
學員優秀博文賞析:雙基準快速排序實現
我一般是不會去主動碰演算法問題的。上學的時候一個演算法複雜度就把我搞煩了,還想讓我去搞演算法本身?我是這麼安慰自己的:反正寫CRUD又不需要演算法,這輩子都不需要演算法的。好吧,其實我是一直不肯承認,不去動演算法的原因只有三個字:因為笨!
所以你去看,一般招演算法工程師的都是大廠,而且,薪水永遠穩居程式設計師工資的頂端位置。流傳在開發界的鄙視鏈中,演算法工程師一直穩居金字塔頂端,俯睨眾生。

故,當學員之中出現第一篇涉足演算法,還寫的有模有樣的的部落格的時候,我是有點吃驚的。雖然只是基礎演算法,但這篇部落格中除了涉及到了演算法本身,還涉及到了原始碼分析,同時為了保證論證的完整性,文末還給出了
這幾乎是一個優秀程式設計師都會具備的素質,可是我們的這位學員才學習了Java一個月啊~~。直到我看到學員本尊的時候,一切都釋然了。你們來感受下他的頭像,我可以保證確實是本尊無疑:

隱藏的大俠都應該是如此的。
來,現在我們就來欣賞這位同學的博文,師徒班常同學的《Java中雙基準快速排序方法(DualPivotQuicksort.sort())的具體實現》:
====================================================================================================
在Java語言的Arrays類下提供了一系列排序(sort)方法,幫助使用者對各種不同資料型別的陣列進行排序. 在1.7之後的版本中, Arrays.sort()方法在操作過程中實際呼叫的是DualPivotQuicksort類下的sort方法,DualPivotQuicksort和Arrays一樣,都在java.util包下,按字面翻譯過來,就是雙(Dual)基準(Pivot)快速排序(Quicksort)演算法.
雙基準快速排序演算法於2009年由Vladimir Yaroslavskiy提出,是對經典快速排序(Classic Quicksort)進行優化後的一個版本, Java自1.7開始,均使用此方法作為預設排序演算法. 接下來,本文就將對此方法的具體實現過程進行簡單的介紹.
在正式進入對DualPivotQuicksort的介紹之前,我們先來對經典快速排序的實現思路進行一下簡單的瞭解:
經典快速排序在操作過程中首先會從陣列中選取一個基準(Pivot),這個基準可以是陣列中的任意一個元素;
隨後,將這個陣列所有其他元素和Pivot進行比較,比Pivot小的數放在左側,大的數放在右側;
如此,我們就在Pivot的左側和右側各得到了一個新的陣列;
接下來我們再在這兩個新的陣列中各自選取新的Pivot,把小的放在左側,大的放在右側,迴圈往復,最終就會得到由小到大順序排列的陣列.
下圖(via wiki)便是Quicksort的一個具體實現:
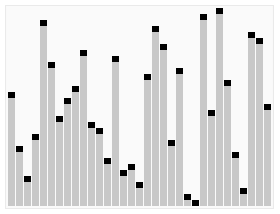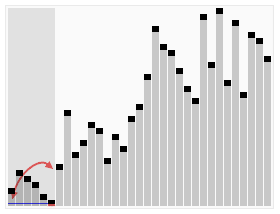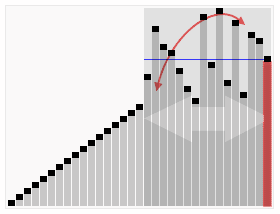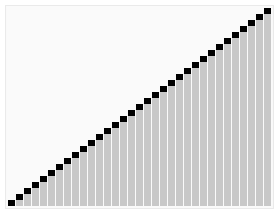
在對Quicksort的基本思路有了一定了解之後,下一步我們就來看Java中DualPivotQuicksort.sort是如何實現的;
本方法在實際工作過程中, 並不是對任何傳入的陣列都直接進行快速排序, 而是會先對陣列進行一系列測試, 然後根據陣列的具體情況選擇最適合的演算法來進行排序,下面我們結合原始碼來看:
首先, 以一個int陣列為例,
當一個數組int[] a被傳入DualPivotQuicksort.sort()時,該方法還會要求其他一系列引數:
static void sort(int[] a, int left, int right, int[] work, int workBase, int workLen)
其中,int[] a是需被排序的int陣列, left和right是該陣列中需要被排序的部分的左右界限. 而後面的work, workBase和workLen三個引數其實並不會參與雙基準快速排序, 而是當系統認為本陣列更適合使用歸併排序(merge sort)的時候, 供歸併排序使用.
