
XPath:爬取百度貼吧圖片,並儲存本地
使用XPath,我們可以先將 HTML檔案 轉換成 XML文件,然後用 XPath 查詢 HTML 節點或元素。
什麼是XML
- XML 指可擴充套件標記語言(EXtensible Markup Language)
- XML 是一種標記語言,很類似 HTML
- XML 的設計宗旨是傳輸資料,而非顯示資料
- XML 的標籤需要我們自行定義。
- XML 被設計為具有自我描述性。
- XML 是 W3C 的推薦標準
- W3School官方文件:http://www.w3school.com.cn/xml/index.asp
XML 和 HTML 的區別

XML文件示例
<?xml version="1.0" encoding="utf-8"?> <bookstore> <book category="cooking"> <title lang="en">Everyday Italian</title> <author>Giada De Laurentiis</author> <year>2005</year> <price>30.00</price> </book> <book category="children"> <title lang="en">Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book> <book category="web"> <title lang="en">XQuery Kick Start</title> <author>James McGovern</author> <author>Per Bothner</author> <author>Kurt Cagle</author> <author>James Linn</author> <author>Vaidyanathan Nagarajan</author> <year>2003</year> <price>49.99</price> </book> <book category="web" cover="paperback"> <title lang="en">Learning XML</title> <author>Erik T. Ray</author> <year>2003</year> <price>39.95</price> </book> </bookstore>
HTML DOM 模型示例
HTML DOM 定義了訪問和操作 HTML 文件的標準方法,以樹結構方式表達 HTML 文件。
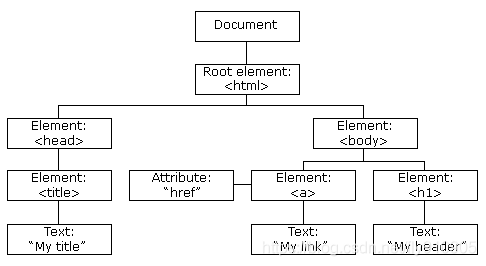
XML的節點關係
1. 父(Parent)
每個元素以及屬性都有一個父。
下面是一個簡單的XML例子中,book 元素是 title、author、year 以及 price 元素的父:
<?xml version="1.0" encoding="utf-8"?> <book> <title>Harry Potter</title> <author>J K. Rowling</author> <year>2005</year> <price>29.99</price> </book>
2. 子(Children)
元素節點可有零個、一個或多個子。
在下面的例子中,title、author、year 以及 price 元素都是 book 元素的子:
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>3. 同胞(Sibling)
擁有相同的父的節點
在下面的例子中,title、author、year 以及 price 元素都是同胞:
<?xml version="1.0" encoding="utf-8"?>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>4. 先輩(Ancestor)
某節點的父、父的父,等等。
在下面的例子中,title 元素的先輩是 book 元素和 bookstore 元素:
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>5. 後代(Descendant)
某個節點的子,子的子,等等。
在下面的例子中,bookstore 的後代是 book、title、author、year 以及 price 元素:
<?xml version="1.0" encoding="utf-8"?>
<bookstore>
<book>
<title>Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book>
</bookstore>
什麼是XPath?
