SS提取的RP限制的。也就是說SS可能已經成為了瓶頸。
Faster-RCNN
這篇文章其實也是承接上文的,fast RCNN不是受SS限制沒法端到端地訓練嗎?那就做一個網路來代替SS唄。這就是Faster-RCNN重點 RPN。但是RPN怎麼做呢?
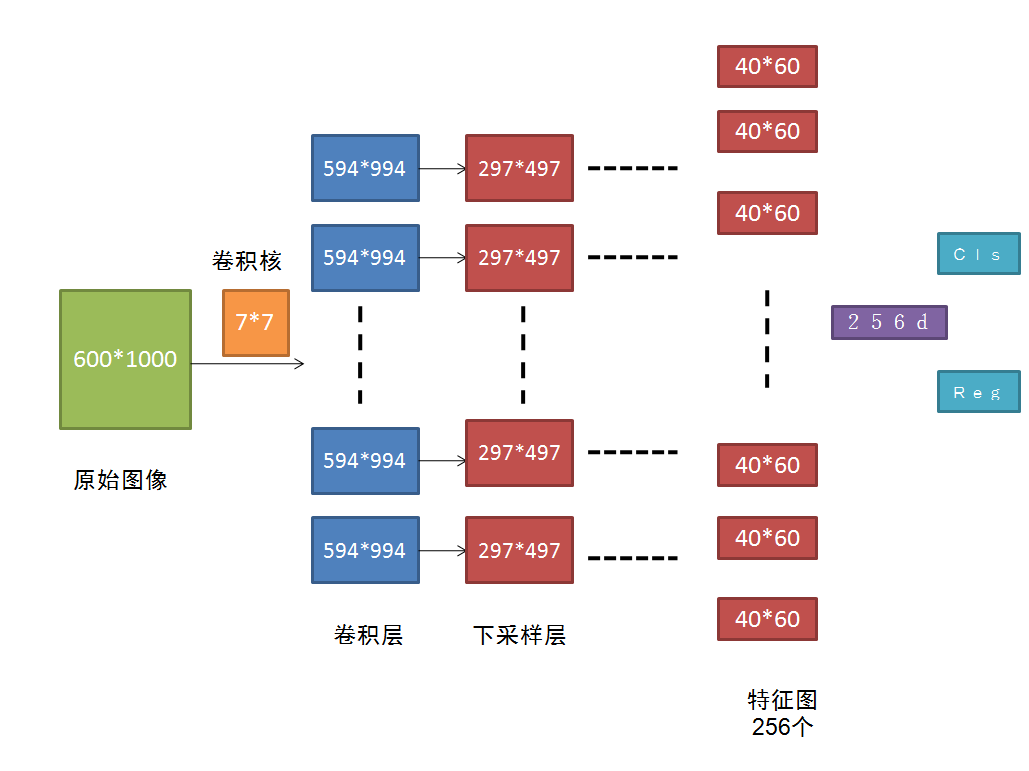
把原始圖進行多次卷積後,得到的256個40*60的feature map,接下來就用一個小的卷積神經網路在這些feature map上滑動,這裡有講解。為了獲得一定的尺度不變形,使用了Anchor的方式,也就是對每一個RP進行多個尺寸的變換,文章使用了9.這樣,對於一個40*60的來說,總共有40*60*9個RP,還是非常多的。
這裡還有個東西可能沒說清楚,就是RPN的輸出是什麼?在每一個視窗上,RPN輸出的是一個256維的特徵。256怎麼來的呢?就是在256個feature map上對應位置分別卷積哈。
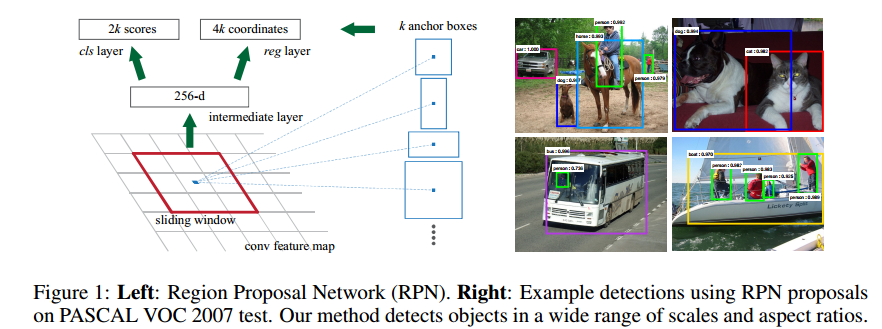
後面的分類和迴歸也是採用的全連線做的。
這樣用來做RP的計算,其實也是被BB迴歸和分類共享的,因為他們的輸入就是這個256d的特徵啊。
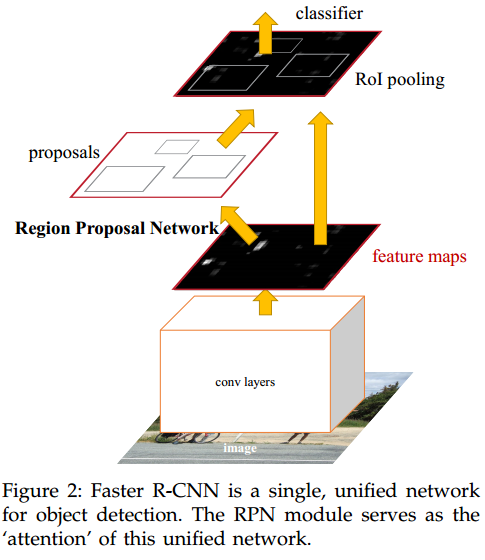
問題:這個計算複雜度還是太高了,沒法達到實時性要求。
YOLO
這個網路最大的優勢就在於快,怎麼做到的呢?首先,那些共享計算的概念肯定是要用到的。然後就是把影象分塊。
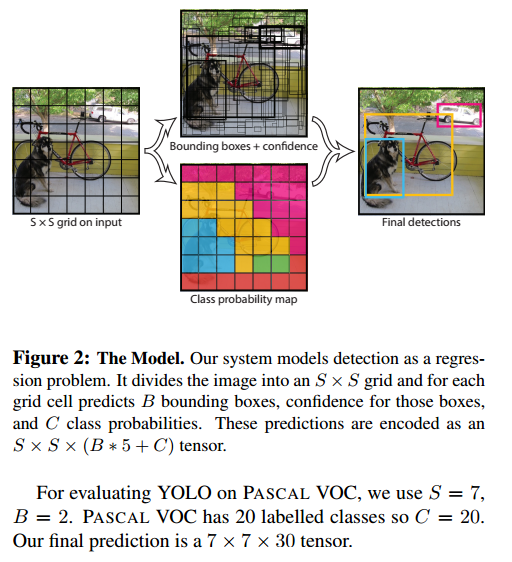
圖片被分成了 S*S個格子,每個格子預測出B個BB,而每個BB包含了5個量: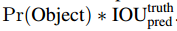
還有每個格子對這C個類的預測分。
在Test階段,
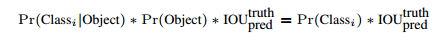
這樣不就得到了目標的概率嗎?真是不錯啊!