但是,在實際使用中,我們並不希望為了排序設定這麼多的引數,因此:
Arrays.sort()在呼叫DualPivotQuicksort.sort()之前,對int陣列的排序提供了兩種引數列表:
public static void sort(int[] a)
直接對int[] a 進行排序,以及:
public static void sort(int[] a, int fromIndex, int toIndex)
對int[] a 中從fromIndex到toIndex(包頭不包尾)之間的元素進行排序.
在這裡,Arrays.sort()會自動將int[] work, int workBase, int workLen設定為null,0,0 省去了使用者的麻煩.
緊接著,DualPivotQuicksort.sort()會對傳入的int陣列進行檢測, 具體流程如下:
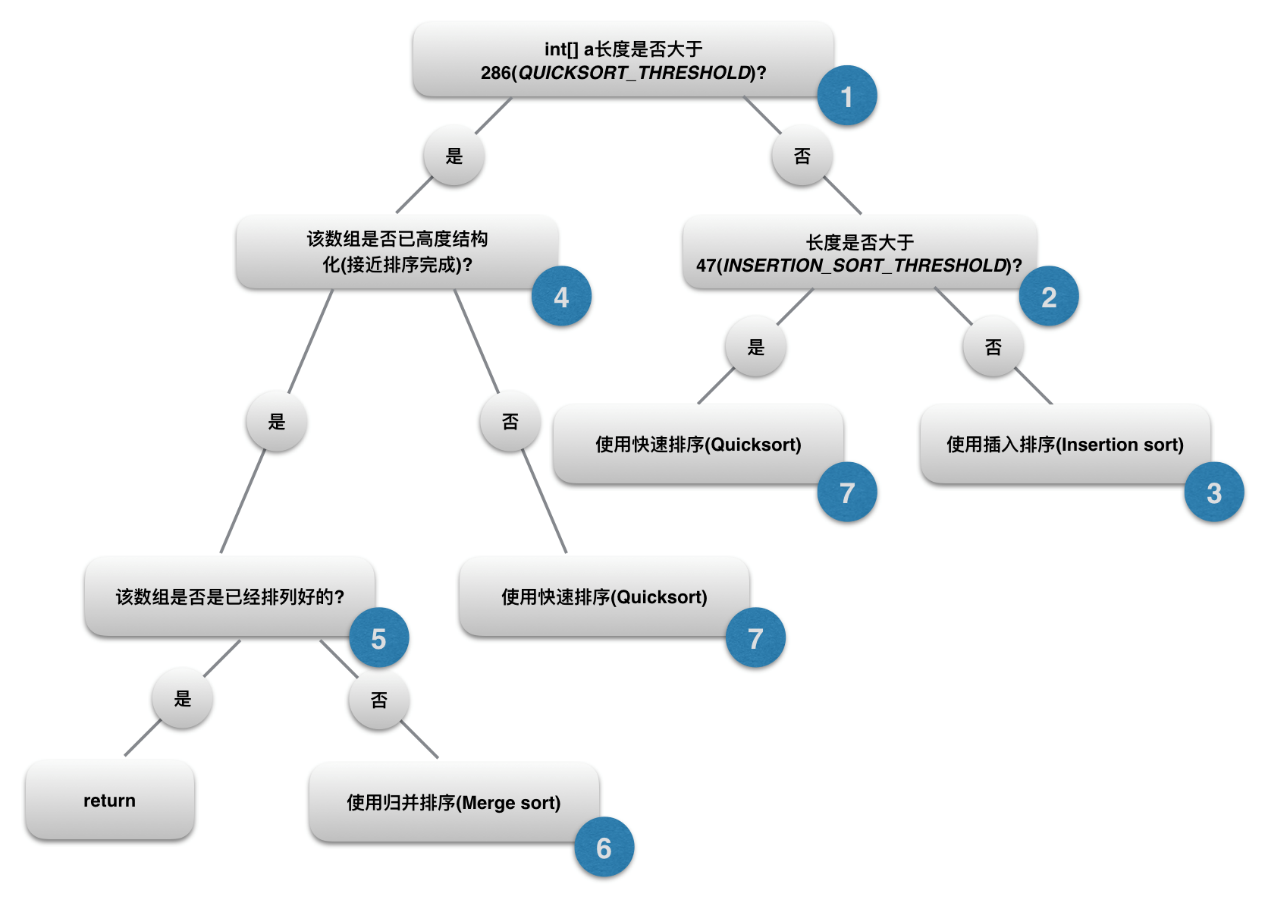
這裡先貼上整個方法的完整原始碼, 然後按上圖中的流程逐步分析, 只想看DualPivotQuicksort的話可以直接跳到下面第7點:
/** * Sorts the specified range of the array using the given * workspace array slice if possible for merging * * @param a the array to be sorted * @param left the index of the first element, inclusive, to be sorted * @param right the index of the last element, inclusive, to be sorted * @param work a workspace array (slice) * @param workBase origin of usable space in work array * @param workLen usable size of work array */ static void sort(int[] a, int left, int right, int[] work, int workBase, int workLen) { // Use Quicksort on small arrays if (right - left < QUICKSORT_THRESHOLD) { sort(a, left, right, true); return; } /* * Index run[i] is the start of i-th run * (ascending or descending sequence). */ int[] run = new int[MAX_RUN_COUNT + 1]; int count = 0; run[0] = left; // Check if the array is nearly sorted for (int k = left; k < right; run[count] = k) { if (a[k] < a[k + 1]) { // ascending while (++k <= right && a[k - 1] <= a[k]); } else if (a[k] > a[k + 1]) { // descending while (++k <= right && a[k - 1] >= a[k]); for (int lo = run[count] - 1, hi = k; ++lo < --hi; ) { int t = a[lo]; a[lo] = a[hi]; a[hi] = t; } } else { // equal for (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k]; ) { if (--m == 0) { sort(a, left, right, true); return; } } } /* * The array is not highly structured, * use Quicksort instead of merge sort. */ if (++count == MAX_RUN_COUNT) { sort(a, left, right, true); return; } } // Check special cases // Implementation note: variable "right" is increased by 1. if (run[count] == right++) { // The last run contains one element run[++count] = right; } else if (count == 1) { // The array is already sorted return; } // Determine alternation base for merge byte odd = 0; for (int n = 1; (n <<= 1) < count; odd ^= 1); // Use or create temporary array b for merging int[] b; // temp array; alternates with a int ao, bo; // array offsets from 'left' int blen = right - left; // space needed for b if (work == null || workLen < blen || workBase + blen > work.length) { work = new int[blen]; workBase = 0; } if (odd == 0) { System.arraycopy(a, left, work, workBase, blen); b = a; bo = 0; a = work; ao = workBase - left; } else { b = work; ao = 0; bo = workBase - left; } // Merging for (int last; count > 1; count = last) { for (int k = (last = 0) + 2; k <= count; k += 2) { int hi = run[k], mi = run[k - 1]; for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) { if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) { b[i + bo] = a[p++ + ao]; } else { b[i + bo] = a[q++ + ao]; } } run[++last] = hi; } if ((count & 1) != 0) { for (int i = right, lo = run[count - 1]; --i >= lo; b[i + bo] = a[i + ao] ); run[++last] = right; } int[] t = a; a = b; b = t; int o = ao; ao = bo; bo = o; } } /** * Sorts the specified range of the array by Dual-Pivot Quicksort. * * @param a the array to be sorted * @param left the index of the first element, inclusive, to be sorted * @param right the index of the last element, inclusive, to be sorted * @param leftmost indicates if this part is the leftmost in the range */ private static void sort(int[] a, int left, int right, boolean leftmost) { int length = right - left + 1; // Use insertion sort on tiny arrays if (length < INSERTION_SORT_THRESHOLD) { if (leftmost) { /* * Traditional (without sentinel) insertion sort, * optimized for server VM, is used in case of * the leftmost part. */ for (int i = left, j = i; i < right; j = ++i) { int ai = a[i + 1]; while (ai < a[j]) { a[j + 1] = a[j]; if (j-- == left) { break; } } a[j + 1] = ai; } } else { /* * Skip the longest ascending sequence. */ do { if (left >= right) { return; } } while (a[++left] >= a[left - 1]); /* * Every element from adjoining part plays the role * of sentinel, therefore this allows us to avoid the * left range check on each iteration. Moreover, we use * the more optimized algorithm, so called pair insertion * sort, which is faster (in the context of Quicksort) * than traditional implementation of insertion sort. */ for (int k = left; ++left <= right; k = ++left) { int a1 = a[k], a2 = a[left]; if (a1 < a2) { a2 = a1; a1 = a[left]; } while (a1 < a[--k]) { a[k + 2] = a[k]; } a[++k + 1] = a1; while (a2 < a[--k]) { a[k + 1] = a[k]; } a[k + 1] = a2; } int last = a[right]; while (last < a[--right]) { a[right + 1] = a[right]; } a[right + 1] = last; } return; } // Inexpensive approximation of length / 7 int seventh = (length >> 3) + (length >> 6) + 1; /* * Sort five evenly spaced elements around (and including) the * center element in the range. These elements will be used for * pivot selection as described below. The choice for spacing * these elements was empirically determined to work well on * a wide variety of inputs. */ int e3 = (left + right) >>> 1; // The midpoint int e2 = e3 - seventh; int e1 = e2 - seventh; int e4 = e3 + seventh; int e5 = e4 + seventh; // Sort these elements using insertion sort if (a[e2] < a[e1]) { int t = a[e2]; a[e2] = a[e1]; a[e1] = t; } if (a[e3] < a[e2]) { int t = a[e3]; a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } if (a[e4] < a[e3]) { int t = a[e4]; a[e4] = a[e3]; a[e3] = t; if (t < a[e2]) { a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } } if (a[e5] < a[e4]) { int t = a[e5]; a[e5] = a[e4]; a[e4] = t; if (t < a[e3]) { a[e4] = a[e3]; a[e3] = t; if (t < a[e2]) { a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } } } // Pointers int less = left; // The index of the first element of center part int great = right; // The index before the first element of right part if (a[e1] != a[e2] && a[e2] != a[e3] && a[e3] != a[e4] && a[e4] != a[e5]) { /* * Use the second and fourth of the five sorted elements as pivots. * These values are inexpensive approximations of the first and * second terciles of the array. Note that pivot1 <= pivot2. */ int pivot1 = a[e2]; int pivot2 = a[e4]; /* * The first and the last elements to be sorted are moved to the * locations formerly occupied by the pivots. When partitioning * is complete, the pivots are swapped back into their final * positions, and excluded from subsequent sorting. */ a[e2] = a[left]; a[e4] = a[right]; /* * Skip elements, which are less or greater than pivot values. */ while (a[++less] < pivot1); while (a[--great] > pivot2); /* * Partitioning: * * left part center part right part * +--------------------------------------------------------------+ * | < pivot1 | pivot1 <= && <= pivot2 | ? | > pivot2 | * +--------------------------------------------------------------+ * ^ ^ ^ * | | | * less k great * * Invariants: * * all in (left, less) < pivot1 * pivot1 <= all in [less, k) <= pivot2 * all in (great, right) > pivot2 * * Pointer k is the first index of ?-part. */ outer: for (int k = less - 1; ++k <= great; ) { int ak = a[k]; if (ak < pivot1) { // Move a[k] to left part a[k] = a[less]; /* * Here and below we use "a[i] = b; i++;" instead * of "a[i++] = b;" due to performance issue. */ a[less] = ak; ++less; } else if (ak > pivot2) { // Move a[k] to right part while (a[great] > pivot2) { if (great-- == k) { break outer; } } if (a[great] < pivot1) { // a[great] <= pivot2 a[k] = a[less]; a[less] = a[great]; ++less; } else { // pivot1 <= a[great] <= pivot2 a[k] = a[great]; } /* * Here and below we use "a[i] = b; i--;" instead * of "a[i--] = b;" due to performance issue. */ a[great] = ak; --great; } } // Swap pivots into their final positions a[left] = a[less - 1]; a[less - 1] = pivot1; a[right] = a[great + 1]; a[great + 1] = pivot2; // Sort left and right parts recursively, excluding known pivots sort(a, left, less - 2, leftmost); sort(a, great + 2, right, false); /* * If center part is too large (comprises > 4/7 of the array), * swap internal pivot values to ends. */ if (less < e1 && e5 < great) { /* * Skip elements, which are equal to pivot values. */ while (a[less] == pivot1) { ++less; } while (a[great] == pivot2) { --great; } /* * Partitioning: * * left part center part right part * +----------------------------------------------------------+ * | == pivot1 | pivot1 < && < pivot2 | ? | == pivot2 | * +----------------------------------------------------------+ * ^ ^ ^ * | | | * less k great * * Invariants: * * all in (*, less) == pivot1 * pivot1 < all in [less, k) < pivot2 * all in (great, *) == pivot2 * * Pointer k is the first index of ?-part. */ outer: for (int k = less - 1; ++k <= great; ) { int ak = a[k]; if (ak == pivot1) { // Move a[k] to left part a[k] = a[less]; a[less] = ak; ++less; } else if (ak == pivot2) { // Move a[k] to right part while (a[great] == pivot2) { if (great-- == k) { break outer; } } if (a[great] == pivot1) { // a[great] < pivot2 a[k] = a[less]; /* * Even though a[great] equals to pivot1, the * assignment a[less] = pivot1 may be incorrect, * if a[great] and pivot1 are floating-point zeros * of different signs. Therefore in float and * double sorting methods we have to use more * accurate assignment a[less] = a[great]. */ a[less] = pivot1; ++less; } else { // pivot1 < a[great] < pivot2 a[k] = a[great]; } a[great] = ak; --great; } } } // Sort center part recursively sort(a, less, great, false); } else { // Partitioning with one pivot /* * Use the third of the five sorted elements as pivot. * This