XPath (XML Path Language) 是一門在 XML 文件中查詢資訊的語言,可用來在 XML 文件中對元素和屬性進行遍歷。
W3School官方文件:http://www.w3school.com.cn/xpath/index.asp
XPath 開發工具
開源的XPath表示式編輯工具:XMLQuire(XML格式檔案可用)
Chrome外掛 XPath Helper
Firefox外掛 XPath Checker
選取節點
XPath 使用路徑表示式來選取 XML 文件中的節點或者節點集。
這些路徑表示式和我們在常規的電腦檔案系統中看到的表示式非常相似。
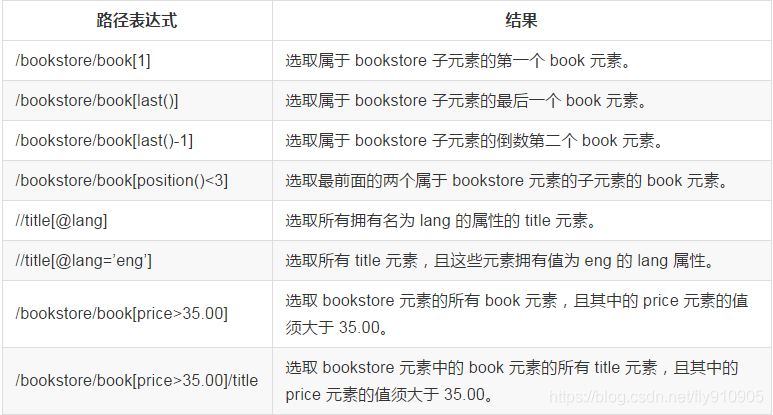
路徑表示式:

在下面的表格中,我們已列出了一些路徑表示式:

謂語(Predicates)
謂語用來查詢某個特定的節點或者包含某個指定的值的節點,被嵌在方括號中。
在下面的表格中,我們列出了帶有謂語的一些路徑表示式,以及表示式的結果:
選取未知節點
XPath 萬用字元可用來選取未知的 XML 元素。
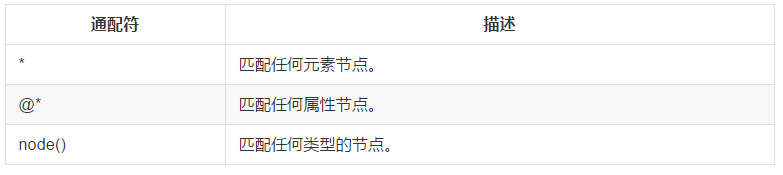
在下面的表格中,我們列出了一些路徑表示式,以及這些表示式的結果:

選取若干路徑
通過在路徑表示式中使用“|”運算子,您可以選取若干個路徑。
例項
在下面的表格中,我們列出了一些路徑表示式,以及這些表示式的結果:
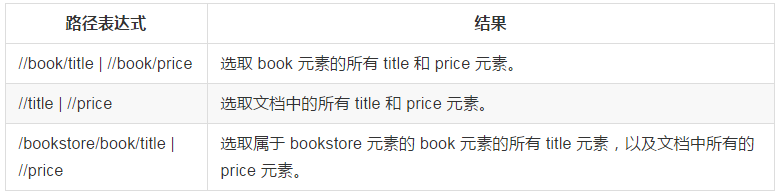
下面列出了可用在 XPath 表示式中的運算子:
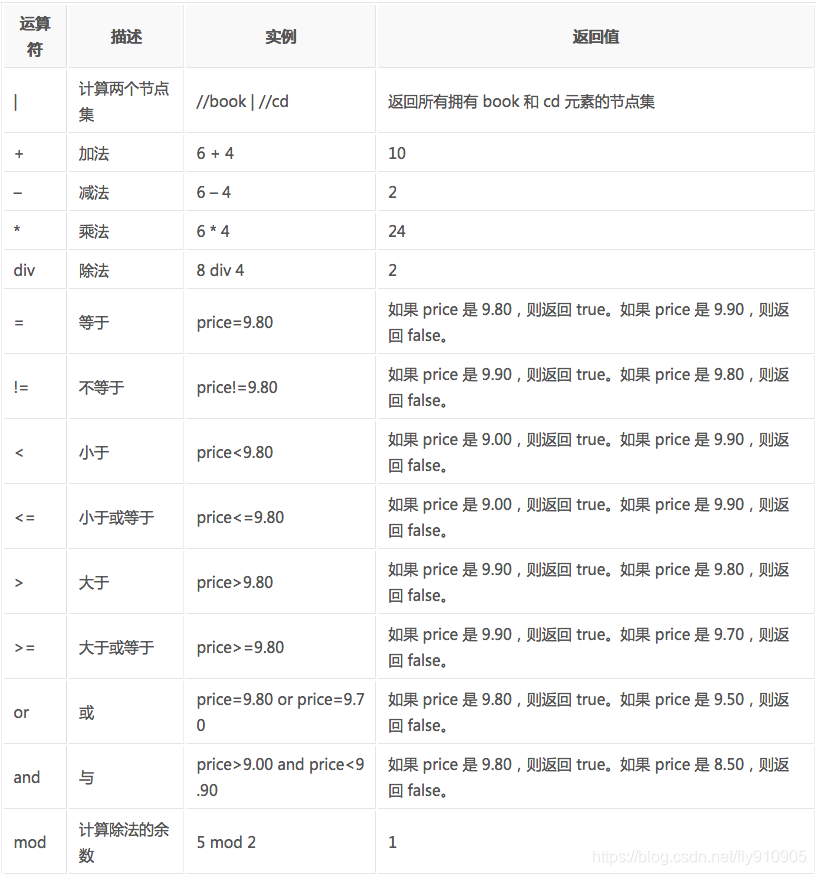
這些就是XPath的語法內容,在運用到Python抓取時要先轉換為xml。
XPath例項測試
1. 獲取所有的 <li> 標籤
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
print type(html) # 顯示etree.parse() 返回型別
result = html.xpath('//li')
print result # 列印<li>標籤的元素集合
print len(result)
print type(result)
print type(result[0])
輸出結果:
<type 'lxml.etree._ElementTree'>
[<Element li at 0x1014e0e18>, <Element li at 0x1014e0ef0>, <Element li at 0x1014e0f38>, <Element li at 0x1014e0f80>, <Element li at 0x1014e0fc8>]
5
<type 'list'>
<type 'lxml.etree._Element'>
2. 繼續獲取<li> 標籤的所有 class屬性
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/@class')
print result執行結果
['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
3. 繼續獲取<li>標籤下hre 為 link1.html 的 <a> 標籤
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a[@href="link1.html"]')
print result執行結果
