
Yarn的基礎介紹以及job的提交流程
1.YARN的基礎理論
1)關於YARN的介紹:
YARN 是一個資源排程平臺,負責為運算程式提供伺服器運算資源,相當於一個分散式的作業系統平臺,而 MapReduce 等運算程式則相當於運行於作業系統之上的應用程式。
2)hadoop1.x中YARN的不足:
- JobTracker是叢集的事務的集中處理,存在單點故障
- JobTracker需要完成得任務太多,既要維護job的狀態又要維護job的task的狀態,造成資源消耗過多
- 在 TaskTracker 端,用Map/Reduce Task作為資源的表示過於簡單,沒有考慮到CPU。記憶體,等資源情況,將兩個需要大消耗量的Task排程到一起,很容易出現OOM。
- 把資源強制劃分為 Map/Reduce Slot,當只有 MapTask 時,TeduceSlot 不能用;當只有 ReduceTask 時,MapSlot 不能用,容易造成資源利用不足。
3)hadoop2.x中YARN的新特性:
MRv2 最基本的想法是將原 JobTracker 主要的資源管理和 Job 排程/監視功能分開作為兩個單獨的守護程序。有一個全域性的ResourceManager(RM)和每個 Application 有一個ApplicationMaster(AM),Application 相當於 MapReduce Job 或者 DAG jobs。ResourceManager和 NodeManager(NM)組成了基本的資料計算框架。ResourceManager 協調叢集的資源利用,任何 Client 或者執行著的 applicatitonMaster 想要執行 Job 或者 Task 都得向 RM 申請一定的資源。ApplicatonMaster 是一個框架特殊的庫,對於 MapReduce 框架而言有它自己的 AM 實現,
使用者也可以實現自己的 AM,在執行的時候,AM 會與 NM 一起來啟動和監視 Tasks。
4)YARN中的角色介紹:
ResourceManager:ResoueceMananer是基於應用程式對叢集資源的需求進行排程的yarn叢集的主控制節點,負責協調和管理整個叢集,相應使用者提交的不同的型別的應用程式,解析、排程、監控等工作。ResourceManager會為每一個application啟動一個MRappmaster,並且MRappmaster分散在各個nodemanager上。
ResourceManager只要有兩個部分組成:
- 應用程式管理器(ApplicationsManager, ASM): 管理和監控所有的應用程式的MRappmaster,啟動應用程式的MRappmaster,以及MRappmaster失敗重啟
- 排程器
- FIFO(先進先出的佇列):先提交的任務先執行 後提交的後執行 內部只維護一個佇列
- Fair 公平排程器:所有的計算任務進行資源的平分,全域性中如果只有一個job那麼當前的job佔用所有的資源
- Capacity(計算能力排程器):可以根據實際的job任務的大小,進行資源的配置
NodeManager:Nodemanager是yarn叢集中正真資源的提供者,也是真正執行應用程式的容器的提供者,監控應用程式的資源情況(cpu、網路、IO、記憶體)。並通過心跳向叢集的主節點ResourceManager 進行彙報以及更新自己的健康狀況。同時也會監督container的生命週期管理,監控每個container的資源情況
MRAppMaster:為當前的job的mapTask和reduceTask向ResourceManager 申請資源、監控當前job的mapTask和reduceTask的執行狀況和進度、為失敗的MapTask和reduceTask重啟、負責對mapTask和reduceTask的資源回收。
Container :Container 是一個容器,一個抽象的邏輯資源單位。容器是由ResourceManager Scheduler 服務動態分配的資源構成的,它包括該節點上的一定量的cpu、網路、IO、記憶體,MapReduce 程式的所有 Task 都是在一個容器裡執行完成的。
5)YARN中的資源排程:
hadoop 1.x: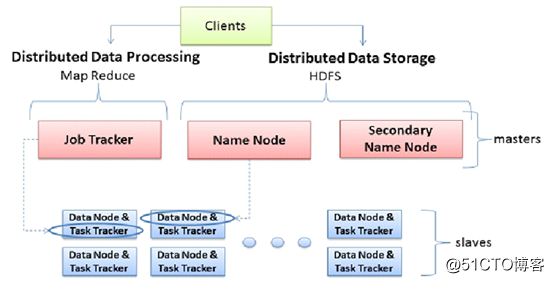
- 首先通過client發起計算作業,由jobTracker向每一個Task Tracker發起計算(每一個job Tracker就是一個map-reduce)