value is inexpensive approximation of the median. */ int pivot = a[e3]; /* * Partitioning degenerates to the traditional 3-way * (or "Dutch National Flag") schema: * * left part center part right part * +-------------------------------------------------+ * | < pivot | == pivot | ? | > pivot | * +-------------------------------------------------+ * ^ ^ ^ * | | | * less k great * * Invariants: * * all in (left, less) < pivot * all in [less, k) == pivot * all in (great, right) > pivot * * Pointer k is the first index of ?-part. */ for (int k = less; k <= great; ++k) { if (a[k] == pivot) { continue; } int ak = a[k]; if (ak < pivot) { // Move a[k] to left part a[k] = a[less]; a[less] = ak; ++less; } else { // a[k] > pivot - Move a[k] to right part while (a[great] > pivot) { --great; } if (a[great] < pivot) { // a[great] <= pivot a[k] = a[less]; a[less] = a[great]; ++less; } else { // a[great] == pivot /* * Even though a[great] equals to pivot, the * assignment a[k] = pivot may be incorrect, * if a[great] and pivot are floating-point * zeros of different signs. Therefore in float * and double sorting methods we have to use * more accurate assignment a[k] = a[great]. */ a[k] = pivot; } a[great] = ak; --great; } } /* * Sort left and right parts recursively. * All elements from center part are equal * and, therefore, already sorted. */ sort(a, left, less - 1, leftmost); sort(a, great + 1, right, false); } } DualPivotQuickSort.sort()
1. 判斷陣列int[] a的長度是否大於常量QUICKSORT_THRESHOLD, 即286:
286是java設定的一個閾值,當陣列長度小於此值時, 系統將不再考慮merge sort, 直接將引數傳入本類中的另一個私有sort方法進行排序
private static void sort(long[] a, int left, int right, boolean leftmost)
// Use Quicksort on small arrays if (right - left < QUICKSORT_THRESHOLD) { sort(a, left, right, true); return; }
2. 繼續判斷int[] a的長度是否大於常量INSERTION_SORT_THRESHOLD, 即47:
3. 若陣列長度小於47, 則使用insertion sort:
陣列傳入本類私有的sort方法後, 會繼續判斷陣列長度是否大於47, 若小於此值, 則直接使用insertion sort並返回結果, 因為插入演算法並非本文重點, 此處不再展開敘述
int length = right - left + 1; // Use insertion sort on tiny arrays if (length < INSERTION_SORT_THRESHOLD) { if (leftmost) { /* * Traditional (without sentinel) insertion sort, * optimized for server VM, is used in case of * the leftmost part. */ for (int i = left, j = i; i < right; j = ++i) { int ai = a[i + 1]; while (ai < a[j]) { a[j + 1] = a[j]; if (j-- == left) { break; } } a[j + 1] = ai; } } else { /* * Skip the longest ascending sequence. */ do { if (left >= right) { return; } } while (a[++left] >= a[left - 1]); /* * Every element from adjoining part plays the role * of sentinel, therefore this allows us to avoid the * left range check on each iteration. Moreover, we use * the more optimized algorithm, so called pair insertion * sort, which is faster (in the context of Quicksort) * than traditional implementation of insertion sort. */ for (int k = left; ++left <= right; k = ++left) { int a1 = a[k], a2 = a[left]; if (a1 < a2) { a2 = a1; a1 = a[left]; } while (a1 < a[--k]) { a[k + 2] = a[k]; } a[++k + 1] = a1; while (a2 < a[--k]) { a[k + 1] = a[k]; } a[k + 1] = a2; } int last = a[right]; while (last < a[--right]) { a[right + 1] = a[right]; } a[right + 1] = last; } return; }
判斷陣列長度是否小於47,若小於則直接使用插入排序
值得注意的是, java在這裡提供了兩種不同的插入排序演算法, 當傳入的引數leftmost真假值不同時, 會使用不同的演算法.