[<Element a at 0x10ffaae18>]
4. 獲取<li> 標籤下的所有 <span> 標籤
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
#result = html.xpath('//li/span')
#注意這麼寫是不對的:
#因為 / 是用來獲取子元素的,而 <span> 並不是 <li> 的子元素,所以,要用雙斜槓
result = html.xpath('//li//span')
print result
執行結果
[<Element span at 0x10d698e18>]
5. 獲取 <li> 標籤下的<a>標籤裡的所有 class
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li/a//@class')
print result執行結果
['blod']
6. 獲取最後一個 <li> 的 <a> 的 href
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li[last()]/a/@href')
# 謂語 [last()] 可以找到最後一個元素
print result
執行結果
['link5.html']
7. 獲取倒數第二個元素的內容
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//li[last()-1]/a')
# text 方法可以獲取元素內容
print result[0].text執行結果
fourth item
8. 獲取 class 值為 bold 的標籤名
# xpath_li.py
from lxml import etree
html = etree.parse('hello.html')
result = html.xpath('//*[@class="bold"]')
# tag方法可以獲取標籤名
print result[0].tag
執行結果
span
使用XPath的爬蟲
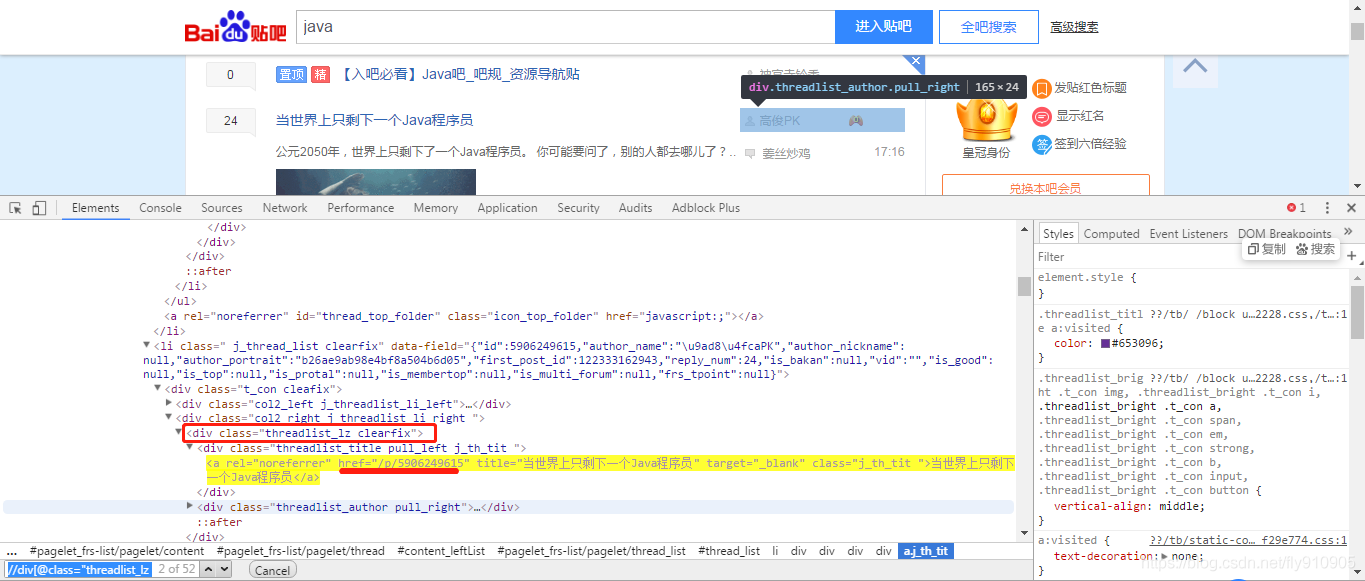
現在我們用XPath來做一個簡單的爬蟲,我們嘗試爬取某個貼吧裡的所有帖子,並且將該這個帖子裡每個樓層釋出的圖片下載到本地。
# tieba_xpath.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import urllib
import urllib2
from lxml import etree
class Spider:
def __init__(self):
self.tiebaName = raw_input("請需要訪問的貼吧:")
self.beginPage = int(raw_input("請輸入起始頁:"))
self.endPage = int(raw_input("請輸入終止頁:"))
self.url = 'http://tieba.baidu.com/f'
self.ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"}
# 圖片編號
self.userName = 1
def tiebaSpider(self):
for page in range(self.beginPage, self.endPage + 1):
pn = (page - 1) * 50 # page number
word = {'pn' : pn, 'kw': self.tiebaName}