下面是網路結構:
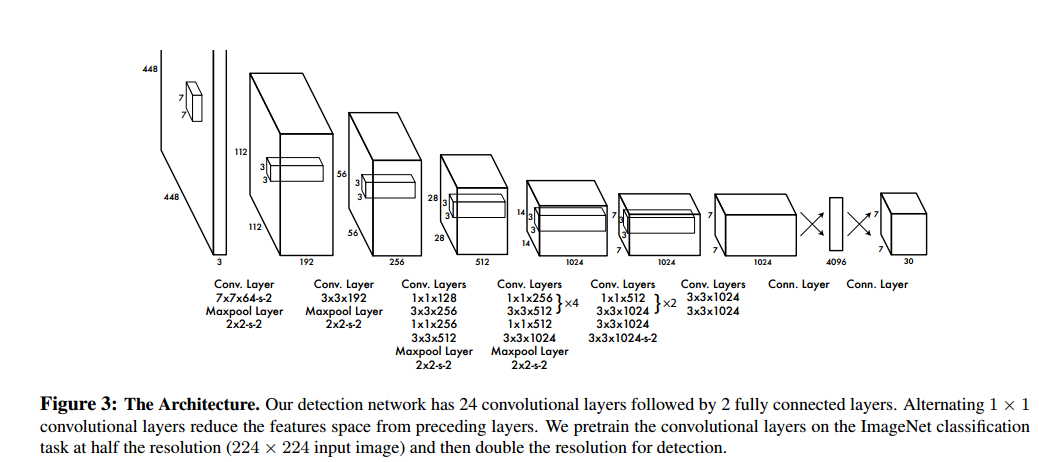
YOLO思想和前面RPN很不一樣了,現在不需要RPN了吧,就直接這麼訓練就好了。但是還是有問題吧,如果一個格子裡面包含了多個目標,那豈不是隻能迴歸是其中一個,而且應該是最明顯的一個。這是不是就是YOLO對小目標檢測很不理想啊,因為小目標在後面層中的feature本來就少。而且SSD雖然快,但是目標檢測的效果卻並不是令人滿意。
SSD
雖然YOLO效果不佳,但是其開創性的Look once的想法還是很值得讚揚和紀念的。SSD繼承了YOLO這個工作,並把它拓展開來了。
SSD中的Default Box(DB)是一個重要的工作。feature是通過卷積等操作得到的,那麼feature其實還是具有相對位置資訊的。把feature劃分到不同的DB中,這樣就可以做到和YOLO一樣的效果了吧。但是這個DB是有Anchor的。
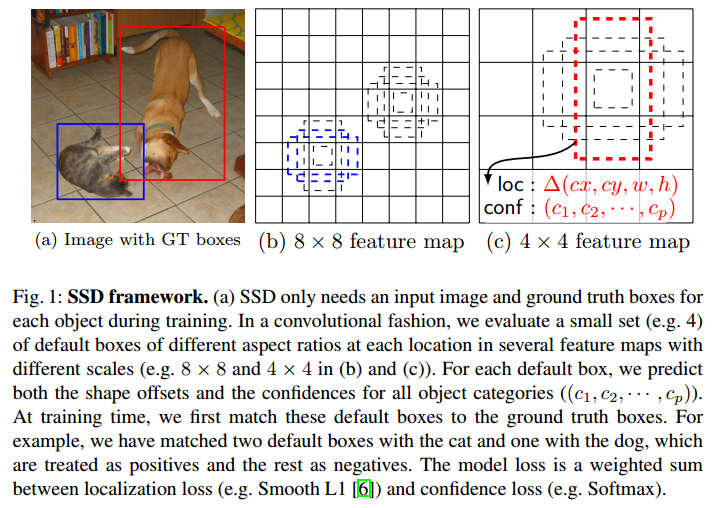
仔細看看這幅圖和裡面的文字吧。就算label和預測的BB是在一個DB裡面,還得看看Anchor是不是吻合的。這樣是不是對於迴歸DB來說更加準確了?
然後看看網路框架吧,這個是和YOLO的一個對比。
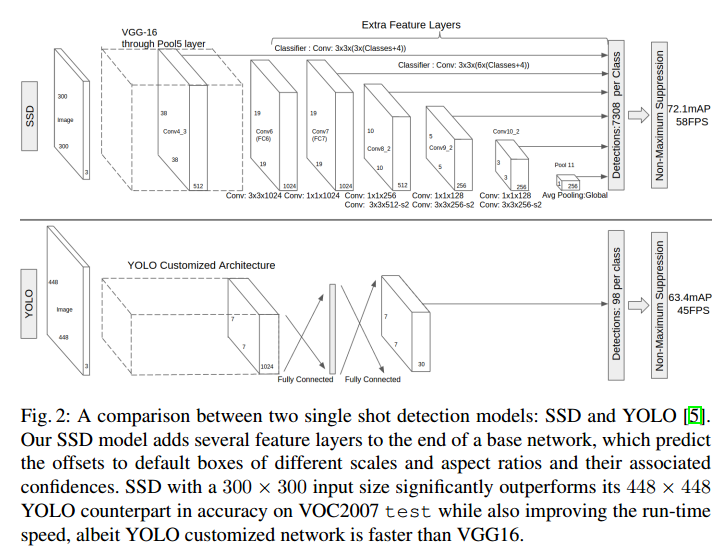
SSD前面的層和YOLO是差不多的,但是後面就不一樣了。YOLO是直接拿著feature map迴歸出BB,還做了分類,SSD是還融合了不同層的特徵。
其實,從SSD可以看出,YOLO並沒有完全利用好共享計算,因為前面層提取的特徵只是用來給下一層作為輸入了啊,但是它還是特徵啊,你就這麼用了一下,其實它還包含了很多有用資訊呢。怎麼這樣說呢?前面層feature map更大,它的細節資訊保留更好。而且,一般而言,前面層偏向於提取邊緣等資訊。邊緣對於視覺來說是非常重要的啊,如果利用起來,肯定能夠有提升吧。當然,這只是一方面。
順便提一下,這個作者另外一篇ParseNet也利用了相似的思想,可以一起看看。
Inside-Outside Network
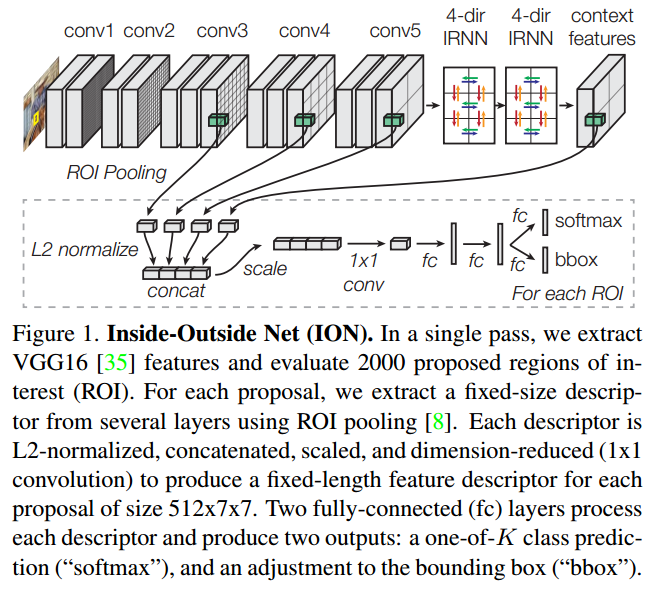
乍一看,這個ION是不是和SSD很像,是的,它也是利用了多層特徵融合的方式來獲得更好的特徵。
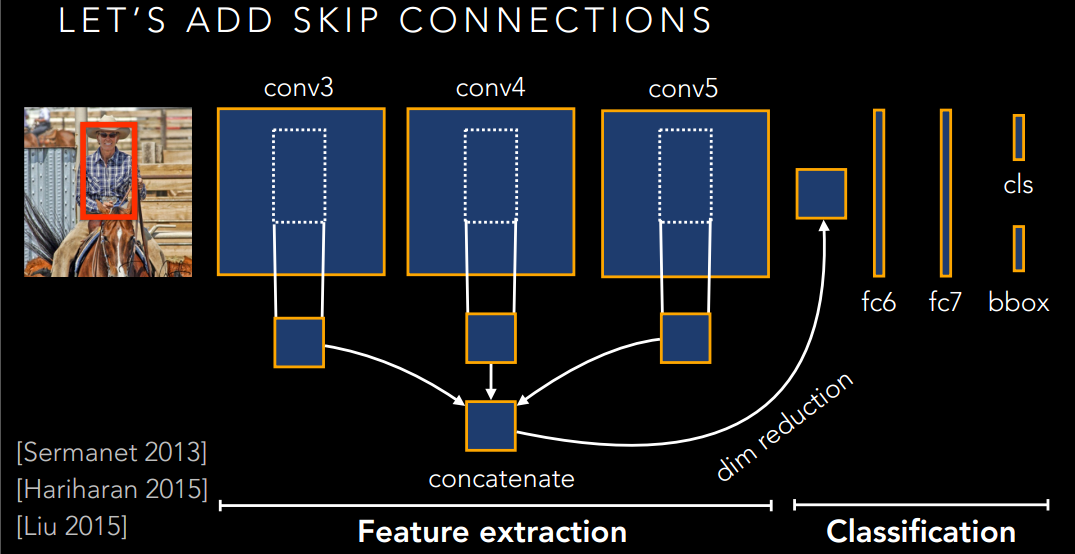
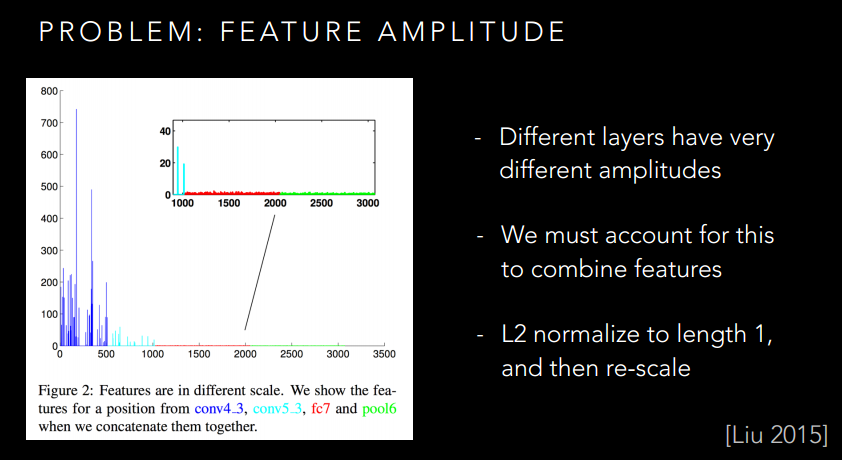
這個Skip-connection就可以很好的利用不同的特徵了。然而,還是有問題的,你想想,不同層的特徵是不是尺度不一樣啊,而且不同層的數值還沒有歸一化呢?如果生搬硬套的湊在一起,是不是有點破壞原本的特徵了,並不一定有很好的提升。
所以作者給出了下面的方法:
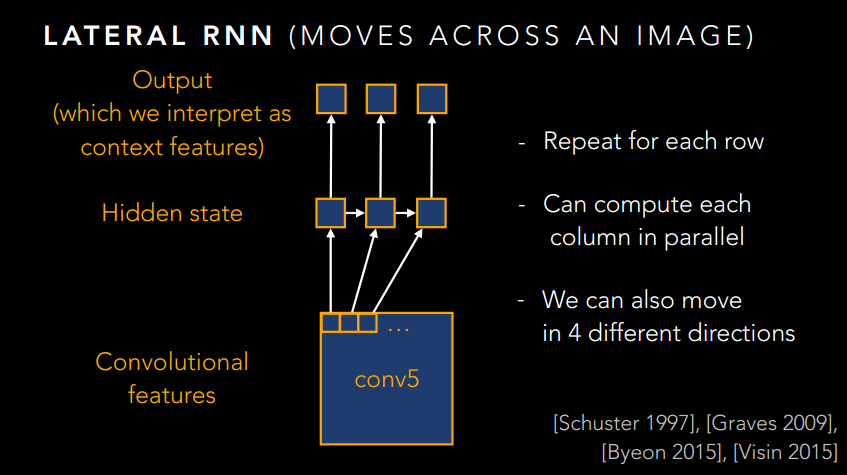
如果僅此而已,那肯定是不能稱之為大作的,肯定要玩出新花樣。想想這個影象其實也是一個序列問題,只不過不是時間序列的,而是空間序列的。那麼,我們是不是可以引入RNN來做點序列化的文章呢?是的,作者就是這麼幹的!
