hadoop-2.6.0.tar.gz的叢集搭建(3節點)(不含zookeeper叢集安裝)
前言
關於幾個疑問和幾處心得!
a.用NAT,還是橋接,還是only-host模式?
b.用static的ip,還是dhcp的?
答:static
c.別認為快照和克隆不重要,小技巧,比別人靈活用,會很節省時間和大大減少錯誤。
d.重用起來指令碼語言的程式設計,如paython或shell程式設計。
對於用scp -r命令或deploy.conf(配置檔案),deploy.sh(實現檔案複製的shell指令碼檔案),runRemoteCdm.sh(在遠端節點上執行命令的shell指令碼檔案)。
e.重要Vmare Tools增強工具,或者,rz上傳、sz下載。
f.

用到的所需:
1、VMware-workstation-full-11.1.2.61471.1437365244.exe
2、CentOS-6.5-x86_64-bin-DVD1.iso
3、jdk-7u69-linux-x64.tar.gz
4、hadoop-2.6.0.tar.gz
機器規劃:
192.168.80.31 ---------------- master
192.168.80.32 ---------------- slave1
192.168.80.33 ---------------- slave1
目錄規劃:
所有namenode節點產生的日誌 /data/dfs/name
所有datanode節點產生的日誌 /data/dfs/data
第一步:安裝VMware-workstation虛擬機器,我這裡是VMware-workstation11版本。
詳細見 ->
第二步:安裝CentOS系統,我這裡是6.6版本。推薦(生產環境中常用)
詳細見 ->
第三步:VMware Tools增強工具安裝
詳細見 ->
第四步:準備小修改(學會用快照和克隆,根據自身要求情況,合理位置快照)
詳細見 ->
第一步:搭建一個3節點的hadoop分散式小叢集--預備工作(master、slave1、slave2的網路連線、ip地址靜態、拍照、遠端)
master
slave1
Slave2
對master而言,
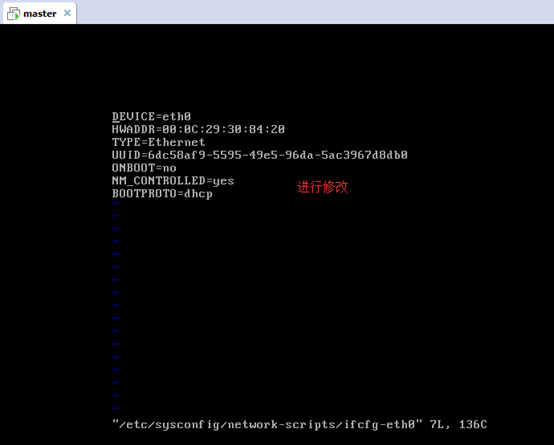
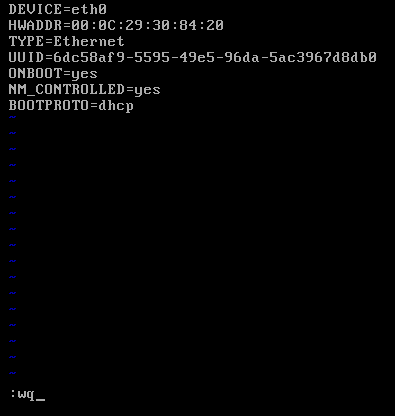
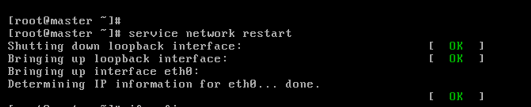
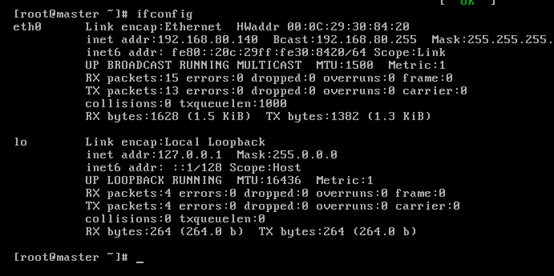

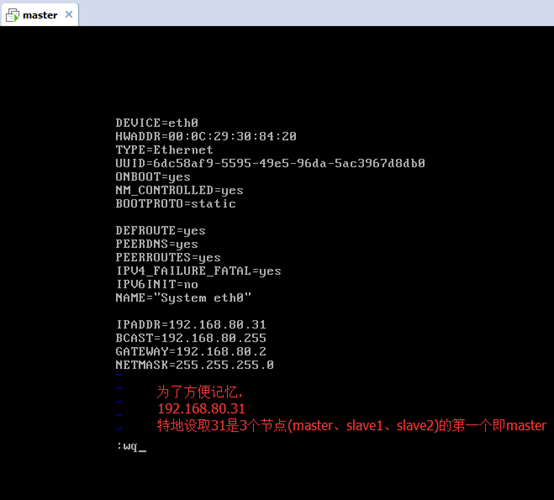
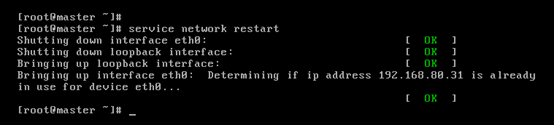
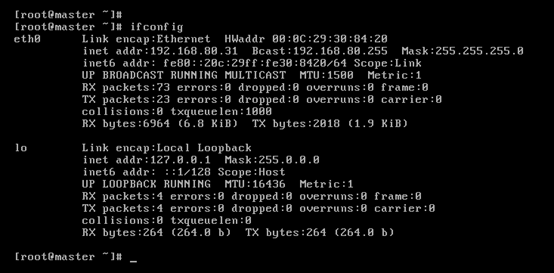

即,成功由原來的192.168.80.140(是動態獲取的)成功地,改變成了192.168.80.31(靜態的)