word = urllib.urlencode(word) #轉換成url編碼格式(字串)
myUrl = self.url + "?" + word
# 示例:http://tieba.baidu.com/f? kw=%E7%BE%8E%E5%A5%B3 & pn=50
# 呼叫 頁面處理函式 load_Page
# 並且獲取頁面所有帖子連結,
links = self.loadPage(myUrl) # urllib2_test3.py
# 讀取頁面內容
def loadPage(self, url):
req = urllib2.Request(url, headers = self.ua_header)
html = urllib2.urlopen(req).read()
# 解析html 為 HTML 文件
selector=etree.HTML(html)
#抓取當前頁面的所有帖子的url的後半部分,也就是帖子編號
# http://tieba.baidu.com/p/4884069807裡的 “p/4884069807”
links = selector.xpath('//div[@class="threadlist_lz clearfix"]/div/a/@href')
# links 型別為 etreeElementString 列表
# 遍歷列表,並且合併成一個帖子地址,呼叫 圖片處理函式 loadImage
for link in links:
link = "http://tieba.baidu.com" + link
self.loadImages(link)
# 獲取圖片
def loadImages(self, link):
req = urllib2.Request(link, headers = self.ua_header)
html = urllib2.urlopen(req).read()
selector = etree.HTML(html)
# 獲取這個帖子裡所有圖片的src路徑
imagesLinks = selector.xpath('//img[@class="BDE_Image"]/@src')
# 依次取出圖片路徑,下載儲存
for imagesLink in imagesLinks:
self.writeImages(imagesLink)
# 儲存頁面內容
def writeImages(self, imagesLink):
'''
將 images 裡的二進位制內容存入到 userNname 檔案中
'''
print imagesLink
print "正在儲存檔案 %d ..." % self.userName
# 1. 開啟檔案,返回一個檔案物件
file = open('./images/' + str(self.userName) + '.png', 'wb')
# 2. 獲取圖片裡的內容
images = urllib2.urlopen(imagesLink).read()
# 3. 呼叫檔案物件write() 方法,將page_html的內容寫入到檔案裡
file.write(images)
# 4. 最後關閉檔案
file.close()
# 計數器自增1
self.userName += 1
# 模擬 main 函式
if __name__ == "__main__":
# 首先建立爬蟲物件
mySpider = Spider()
# 呼叫爬蟲物件的方法,開始工作
mySpider.tiebaSpider()執行效果:
