
大資料教程(8.6)yarn客戶端提交job的流程梳理和總結&自定義partition程式設計
上一篇部落格博主分享了mapreduce的並行原理,本篇部落格將繼續分享yarn客戶端提交job的流程和自定義partition程式設計。
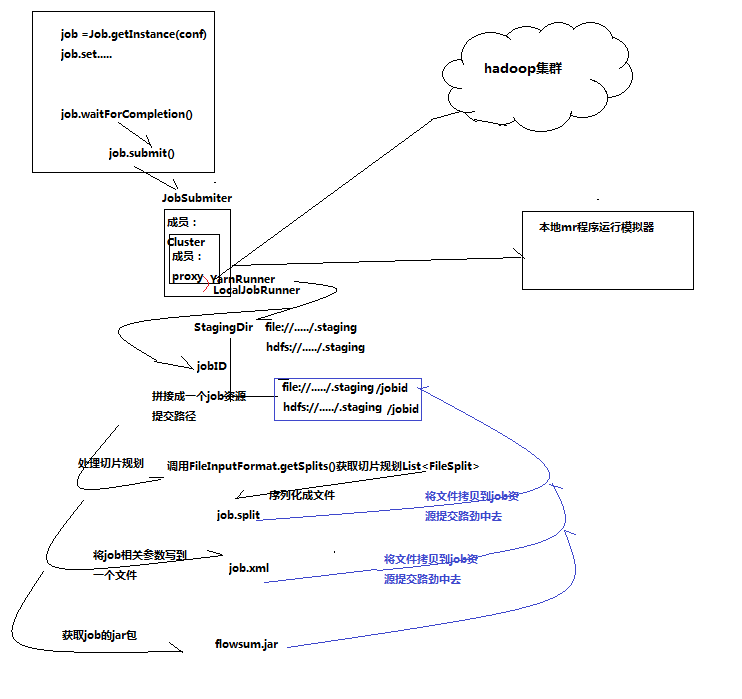
一、yarn客戶端提交job的流程
二、自定義partition程式設計
FlowBean(輸出結果類)
package com.empire.hadoop.mr.provinceflow; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; public class FlowBean implements Writable { private long upFlow; private long dFlow; private long sumFlow; //反序列化時,需要反射呼叫空參建構函式,所以要顯示定義一個 public FlowBean() { } public FlowBean(long upFlow, long dFlow) { this.upFlow = upFlow; this.dFlow = dFlow; this.sumFlow = upFlow + dFlow; } public long getUpFlow() { return upFlow; } public void setUpFlow(long upFlow) { this.upFlow = upFlow; } public long getdFlow() { return dFlow; } public void setdFlow(long dFlow) { this.dFlow = dFlow; } public long getSumFlow() { return sumFlow; } public void setSumFlow(long sumFlow) { this.sumFlow = sumFlow; } /** * 序列化方法 */ public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(dFlow); out.writeLong(sumFlow); } /** * 反序列化方法 注意:反序列化的順序跟序列化的順序完全一致 */ public void readFields(DataInput in) throws IOException { upFlow = in.readLong(); dFlow = in.readLong(); sumFlow = in.readLong(); } public String toString() { return upFlow + "\t" + dFlow + "\t" + sumFlow; } }
ProvincePartitioner (自定義分割槽類)
package com.empire.hadoop.mr.provinceflow; import java.util.HashMap; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; /** * K2 V2 對應的是map輸出kv的型別 * * @author */ public class ProvincePartitioner extends Partitioner<Text, FlowBean> { public static HashMap<String, Integer> proviceDict = new HashMap<String, Integer>(); static { proviceDict.put("136", 0); proviceDict.put("137", 1); proviceDict.put("138", 2); proviceDict.put("139", 3); } @Override public int getPartition(Text key, FlowBean value, int numPartitions) { String prefix = key.toString().substring(0, 3); Integer provinceId = proviceDict.get(prefix); return provinceId == null ? 4 : provinceId; } }
FlowCount(mapreduce主類)
package com.empire.hadoop.mr.provinceflow;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class FlowCount {
static class FlowCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString(); //將一行內容轉成string
String[] fields = line.split("\t"); //切分欄位
String phoneNbr = fields[1]; //取出手機號
long upFlow = Long.parseLong(fields[fields.length - 3]); //取出上行流量下行流量
long dFlow = Long.parseLong(fields[fields.length - 2]);
context.write(new Text(phoneNbr), new FlowBean(upFlow, dFlow));
}
}
static class FlowCountReducer extends Reducer<Text, FlowBean, Text, FlowBean> {
//<183323,bean1><183323,bean2><183323,bean3><183323,bean4>.......
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context)
throws IOException, InterruptedException {
long sum_upFlow = 0;
long sum_dFlow = 0;
//遍歷所有bean,將其中的上行流量,下行流量分別累加
for (FlowBean bean : values) {
sum_upFlow += bean.getUpFlow();
sum_dFlow += bean.getdFlow();
}
FlowBean resultBean = new FlowBean(sum_upFlow, sum_dFlow);
context.write(key, resultBean);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
/*
* conf.set("mapreduce.framework.name", "yarn");
* conf.set("yarn.resoucemanager.hostname", "mini1");
*/
Job job = Job.getInstance(conf);
/* job.setJar("/home/hadoop/wc.jar"); */
//指定本程式的jar包所在的本地路徑
job.setJarByClass(FlowCount.class);
//指定本業務job要使用的mapper/Reducer業務類
job.setMapperClass(FlowCountMapper.class);
job.setReducerClass(FlowCountReducer.class);
//指定我們自定義的資料分割槽器
job.setPartitionerClass(ProvincePartitioner.class);
//同時指定相應“分割槽”數量的reducetask
job.setNumReduceTasks(5);
//指定mapper輸出資料的kv型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//指定最終輸出的資料的kv型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
//指定job的輸入原始檔案所在目錄
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的輸出結果所在目錄
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//將job中配置的相關引數,以及job所用的java類所在的jar包,提交給yarn去執行
/* job.submit(); */
boolean res = job.waitForCompletion(true);
System.exit(res ? 0 : 1);
}
}
三、執行jar包,並檢視結果
#提交hadoop叢集執行
hadoop jar flowcount_patitioner_aaron.jar com.empire.hadoop.mr.provinceflow.FlowCount /user/hadoop/flowcount /flowcountpatitioner
#檢視輸出結果目錄
hdfs dfs -ls /flowcountpatitioner
#瀏覽輸出結果
hdfs dfs -cat /flowcountpatitioner/part-r-00000執行效果:
18/11/29 07:26:20 INFO client.RMProxy: Connecting to ResourceManager at centos-aaron-h1/192.168.29.144:8032
18/11/29 07:26:21 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
18/11/29 07:26:22 INFO input.FileInputFormat: Total input files to process : 5
18/11/29 07:26:22 INFO mapreduce.JobSubmitter: number of splits:5
18/11/29 07:26:22 INFO Configuration.deprecation: yarn.resourcemanager.system-metrics-publisher.enabled is deprecated. Instead, use yarn.system-metrics-publisher.enabled
18/11/29 07:26:23 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1543447570289_0001
18/11/29 07:26:24 INFO impl.YarnClientImpl: Submitted application application_1543447570289_0001
18/11/29 07:26:24 INFO mapreduce.Job: The url to track the job: http://centos-aaron-h1:8088/proxy/application_1543447570289_0001/
18/11/29 07:26:24 INFO mapreduce.Job: Running job: job_1543447570289_0001
18/11/29 07:26:36 INFO mapreduce.Job: Job job_1543447570289_0001 running in uber mode : false
18/11/29 07:26:36 INFO mapreduce.Job: map 0% reduce 0%
18/11/29 07:26:45 INFO mapreduce.Job: map 20% reduce 0%
18/11/29 07:27:02 INFO mapreduce.Job: map 40% reduce 1%
18/11/29 07:27:04 INFO mapreduce.Job: map 100% reduce 1%
18/11/29 07:27:05 INFO mapreduce.Job: map 100% reduce 8%
18/11/29 07:27:06 INFO mapreduce.Job: map 100% reduce 60%
18/11/29 07:27:07 INFO mapreduce.Job: map 100% reduce 100%
18/11/29 07:27:07 INFO mapreduce.Job: Job job_1543447570289_0001 completed successfully
18/11/29 07:27:08 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=4195
FILE: Number of bytes written=1986755
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=11574
HDFS: Number of bytes written=594
HDFS: Number of read operations=30
HDFS: Number of large read operations=0
HDFS: Number of write operations=10
Job Counters
Killed map tasks=1