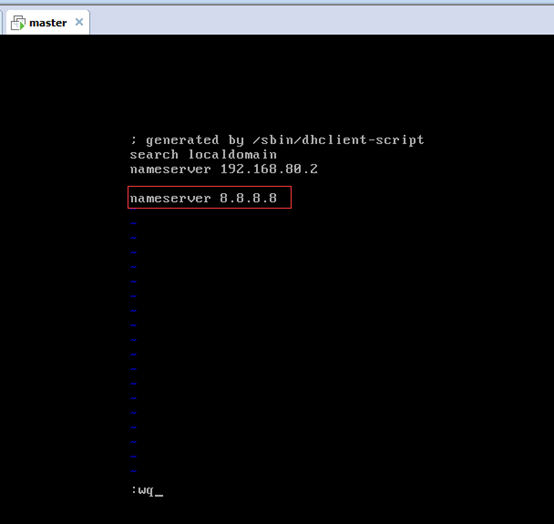
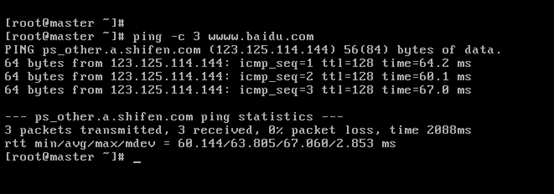
以上是master 的 192.168.80.31
對slave1而言,

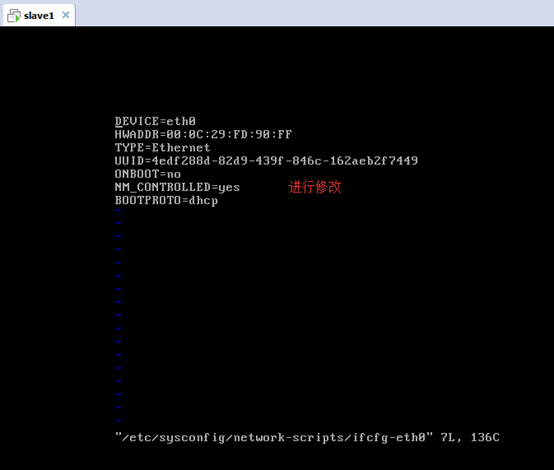
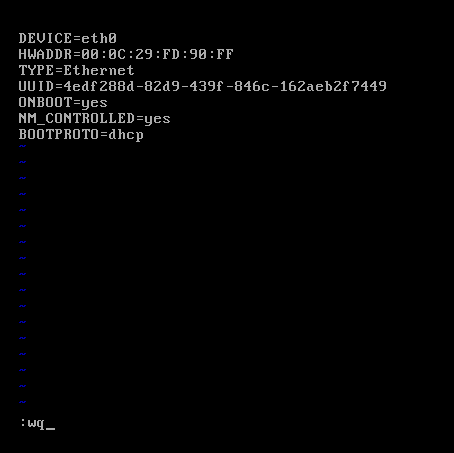
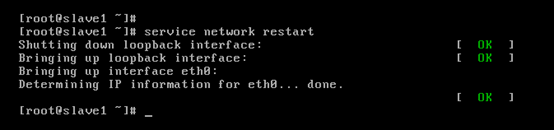
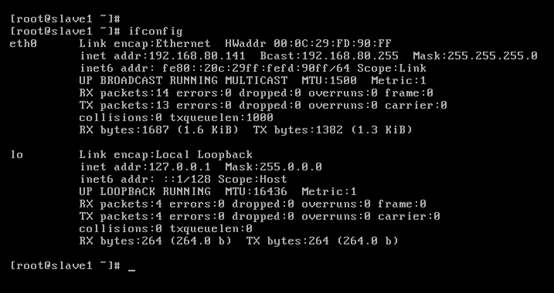


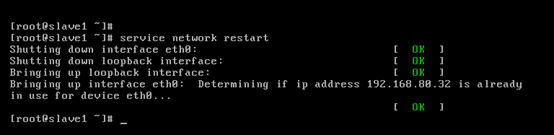
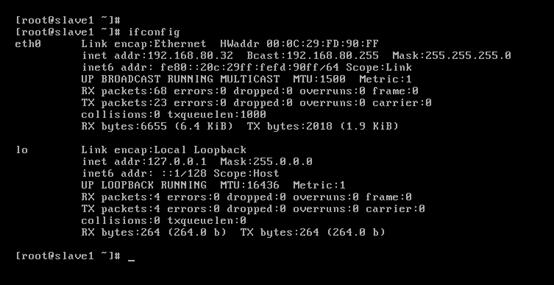

即,成功由原來的192.168.80.141(是動態獲取的)成功地,改變成了192.168.80.32(靜態的)

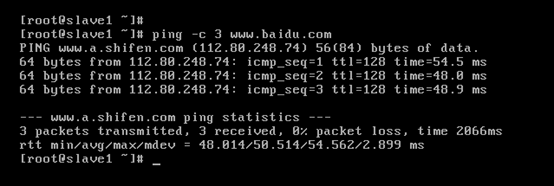
以上是slave1 的 192.168.80.32
對slave2而言,
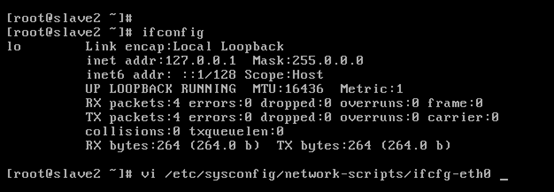


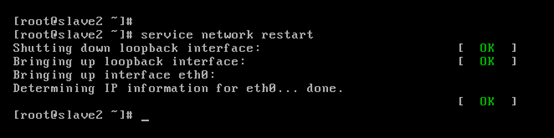
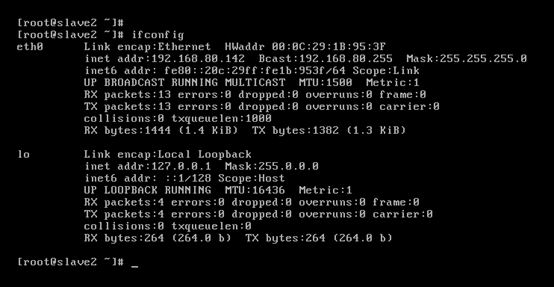

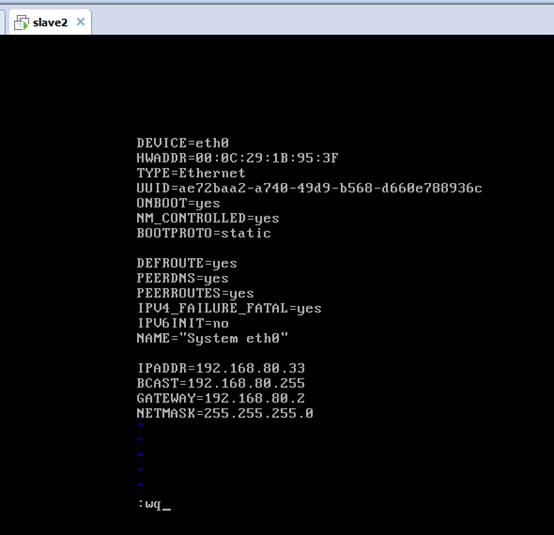
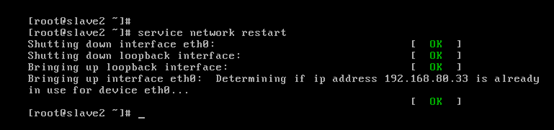
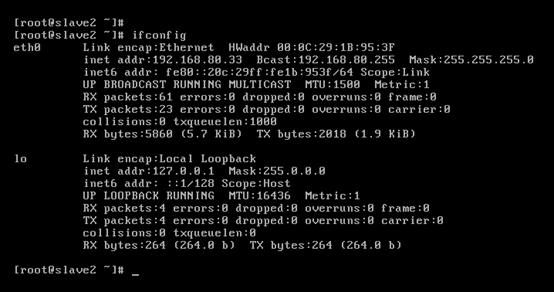

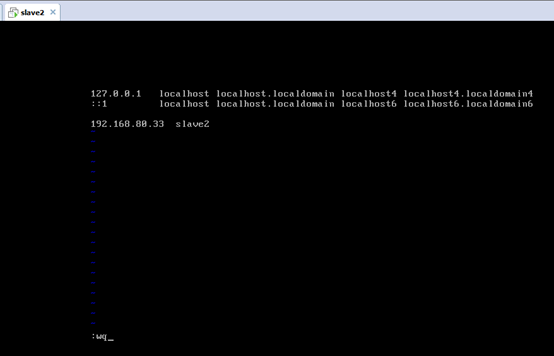
即,成功由原來的192.168.80.142(是動態獲取的)成功地,改變成了192.168.80.33(靜態的)


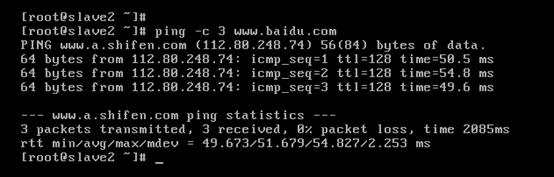
以上是slave2 的 192.168.80.33
開啟,C:\Windows\System32\drivers\etc
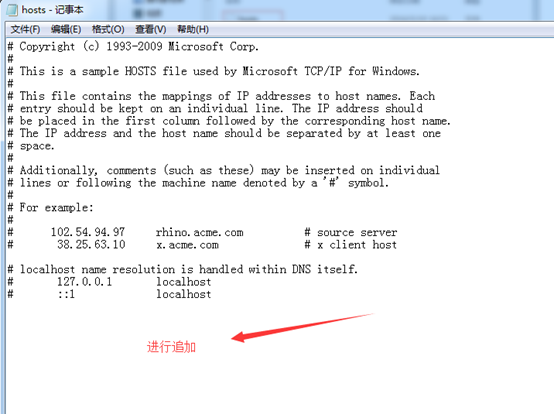

ssh master
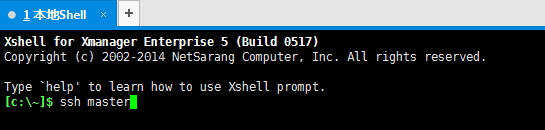

ssh slave1


ssh slave2

第二步:搭建一個3節點的hadoop分散式小叢集--預備工作(master、slave1、slave2的使用者規劃、目錄規劃)
1 使用者規劃
依次,對master、slave1、slave2進行使用者規劃,hadoop使用者組,hadoop使用者。
先新建使用者組,再來新建使用者 。
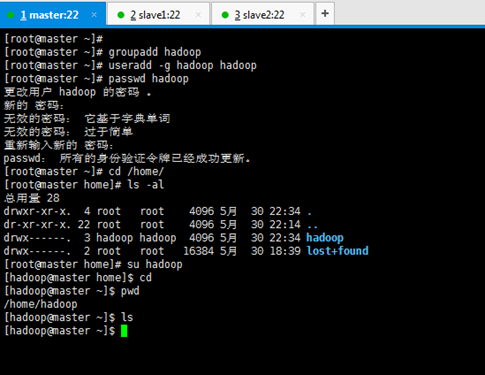
[[email protected] ~]# groupadd hadoop [[email protected] ~]# useradd -g hadoop hadoop (一般推薦用 useradd -g -m hadoop hadoop ) [[email protected] ~]# passwd hadoop [[email protected] ~]# cd /home/ [[email protected] home]# ls -al [[email protected] home]# su hadoop [[email protected] home]$ cd [[email protected] ~]$ pwd [[email protected] ~]$ ls [[email protected] ~]$
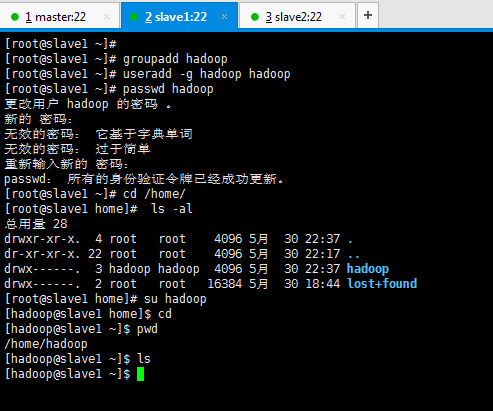
[[email protected] ~]# groupadd hadoop [[email protected] ~]# useradd -g hadoop hadoop [[email protected] ~]# passwd hadoop [[email protected] ~]# cd /home/ [[email protected] home]# ls -al [[email protected] home]# su hadoop [[email protected] home]$ cd [[email protected] ~]$ pwd [[email protected] ~]$ ls [[email protected] ~]$
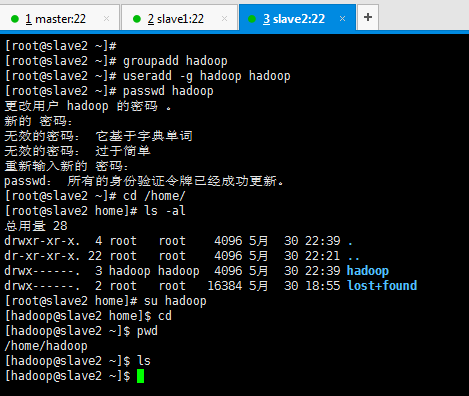
[[email protected] ~]# groupadd hadoop [[email protected] ~]# useradd -g hadoop hadoop [[email protected] ~]# passwd hadoop [[email protected] ~]# cd /home/ [[email protected] home]# ls -al [[email protected] home]# su hadoop [[email protected] home]$ cd [[email protected] ~]$ pwd [[email protected] ~]$ ls [[email protected] ~]$
2目錄規劃
依次,對master、slave1、slave2進行目錄規劃,
名稱 路徑
所有叢集安裝的軟體目錄 /home/hadoop/app/
所有臨時目錄 /tmp
這個是,系統會預設的臨時目錄是在/tmp下,而這個目錄在每次重啟後都會被刪掉,必須重新執行format才行,否則會出錯。
如果這裡,我們像下面這樣的話,