- 具體工作的是Task Tracker,而jobTracker是做資源管理的,首先Task Tracker會向job tracker做心跳,並同時的拉取相應的任務,開始計算。
- 首先job Tracker控制Task Tracker並行map計算,當map結束之後,job Tracker控制Task Tracker並行reduce計算。
hadoop 2.x: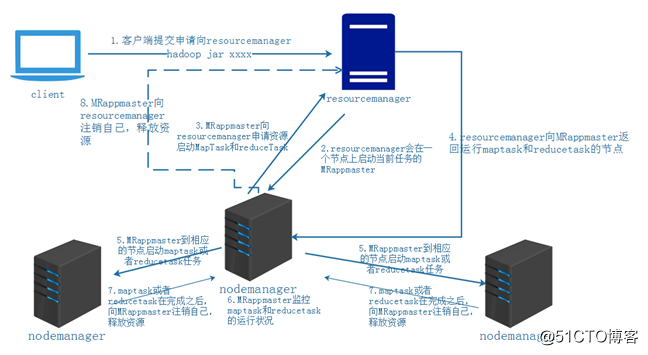
- 客戶端提交計算任務到resourceManager(hadoopxx.jar)
- resourceManager會在一個節點上啟動一個container,在其中執行一個MRappmaster
- MRappmaster向resourceManager申請資源執行行maptask和reducetask
- resourceManager向MRAPPmaster返回執行maptask和reducetask的節點
- MRAPPmaster到相應的節點中啟動一個container在其中執行maptask和reudcetask
- MRappmaster監控maptask或者reducetask的執行狀況
- nodemanger在執行完maptask或者reducetask後,向MRappmaster申請登出自己,釋放資源
- MRappmaster向resourcemanager登出自己,釋放資源。
2.YARN的job 提交流程
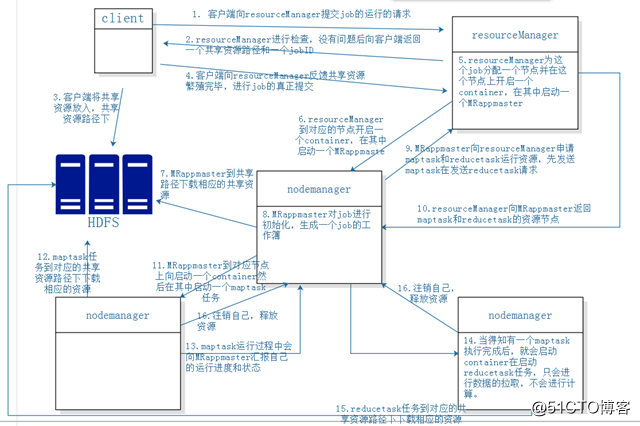
- 客戶端向resourcemanager提交job執行的請求(hadoop jar xxxx.jar)
- Resourcemanager進行檢查,沒有問題的時候,向客戶端返回一個共享資源路徑以及JobID
- 客戶端將共享資源放入共享路徑下:(/tmp/hadoop-yarn/staging/hadoop/.staging/job_1539740094604_0002/)
- Job.jar 需要執行的jar包,重新命名為job.jar
- Job.split 切片資訊 (FlieInputFormat---getSplits List<Split>)
- Job.xml 配置檔案資訊 (一些列的job.setxxxx())
- 客戶端向resourcemanager反饋共享資源放置完畢,進行job的真正提交
- resourceManager為這個job分配一個節點並在這個節點上啟動MRAPPmaster任務
- resourceManager到對應的節點上去啟動一個container然後啟動mrappmaster
- MRappmaster去共享資源路徑中下載資源(主要是split、job)
- MRappmater對job進行初始化,生成一個job工作簿,job的工作薄記錄著maptask和reduce的執行進度和狀態
- MRappmaster向resourcemanager申請maptask和reducetask的執行的資源,先發maptask然後發reducetask
- resourcemanager向MRAPPmaster返回maptask和reduce的資源節點(返回節點時,有就近原則,優先返回當前的maptask所處理切片的實際節點,資料處處理的時候可以做到資料的本地化處理。如果是多副本的時候就在多副本的任意節點。而reducetask任務在任意不忙的節點上啟動)
- MRAPPmaster到對應的節點上啟動一個container,然後在container中啟動maptask任務
- maptask任務到對應的共享資源路徑下下載相應的資源(執行的jar包)
- maptask任務啟動,並且定時向MRAPPmaster彙報自己的執行狀態和進度
- 當有一個maptask任務完成之後,reduce就啟動container然後在啟動啟動reduce任務,但是這裡的reducetask只做資料拉取的工作,不會進行計算
- duceTask任務到對應的共享資源路徑下載相應的資源(執行的jar包),當所有的maptask任務執行完成後,啟動reduce任務進行計算
- 當maptask或者是reducetask任務執行完成之後,就會向MRAPPmaster申請登出自己,釋放資源
- 當application任務完成之後,MRAPPmaster會向resourcemanager申請登出自己,釋放資源