
Jmeter-提取請求及響應結果並儲存到本地檔案
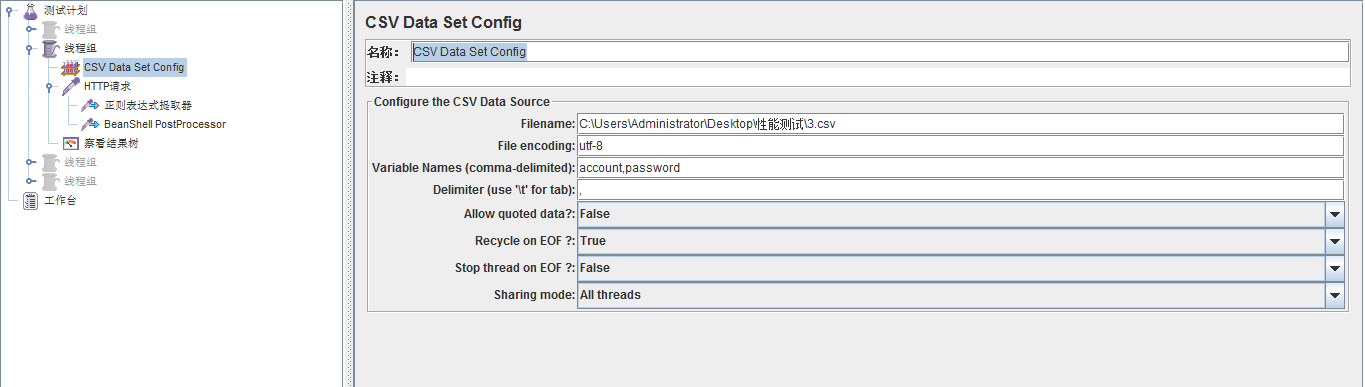
1、新建一個本地csv檔案,存放請求需要使用的變數值account,password,並配置CSV Data Set Config
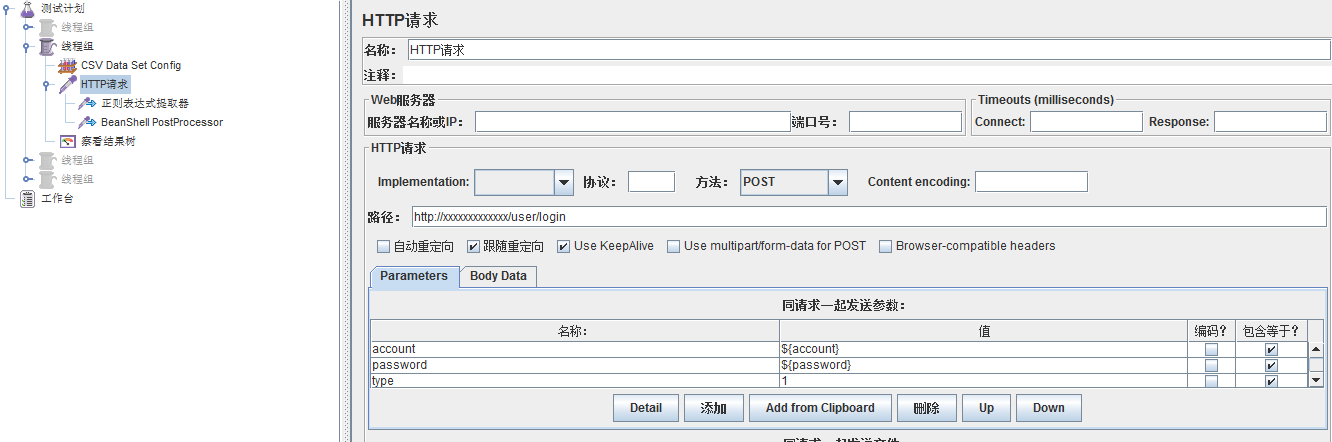
2、新增一個HTTP請求
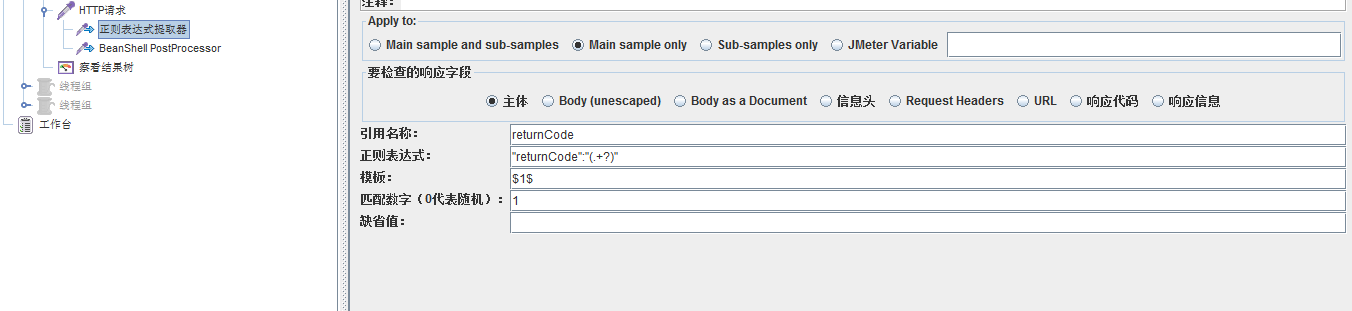
3、新增正則提取器用來提取響應結果中的returnCode
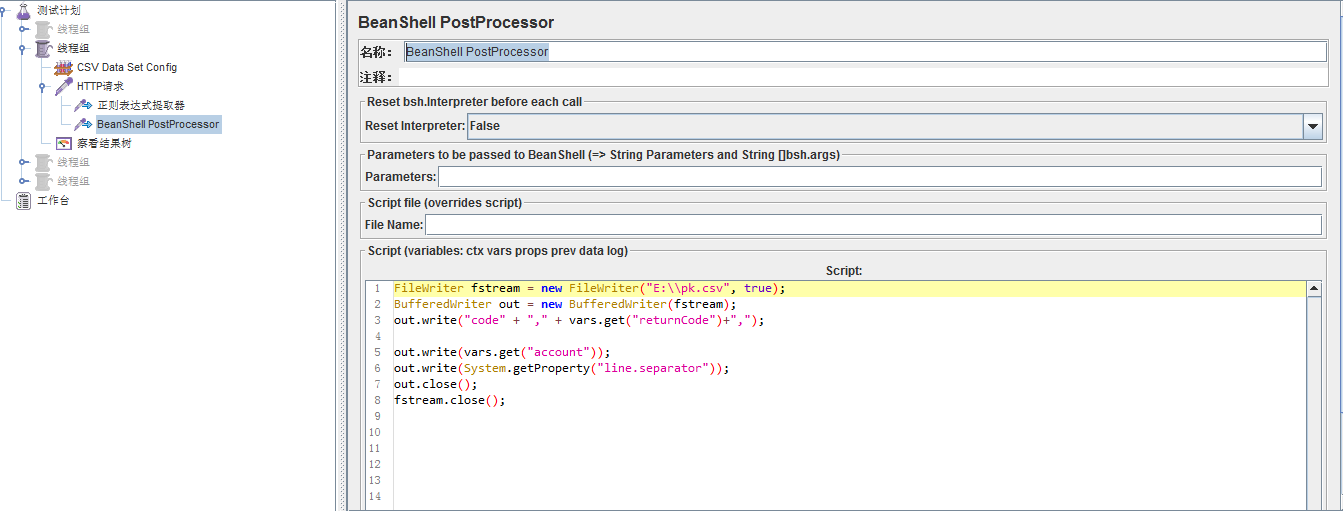
4、在本地新建一個pk.csv檔案,新建一個BeanShell PostProcessor後置處理器,用於提取結果並將之儲存到pk.csv檔案。
相關推薦
Jmeter-提取請求及響應結果並儲存到本地檔案
1、新建一個本地csv檔案,存放請求需要使用的變數值account,password,並配置CSV Data Set Config 2、新增一個HTTP請求3、新增正則提取器用來提取響應結果中的returnCode 4、在本地新建一個pk.csv檔案,新建一個Bean
Jmeter-BeanShell PostProcessor提取請求及響應結果並保存到本地文件
請求 src 響應 http請求 return 變量 ont acc beanshell 1、新建一個本地csv文件,存放請求需要使用的變量值account,password,並配置CSV Data Set Config 2、添加一個HTTP請求 3、添加
Jmeter分析請求的響應結果
問題場景:利用Jmeter同時傳送了n次請求,n次請求都被響應了,比如響應結果是這種格式的 {"status":3} 這個status的值,有可能為1,2,3,這時候我們想統計一下status為1 ,2 ,3的請求分別有多少個。 解決方法:據說beanshell這個東西可
Java編寫爬蟲,並儲存本地檔案,未涉及圖片,視訊的儲存,只是儲存文字內容
Java Jsoup jar包編寫爬蟲 這個案例內容很簡單,只是設計文字的爬取,未涉及到圖片儲存與視訊儲存。記錄下來只是方便自己的一個記錄、同時希望給向我這樣第一次接觸爬蟲的朋友一個參考!! 個人覺得分為兩步走!當然,我寫了三個檔案,內容如下: 一、開始方法 S
shell正則提取字串中的數字並儲存到變數中
1.提取數字到變數 temp = `echo "helloworld20181212 | tr -cd "[0-9]""` echo ${temp} 2.釋義tr -cd "[0-9]" tr是translate的縮寫,主要用於刪除檔案中的控制字元,或者進行字元轉換 &n