Launched map tasks=6
Launched reduce tasks=5
Data-local map tasks=6
Total time spent by all maps in occupied slots (ms)=111307
Total time spent by all reduces in occupied slots (ms)=93581
Total time spent by all map tasks (ms)=111307
Total time spent by all reduce tasks (ms)=93581
Total vcore-milliseconds taken by all map tasks=111307
Total vcore-milliseconds taken by all reduce tasks=93581
Total megabyte-milliseconds taken by all map tasks=113978368
Total megabyte-milliseconds taken by all reduce tasks=95826944
Map-Reduce Framework
Map input records=110
Map output records=110
Map output bytes=3945
Map output materialized bytes=4315
Input split bytes=624
Combine input records=0
Combine output records=0
Reduce input groups=21
Reduce shuffle bytes=4315
Reduce input records=110
Reduce output records=21
Spilled Records=220
Shuffled Maps =25
Failed Shuffles=0
Merged Map outputs=25
GC time elapsed (ms)=3300
CPU time spent (ms)=5980
Physical memory (bytes) snapshot=1349332992
Virtual memory (bytes) snapshot=8470929408
Total committed heap usage (bytes)=689782784
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=10950
File Output Format Counters
Bytes Written=594處理結果:
[[email protected] ~]$ hdfs dfs -ls /flowcountpatitioner
Found 6 items
-rw-r--r-- 2 hadoop supergroup 0 2018-11-29 07:27 /flowcountpatitioner/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 58 2018-11-29 07:27 /flowcountpatitioner/part-r-00000
-rw-r--r-- 2 hadoop supergroup 113 2018-11-29 07:27 /flowcountpatitioner/part-r-00001
-rw-r--r-- 2 hadoop supergroup 24 2018-11-29 07:27 /flowcountpatitioner/part-r-00002
-rw-r--r-- 2 hadoop supergroup 112 2018-11-29 07:27 /flowcountpatitioner/part-r-00003
-rw-r--r-- 2 hadoop supergroup 287 2018-11-29 07:27 /flowcountpatitioner/part-r-00004
[[email protected] ~]$ hdfs dfs -cat /flowcountpatitioner/part-r-00000
13602846565 9690 14550 24240
13660577991 34800 3450 38250
[[email protected] ~]$ hdfs dfs -cat /flowcountpatitioner/part-r-00001
13719199419 1200 0 1200
13726230503 12405 123405 135810
13726238888 12405 123405 135810
13760778710 600 600 1200
[[email protected] ~]$ hdfs dfs -cat /flowcountpatitioner/part-r-00002
13826544101 1320 0 1320
[[email protected] ~]$ hdfs dfs -cat /flowcountpatitioner/part-r-00003
13922314466 15040 18600 33640
13925057413 55290 241215 296505
13926251106 1200 0 1200
13926435656 660 7560 8220
[[email protected] ~]$ hdfs dfs -cat /flowcountpatitioner/part-r-00004
13480253104 900 900 1800
13502468823 36675 551745 588420
13560436666 5580 4770 10350
13560439658 10170 29460 39630
15013685858 18295 17690 35985
15920133257 15780 14680 30460
15989002119 9690 900 10590
18211575961 7635 10530 18165
18320173382 47655 12060 59715
84138413 20580 7160 27740四、最後總結
(1)預設實現分割槽的類:HashPatitioner(分割槽效果是根據key的hashcode模reducetasks的啟動數量後是幾就落到幾號分割槽,分割槽總數就等於numReduceTasks)
/**
* Partition keys by their {@link Object#hashCode()}.
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}(2)job提交後的切片是定的,但是啟動的maptask數不一定就等於切片數;當maptask執行慢時,叢集會以為它有問題,於是再啟動一個maptask來執行這個慢的task對於的切片,兩個一起跑看誰先跑完用誰的結果;(這就是推測執行)
(3)當重寫了分割槽後,一般我們要手動在程式碼中設定reducetask個數為分割槽數;但如果沒有設定reducetask時,預設reducetask數會啟動一個,此時是可以正常執行的,只是只能生成一個結果檔案;當設定為大於1小於分割槽數的reducetask時會報錯,因為它不知道有些資料應該入哪個區;當設定為大於分割槽數的reducetask時,程式能正常執行,只是大於分割槽的那幾個reducetask不會收到資料,也不會產生結果。【建議由條件的小夥伴們驗證下結論】
最後寄語,以上是博主本次文章的全部內容,如果大家覺得博主的文章還不錯,請點贊;如果您對博主其它伺服器大資料技術或者博主本人感興趣,請關注博主部落格,並且歡迎隨時跟博主溝通交流。