那麼得,事先在配置之前就要用root使用者建立/data/tmp。
暫時沒弄下面的
所有namenode節點產生的日誌 /data/dfs/name
所有datanode節點產生的日誌 /data/dfs/data
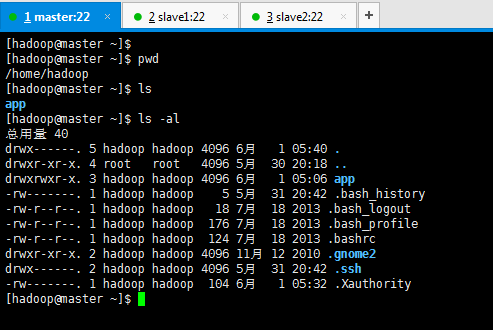
[[email protected] ~]$ mkdir app
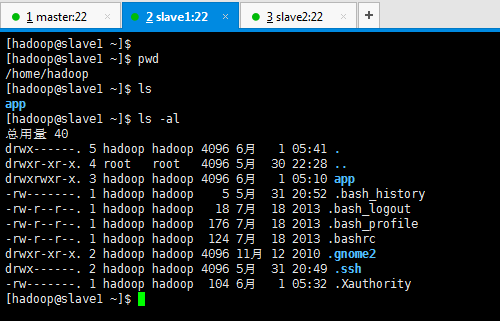
[[email protected] ~]$ mkdir app

[[email protected] ~]$ mkdir app
下面為這三臺機器分配IP地址及相應的角色
192.168.80.31-----master,namenode,jobtracker
192.168.80.32-----slave1,datanode,tasktracker
192.168.80.33----- slave2,datanode,tasktracker
第三步:搭建一個3節點的hadoop分散式小叢集--預備工作(master、slave1、slave2的環境檢查)
叢集安裝前的環境檢查
在叢集安裝之前,我們需要一個對其環境的一個檢查
時鐘同步
3.1 master

[[email protected] hadoop]# date [[email protected] hadoop]# cd /usr/share/zoneinfo/ [[email protected] zoneinfo]# ls [[email protected] zoneinfo]# cd Asia/ [[email protected] Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime cp:是否覆蓋"/etc/localtime"? y [[email protected] Asia]#
我們需要ntp命令,來實現時間的同步。


[[email protected] Asia]# pwd
[[email protected] Asia]# yum -y install ntp

[[email protected] Asia]# ntpdate pool.ntp.org
3.2 slave1
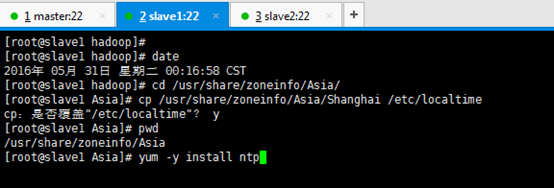
[[email protected] hadoop]# date [[email protected] hadoop]# cd /usr/share/zoneinfo/Asia/ [[email protected] Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime cp:是否覆蓋"/etc/localtime"? y [[email protected] Asia]# pwd /usr/share/zoneinfo/Asia [[email protected] Asia]# yum -y install ntp

[[email protected] Asia]# ntpdate pool.ntp.org
3.3 slave2
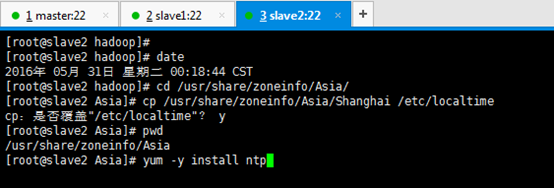
[[email protected] hadoop]# date [[email protected] hadoop]# cd /usr/share/zoneinfo/Asia/ [[email protected] Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime cp:是否覆蓋"/etc/localtime"? y [[email protected] Asia]# pwd /usr/share/zoneinfo/Asia [[email protected] Asia]# yum -y install ntp

[[email protected] Asia]# ntpdate pool.ntp.org
hosts檔案檢查
依次對master,slave1,slave2
master

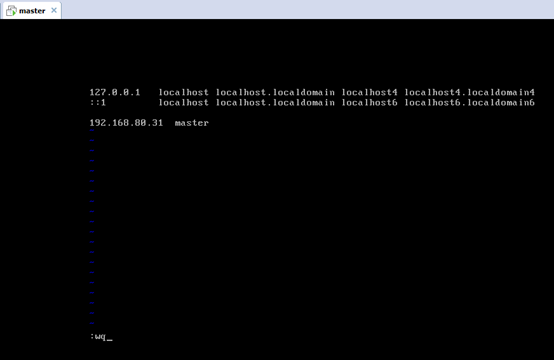
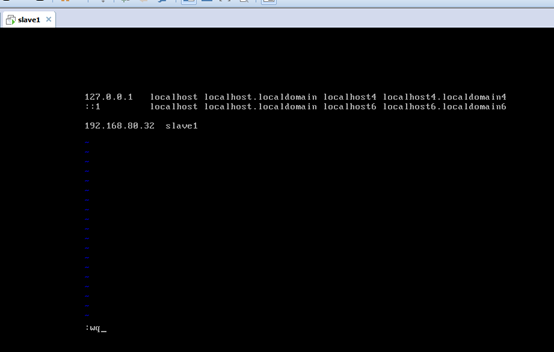
[[email protected] Asia]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
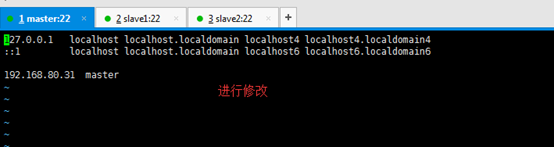
192.168.80.31 master
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
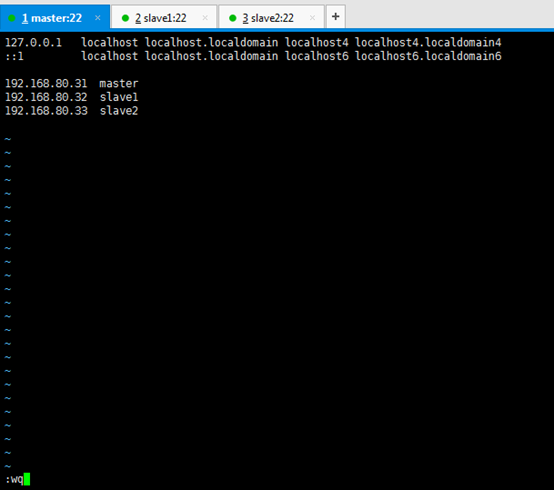
192.168.80.31 master 192.168.80.32 slave1 192.168.80.33 slave2
slave1

127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6

192.168.80.32 slave1
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
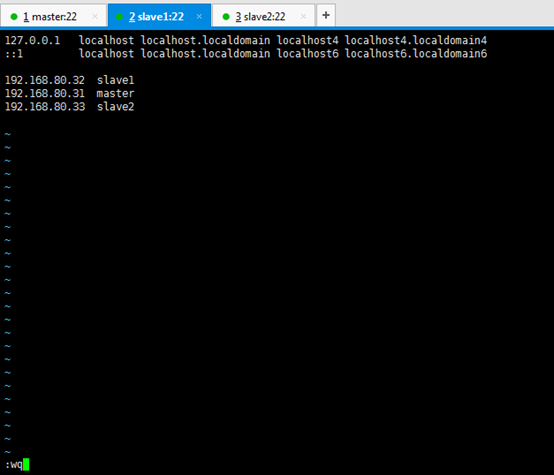
192.168.80.32 slave1 192.168.80.31 master 192.168.80.33 slave2
slave2