PHP封裝一個通用的CURL類方法(設定、獲取請求頭響應頭並處理)
通用的一個CURL類方法,設定請求頭、獲取響應頭等! 包括將格式處理成陣列格式,方便直接輸出 /** * 傳送https post請求,也支援http請求,包括header請求 * @param string $url 請求域名 * @
java傳送http請求獲取響應結果【工具包系列】
import org.apache.commons.httpclient.HttpException; import org.apache.commons.httpclient.NameValuePair; import org.apache.log4j.Logger;
web伺服器開發日記---HTTP請求及響應
HTTP URL (URL是一種特殊型別的URI,包含了用於查詢某個資源的足夠的資訊)的格式如下:http://host[":"port][abs_path] http表示要通過HTTP協議來定位網路資源;host表示合法的Internet主機域名或者IP地址;por
httpbin:測試 HTTP 請求及響應的網站
httpbin這個網站能測試 HTTP 請求和響應的各種資訊,比如 cookie、ip、headers 和登入驗證等,且支援 GET、POST 等多種方法
一次查詢請求及響應的過程
一次請求響應(以查詢為例)的具體的過程:1.客戶端瀏覽器傳送請求到伺服器;伺服器通過客戶端請求的URI傳遞到servlet,sevlet呼叫doGet()或doPost方法;在主管查詢的servlet中這兩個方法的方法體中呼叫Dao;根據Dao執行sql程式碼訪問資料庫,將查
菜鳥寫Python實戰:Scrapy完成知乎登入並儲存cookies檔案用於請求他頁面(by Selenium)
一、前言 現在知乎的登入請求越來越複雜了,通過f12調出瀏覽器網路請求情況分析request引數,似乎不再簡單可知了,因為知乎很多請求引數都字元加密顯示了,如下圖,我們很難再知道發起請求時要傳遞什麼引數給它。 二、思路 我們知道知乎一些內容是需要登入才能看到,因
【Matlab】將avi視訊提取出幀序列圖片並儲存
想要用Matlab提取avi視訊中的幀影象,並儲存成jpg格式 %read video and save every frame as .jpg %obj = VideoReader('D:\data\test_video_3\test_video_3.avi'); ob
shell正則提取字串中的數字並儲存到變數
1.提取數字到變數 temp=`echo "helloworld20180719" | tr -cd "[0-9]" ` echo $temp 輸出 20180719 2.重定向到檔案 echo "helloworld20180719" | tr -cd "[0
XPath:爬取百度貼吧圖片,並儲存本地
使用XPath,我們可以先將 HTML檔案 轉換成 XML文件,然後用 XPath 查詢 HTML 節點或元素。 什麼是XML XML 指可擴充套件標記語言(EXtensible Markup
Go後臺對圖片base64解碼,並儲存至檔案伺服器。
單人開發移動端專案前後端,對專案中出現的一些問題做記錄。 前端使用vue,預設base64編碼上傳圖片,略過。 後臺使用go-gin框架,主要使用了路由和資料傳輸和繫結的功能 1. 後端宣告一個結構體用於接收前端資料和將資料儲存到資料庫(mangodb) 其中ImgList用於接收
Android日誌列印類LogUtils,能夠定位到類名,方法名以及出現錯誤的行數並儲存日誌檔案
關注finddreams,一起分享,一起進步!http://blog.csdn.net/finddreams/article/details/4556
Java檔案上傳資料庫(並儲存本地)、word轉pdf並進行頁面預覽
對於頁面預覽用到了OpenOffice附件: 官方的下載地址:Apache OpenOffice 選擇windows版本安裝完成後,在cmd中執行下面兩個命令,檢視工作管理員中是否有soffice.bin的程序。(用到OpenOffice,必須保證工作管理員中有
【優化版】Java檔案上傳資料庫(並儲存本地)、word轉pdf並進行頁面預覽
上一篇檔案上傳【點選跳轉】,是將路徑等檔案資訊存進log_file臨時表,內容二進位制存入資料庫Test表,這種邏輯是在呼叫資料庫表Test內容展示時,判斷檔案為word(轉換成pdf)還是pdf(直接展示)。 上一篇連結:連結地址。 下面進一步優化: 具體邏輯
匯出redis中的特定 key值中的結果 並輸出到檔案
redis-cli -a Jx123456 -p 6379 --scan --pattern "*.com" >> temp.log // redis-cli 小寫 -a 密碼 排序輸出: sort china.txt | uniq -u >china_u
scrapy 詳細例項-爬取百度貼吧資料並儲存到檔案和和資料庫中
Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架。 可以應用在包括資料探勘,資訊處理或儲存歷史資料等一系列的程式中。使用框架進行資料的爬取那,可以省去好多力氣,如不需要自己去下載頁面、資料處理我們也不用自己去寫。我們只需要關注資料的爬取規則就行,scrap