
Neutron 理解 (3): Open vSwitch + GRE/VxLAN 組網 [Netruon Open vSwitch + GRE/VxLAN Virutal Network]
學習 Neutron 系列文章:
目前,OpenStack Neutron 支援使用兩種隧道網路技術 通用路由封裝(GRE) 和 VxLAN 來實現虛擬的二層網路。這兩種技術大致看起來非常相似,都是需要使用 OpenStack 在計算和網路節點上建立隧道來傳輸封裝的虛機發出的資料幀:

在Neutron 中使用 GRE/VxLAN 時的配置也幾乎完全相同。具體可以參考我已有的幾篇文章:
本文將不再重複說明這些配置細節。本文將試著分析兩種技術本身的異同,以及Neutorn 中的程式碼過程。
1. Overlay 網路
1.1 Overlay 技術概述
Overlay 在網路技術領域,指的是一種網路架構上疊加的虛擬化技術模式,其大體框架是對基礎網路不進行大規模修改的條件下,實現應用在網路上的承載,並能與其它網路業務分離,並且以基於IP的基礎網路技術為主。Overlay 技術是在現有的物理網路之上構建一個虛擬網路,上層應用只與虛擬網路相關。一個Overlay網路主要由三部分組成:
- 邊緣裝置:是指與虛擬機器直接相連的裝置
- 控制平面:主要負責虛擬隧道的建立維護以及主機可達性資訊的通告
- 轉發平面:承載 Overlay 報文的物理網路

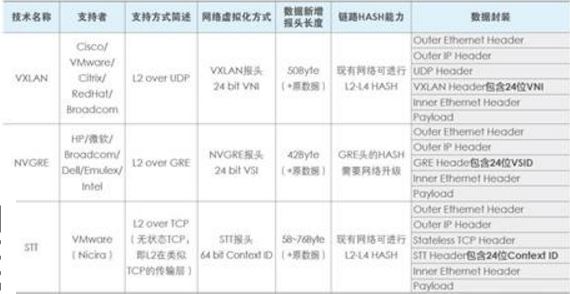
當前主流的 Overlay 技術主要有VXLAN, GRE/NVGRE和 STT。這三種二層 Overlay 技術,大體思路均是將乙太網報文承載到某種隧道層面,差異性在於選擇和構造隧道的不同,而底層均是 IP 轉發。如下表所示為這三種技術關鍵特性的比較。其中VXLAN利用了現有通用的UDP傳輸,其成熟性高。總體比較,VLXAN技術相對具有優勢。
1. 1 GRE 技術
GRE(Generic Routing Encapsulation,通用路由協議封裝)協議,是一種 IP-over-IP 的隧道,由 Cisco 和 Net-smiths 等公司於1994年提交給IETF,它對部分網路層協議(IP)的資料報進行封裝,使這些被封裝的資料報能夠在 IPv4/IPv6 網路中傳輸。其協議格式見RFC2784(https://tools.ietf.org/html/rfc2784)。簡單的說,GRE是一種協議封裝的格式。它規定了如何用一種網路協議去封裝另一種網路協議,很多網路裝置都支援該協議。說得直白點,就是 GRE 將普通的包(如ip包)封裝了,又按照普通的ip包的路由方式進行路由,相當於ip包外面再封裝一層 GRE 包。在本例子中,在 GRE 包外圍實際上又有一層公網的ip包。
GRE 使用 tunnel(隧道)技術,資料報在 tunnel 的兩端封裝,並在這個通路上傳輸,到另外一端的時候解封裝。你可以認為 tunnel 是一個虛擬的點對點的連線。(實際 Point To Point 連線之後,加上路由協議及nat技術,就可以把兩個隔絕的區域網連線在一起,就實現了NetToNet的互聯)。一般 GRE turnel 是在多個網路裝置(一般為路由器)之間建立。因為 linux 服務具備路由轉發功能,所以當您缺少專業的路由裝置的時候,可使用 linux 伺服器實現 gre turnel 的建立(實際上巨大多數網路裝置都使用unix或linux系統)。

這篇文章 很好地解釋 GRE 的原理和一個應用場景。
1.1.1 應用場景
辦公網(LAN 192.168.1.0/24,並通過固定的公網IP上網)和 IDC (LAN 10.1.1.0/24,並有多個公網ip,兩者通過公網ip互聯)這兩個區域網 (或者任意兩個不同區域網) 相互隔離。但是在日常運維和研發過程中,需要在辦公網訪問IDC網路。如果都通過公網 IP 繞,既不方便,也不安全;拉專線是最穩定可靠的辦法,但是成本高。
1.1.2 使用 GRE 的配置
如果公司有多餘的固定的公網 ip 或者路由器本身支援GRE,建議使用 GRE 方案。
(1)辦公網路由器(linux伺服器實現):區域網IP 192.168.1.254,公網 IP 180.1.1.1 配置。
cat /usr/local/admin/gre.sh #並把改指令碼加入開機啟動
#!/bin/bash modprobe ip_gre #載入gre模組 ip tunnel add office mode gre remote 110.2.2.2 local 180.1.1.1 ttl 255 #使用公網 IP 建立 tunnel 名字叫 ”office“ 的 device,使用gre mode。指定遠端的ip是110.2.2.2,本地ip是180.1.1.1。這裡為了提升安全性,你可以配置iptables,公網ip只接收來自110.2.2.2的包,其他的都drop掉。 ip link set office up #啟動device office ip link set office up mtu 1500 #設定 mtu 為1500 ip addr add 192.192.192.2/24 dev office #為 office 新增ip 192.192.192.2 echo 1 > /proc/sys/net/ipv4/ip_forward #讓伺服器支援轉發 ip route add 10.1.1.0/24 dev office #新增路由,含義是:到10.1.1.0/24的包,由office裝置負責轉發 iptables -t nat -A POSTROUTING -d 10.1.1.0/24 -j SNAT --to 192.192.192.2#否則 192.168.1.x 等機器訪問 10.1.1.x網段不通
IDC路由器(linux伺服器實現):區域網 ip:10.1.1.1,公網 ip110.2.2.2配置
cat /usr/local/admin/gre.sh#並把改指令碼加入開機啟動
#!/bin/bash modprobe ip_gre ip tunnel add office mode gre remote 180.1.1.1 local 110.2.2.2 ttl 255 ip link set office up ip link set office up mtu 1500 ip addr add 192.192.192.1/24 dev office #為office新增 ip 192.192.192.1 echo 1 > /proc/sys/net/ipv4/ip_forward ip route add 192.168.1.0/24 dev office iptables -t nat -A POSTROUTING -s 192.192.192.2 -d 10.1.0.0/16 -j SNAT --to 10.1.1.1 #否則192.168.1.X等機器訪問10.1.1.x網段不通 iptables -A FORWARD -s 192.192.192.2 -m state --state NEW -m tcp -p tcp --dport 3306 -j DROP #禁止直接訪問線上的3306,防止內網被破
配置示意圖:

然後兩個區域網中的機器就可以互通了。
1.1.3 過程

過程:
1. GRE turnel 的打通:這個過程就是雙方建立turnel的過程。
2. 區域網路由過程
(1)主機 A 傳送一個源為192.168.1.2,目的為 10.1.1.2 的包。
(2)封裝過程
1、根據內網路由,可能是你的預設路由閘道器將之路由至 192.168.1.254。
2、192.168.1.254 第一次封裝包,增加 GRE 包頭,說明包的目的地址 192.192.192.1 和源地址192.192.192.2。
3、192.168.1.254 第二次封裝包,增加公網的包頭(否則在公網上無法路由),說明包的目的地址 110.2.2.2 和源地址 180.1.1.1。
4、192.168.1.254 把所有到 10.1.1.0/24 的包,源地址都轉換為從192.192.192.2 出(snat)。
3. 公網路由過程:經過n個路由裝置,該包最終路由到110.2.2.2。
4. 拆包過程
1、B端的路由器檢測到是到達自己的 IP,就開始拆包。
2、拆包之後發現有GRE協議,就進一步拆包。
3、拆包之後發現目的地不是自己的內網ip、發現自己本地做了snat,就將其源IP替換為10.1.1.1。
5. 區域網路由
1、實際上從 10.1.1.1 出發的,到達目的地為 10.1.1.2 的包,無需路由,直接在區域網內廣播。10.1.1.2 的機器確定是傳送給自己的包,就接收。然後進一步處理了。
1.1.4 GRE 的不足
GRE 技術本身還是存在一些不足之處:
(1)Tunnel 的數量問題
GRE 是一種點對點(point to point)標準。Neutron 中,所有計算和網路節點之間都會建立 GRE Tunnel。當節點不多的時候,這種組網方法沒什麼問題。但是,當你在你的很大的資料中心中有 40000 個節點的時候,又會是怎樣一種情形呢?使用標準 GRE的話,將會有 780 millions 個 tunnels。
(2)擴大的廣播域
GRE 不支援組播,因此一個網路(同一個 GRE Tunnel ID)中的一個虛機發出一個廣播幀後,GRE 會將其廣播到所有與該節點有隧道連線的節點。
(3)GRE 封裝的IP包的過濾和負載均衡問題
目前還是有很多的防火牆和三層網路裝置無法解析 GRE Header,因此它們無法對 GRE 封裝包做合適的過濾和負載均衡。
1.2. VxLAN 技術
VxLAN 主要用於封裝、轉發2層報文。VXLAN 全稱 Virtual eXtensible Local Area Network,簡單的說就是擴充了的 VLAN,其使得多個通過三層連線的網路可以表現的和直接通過一臺一臺物理交換機連線配置而成的網路一樣處在一個 LAN 中。
它的實現機制是,將二層報文加上個 VxLAN header,封裝在一個 UDP 包中進行傳輸。VxLAN header 會包括一個 24 位的 ID(稱為VNI),含義類似於 VLAN id 或者 GRE 的 tunnel id。GRE 一般是通過路由器來進行 GRE 協議的封裝和解封的,在 VXLAN 中這類封裝和解封的元件有個專有的名字叫做 VTEP。相比起 VLAN 來說,好處在於其突破了VLAN只有 4000+ 子網的限制,同時架設在 UDP 協議上後其擴充套件性提高了不少(因為 UDP 是高層協議,遮蔽了底層的差異,換句話說遮蔽了二層的差異)。
1.2.1 VxLAN 主要的網路裝置與組網方案
VXLAN網路裝置主要有三種角色,分別是:
(1)VTEP(VXLAN Tunnel End Point):直接與終端裝置比如虛機連線的裝置,負責原始以太報文的 VXLAN 封裝和解封裝,形態可以是虛擬交換機比如 Open vSwitch,也可以是物理交換機。
(2)VXLAN GW(VXLAN Gateway/二層閘道器):用於終結VXLAN網路,將VXLAN報文轉換成對應的傳統二層網路送到傳統乙太網絡,適用於VXLAN網路內伺服器與遠端終端或遠端伺服器的二層互聯。如在不同網路中做虛擬機器遷移時,當業務需要傳統網路中伺服器與VXLAN網路中伺服器在同一個二層中,此時需要使用VXLAN二層閘道器打通VXLAN網路和二層網路。如下圖所示,VXLAN 10網路中的伺服器要和IP網路中VLAN100的業務二層互通,此時就需要通過VXLAN的二層閘道器進行互聯。VXLAN10的報文進入IP網路的流量,剝掉VXLAN的報文頭,根據VXLAN的標籤查詢對應的VLAN網路(此處對應的是VLAN100),並據此在二層報文中加入VLAN的802.1Q報文送入IP網路;相反VLAN100的業務流量進入VXLAN也需要根據VLAN獲知對應的VXLAN網路編號,根據目的MAC獲知遠端VTEP的IP地址,基於以上資訊進行VXLAN封裝後送入對應的VXLAN網路。可見,它除了具備 VTEP 的功能外,還負責 VLAN 報文與 VXLAN 報文之間的對映和轉發,主要以物理交換機為主。

(3)VXLAN IP GW(VXLAN IP Gateway/三層閘道器):用於終結 VXLAN 網路,將 VXLAN 報文轉換成傳統三層報文送至 IP 網路,適用於 VXLAN 網路內伺服器與遠端終端之間的三層互訪;同時也用作不同VXLAN網路互通。如下圖所示,當伺服器訪問外部網路時,VXLAN三層閘道器剝離對應VXLAN報文封裝,送入IP網路;當外部終端訪問VXLAN內的伺服器時,VXLAN根據目的IP地址確定所屬VXLAN及所屬的VTEP,加上對應的VXLAN報文頭封裝進入VXLAN網路。VXLAN之間的互訪流量與此類似,VXLAN閘道器剝離VXLAN報文頭,並基於目的IP地址確定所屬VXLAN及所屬的VTEP,重新封裝後送入另外的VXLAN網路。可見,具有 VXLAN GW 的所有功能,此外,還負責處理不同 VXLAN 之間的報文通訊,同時也是資料中心內部服務嚮往釋出業務的出口,主要以高效能物理交換機為主。

可見,無論是二層還是三層閘道器,均涉及到查錶轉發、VXLAN報文的解封裝和封裝操作。從轉發效率和執行效能來看,都只能在物理網路裝置上實現,並且傳統裝置無法支援,必須通過新的硬體形式來實現。以上裝置均是物理網路的邊緣裝置,而有三種邊緣裝置構成了VXLAN Overlay 網路,對於應用系統來說,只與這三種裝置相關,而與底層物理網路無關。

Overlay 網路架構就純大二層的實現來說,可分為 網路Overlay、主機Overlay以及兩種方式同時部署的混合Overlay。 Overlay網路與外部網路資料連通也有多種實現模式,並且對於關鍵網路部件有不同的技術要求。
(1)網路 Overlay 方案:使用物理交換機做VxLAN網路裝置

網路Overlay
網路Overlay 方案如上圖所示,所有的物理接入交換機支援VXLAN,物理伺服器支援SR-IOV功能,使虛擬機器通過SR-IOV技術直接與物理交換機相連,虛擬機器的流量在接入交換機上進行VXLAN報文的封裝和解除安裝,對於非虛擬化伺服器,直接連線支援VXLAN的接入交換機,伺服器流量在接入交換機上進行VXLAN報文封裝和解除安裝;當VXLAN網路需要與VLAN網路通訊時,採用物理交換機做VXLAN GW,實現VXLAN網路主機與VLAN網路主機的通訊;採用高階交換機做VXLAN IP GW,實現VXLAN網路與WAN以及Internet的互連。
(2)主機Overlay方案:使用伺服器上的軟體實現VxLAN網路裝置

主機Overlay
在主機Overlay方案中(如上圖所示),VTEP、VXLAN GW、VXLAN IP GW 均通過安裝在伺服器上的軟體實現,
- vSwitch 實現VTEP功能,完成VXLAN報文的封裝解封裝;
- vFW 等實現VXLAN GW功能,實現VXLAN網路與VLAN網路、物理伺服器的互通;
- vRouter作為VXLAN IP GW,實現 VXLAN 網路與 Internet和WAN的互聯。
在本組網中,由於所有VXLAN報文的封裝解除安裝都通過軟體實現,會佔用部分伺服器資源,當訪問量大時,vRouter會成為系統瓶頸。
(3)混合Overlay組網方案

混合Overlay
上述兩種組網方案中,網路Overlay方案與虛擬機器相連,需要通過一些特殊的要求或技術實現虛擬機器與VTEP的對接,組網不夠靈活,但是主機Overlay方案與傳統網路互通時,連線也比較複雜,且通過軟體實現 VXLAN IP GW 也會成為整個網路的瓶頸,所以最理想的組網方案應該是一個結合了網路Overlay與主機Overlay兩種方案優勢的混合Overlay方案。
如上圖所示,它通過 vSwitch 實現虛擬機器的VTEP,通過物理交換機實現物理伺服器的VTEP,通過物理交換機實現VXALN GW和VXLAN IP GW;混合式Overlay組網方案對虛擬機器和物理伺服器都能夠很好的相容,同時通過專業的硬體交換機實現VXLAN IP GW從而承載超大規模的流量轉發,是目前應用比較廣泛的組網方案。
VxLAN 網路中,虛機之間的三種互訪形式:
- 相同VXLAN內 VM之間互訪:
- 單播報文在 VTEP 處查詢目的MAC地址,確定對應的VTEP主機IP地址
- 根據目的和源VTEP主機IP地址封裝VXLAN報文頭後傳送給IP核心網
- IP 核心內部根據路由轉發該UDP報文給目的VTEP
- 目的VTEP解封裝VXLAN報文頭後按照目的MAC轉發報文給目的VM
-
不同VXLAN內 VM之間需要互訪經過VXLAN IP GW 完成,
-
在VXLAN IP GW上匹配 VXLAN Maping 表項進行轉發,報文封裝模式同同一VXLAN內VM一致
-
-
VXLAN VM與VLAN VM之間互訪,通過VXLAN GW來完成,
-
VXLAN 報文先通過VXLAN 內部轉發模式對報文進行封裝,目的IP為VXLAN GW,
-
在VXLAN GW把VXLAN報文解封裝後,匹配二層轉發表項進行轉發,VLAN到VXLAN的訪問流程正好相反
-
1.2.2 VXLAN 的實現
1.2.2.1 VxLAN 將二層資料幀封裝為 UDP 包
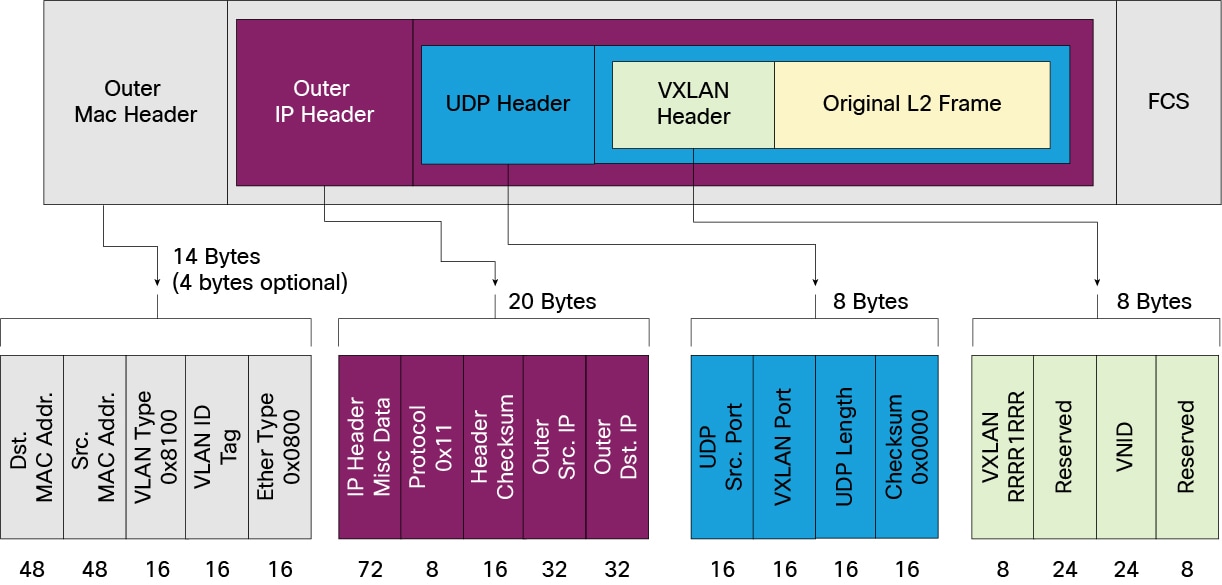
含義:
- Outer MAC destination address (MAC address of the tunnel endpoint VTEP)
- Outer MAC source address (MAC address of the tunnel source VTEP)
- Outer IP destination address (IP address of the tunnel endpoint VTEP)
- Outer IP source address (IP address of the tunnel source VTEP)
- Outer UDP header:Src port 往往用於 load balancing,下文有提到;Dst port 即 VXLAN Port,預設值為 4789.
- VNID:表示該幀的來源虛機所在的 VXLAN 網段的 ID
特點:
- VNID: 24-bits,最大 16777216。每個不同的 24-bits VNI 代表一個 VXLAN 網段。只有同一個網段中的虛機才能互相通訊。
- VXLAN Port:目的 UDP 埠,預設使用 4789 埠。使用者可以自己配置。
- 兩個 VTEP 之間的 VXLAN tunnels 是無狀態的。
- VTEP 可以在虛擬交換機上,物理交換機或者物理伺服器上通過軟體或者硬體實現。
- 使用多播來傳送未知目的的、廣播或者多播幀。
- VTEP 不可以對 VXLAN 包分段。
1.2.2.2 VTEP 定址
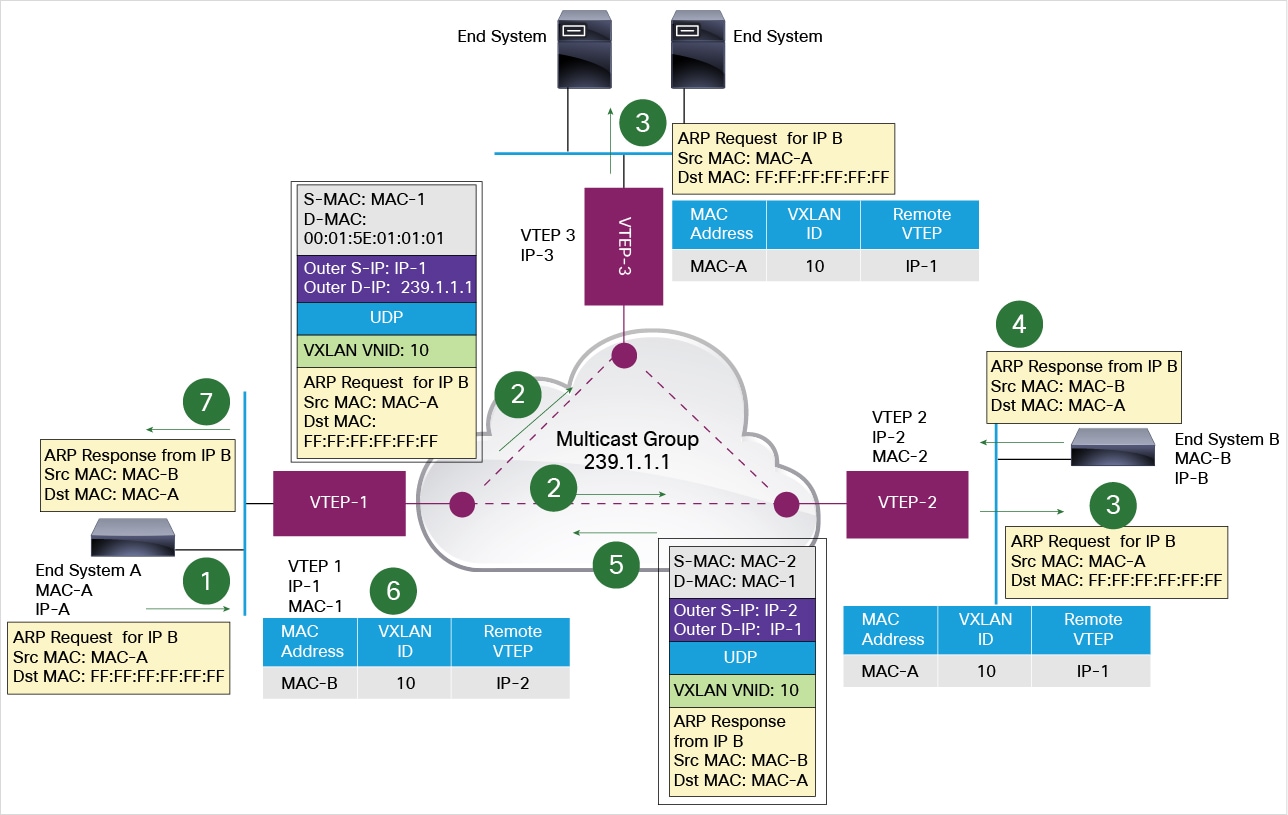
一個 VTEP 可以管理多個 VXLAN 隧道,每個隧道通向不同的目標。那 VTEP 接收到一個二層幀後,它怎麼根據二層幀中的目的 MAC 地址找到對應的 VXLAN 隧道呢?VXLAN 利用了多播和 MAC 地址學習技術。如果它收到的幀是個廣播幀比如 ARP 幀,也會經過同樣的過程。
以下圖為例,每個 VTEP 包含兩個 VXLAN 隧道。VTEP-1 收到二層 ARP 幀1(A 要查詢 B 的 MAC) 後,發出一個 Dst IP 地址為VTEP多播組 239.1.1.1 的 VXLAN 封裝 UDP 包。該包會達到 VTEP-2 和 VTEP-3。VTEP-3 收到後,因為目的 IP 地址不在它的範圍內,丟棄該包,但是學習到了一條路徑:MAC-A,VNI 10,VTEP-1-IP,它知道要到達 A 需要經過 VTEP-1 了。VTEP-2 收到後,發現目的 IP 地址是機器 B,交給 B,同時新增學習到的規則 MAC-A,VNI 10,VTEP-1-IP。B 發回響應幀後,VTEP-2 直接使用 VTEP-1 的 IP 直接將它封裝成三層包,通過物理網路直接到達 VTEP-1,再由它交給 A。VTEP-1 也學習到了一條規則 MAC-B,VNI 10,VTEP-2-IP。
1.2.2.3 VxLAN 組網
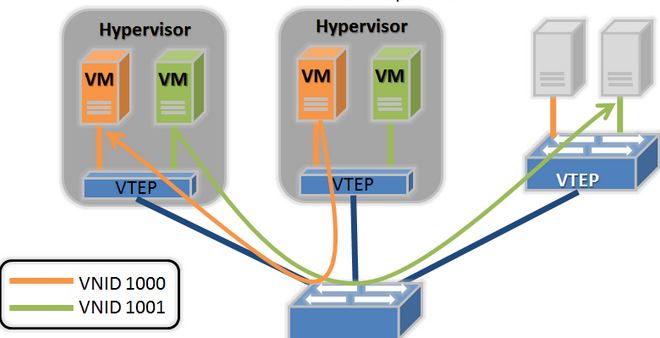
- 邏輯 VxLAN Tunnel:建立在物理的 VxLAN 網路之上,向虛機提供虛擬的二層網路,以 VNID 做區分。
- VTEP (VxLAN Tunnel End Point):對虛機的二層包封裝和解封。
1.2.2.4 資料流向
傳送端:
- 計算目的地址:Linux 核心在傳送之前會檢查資料幀的目的MAC地址,需要選擇目的 VTEP。
- 如果是廣播或者多播地址,則使用其 VNI 對應的 VXLAN group 組播地址,該多播組內所有的 VTEP 將收到該多播包;
- 如果是單播地址,如果 Linux 的 MAC 表中包含該 MAC 地址對應的目的 VTEP 地址,則使用它;
- 如果是單播地址,但是 LInux 的 MAC 表中不包含該 MAC 地址對應的目的 VTEP IP,那麼使用該 VNI 對應的組播地址。
- 新增Headers:依次新增 VXLAN header,UDP header,IP header。
接收端:
- UDP監聽:因為 VXLAN 利用了 UDP,所以它在接收的時候勢必須要有一個 UDP server 在監聽某個埠,這個是在 VXLAN 初始化的時候完成的。
- IP包剝離:一層一層剝離出原始的資料幀,交給 TCP/IP 棧,由它交給虛機。
實現程式碼在 這裡。
1.2.2.6 負載均衡
組成 VXLAN 隧道的三層路由器在有多條 ECMP (Equal-cost multi-path routing)路徑通往目的 VTEP 時往往會使用基於每個包( per-package) 的 負載均衡(load balancing)。因為兩個 VTEP 之間的所有資料包具有相同的 outer source and destination IP addresses 和 UDP destination port,因此 ECMP 只能使用 soure UDP port。VTEP 往往將其設定為原始資料幀中的一些引數的 hash 值,這樣 ECMP 就可以使用該 hash 值來區分 tunnels 直接的網路流量了。
這裡有更詳細的 VXLAN 介紹。
1.3. 相關技術對比
1.3.1 VLAN 和 VxLAN 的對比

該圖中的網路元件和Neutorn 中相應的元件一一對應:
| VLAN | VXLAN |
|
cloudVirBrX 對應於 br-int ethY.X 對應於 br-eth3 (物理bridge) ethY 對應於 Hypervisor NIC |
cloudVirBrX 對應於 br-int vxlanX 對應於 Neutron 中的 br-tun。 cloudbrZ 對應於 Neutorn 中的 br-tun 上的 vxlan interface。 ethY 對應於Hypervisor NIC |
1.3.2 GRE 和 VXLAN 對比
| Feature | VXLAN | GRE |
|---|---|---|
| Segmentation | 24-bit VNI (VXLAN Network Identifier) | Uses different Tunnel IDs |
| Theoretical scale limit | 16 million unique IDs | 16 million unique IDs |
| Transport | UDP (default port 4789) | IP Protocol 47 |
| Filtering | VXLAN uses UDP with a well-known destination port; firewalls and switch/router ACLs can be tailored to block only VXLAN traffic. | Firewalls and layer 3 switches and routers with ACLs will typically not parse deeply enough into the GRE header to distinguish tunnel traffic types; all GRE would need to be blocked indiscriminately. |
| Protocol overhead | 50 bytes over IPv4 (8 bytes VXLAN header, 20 bytes IPv4 header, 8 bytes UDP header, 14 bytes Ethernet). | 42 bytes over IPv4 (8 bytes GRE header, 20 bytes IPv4 header, 14 bytes Ethernet). |
| Handling unknown destination packets, broadcasts, and multicast | VXLAN uses IP multicast to manage flooding from these traffic types. Ideally, one logical Layer 2 network (VNI) is associated with one multicast group address on the physical network. This requires end-to-end IP multicast support on the physical data center network. | GRE has no built-in protocol mechanism to address these. This type of traffic is simply replicated to all nodes. |
| IETF specification | http://tools.ietf.org/html/draft-mahalingam-dutt-dcops-vxlan-01 | http://tools.ietf.org/html/rfc2784.html |
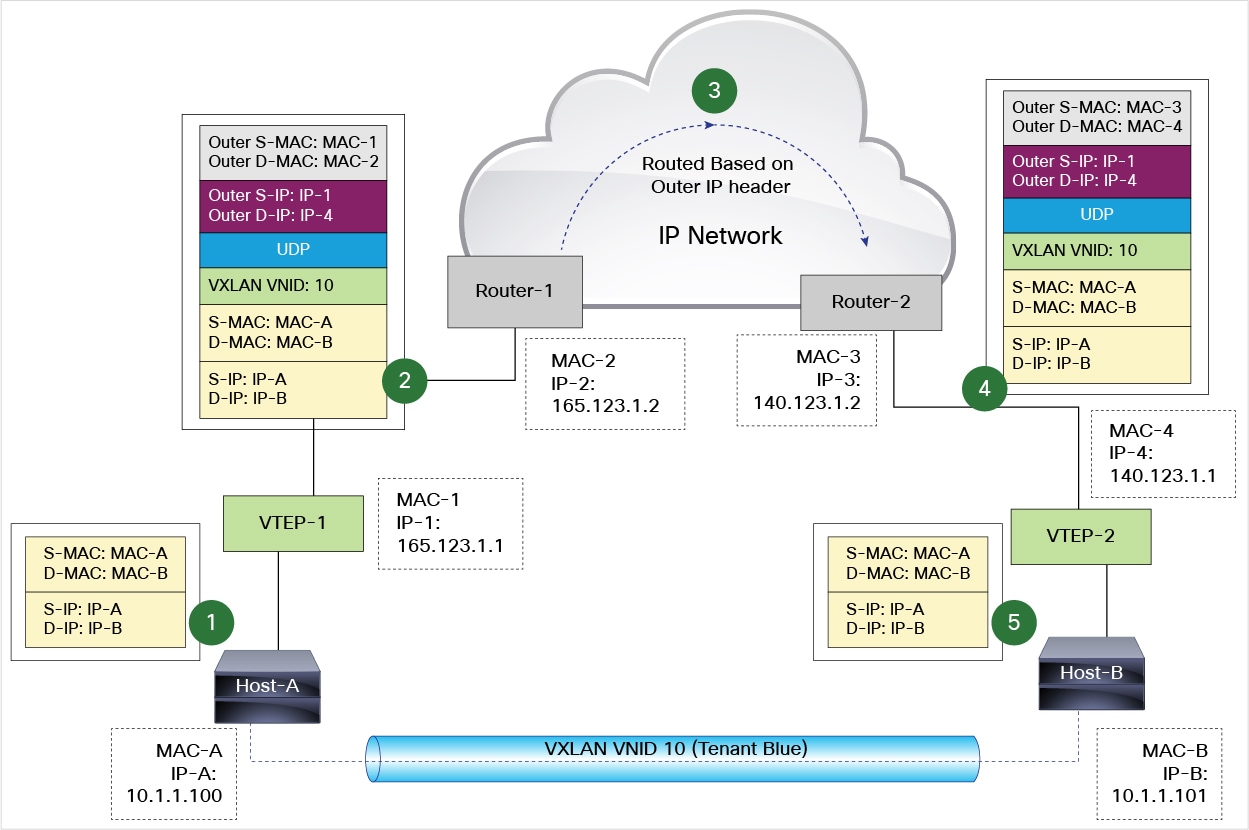
2. Neutron 通過 OVS 對 GRE 和 VXLAN 的支援
因為 OVS 對兩種協議的實現機制,Neutron 對兩個協議的支援的程式碼和配置幾乎是完全一致的,除了一些細小差別,比如名稱,以及個別配置比如VXLAN的UDP埠等。OVS 在計算或者網路節點上的 br-tun 上建立多個 tunnel port,和別的節點上的 tunnel port 之間建立點對點的 GRE/VXLAN Tunnel。Neutron GRE/VXLAN network 使用 segmentation_id (VNI 或者 GRE tunnel id) 作為其網路標識,類似於 VLAN ID,來實現不同網路內網路流量之間的隔離。
2.1 Open vSwitch 實現的 VxLAN VTEP
從上面的基礎知識部分,我們知道 VTEP 不只是實現包的封裝和解包,還包括:
(1)ARP 解析:需要儘量高效的方式響應本地虛機的 ARP 請求
(2)目的 VTEP 地址搜尋:根據目的虛機的 MAC 地址,找到它所在機器的 VTEP 的 IP 地址
通常的實現方式包括:
(1)使用 L3 多播

(2)使用 SDN 控制器(controller)來提供集中式的 MAC/IP 對照表


(一個基於 Linuxbrige + VxLAN + Service Node 的集中式 Controller node 解決 VNI-VTEP_IPs 對映的提議,替代L3多播和廣播,來源: 20140520-dlapsley-openstack-summit-vancouver-vxlan-v0-150520174345-lva1-app6891.pptx)
(3)在VTEP本地執行一個代理(agent),接收(MAC, IP, VTEP IP)資料,並提供給 VTEP
那 Open vSwitch 是如何實現這些功能需求的呢?
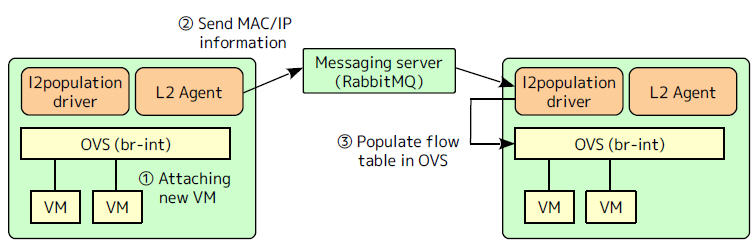
(1)在沒有啟用 l2population 的情況下,配置了多播就使用多播,沒的話就使用廣播
(2)在啟用 l2population 的情況下,在虛機 boot 以後,通過 MQ 向用於同網路虛機的節點上的 l2population driver 傳送兩種資料,再將資料加入到 OVS 流表
(2.1)FDB (forwarding database): 目的地址-所在 VTEP IP 地址的對照表,用於查詢目的虛機所在的 VTEP 的 IP 地址
(2.2)虛機 IP 地址 - MAC 地址的對照表,用於響應本地虛機的 ARP 請求
2.2 隧道埠 (tunnel port)
下面是一個例項。該例子中,10.0.1.31 Hypervisor上的 br-tun 上分別有兩個 GRE tunnel 埠和兩個 VXLAN tunnel 埠,分別連線 目標 Hypervisor 10.0.1.39 和 21。
Bridge br-tun Port "vxlan-0a000127" Interface "vxlan-0a000127" type: vxlan options: {df_default="true", in_key=flow, local_ip="10.0.1.31", out_key=flow, remote_ip="10.0.1.39"} Port "vxlan-0a000115" Interface "vxlan-0a000115" type: vxlan options: {df_default="true", in_key=flow, local_ip="10.0.1.31", out_key=flow, remote_ip="10.0.1.21"} Port "gre-0a000127" Interface "gre-0a000127" type: gre options: {df_default="true", in_key=flow, local_ip="10.0.1.31", out_key=flow, remote_ip="10.0.1.39"} Port "gre-0a000115" Interface "gre-0a000115" type: gre options: {df_default="true", in_key=flow, local_ip="10.0.1.31", out_key=flow, remote_ip="10.0.1.21"}
當有多個節點時,Neutron 會建立一個 tunnel 網:
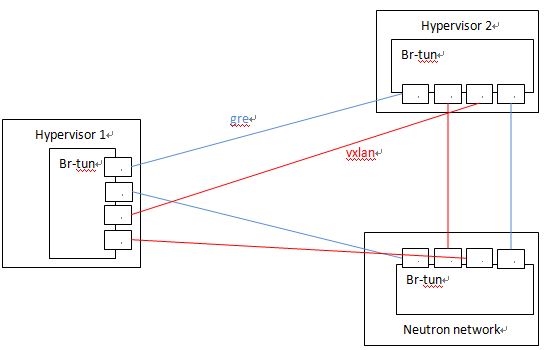
2.3 在不使用 l2population 時的隧道建立過程
要使用 GRE 和 VXLAN,管理員需要在 ml2 配置檔案中配置 local_ip(比如該物理伺服器的公網 IP),並使用配置項 tunnel_types 指定要使用的隧道型別,即 GRE 或者 VXLAN。當 enable_tunneling = true 時,Neutorn ML2 Agent 在啟動時會建立 tunnel bridge,預設為 br-tun。接著,ML2 Agent 會在 br-tun 上建立 tunnel ports,作為 GRE/VXLAN tunnel 的一端。具體過程如圖所示:

OVS 預設使用 4789 作為 VXLAN port。下表中可以看出 Neutron 節點在該埠上監聽來自所有源的UDP包:
[email protected]:/home/s1# netstat -lnup Active Internet connections (only servers) Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name udp 3840 0 0.0.0.0:4789 0.0.0.0:* -
2.4 Neutron tunnel 資料流向
Neutron 中的資料流向是受 Neutron 新增在 integration bridge 和 tunnel bridge 中的 OpenFlow rules 控制的,而且和 L2 population 直接相關。具體內容在下一篇文章中會仔細分析。
2.5 MTU 問題(來源)
VXLAN 模式下虛擬機器中的 mtu 最大值為1450,也就是隻能小於1450,大於這個值會導致 openvswitch 傳輸分片,進而導致虛擬機器中資料包資料重傳,從而導致網路效能下降。GRE 模式下虛擬機器 mtu 最大為1462。
計算方法如下:
- vxlan mtu = 1450 = 1500 – 20(ip頭) – 8(udp頭) – 8(vxlan頭) – 14(乙太網頭)
- gre mtu = 1458 = 1500 – 20(ip頭) – 8(gre頭) – 14(乙太網頭)
#/etc/neutron/dhcp_agent.ini [DEFAULT] dnsmasq_config_file = /etc/neutron/dnsmasq-neutron.conf #/etc/neutron/dnsmasq-neutron.conf dhcp-option-force=26,1450或1458
重啟 DHCP Agent,讓虛擬機器重新獲取 IP,然後使用 ifconfig 檢視是否正確配置 mtu。
3. H3C 選擇 VxLAN 的理由
H3C 是國內領先的網路裝置供應商之一,在其 一篇文章 中,談到了他們為什麼選擇 VxLAN 技術。這對別的使用者具有一定的參考性。
3.1 為什麼選擇 VxLAN
從Overlay網路出現開始,業界陸續定義了多種實現Overlay網路的技術,主流技術包括:VXLAN、NVGRE、STT、Dove等(如圖3所示)。


Overlay主流技術概覽(沒找到清晰圖。。)
從標準化程度進行分析,DOVE和STT到目前為止,標準化進展緩慢,基本上可以看作是IBM和VMware的私有協議。因此,從H3C的角度來看無法選擇這兩種技術。
從技術的實用性來看,XLAN和NVGRE兩種技術基本相當。其主要的差別在於鏈路Hash能力。由於NVGRE採用了GRE的封裝報頭,需要在標準GRE報頭中修改部分位元組來進行Hash實現鏈路負載分擔。這就需要對物理網路上的裝置進行升級改造,以支援基於GRE的負載分擔。這種改造大部分客戶很難接受。相對而言,VXLAN技術是基於UDP報頭的封裝,傳統網路裝置可以根據UDP的源埠號進行Hash實現鏈路負載分擔。這樣VXLAN網路的部署就對物理網路沒有特殊要求。這是最符合客戶要求的部署方案,所以VXLAN技術是目前業界主流的實現方式。
3.2 VXLAN為什麼選擇SDN
VXLAN的標準協議目前只定義了轉發平面流程,對於控制平面目前還沒有協議規範,所以目前業界有三種定義VXLAN控制平面的方式。
方式1:組播。由物理網路的組播協議形成組播表項,通過手工將不同的VXLAN與組播組一一繫結。VXLAN的報文通過繫結的組播組在組播對應的範圍內進行泛洪。簡單來說,和VLAN方式的組播泛洪和MAC地址自學習基本一致。區別只是前者在三層網路中預定義的組播範圍內泛洪,而後者是在二層網路中指定VLAN範圍內泛洪。這種方式的優點是非常簡單,不需要做協議擴充套件。但缺點也是顯而易見的,需要大量的三層組播表項,需要複雜的組播協議控制。顯然,這兩者對於傳統物理網路的交換機而言,都是巨大的負荷和挑戰,基本很難實現。同時,這種方式還給網路帶來大量的組播泛洪流量,對網路效能有很大的影響。
方式2:自定義協議。通過自定義的鄰居發現協議學習Overlay網路的拓撲結構並建立隧道管理機制。通過自定義(或擴充套件)的路由協議透傳Overlay網路的MAC地址(或IP地址)。通過這些自定義的協議可以實現VXLAN控制平面轉發表項的學習機制。這種方式的優點是不依賴組播,不存在大量的組播泛洪報文,對網路效能影響很小。缺點是通過鄰居發現協議和路由協議控制所有網路節點,這樣網路節點的數量就受到協議的限制。換句話說,如果網路節點的數量超過一定範圍,就會導致對應的協議(例如路由協議)執行出現異常。這一點在網際網路行業更加明顯,因為網際網路行業雲端計算的基本特徵就是大規模甚至超大規模。尤其是在vSwitch上執行VXLAN自定義路由協議,其網路節點數量可以達到幾千甚至上萬個,沒有路由協議可以支援這種規模的網路。
方式3:SDN控制器。通過SDN控制器集中控制VXLAN的轉發,經由Openflow協議下發表項是目前業界的主流方式。這種方式的優點是不依賴組播,不對網路造成負荷;另外,控制器通過叢集技術可以實現動態的擴容,所以可以支援大規模甚至超大規模的VXLAN網路。當然,SDN控制器本身的效能和可靠性決定了全網的效能和可靠性,所以如何能夠提高控制器的效能和可靠性就是核心要素。
3.3 VXLAN Fabric網路架構的優勢
雲端計算網路一直都有一個理念:Network as a Fabric,即整網可以看作是一個交換機。通過VXLAN Overlay可以很好地實現這一理念——VXLAN Fabric(如下圖所示)。
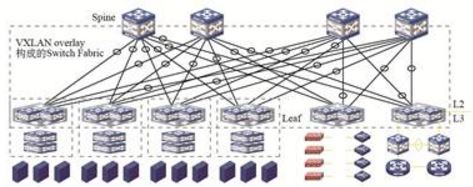
VXLAN Fabric網路架構
Spine和Leaf節點共同構建了Fabric的兩層網路架構,通過VXLAN實現Spine和Leaf之間的互聯,可以看做是交換機的背板交換鏈路。Spine節點數量可以擴容,最大可以達到16臺。Leaf節點數量也可以平滑擴容。理論上只要Spine節點的埠密度足夠高,這個Fabric可以接入數萬臺物理伺服器。
另外,通過VXLAN隧道可以實現安全伺服器節點的靈活接入。這些安全服務節點可以集中部署在一個指定區域,也可以靈活部署在任意Leaf節點下。通過Service Chain技術實現任意兩個虛擬機器之間可以通過任意安全服務節點互聯。保證網路中虛擬機器業務的安全隔離和控制訪問。同理,Fabric的出口節點也可以部署在任意位置,可以靈活擴充套件。
簡而言之,VXLAN Fabric構建了一個靈活的、穩定的、可擴充套件的Overlay網路。這個網路可以有效地解決雲端計算對網路的挑戰,是雲端計算網路發展的趨勢。
參考連結:
本文中大部分圖片來自網際網路。
歡迎大家關注我的個人公眾號:

相關推薦
Neutron 理解 (3): Open vSwitch + GRE/VxLAN 組網 [Netruon Open vSwitch + GRE/VxLAN Virutal Network]
學習 Neutron 系列文章: 目前,OpenStack Neutron 支援使用兩種隧道網路技術 通用路由封裝(GRE) 和 VxLAN 來實現虛擬的二層網路。這兩種技術大致看起來非常相似,都是需要使用 OpenStack 在計算和網路節點
Neutron 理解 (2): 使用 Open vSwitch + VLAN 組網 [Neutron Open vSwitch + VLAN Virtual Network]
學習 Neutron 系列文章: 1. L2 基礎知識 1.1 VLAN 基礎知識 1.1.1 VLAN 的含義 LAN 表示 Local Area Network,本地區域網,通常使用 Hub 和 Switch 來連線LAN 中的計算機。一般
Neutron 理解(14):Neutron ML2 + Linux bridge + VxLAN 組網
學習 Neutron 系列文章: 1. 基礎知識 1.1 VXLAN 和 Linux 以及 Linux bridge 的關係 VXLAN 是一個新興的SDN 標準,它定義了一種新的 overlay 網路,它主要的創造者是 VMware,
RxJava 2.x 理解-3
com span gpo log div .com itl http 教程 背壓: 給初學者的RxJava2.0教程(四) 給初學者的RxJava2.0教程(五) 給初學者的RxJava2.0教程(六) 給初學者的RxJava2.0教程(七) 給初學者的RxJava2.0教
redis個人理解3---redis的事件驅動原始碼分析
redis的事件驅動 redis效能很好,而且是一個單執行緒的框架。得益於redis主要通過非同步IO, 多路複用的技術,使用反應堆(reactor)模式,把大量的io操作通過訊息驅動的方式單執行緒一條條處理,這樣可以很好的利用CPU資源。因為沒有同步呼叫,所以處理速度非常快。使得多個Client訪問red
理解OpenShift(1):網路之 Router 和 Route Neutron 理解 (7): Neutron 是如何實現負載均衡器虛擬化的
理解OpenShift(1):網路之Router 和 Route 1. OpenShift 為什麼需要 Router 和 Route? 顧名思義,Router 是路由器,Route 是路由器中配置的路由。OpenShift 中的這兩個概念是為了解決從叢集外部(就是從除了叢集節點
Caffe原始碼理解3:Layer基類與template method設計模式
目錄 寫在前面 template method設計模式 Layer 基類 Layer成員變數 構造與析構 SetUp成員函式 前向傳播與反向傳播 其他成員函式 參考 部落格:blog.shinelee.me | 部落格園 | CS
Neutron 理解 (6): Neutron 是怎麼實現虛擬三層網路的 [How Neutron implements virtual L3 network]
學習 Neutron 系列文章: Neutron 對虛擬三層網路的實現是通過其 L3 Agent (neutron-l3-agent)。該 Agent 利用 Linux IP 棧、route 和 iptables 來實現內網內不同網路內的虛機之間的網路流量
Neutron 理解 (9): OpenStack 是如何實現 Neutron 網路 和 Nova虛機 防火牆的 [How Nova Implements Security Group and How Neutron Implements Virtua
學習 Neutron 系列文章: 1. Nova 安全組 1.1 配置 節點 配置檔案 配置項 說明 controller /etc/nova/nova.conf security_group_api =
Neutron 理解 (4): Neutron OVS OpenFlow 流表 和 L2 Population [Netruon OVS OpenFlow tables + L2 Population]
學習 Neutron 系列文章: OVS bridge 有兩種模式:“normal” 和 “flow”。“normal” 模式的 bridge 同普通的 Linux 橋,而 “flow” 模式的 bridge 是根據其流表(flow tab
Neutron 理解 (1): Neutron 所實現的網路虛擬化 [How Neutron Virtualizes Network]
學習 Neutron 系列文章: 1. 為什麼要網路虛擬化? 個人認為,這裡主要有兩個需求:一個是資料中心的現有網路不能滿足雲端計算的物理需求;另一個是資料中心的現有網路不能滿足雲端計算的軟體化即SDN要求。 1.1 現有物理網路不能
Neutron 理解 (8): Neutron 是如何實現虛機防火牆的 [How Neutron Implements Security Group]
學習 Neutron 系列文章: 1. 基礎知識 1.1 防火牆(firewall) 防火牆是依照特定的規則來控制進出它的網路流量的網路安全系統。一個典型的場景是在一個受信任的內網和不受信任的外網比如 Internet 之間建立一個屏障。防火牆
OpenStack Neutron(3):建立instance分配floating IP及neutron原理分析
現在可以通過Dashboard建立instance並且分配floating IP,從而我們可以通過外網隨意訪問建立的instance,例如ping或者SSH。需要注意的是在分配security group的時候,如果要使用Default 的security group,需要新
Neutron 理解 (7): Neutron 是如何實現負載均衡器虛擬化的 [LBaaS V1 in Juno]
學習 Neutron 系列文章: 1. 基礎知識 1.1 負載均衡的概念 負載均衡(Load Balancing)是將來訪的網路流量在執行相同應用的多個伺服器之間進行分發的一種核心網路服務。它的功能由負載均衡器(load balancer)提供。負
ROS-Industrial 之 industrial_robot_client 分析理解(3)
經過前面(1)和(2)的理解與討論,此篇文章對ROS向機器人控制器的資料下載相關檔案進行說明。 JOINT_TRAJECTORY_STREAMER #ifndef JOINT_TRAJECTORY_STREAMER_H #define JOINT_
Neutron 理解 (1): Neutron 所實現的虛擬化網路 [How Netruon Virtualizes Network]
1. 為什麼要網路虛擬化? 個人認為,這裡主要有兩個需求:一個是資料中心的現有網路不能滿足雲端計算的物理需求;另一個是資料中心的現有網路不能滿足雲端計算的軟體化即SDN要求。 1.1 現有物理網路不能滿足雲端計算的需求 網際網路行業資料中心的基本特徵就是伺服
渲染管線理解3
裁剪 在規格化裝置座標中,只有在x∈[-1,1],y∈[-1,1],z∈[-1,1]內的三角形才會被渲染。即在檢視座標中在視錐內的三角形會被渲染。 一般平面裁剪 假設是直線裁剪,PR會被裁剪,平面為ax+by+cz+d=0。法向量指向內側(PQ方向)。
深入學習理解(3):java:CompletionService解決ExecutorService的submit方法的缺點
在ExecutorService的submit方法中可以獲取返回值,通過Future的get方法,但是這個Future類存在缺陷,Future介面呼叫get()方法取得處理後的返回結果時具有阻塞性,也就是說呼叫Future的get方法時,任務沒有執行完成,則ge
對Faster R-CNN的理解(3)
font img left box strong 技術 mar 圖片 http 2.2 邊框回歸 邊框回歸使用下面的幾個公式: xywh是預測值,帶a的是anchor的xywh,帶*的是GT Box的xywh,可以看作是anchor經過一定的變換回歸到附近的G
js 完整的window.open()控制視窗屬性 & open多個視窗
1.完整的window.open()控制視窗屬性: window.open() 支援環境 JavaScript1.0+/JScript1.0+/Nav2+/IE3+/Opera3+ 語法 w