127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
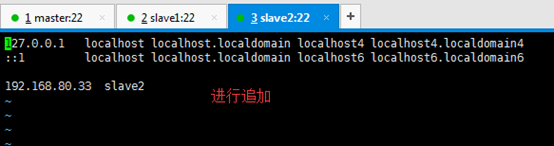
192.168.80.33 slave2
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
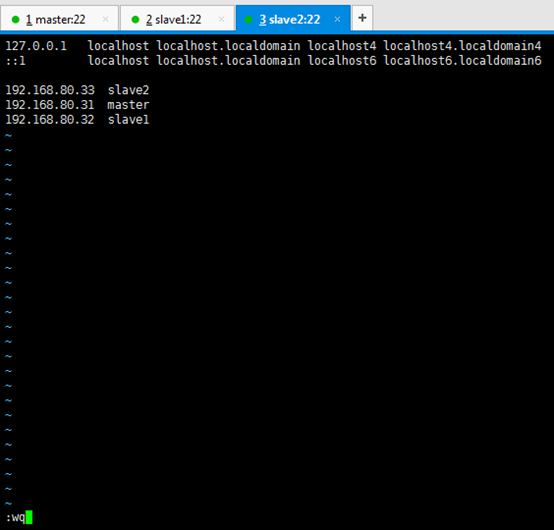
192.168.80.33 slave2 192.168.80.31 master 192.168.80.32 slave1
禁用防火牆
依次對master,slave1,slave2
在這裡哈,參考了很多,也諮詢了一些人。直接永久關閉吧。
master
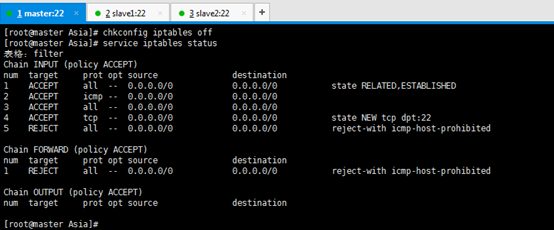
[[email protected] Asia]# chkconfig iptables off
[[email protected] Asia]# service iptables status
slave1
[[email protected] Asia]# chkconfig iptables off
[[email protected] Asia]# service iptables status
slave2
[[email protected] Asia]# chkconfig iptables off
[[email protected] Asia]# service iptables status
第四步:搭建一個3節點的hadoop分散式小叢集--預備工作(master、slave1、slave2的SSH免密碼通訊的配置)
SSH免密碼通訊的配置
1、每臺機器的各自本身的無密碼訪問
master
[[email protected] Asia]# su hadoop [[email protected] Asia]$ cd [[email protected] ~]$ cd .ssh [[email protected] ~]$ mkdir .ssh [[email protected] ~]$ ssh-keygen -t rsa (/home/hadoop/.ssh/id_rsa): (Enter鍵) Enter passphrase (empty for no passphrase): (Enter鍵) Enter same passphrase again: (Enter鍵)
[[email protected] ~]$ pwd [[email protected] ~]$ cd .ssh [[email protected] .ssh]$ ls [[email protected] .ssh]$ cat id_rsa.pub >> authorized_keys [[email protected] .ssh]$ ls [[email protected] .ssh]$ cat authorized_keys ssh-rsa [[email protected] .ssh]$ cd .. [[email protected] ~]$ chmod 700 .ssh [[email protected] ~]$ chmod 600 .ssh/* [[email protected] ~]$ ls -al
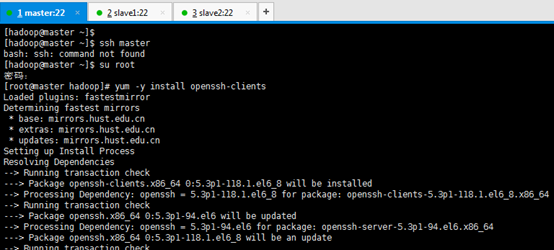
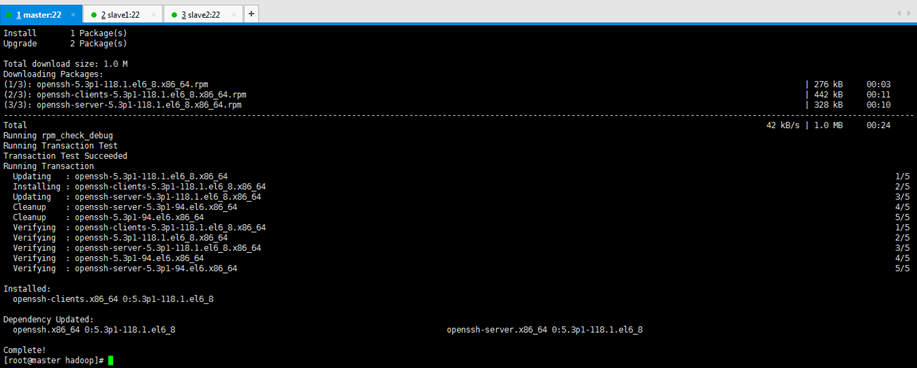
[[email protected] ~]$ ssh master [[email protected] ~]$ su root 密碼: [[email protected] hadoop]# yum -y install openssh-clients
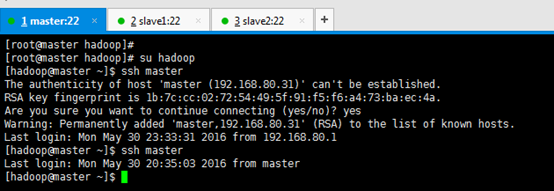
[[email protected] hadoop]# su hadoop [[email protected] ~]$ ssh master Are you sure you want to continue connecting (yes/no)? yes [[email protected] ~]$ ssh master
slave1
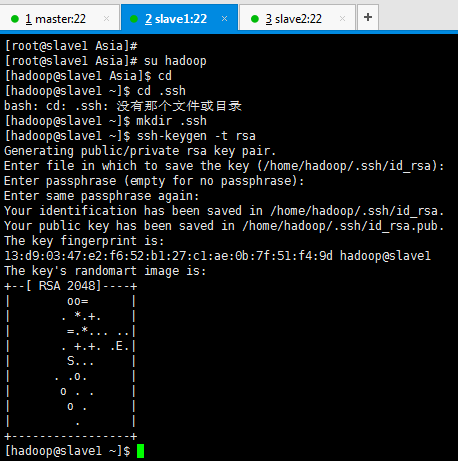
[[email protected] Asia]# su hadoop [[email protected] Asia]$ cd [[email protected] ~]$ cd .ssh [[email protected] ~]$ mkdir .ssh [[email protected] ~]$ ssh-keygen -t rsa (/home/hadoop/.ssh/id_rsa): (Enter鍵) Enter passphrase (empty for no passphrase): (Enter鍵) Enter same passphrase again: (Enter鍵)

