
理解 OpenStack 高可用(HA) (4): Pacemaker 和 OpenStack Resource Agent (RA)
本系列會分析OpenStack 的高可用性(HA)概念和解決方案:
1. Pacemaker
1.1 概述
Pacemaker 承擔叢集資源管理者(CRM - Cluster Resource Manager)的角色,它是一款開源的高可用資源管理軟體,適合各種大小叢集。Pacemaker 由 Novell 支援,SLES HAE 就是用 Pacemaker 來管理叢集,並且 Pacemaker 得到了來自Redhat,Linbit等公司的支援。它用資源級別的監測和恢復來保證叢集服務(aka. 資源)的最大可用性。它可以用基礎元件(Corosync 或者是Heartbeat)來實現叢集中各成員之間的通訊和關係管理。它包含以下的關鍵特性:
- 監測並恢復節點和服務級別的故障
- 儲存無關,並不需要共享儲存
- 資源無關,任何能用指令碼控制的資源都可以作為服務
- 支援使用 STONITH 來保證資料一致性
- 支援大型或者小型的叢集
- 支援 quorum (仲裁) 或 resource(資源) 驅動的叢集
- 支援任何的冗餘配置
- 自動同步各個節點的配置檔案
- 可以設定叢集範圍內的 ordering, colocation and anti-colocation
- 支援高階的服務模式
1.2 Pacemaker 叢集的架構
1.2.1 軟體架構
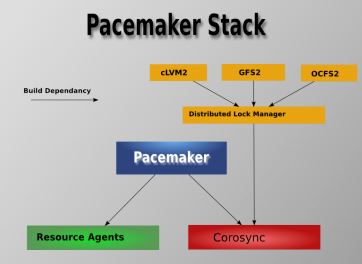
- Pacemaker - 資源管理器(CRM),負責啟動和停止服務,而且保證它們是一直執行著的以及某個時刻某服務只在一個節點上執行(避免多服務同時操作資料造成的混亂)。
- Corosync - 訊息層元件(Messaging Layer),管理成員關係、訊息和仲裁。見 1.2 部分介紹。
- Resource Agents - 資源代理,實現在節點上接收 CRM 的排程對某一個資源進行管理的工具,這個管理的工具通常是指令碼,所以我們通常稱為資源代理。任何資源代理都要使用同一種風格,接收四個引數:{start|stop|restart|status},包括配置IP地址的也是。每個種資源的代理都要完成這四個引數據的輸出。Pacemaker 的 RA 可以分為三種:(1)Pacemaker 自己實現的 (2)第三方實現的,比如 RabbitMQ 的 RA (3)自己實現的,比如 OpenStack 實現的它的各種服務的RA,這是 mysql 的 RA。
1.2.2 Pacemaker 支援的叢集型別
Pacemaker 支援多種型別的叢集,包括 Active/Active, Active/Passive, N+1, N+M, N-to-1 and N-to-N 等。

這裡 有詳細的 Pacemaker 安裝方法。這是 中文版。這篇文章 提到了 Pacemaker 的一些問題和替代方案。
1.3 Corosync
Corosync用於高可用環境中提供通訊服務,位於高可用叢集架構中的底層,扮演著為各節點(node)之間提供心跳資訊傳遞這樣的一個角色。Pacemaker 位於 HA 叢集架構中資源管理、資源代理這麼個層次,它本身不提供底層心跳資訊傳遞的功能,它要想與對方節點通訊就需要藉助底層的心跳傳遞服務,將資訊通告給對方。

關於心跳的基本概念:
- 心跳:就是將多臺伺服器用網路連線起來,而後每一臺伺服器都不停的將自己依然線上的資訊使用很簡短很小的通告給同一個網路中的其它主機,告訴它們自己依然線上,其它伺服器收到這個心跳資訊就認為它是線上的,尤其是主伺服器。
- 心跳資訊怎麼傳送,由誰來收,其實就是程序間通訊。兩臺主機是沒法通訊的,只能利用網路功能,通過程序監聽在某一套接字上,實現資料傳送,資料請求,所以多臺伺服器就得運行同等的程序,這兩個程序不停的進行通訊,主節點(主伺服器)不停的向對方同等的節點發送自己的心跳資訊,那這個軟體就叫高可用的叢集的基準層次,也叫心跳資訊傳遞層以及事物資訊的傳遞層,這是執行在叢集中的各節點上的程序,這個程序是個服務軟體,關機後需要將其啟動起來,主機間才可以傳遞資訊的,一般是主節點傳給備節點。
這篇文章 詳細介紹了其原理。
1.4 Fencing Agent
一個 Pacemaker 叢集往往需要使用 Fencing agent。https://alteeve.ca/w/ANCluster_Tutorial_2#Concept.3B_Fencing 詳細地闡述了Fencing的概念及其必要性。Fencing 是在一個節點不穩定或者無答覆時將其關閉,使得它不會損壞叢集的其它資源,其主要用途是消除腦裂。
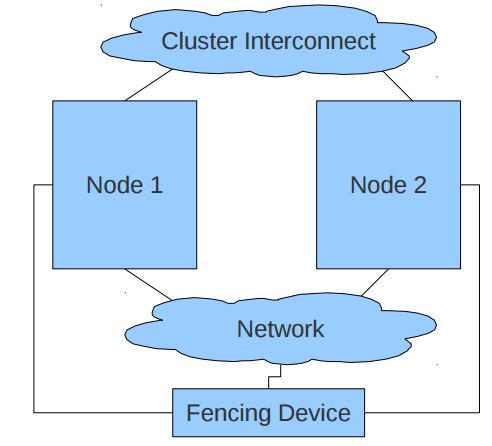
通常有兩種型別的 Fencing agent:power(電源)和 storage (儲存)。Power 型別的 Agent 會將節點的電源斷電,它通常連到物理的裝置比如UPS;Storage 型別的Agent 會確保某個時刻只有一個節點會讀寫共享的儲存。
1.5 資源代理(Resource Agent - RA)
一個 RA 是管理一個叢集資源的可執行程式,沒有固定其實現的程式語言,但是大部分RA都是用 shell 指令碼實現的。Pacemaker 使用 RA 來和受管理資源進行互動,它既支援它自身實現的70多個RA,也支援第三方RA。Pacemaker 支援三種類型的 RA:
主流的 RA 都是 OCF 型別的。RA 支援的主要操作包括:
- start: enable or start the given resource
- stop: disable or stop the given resource
- monitor: check whether the given resource is running (and/or doing useful work), return status as running or not running
- validate-all: validate the resource's configuration
- meta-data: return information about the resource agent itself (used by GUIs and other management utilities, and documentation tools)
在一個 OpenStack Pacemaker 叢集中,往往都包括這幾種型別的 RA,比如:
- RabbitMQ RA 和 OpenStack RA 也是第三方的
在 OpenStack 控制節點Pacemaker叢集中各元件:

- CIB 是個分散式的XML 檔案,有使用者新增配置
- Pacemaker 和 Corosync 根據 CIB 控制 LRMD 的行為
- LRMD 通過呼叫 RA 的介面控制各資源的行為
1.5.1 RA 的實現
usage() { #RA 的功能,包括 start,stop,validate-all,meta-data,status 和 monitor glance-api 等,每個對應下面的一個函式 cat <<UEND usage: $0 (start|stop|validate-all|meta-data|status|monitor) $0 manages an OpenStack ImageService (glance-api) process as an HA resource The 'start' operation starts the imaging service. The 'stop' operation stops the imaging service. The 'validate-all' operation reports whether the parameters are valid The 'meta-data' operation reports this RA's meta-data information The 'status' operation reports whether the imaging service is running The 'monitor' operation reports whether the imaging service seems to be working UEND } meta_data() { #meta-data 功能,輸出一段XML cat <<END ... END } ####################################################################### # Functions invoked by resource manager actions glance_api_validate() { #檢查 glance-api,比如libaray是否存在,配置檔案是否存在,RA 使用的使用者是否存在 local rc check_binary $OCF_RESKEY_binary check_binary $OCF_RESKEY_client_binary # A config file on shared storage that is not available # during probes is OK. if [ ! -f $OCF_RESKEY_config ]; then if ! ocf_is_probe; then ocf_log err "Config $OCF_RESKEY_config doesn't exist" return $OCF_ERR_INSTALLED fi ocf_log_warn "Config $OCF_RESKEY_config not available during a probe" fi getent passwd $OCF_RESKEY_user >/dev/null 2>&1 rc=$? if [ $rc -ne 0 ]; then ocf_log err "User $OCF_RESKEY_user doesn't exist" return $OCF_ERR_INSTALLED