下面就放一些RNN的圖吧,感受一下大神的風采。
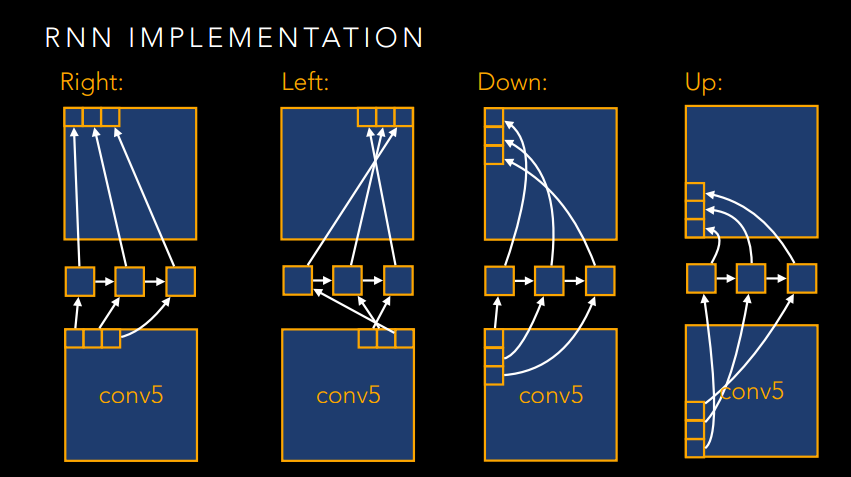
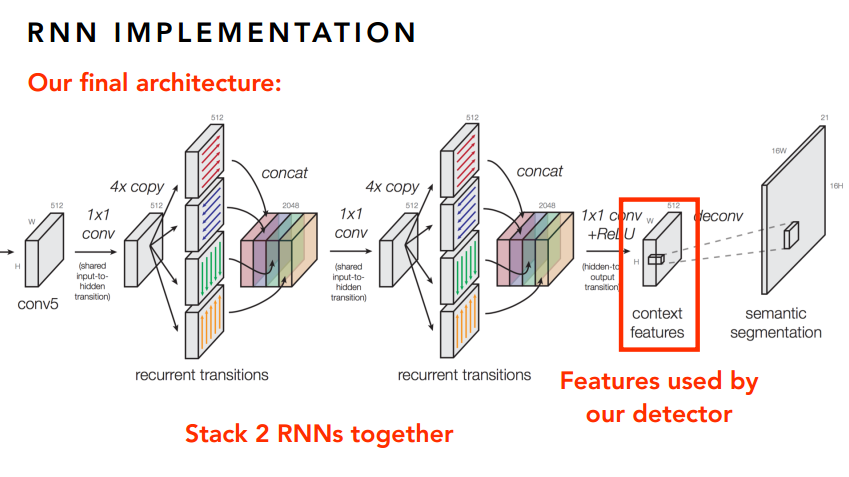
寫在最後
好了,已經把目標檢測的幾篇論文稍微介紹一下了,但是裡面很多細節都沒有去多講,要重現這些論文,肯定少不了看看原文,然後讀下程式碼的。最好是把文章的網路可視化出來看看,一定有個不錯的體會。這裡有個很好的線上視覺化工具哦,有興趣的可以試試。
PS
最後就是求職的事情了。最近一直忙著招工作,卻發現視覺的工作好難找啊!可能是自己學藝不精吧,但是本人一直對視覺有強烈的好奇心和興趣,也希望能夠在視覺這方面做出些成果。所以希望有一個有夢想的團隊能收留我,不一定是要有很高的工資,但是一定要有抱負。另外,如果是做NLP,我也是挺有興趣,只是暫時沒有深入瞭解這方面,如果團隊願意帶,我也挺想學的。好了,囉嗦完了,歡迎評論。
Reference
做一個相當不專業的參考文獻吧,因為找不到工作,實在是有點心累。後面看了更多論文後再補吧。各位客觀見諒。