
【NLP】Python NLTK獲取文字語料和詞彙資源
作者:白寧超
2016年11月7日13:15:24
摘要:NLTK是由賓夕法尼亞大學計算機和資訊科學使用python語言實現的一種自然語言工具包,其收集的大量公開資料集、模型上提供了全面、易用的介面,涵蓋了分詞、詞性標註(Part-Of-Speech tag, POS-tag)、命名實體識別(Named Entity Recognition, NER)、句法分析(Syntactic Parse)等各項 NLP 領域的功能。本文主要介紹NLTK(Natural language Toolkit)的幾種語料庫,以及內建模組下函式的基本操作,諸如雙連詞、停用詞、詞頻統計、構造自己的語料庫等等,這些都是非常實用的。主要還是基礎知識,關於python方面知識,可以參看本人的【Python五篇慢慢彈】系列文章(本文原創編著,轉載註明出處:Python NLTK獲取文字語料和詞彙資源)
目錄
1 古騰堡語料庫
直接獲取語料庫的所有文字:nltk.corpus.gutenberg.fileids()
>>> import nltk >>> nltk.corpus.gutenberg.fileids()
執行結果:

匯入包獲取語料庫的所有文字
>>> from nltk.corpus import gutenberg >>> gutenberg.fileids() ['austen-emma.txt', 'austen-persuasion.txt', 'austen-sense.txt', 'bible-kjv.txt', 'blake-poems.txt', 'bryant-stories.txt', 'burgess-busterbrown.txt', 'carroll-alice.txt', 'chesterton-ball.txt', 'chesterton-brown.txt', 'chesterton-thursday.txt', 'edgeworth-parents.txt', 'melville-moby_dick.txt', 'milton-paradise.txt', 'shakespeare-caesar.txt', 'shakespeare-hamlet.txt', 'shakespeare-macbeth.txt', 'whitman-leaves.txt']
查詢某個文字
>>> persuasion=nltk.corpus.gutenberg.words("austen-persuasion.txt")
>>> len(persuasion)
98171
>>> persuasion[:200]
['[', 'Persuasion', 'by', 'Jane', 'Austen', '1818', ...]
查詢檔案識別符號
num_char = len(gutenberg.raw(fileid)) # 原始文字的長度,包括空格、符號等
num_words = len(gutenberg.words(fileid)) #詞的數量
num_sents = len(gutenberg.sents(fileid)) #句子的數量
num_vocab = len(set([w.lower() for w in gutenberg.words(fileid)])) #文字的尺寸
# 打印出平均詞長(包括一個空白符號,如下詞長是3)、平均句子長度、和文字中每個詞出現的平均次數
print(int(num_char/num_words),int(num_words/num_sents),int(num_words/num_vocab),fileid)
執行結果:

2 網路和聊天文字
獲取網路聊天文字
>>> from nltk.corpus import webtext >>> for fileid in webtext.fileids(): print(fileid,webtext.raw(fileid))
執行結果

檢視網路聊天文字資訊
>>> for fileid in webtext.fileids(): print(fileid,len(webtext.words(fileid)),len(webtext.raw(fileid)),len(webtext.sents(fileid)),webtext.encoding(fileid)) firefox.txt 102457 564601 1142 ISO-8859-2 grail.txt 16967 65003 1881 ISO-8859-2 overheard.txt 218413 830118 17936 ISO-8859-2 pirates.txt 22679 95368 1469 ISO-8859-2 singles.txt 4867 21302 316 ISO-8859-2 wine.txt 31350 149772 2984 ISO-8859-2
即時訊息聊天會話語料庫:
>>> from nltk.corpus import nps_chat
>>> chatroom = nps_chat.posts('10-19-20s_706posts.xml')
>>> chatroom[123]
['i', 'do', "n't", 'want', 'hot', 'pics', 'of', 'a', 'female', ',', 'I', 'can', 'look', 'in', 'a', 'mirror', '.']
3 布朗語料庫
檢視語料資訊:
>>> from nltk.corpus import brown >>> brown.categories() ['adventure', 'belles_lettres', 'editorial', 'fiction', 'government', 'hobbies', 'humor', 'learned', 'lore', 'mystery', 'news', 'religion', 'reviews', 'romance', 'science_fiction']
比較文體中情態動詞的用法:
>>> import nltk >>> from nltk.corpus import brown >>> new_texts=brown.words(categories='news') >>> fdist=nltk.FreqDist([w.lower() for w in new_texts]) >>> modals=['can','could','may','might','must','will'] >>> for m in modals: print(m + ':',fdist[m]) can: 94 could: 87 may: 93 might: 38 must: 53 will: 389
NLTK條件概率分佈函式:
>>> cfd=nltk.ConditionalFreqDist((genre,word) for genre in brown.categories() for word in brown.words(categories=genre)) >>> genres=['news','religion','hobbies','science_fiction','romance','humor'] >>> modals=['can','could','may','might','must','will'] >>> cfd.tabulate(condition=genres,samples=modals)
執行結果:

4 路透社語料庫
包括10788個新聞文件,共計130萬字,這些文件分90個主題,安裝訓練集和測試分組,編號‘test/14826’文件屬於測試
>>> from nltk.corpus import reuters >>> print(reuters.fileids()[:500])
執行結果:
檢視語料包括的前100個類別:>>> print(reuters.categories()[:100])

檢視語料尺寸:
>>> len(reuters.fileids()) 10788
檢視語料類別尺寸:
>>> len(reuters.categories()) 90
檢視某個編號的語料下類別尺寸:
>>> reuters.categories('training/9865')
['barley', 'corn', 'grain', 'wheat']
檢視某幾個聯合編號下語料的類別尺寸:
>>> reuters.categories(['training/9865','training/9880']) ['barley', 'corn', 'grain', 'money-fx', 'wheat']
檢視哪些編號的檔案屬於指定的類別:
>>> reuters.fileids('barley')
['test/15618', 'test/15649', 'test/15676', 'test/15728', 'test/15871', 'test/15875', 'test/15952', 'test/17767', 'test/17769', 'test/18024', 'test/18263', 'test/18908', 'test/19275', 'test/19668', 'training/10175', 'training/1067', 'training/11208', 'training/11316', 'training/11885', 'training/12428', 'training/13099', 'training/13744', 'training/13795', 'training/13852', 'training/13856', 'training/1652', 'training/1970', 'training/2044', 'training/2171', 'training/2172', 'training/2191', 'training/2217', 'training/2232', 'training/3132', 'training/3324', 'training/395', 'training/4280', 'training/4296', 'training/5', 'training/501', 'training/5467', 'training/5610', 'training/5640', 'training/6626', 'training/7205', 'training/7579', 'training/8213', 'training/8257', 'training/8759', 'training/9865', 'training/9958']
5 就職演說語料庫
檢視語料資訊:
>>> from nltk.corpus import inaugural >>> len(inaugural.fileids()) 56 >>> inaugural.fileids() ['1789-Washington.txt', '1793-Washington.txt', '1797-Adams.txt', '1801-Jefferson.txt', '1805-Jefferson.txt', '1809-Madison.txt', '1813-Madison.txt', '1817-Monroe.txt', '1821-Monroe.txt', '1825-Adams.txt', '1829-Jackson.txt', '1833-Jackson.txt', '1837-VanBuren.txt', '1841-Harrison.txt', '1845-Polk.txt', '1849-Taylor.txt', '1853-Pierce.txt', '1857-Buchanan.txt', '1861-Lincoln.txt', '1865-Lincoln.txt', '1869-Grant.txt', '1873-Grant.txt', '1877-Hayes.txt', '1881-Garfield.txt', '1885-Cleveland.txt', '1889-Harrison.txt', '1893-Cleveland.txt', '1897-McKinley.txt', '1901-McKinley.txt', '1905-Roosevelt.txt', '1909-Taft.txt', '1913-Wilson.txt', '1917-Wilson.txt', '1921-Harding.txt', '1925-Coolidge.txt', '1929-Hoover.txt', '1933-Roosevelt.txt', '1937-Roosevelt.txt', '1941-Roosevelt.txt', '1945-Roosevelt.txt', '1949-Truman.txt', '1953-Eisenhower.txt', '1957-Eisenhower.txt', '1961-Kennedy.txt', '1965-Johnson.txt', '1969-Nixon.txt', '1973-Nixon.txt', '1977-Carter.txt', '1981-Reagan.txt', '1985-Reagan.txt', '1989-Bush.txt', '1993-Clinton.txt', '1997-Clinton.txt', '2001-Bush.txt', '2005-Bush.txt', '2009-Obama.txt']