leftmost代表的是本次傳入的陣列是否是從最初的int[] a的最左側left開始的, 因為本方法在整個排序過程中可能會針對陣列的不同部分被多次呼叫, 因此leftmost有可能為false.
Quicksort的情況我們放到最後再談, 這裡先回過來看第一步判斷中陣列長度大於286的情形, 這種情況下, 系統會
4.繼續判斷該陣列是否已經高度結構化(即已經接近排序完成):
這裡的基本思路是這樣的:
a. 定義一個常量MAX_RUN_COUNT = 67;
b. 定義一個計數器int count = 0; 定義一個數組int[] run 使之長度為MAX_RUN_COUNT + 1;
c. 令run[0] = left, 然後從傳入陣列的最左側left開始遍歷, 若陣列的前n個元素均為升序/降序排列, 而第n + 1個元素的升/降序發生了改變, 則將第n個元素的索引存入run[1], 同時++count, 此時count的值為1;
d. 從n + 1開始繼續遍歷, 直至升/降序再次改變, 再將此處的索引存入run[2], ++count, 此時count的值為2, 以此類推...
......
e. 若將整個陣列全部遍歷完成後, count仍然小於MAX_RUN_COUNT (即整個陣列升降序改變的次數低於67次), 證明該陣列是高度結構化的, 則使用merge sort進行排序;
若count == MAX_RUN_COUNT時, 還未完成對陣列的遍歷, 則證明陣列並非高度結構化, 則呼叫前文所述私有sort方法進行quicksort.
/* * Index run[i] is the start of i-th run * (ascending or descending sequence). */ int[] run = new int[MAX_RUN_COUNT + 1]; int count = 0; run[0] = left; // Check if the array is nearly sorted for (int k = left; k < right; run[count] = k) { if (a[k] < a[k + 1]) { // ascending while (++k <= right && a[k - 1] <= a[k]); } else if (a[k] > a[k + 1]) { // descending while (++k <= right && a[k - 1] >= a[k]); for (int lo = run[count] - 1, hi = k; ++lo < --hi; ) { int t = a[lo]; a[lo] = a[hi]; a[hi] = t; } } else { // equal for (int m = MAX_RUN_LENGTH; ++k <= right && a[k - 1] == a[k]; ) { if (--m == 0) { sort(a, left, right, true); return; } } } /* * The array is not highly structured, * use Quicksort instead of merge sort. */ if (++count == MAX_RUN_COUNT) { sort(a, left, right, true); return; } }
判斷該陣列是否已經高度結構化
5. 判斷該陣列是否是是已經排列好的:
若該陣列是高度結構化的, 在使用merge sort進行排序之前, 會先檢驗陣列是否本身就是排序好的, 思路很簡單, 如果在前面的檢測中一次就完成了遍歷, 就證明該陣列是排序好的, 則直接返回結果:
// Check special cases // Implementation note: variable "right" is increased by 1. if (run[count] == right++) { // The last run contains one element run[++count] = right; } else if (count == 1) { // The array is already sorted return; }
判斷陣列是否本來就是排列好的
*當然, 在具體實現中還有不少其他要考慮的因素, 有興趣瞭解的話可以結合上一部分程式碼進行閱讀.
6. 進行歸併排序(merge sort):
此處不再展開敘述, 值得注意的是, 由於歸併演算法在操作過程中需要使用一塊額外的儲存空間, 本方法引數列表中要求的work, workBase和workLen三個引數就是在此處使用的:
// Determine alternation base for merge byte odd = 0; for (int n = 1; (n <<= 1) < count; odd ^= 1); // Use or create temporary array b for merging int[] b; // temp array; alternates with a int ao, bo; // array offsets from 'left' int blen = right - left; // space needed for b if (work == null || workLen < blen || workBase + blen > work.length) { work = new int[blen]; workBase = 0; } if (odd == 0) { System.arraycopy(a, left, work, workBase, blen); b = a; bo = 0; a = work; ao = workBase - left; } else { b = work; ao = 0; bo = workBase - left; } // Merging for (int last; count > 1; count = last) { for (int k = (last = 0) + 2; k <= count; k += 2) { int hi = run[k], mi = run[k - 1]; for (int i = run[k - 2], p = i, q = mi; i < hi; ++i) { if (q >= hi || p < mi && a[p + ao] <= a[q + ao]) { b[i + bo] = a[p++ + ao]; } else { b[i + bo] = a[q++ + ao]; } } run[++last] = hi; } if ((count & 1) != 0) { for (int i = right, lo = run[count - 1]; --i >= lo; b[i + bo] = a[i + ao] ); run[++last] = right; } int[] t = a; a = b; b = t; int o = ao; ao = bo; bo = o; } merge sort
7. 進行雙基準快速排序(dual pivot quicksort):
只有在上述情況都不滿足的情況下, 本方法才會使用雙基準快速排序演算法進行排序,
演算法本身的思路並不複雜, 和經典快速排序相差不大, 顧名思義, 比起經典快排, 該演算法選取了兩個Pivot, 我們姑且稱之為P1和P2.
P1和P2都從陣列中選出, P1在P2的右側, 且P1必須小於P2, 如果不是, 則交換P1和P2的值;
接下來令陣列中的每一個元素和基準進行比較, 比P1小的放在P1左邊, 比P2大的放在P2右邊, 介於兩者之間的放在中間.
這樣, 最終我們會的得到三個陣列, 比P1小元素構成的陣列, 介於P1和P2之間的元素構成的陣列, 以及比P2大的元素構成的陣列.
最後, 遞迴地對這三個陣列進行排序, 最終得到排序完成的結果.
思路上雖然, 並不複雜, 但Java為了儘可能的提高效率, 在對這個演算法進行實現的過程中增加了非常多的細節, 下面我們就來大致看一下其中的部分內容:
// Inexpensive approximation of length / 7 int seventh = (length >> 3) + (length >> 6) + 1; /* * Sort five evenly spaced elements around (and including) the * center element in the range. These elements will be used for * pivot selection as described below. The choice for spacing * these elements was empirically determined to work well on * a wide variety of inputs. */ int e3 = (left + right) >>> 1; // The midpoint int e2 = e3 - seventh; int e1 = e2 - seventh; int e4 = e3 + seventh; int e5 = e4 + seventh; // Sort these elements using insertion sort if (a[e2] < a[e1]) { int t = a[e2]; a[e2] = a[e1]; a[e1] = t; } if (a[e3] < a[e2]) { int t = a[e3]; a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } if (a[e4] < a[e3]) { int t = a[e4]; a[e4] = a[e3]; a[e3] = t; if (t < a[e2]) { a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } } if (a[e5] < a[e4]) { int t = a[e5]; a[e5] = a[e4]; a[e4] = t; if (t < a[e3]) { a[e4] = a[e3]; a[e3] = t; if (t < a[e2]) { a[e3] = a[e2]; a[e2] = t; if (t < a[e1]) { a[e2] = a[e1]; a[e1] = t; } } } } // Pointers int less = left; // The index of the first element of center part int great = right; // The index before the first element of right part if (a[e1] != a[e2] && a[e2] != a[e3] && a[e3] != a[e4] && a[e4] != a[e5]) { /* * Us