fi true } glance_api_status() { #獲取執行狀態,通過檢查 pid 檔案來確認 glance-api 是否在執行 local pid local rc if [ ! -f $OCF_RESKEY_pid ]; then ocf_log info "OpenStack ImageService (glance-api) is not running" return $OCF_NOT_RUNNING else pid=`cat $OCF_RESKEY_pid` fi ocf_run -warn kill -s 0 $pid rc=$? if [ $rc -eq 0 ]; then return $OCF_SUCCESS else ocf_log info "Old PID file found, but OpenStack ImageService (glance-api) is not running" return $OCF_NOT_RUNNING fi } glance_api_monitor() { #監控 glance-api 服務的執行狀態,通過執行 glance image-list 命令 local rc glance_api_status rc=$? # If status returned anything but success, return that immediately if [ $rc -ne $OCF_SUCCESS ]; then return $rc fi # Monitor the RA by retrieving the image list if [ -n "$OCF_RESKEY_os_username" ] && [ -n "$OCF_RESKEY_os_password" ] \ && [ -n "$OCF_RESKEY_os_tenant_name" ] && [ -n "$OCF_RESKEY_os_auth_url" ]; then ocf_run -q $OCF_RESKEY_client_binary \ --os_username "$OCF_RESKEY_os_username" \ --os_password "$OCF_RESKEY_os_password" \ --os_tenant_name "$OCF_RESKEY_os_tenant_name" \ --os_auth_url "$OCF_RESKEY_os_auth_url" \ index > /dev/null 2>&1 rc=$? if [ $rc -ne 0 ]; then ocf_log err "Failed to connect to the OpenStack ImageService (glance-api): $rc" return $OCF_NOT_RUNNING fi fi ocf_log debug "OpenStack ImageService (glance-api) monitor succeeded" return $OCF_SUCCESS } glance_api_start() { #啟動 glance-api 服務 local rc glance_api_status rc=$? if [ $rc -eq $OCF_SUCCESS ]; then ocf_log info "OpenStack ImageService (glance-api) already running" return $OCF_SUCCESS fi # run the actual glance-api daemon. Don't use ocf_run as we're sending the tool's output # straight to /dev/null anyway and using ocf_run would break stdout-redirection here. su ${OCF_RESKEY_user} -s /bin/sh -c "${OCF_RESKEY_binary} --config-file $OCF_RESKEY_config \ $OCF_RESKEY_additional_parameters"' >> /dev/null 2>&1 & echo $!' > $OCF_RESKEY_pid # Spin waiting for the server to come up. # Let the CRM/LRM time us out if required while true; do glance_api_monitor rc=$? [ $rc -eq $OCF_SUCCESS ] && break if [ $rc -ne $OCF_NOT_RUNNING ]; then ocf_log err "OpenStack ImageService (glance-api) start failed" exit $OCF_ERR_GENERIC fi sleep 1 done ocf_log info "OpenStack ImageService (glance-api) started" return $OCF_SUCCESS } glance_api_stop() { #停止 glance-api 服務 local rc local pid glance_api_status rc=$? if [ $rc -eq $OCF_NOT_RUNNING ]; then ocf_log info "OpenStack ImageService (glance-api) already stopped" return $OCF_SUCCESS fi # Try SIGTERM pid=`cat $OCF_RESKEY_pid` ocf_run kill -s TERM $pid rc=$? if [ $rc -ne 0 ]; then ocf_log err "OpenStack ImageService (glance-api) couldn't be stopped" exit $OCF_ERR_GENERIC fi # stop waiting shutdown_timeout=15 if [ -n "$OCF_RESKEY_CRM_meta_timeout" ]; then shutdown_timeout=$((($OCF_RESKEY_CRM_meta_timeout/1000)-5)) fi count=0 while [ $count -lt $shutdown_timeout ]; do glance_api_status rc=$? if [ $rc -eq $OCF_NOT_RUNNING ]; then break fi count=`expr $count + 1` sleep 1 ocf_log debug "OpenStack ImageService (glance-api) still hasn't stopped yet. Waiting ..." done glance_api_status rc=$? if [ $rc -ne $OCF_NOT_RUNNING ]; then # SIGTERM didn't help either, try SIGKILL ocf_log info "OpenStack ImageService (glance-api) failed to stop after ${shutdown_timeout}s \ using SIGTERM. Trying SIGKILL ..." ocf_run kill -s KILL $pid fi ocf_log info "OpenStack ImageService (glance-api) stopped" rm -f $OCF_RESKEY_pid return $OCF_SUCCESS } ####################################################################### case "$1" in meta-data) meta_data exit $OCF_SUCCESS;; usage|help) usage exit $OCF_SUCCESS;; esac # Anything except meta-data and help must pass validation glance_api_validate || exit $? # What kind of method was invoked? case "$1" in start) glance_api_start;; stop) glance_api_stop;; status) glance_api_status;; monitor) glance_api_monitor;; validate-all) ;; *) usage exit $OCF_ERR_UNIMPLEMENTED;; esac
1.5.2 RA 的配置
(1)因為上述的 RA 是第三方的,因此需要將它下載到本地,RA 所在的資料夾是 /usr/lib/ocf/resource.d/provider,對 OpenStack 來說,就是 /usr/lib/ocf/resource.d/openstack。然後設定其許可權為可執行。
(2)通過執行 crm configure,輸入下面的配置,就可以建立一個 Pacemaker 資源來對 glance-api 服務進行 monitor:
primitive p_glance-api ocf:openstack:glance-api \ params config="/etc/glance/glance-api.conf" os_password="secretsecret" \ os_username="admin" os_tenant_name="admin" os_auth_url="http://192.168.42. 103:5000/v2.0/" \ op monitor interval="30s" timeout="30s"
該配置指定了:
- ocf:openstack:glance-api: ”ocf“ 是指該 RA 的型別,”openstack“ 是指RA 的 namespace,”glance-api“ 是 RA 可執行程式的名稱。
- os_* 和 interval 和 timeout 引數引數(monitor 函式會用到)
- glance-api 和 config 檔案 (在 start 和 stop 中會用到)
- ”op monitor“ 表示對該資源進行 monitor,如果失敗,則執行預設的行為 restart(先 stop 再 start)(注意這裡Pacemaker 有可能在另一個節點上重啟,OpenStack 依賴其它約束比如 Pacemaker resource group 等來進行約束)
- ”interval = 30s“ 表示 monitor 執行的間隔是 30s
- ”timeout = 30“ 表示每次 monitor 的最長等待時間為 30s
- 另外,其實這裡可以指定該資源為 clone 型別,表示它會分佈在兩個節點上運行於 active/active 模式;既然這裡沒有設定,它就只執行在一個節點上。
- 另外,Pacemaker 1.1.18 版本之後,crm configure 命令被移除了,取而代之的是 pcs 命令。
(3)建立一個 service group
group g_services_api p_api-ip p_keystone p_glance-api p_cinder-api p_neutron-server p_glance-registry p_ceilometer-agent-central
Pacemaker group 的一些特性:
- 一個 group 中的所有服務都位於同一個節點上。本例中,VIP 在哪裡,其它的服務也在那個節點上執行。
- 規定了 failover 時的啟動和停止操作的規則:啟動時,group 中所有的 service 都是按照給定順序被啟動的;停止時,group 中所有的 service 都是按照逆給定順序被停止的
- 啟動時,前面的 service 啟動失敗了的話,後面的服務不會被啟動。本例中,如果 p_api-ip (VIP)啟動失敗,後面的服務都不會被啟動
1.4.3 Pacemaker 對 RA 的使用
Pacemaker 根據 CIB 中對資源的 operation 的定義來執行相應的 RA 中的命令:
(1)monitor:Pacemaker 使用 monitor 介面來檢查整個叢集範圍內該資源的狀態,來避免重複啟動一個資源。同時,重啟已經崩潰的資源。
(2)restart:在被 monitored 的資源不在執行時,它會被重啟(stop 再 start)。需要注意的是,Pacemaker 不一定在原來的節點上重啟某服務,因此,需要通過更多的限制條件(group 和 colocation),來使得某服務在規定的節點上執行。
(3)failover:當 master 節點宕機時,Pacemaker 會啟動failover 將它監管的服務切換到被節點上繼續執行。這種切換,也許需要啟動服務,也許只需要做上下文切換即可。
在標準的 Pacemaker Active/Standby 兩節點叢集中,兩個節點之間至少有兩條通訊鏈路(communication path),一條為直接的 back-to-back link,另一條為伺服器的標準物理網路。使用冗餘的鏈路是高度推薦的,因為,即使一條鏈路失效了,伺服器之間還能互相通訊。而只要伺服器之間還有一條 通訊鏈路,那麼叢集就不會觸發 failover。 當一個節點宕機或者網路失去連線時,另一個節點會檢測到,然後它會啟動切換(failover)把自己從備變為主。這過程中,新 master 上的 Pacemaker 會呼叫所有 RA 的 start 方法,將所有的資源服務啟動。然後,當原來的 master 節點重新上線以後,它上面執行的 Pacemaker 會呼叫所有 RA 的 stop 方法,將全部資源服務停止。 當然,每次重新啟動服務比較消耗時間,對於無狀態的服務,比如 glance-api,完全可以執行在兩個節點上,Pacemaker 只需要控制上下文的切換即可。 如果兩個節點都線上(online),但是互相之間的通訊鏈路都斷了,每個節點都會認為對方節點已經down了,因此,各自會啟動全部的服務,同時將 DRBD 資源轉到 Primary,那麼這時候就會處於腦裂狀態。這時候,要麼需要管理員的介入,要麼需要使用 STONITH 。關於 STONITH, 可以閱讀 https://ourobengr.com/ha/1.4.4 CIB 和 Pacemaker 的行為
這篇文章 分析了使用者在 CIB 中對 Pacemaker 所做的配置和 Pacemaker 的行為時間之間的關係。
CIB 針對重啟服務的行為,做了兩種規定:
- 1) Intervals and timeout of recovery tasks (“when”).
- 2) Grouping and colocation of recovery tasks (“where”).
各種配置項、值和結果:
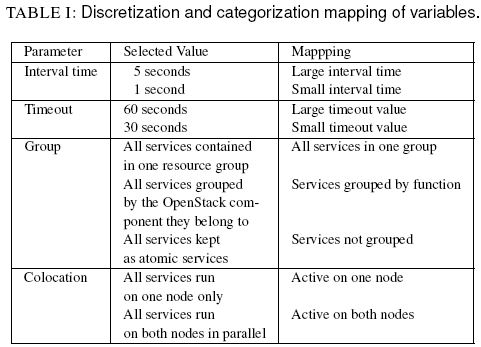