[[email protected] ~]$ pwd [[email protected] ~]$ cd .ssh [[email protected] .ssh]$ ls [[email protected] .ssh]$ cat id_rsa.pub >> authorized_keys [[email protected] .ssh]$ ls [[email protected] .ssh]$ cat authorized_keys ssh-rsa [[email protected] .ssh]$ cd .. [[email protected] ~]$ chmod 700 .ssh [[email protected] ~]$ chmod 600 .ssh/* [[email protected] ~]$ ls -al
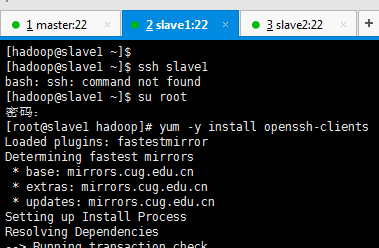
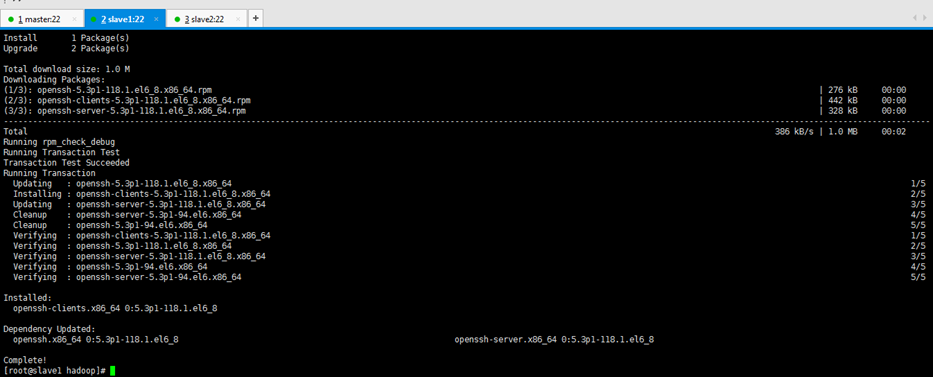
[[email protected] ~]$ ssh slave1 [[email protected] ~]$ su root [[email protected] hadoop]# yum -y install openssh-clients
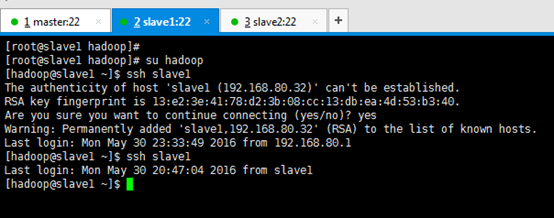
[[email protected] hadoop]# su hadoop [[email protected] ~]$ ssh slave1 Are you sure you want to continue connecting (yes/no)? yes [[email protected] ~]$ ssh slave1
slave2
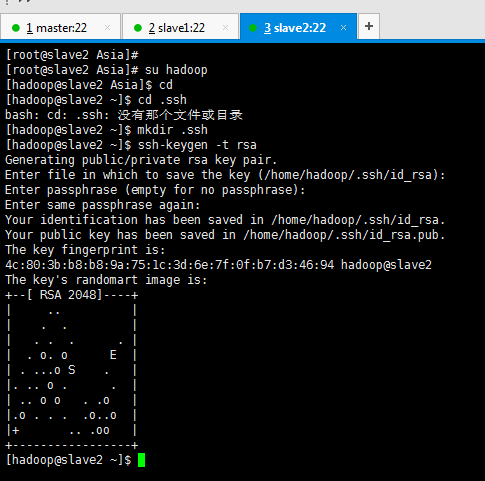
[[email protected] Asia]# su hadoop [[email protected] Asia]$ cd [[email protected] ~]$ cd .ssh [[email protected] ~]$ mkdir .ssh [[email protected] ~]$ ssh-keygen -t rsa (/home/hadoop/.ssh/id_rsa): (Enter鍵) Enter passphrase (empty for no passphrase): (Enter鍵) Enter same passphrase again: (Enter鍵)
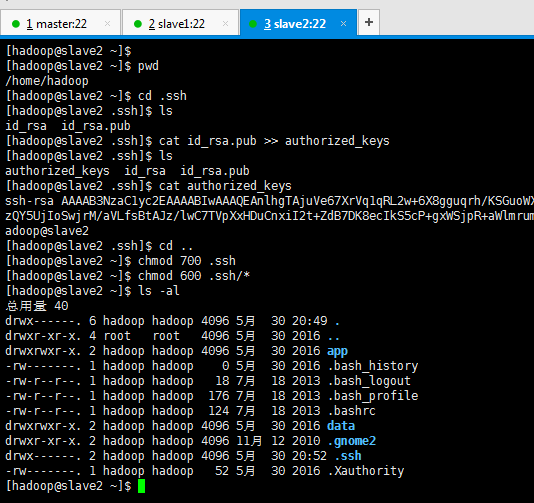
[[email protected] ~]$ pwd [[email protected] ~]$ cd .ssh [[email protected] .ssh]$ ls [[email protected] .ssh]$ cat id_rsa.pub >> authorized_keys [[email protected] .ssh]$ ls [[email protected] .ssh]$ cat authorized_keys ssh-rsa [[email protected] .ssh]$ cd .. [[email protected] ~]$ chmod 700 .ssh [[email protected] ~]$ chmod 600 .ssh/* [[email protected] ~]$ ls -al
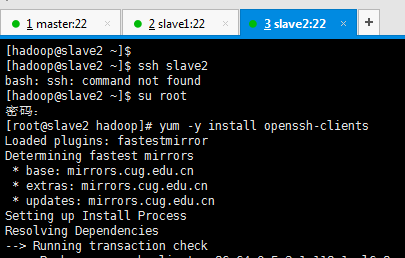
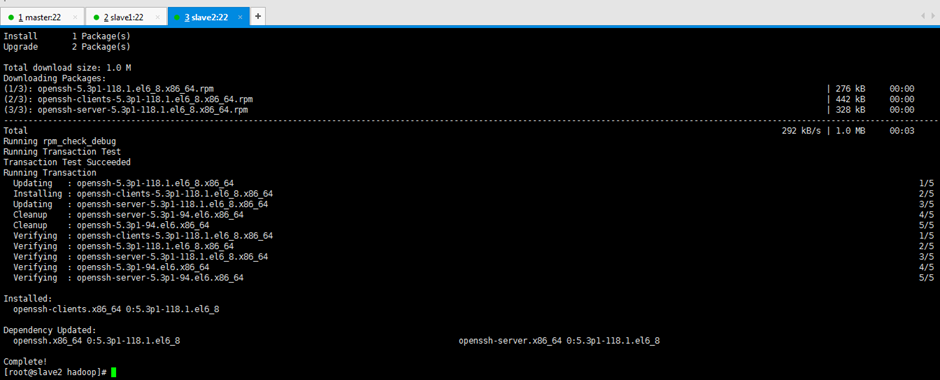
[[email protected] ~]$ ssh slave2 [[email protected] ~]$ su root [[email protected] hadoop]# yum -y install openssh-clients
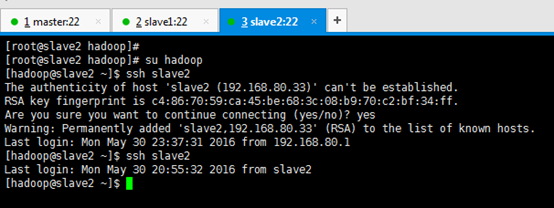
[[email protected] hadoop]# su hadoop [[email protected] ~]$ ssh slave2 Are you sure you want to continue connecting (yes/no)? yes [[email protected] ~]$ ssh slave2
到此,為止。每臺機器的各自本身的無密碼訪問已經成功設定好了
2、 每臺機器之間的無密碼訪問的設定
2.1連線master
完成slave1與master,slave2與msater
2.1.1完成slave1與master
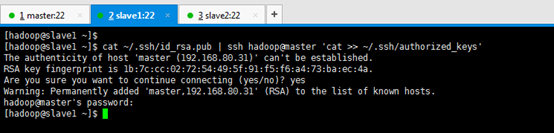
[[email protected] ~]$ cat ~/.ssh/id_rsa.pub | ssh [email protected] 'cat >> ~/.ssh/authorized_keys' Are you sure you want to continue connecting (yes/no)? yes [email protected]'s password:(是master的密碼)

[[email protected] ~]$ cd .ssh [[email protected] .ssh]$ ls [[email protected] .ssh]$ cat authorized_keys
2.1.2完成slave2與master