這篇文章通過多種測試,得出如下基本的結論:
- CIB 配置對資源恢復時長有直接影響
- 減少 group 有利於減少時長
- 增加 colocation 有利於減少時長
- 需要合理地進行配置來儘可能減少時長
詳細的結論可以直接閱讀那論文。
2. DRBD
DRBD (Distributed Replication Block Device) 即分散式複製塊裝置。它的工作原理是:在A主機上有對指定磁碟裝置寫請求時,資料傳送給 A主機的 kernel,然後通過 kernel 中的一個模組,把相同的資料通過網路傳送給 B主機的 kernel 一份,然後 B主機再寫入自己指定的磁碟裝置,從而實現兩主機資料的同步,也就實現了寫操作高可用。DRBD一般是一主一從,並且所有的讀寫和掛載操作,只能在主節點伺服器上進行,但是主從DRBD伺服器之間是可以進行調換的。因此,DRBD 可以看著基於網路的 RAID 1 的實現。 DRBD共有兩部分組成:核心模組和使用者空間的管理工具。其中 DRBD 核心模組程式碼已經整合進Linux核心 2.6.33 以後的版本中,因此,如果你的核心版本高於此版本的話,你只需要安裝管理工具即可;否則,你需要同時安裝核心模組和管理工具兩個軟體包,並且此兩者的版本號一定要保持對應。最新的 DRBD 版本為 8.4.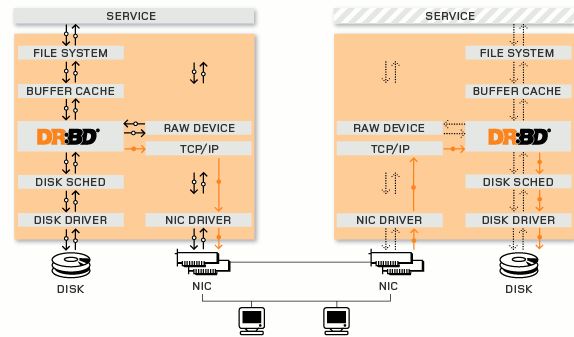 (file system, buffer cache, disk scheduler, disk drivers, TCP/IP stack and network interface card (NIC) driver)
(file system, buffer cache, disk scheduler, disk drivers, TCP/IP stack and network interface card (NIC) driver)
3. Stonith
這是一個很有意思的技術,可以用來預防腦裂。Stonith 是“shoot the other node in the head” 的首字母簡寫,它是 Heartbeat 軟體包的一個元件,它允許使用一個遠端或“智慧的”連線到健康伺服器的電源裝置自動重啟失效伺服器的電源,stonith裝置可以關閉電源並響應軟體命令,執行Heartbeat的伺服器可以通過串列埠線或網線向stonith裝置傳送命令,它控制高可用伺服器對中其他伺服器的電力供應,換句話說,主伺服器可以復位備用伺服器的電源,備用伺服器也可以復位主伺服器的電源。詳細的說明可以參考 這篇文章。相關推薦
理解 OpenStack 高可用(HA) (4): Pacemaker 和 OpenStack Resource Agent (RA)
本系列會分析OpenStack 的高可用性(HA)概念和解決方案: 1. Pacemaker 1.1 概述 Pacemaker 承擔叢集資源管理者(CRM - Cluster Resource Manager)的角色,它是一款開源的高可用資源管理軟體,適合各種大小叢集
理解 OpenStack 高可用(HA)(5):RabbitMQ HA
本系列會分析OpenStack 的高可用性(HA)概念和解決方案: 1. RabbitMQ 叢集 你可以使用若干個RabbitMQ 節點組成一個 RabbitMQ 叢集。叢集解決的是擴充套件性問題。所有的資料和狀態都會在叢集內所有的節點上被複制,只
理解 OpenStack 高可用(HA)(3):Neutron 分散式虛擬路由(Neutron Distributed Virtual Routing)
本系列會分析OpenStack 的高可用性(HA)概念和解決方案: Neutron 作為 OpenStack 一個基礎性關鍵服務,高可用性(HA)和擴充套件性是它的基本需求之一。對 neutron server 來說,因為它是無狀態的,我們可以使用負載均衡器(Load B
理解 OpenStack 高可用(HA)(2):Neutron L3 Agent HA 之 虛擬路由冗餘協議(VRRP)
本系列會分析OpenStack 的高可用性(HA)概念和解決方案: 1. 基礎知識 1.1 虛擬路由冗餘協議 - VRRP 1.1.1 概念 路由器是整個網路的核心。一個網路內的所有主機往往都設定一條預設路由,這樣,主機發出的目的地址不在本網段的報文將被通過預設路由
理解 OpenStack 高可用(HA)(1):OpenStack 高可用和災備方案 [OpenStack HA and DR]
本系列會分析OpenStack 的高可用性(HA)概念和解決方案: 1. 基礎知識 1.1 高可用 (High Availability,簡稱 HA) 高可用性是指提供在本地系統單個元件故障情況下,能繼續訪問應用的能力,無論這個故障是業務流程、物理設施、IT軟/硬體的
私有云落地解決方案之openstack高可用(pike版本)-cinder
作者:【吳業亮】 建立使用者 # openstack user create --domain default --project service --password Changeme_123