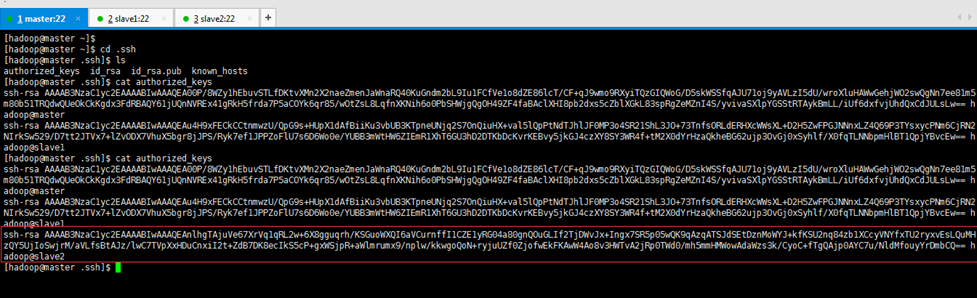
[[email protected] ~]$ cat ~/.ssh/id_rsa.pub | ssh [email protected] 'cat >> ~/.ssh/authorized_keys'
將master的authorized_keys,分發給slave1

[[email protected] .ssh]$ scp -r authorized_keys [email protected]:~/.ssh/ Are you sure you want to continue connecting (yes/no)? yes [email protected]'s password:(密碼是hadoop)
檢視

[[email protected] ~]$ cd .ssh [[email protected] .ssh]$ ls [[email protected] .ssh]$ cat authorized_keys
將master的authorized_keys,分發給slave2
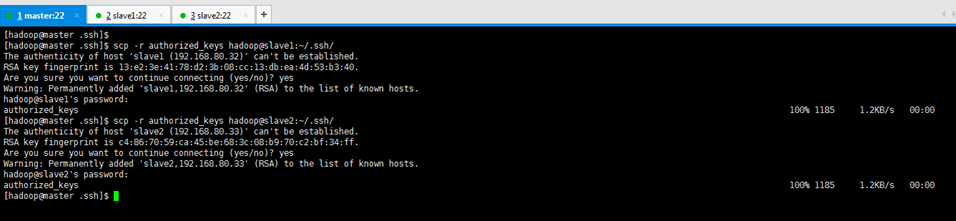
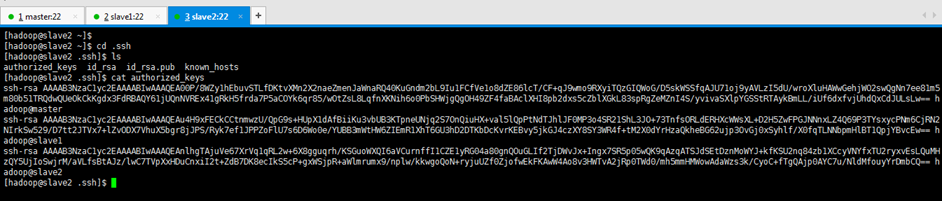
[[email protected] .ssh]$ scp -r authorized_keys [email protected]:~/.ssh/ Are you sure you want to continue connecting (yes/no)? yes [email protected]'s password:(密碼是hadoop)
至此,完成slave1與master,slave2與msater
現在,我們來互相測試下。
從master出發,
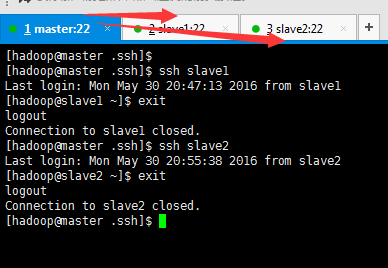
[[email protected] .ssh]$ ssh slave1
[[email protected] .ssh]$ ssh slave2
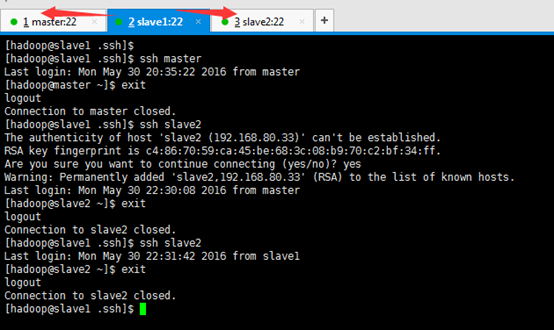
[[email protected] .ssh]$ ssh master [[email protected] ~]$ exit [[email protected] .ssh]$ ssh slave2 Are you sure you want to continue connecting (yes/no)? yes [[email protected] ~]$ exit [[email protected] .ssh]$ ssh slave2 [[email protected] ~]$ exit [[email protected] .ssh]$
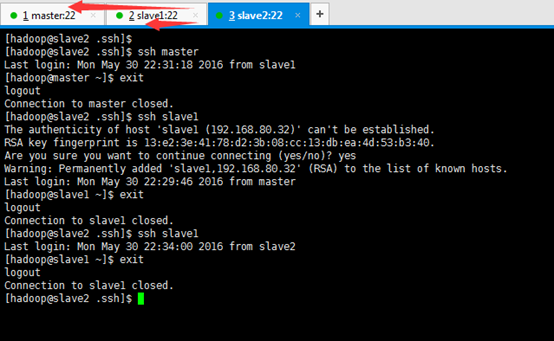
[[email protected] .ssh]$ ssh master [[email protected] ~]$ exit [[email protected] .ssh]$ ssh slave1 Are you sure you want to continue connecting (yes/no)? yes [[email protected] ~]$ exit [[email protected] .ssh]$ ssh slave1 [[email protected] ~]$ exit
至此,3節點的master、slave1、slave2的SSH免密碼通訊的配置,已經完成。
分:
第一步,各機器的各自本身間的免密碼通訊。
第二步,各機器的之間的免密碼通訊。
第五步:搭建一個3節點的hadoop分散式小叢集--預備工作(master、slave1、slave2的JDK安裝與配置)
master

[[email protected] ~]$ ls [[email protected] ~]$ cd app/ [[email protected] app]$ ls [[email protected] app]$ rz [[email protected] app]$ su root [[email protected] app]# yum -y install lrzsz