私有云落地解決方案之openstack高可用(pike版本)-架構
作者:【吳業亮】 本架構借鑑redhat架構 1、API 服務:包括 *-api, neutron-server,glance-registry, nova-novncproxy,keystone,httpd 等。由 HAProxy 提供負載均衡,將請求
私有云落地解決方案之openstack高可用(pike版本)-horizon
作者:【吳業亮】 安裝rpm包 # yum -y install openstack-dashboard 修改配置檔案 /etc/openstack-dashboard/local_sett
Hadoop2.7.2高可用(HA)環境下Hbase高可用(HA)環境的搭建(在Ubuntu14.04下以root使用者進行配置)
Hadoop2.7.2高可用(HA)環境下Hbase高可用(HA)環境的搭建 轉載請註明出處:http://blog.csdn.net/qq_23181841/article/details/75095370 (在Ubuntu14.04下以root使用者進行配置) 下載
私有云落地解決方案之openstack高可用(pike版本)-訊息佇列
作者:【吳業亮】 1、安裝軟體包 yum install erlang rabbitmq-server –y 2、啟動服務並設定開機啟動 systemctl enable rabbitm
私有云落地解決方案之openstack高可用(pike版本)-叢集引數
作者:【吳業亮】 一、新增服務 將訊息佇列加入叢集監控中 crm configure primitive rabbitmq-server systemd:rabbitmq-server \ params environment_file="/etc
OpenStack 高可用和災備方案(下)
3. 部分 OpenStack 方案提供者的 HA 方案 3.1 RDO HA 這裡 有完整的 RDO HA 部署方案: 該配置最少需要五臺機器: 一臺(物理或者虛擬)伺服器部署 nfs server,dhcp,dns一臺物理伺服器來作為計算節點三臺物理伺服器組成 pac
高並發與高可用實戰之基礎知識大型網站架構特征(一)
電商系統 保障系統 iptables ID 失敗重試 容量 設計原則 服務調用 冪等 大型網站架構特征: 1.高並發?(用戶訪問量比較大) 解決方案:拆分系統、服務化、消息中間件、緩存、並發化 高並發設計原則 系統設計不僅需要考慮實現業務功能,還要保證系統高並發、高
spark-2.4.0-hadoop2.7-高可用(HA)安裝部署
1. 主機規劃 主機名稱 IP地址 作業系統 部署軟體 執行程序 備註 mini01 172.16.1.11【內網】 10.0.0.11 【外網】
基於ubuntu搭建Redis(4.0) Cluster 高可用(HA)叢集環境
What is Redis? Redis is often referred as a data structures server. What this means is that Redis provides access to mutable data
使用HeartBeat實現高可用HA的配置過程詳解
接口 dea ive for 64位 doc 主機名 停止 enforce 使用HeartBeat實現高可用HA的配置過程詳解 一、寫在前面 HA即(high available)高可用,又被叫做雙機熱備,用於關鍵性業務。簡單理解就是,有2臺機器 A 和 B,正常
理解HDFS高可用性架構
共享存儲 src mage namenode 存儲系統 tro ima 會同 同時 在Hadoop1.x版本的時候,Namenode存在著單點失效的問題。如果namenode失效了,那麽所有的基於HDFS的客戶端——包括MapReduce作業均無法讀,寫或列文件,因為nam
第11章 拾遺4:IPv6和IPv4共存技術(1)_雙棧技術和6to4隧道技術
說明 images 測試結果 ges conf alt style dns服務 數據 6. IPv6和IPv4共存技術 6.1 雙棧技術 (1)雙協議主機的協議結構 (2)雙協議棧示意圖 ①雙協議主機在通信時首先通過支持雙協議的DNS服務器查詢與目的主機名對應的
spring boot 1.5.4 定時任務和異步調用(十)
springboot springboot1.5.4 springboot之web開發 springboot定時任務 springboot異步回調 上一篇:spring boot1.5.4 統一異常處理(九) 1 Spring Boot定時任務和異步調用我們在編寫Spring B
heartbeat+nginx搭建高可用HA集群
resp acl 取代 doc /usr 廣播 cin iptables ha.cf 前言: HA即(high available)高可用,又被叫做雙機熱備,用於關鍵性業務。簡單理解就是,有2臺機器 A 和 B,正常是 A 提供服務,B 待命閑置,當 A 宕機或服務宕掉,