檢視演說語料的年份:
>>> [fileid[:4] for fileid in inaugural.fileids()] ['1789', '1793', '1797', '1801', '1805', '1809', '1813', '1817', '1821', '1825', '1829', '1833', '1837', '1841', '1845', '1849', '1853', '1857', '1861', '1865', '1869', '1873', '1877', '1881', '1885', '1889', '1893', '1897', '1901', '1905', '1909', '1913', '1917', '1921', '1925', '1929', '1933', '1937', '1941', '1945', '1949', '1953', '1957', '1961', '1965', '1969', '1973', '1977', '1981', '1985', '1989', '1993', '1997', '2001', '2005', '2009']
條件概率分佈
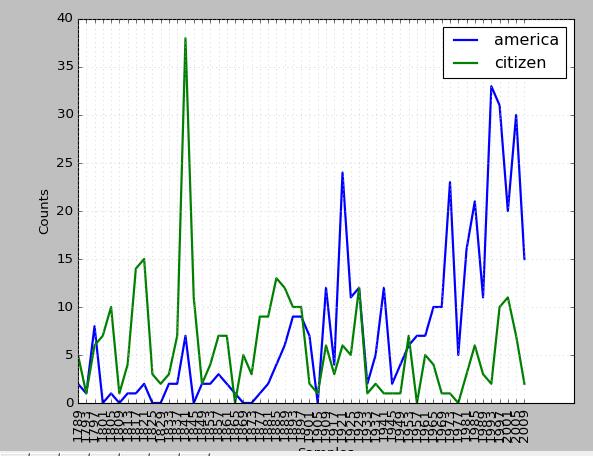
>>> import nltk >>> cfd=nltk.ConditionalFreqDist((target,fileid[:4]) for fileid in inaugural.fileids() for w in inaugural.words(fileid) for target in ['america','citizen'] if w.lower().startswith(target)) >>> cfd.plot()
執行結果:
標註文字語料庫 :許多語料庫都包括語言學標註、詞性標註、命名實體、句法結構、語義角色等
其他語言語料庫 :某些情況下使用語料庫之前學習如何在python中處理字元編碼
>>> nltk.corpus.cess_esp.words() ['El', 'grupo', 'estatal', 'Electricité_de_France', ...]
文字語料庫常見的幾種結構:
- 孤立的沒有結構的文字集;
- 按文體分類成結構(布朗語料庫)
- 分類會重疊的(路透社語料庫)
- 語料庫可以隨時間變化的(就職演說語料庫)
查詢NLTK語料庫函式help(nltk.corpus.reader)
6 載入自己的語料庫
構建自己語料庫
>>> from nltk.corpus import PlaintextCorpusReader
>>> corpus_root=r'E:\dict'
>>> wordlists=PlaintextCorpusReader(corpus_root,'.*')
>>> wordlists.fileids()
['dqdg.txt', 'q0.txt', 'q1.txt', 'q10.txt', 'q2.txt', 'q3.txt', 'q5.txt', 'text.txt']
>>> len(wordlists.words('text.txt')) #如果輸入錯誤或者格式不正確,notepad++轉換下編碼格式即可
152389
語料庫資訊:
構建完成自己語料庫之後,利用python NLTK內建函式都可以完成對應操作,換言之,其他語料庫的方法,在自己語料庫中通用,唯一的問題是,部分方法NLTK是針對英文語料的,中文語料不通用(典型的就是分詞),解決方法很多,諸如你通過外掛等在NLTK工具包內完成對中文的支援。另外也可以在NLTK中利用StandfordNLP工具包完成對自己語料的操作,這部分知識上節講解過。
7 條件概率分佈
條件頻率分佈是頻率分佈的集合,每一個頻率分佈有一個不同的條件,這個條件通常是文字的類別。
條件和事件:
頻率分佈計算觀察到的事件,如文字中出現的詞彙。條件頻率分佈需要給每個事件關聯一個條件,所以不是處理一個詞序列,而是處理一系列配對序列。
詞序列:text=['The','Fulton','County']
配對序列:pairs=[('news','The'),('news','Fulton')]
每隊形式:(條件,事件),如果我們按照文體處理整個布朗語料庫,將有15個條件(一個文體一個條件)和1161192個事件(一個詞一個事件)
按文體計算詞彙:
>>> from nltk.corpus import brown >>> cfd=nltk.ConditionalFreqDist((genre,word) for genre in brown.categories() for word in brown.words(categories=genre))
拆開來看,只看兩個文體:新聞和言情。對於每個文體,便利檔案中的每個詞以產生文體與詞配對
>>> genre_word=[(genre,word) for genre in ['news','romance'] for word in brown.words(categories=genre)] >>> len(genre_word) 170576
文體_詞匹配
>>> genre_word[:4]
[('news', 'The'), ('news', 'Fulton'), ('news', 'County'), ('news', 'Grand')]
>>> genre_word[-4:]
[('romance', 'afraid'), ('romance', 'not'), ('romance', "''"), ('romance', '.')]
條件頻率:
>>> cfd=nltk.ConditionalFreqDist(genre_word) >>> cfd <ConditionalFreqDist with 2 conditions> >>> cfd.conditions() ['romance', 'news'] >>> len(cfd['news']) 14394 >>> len(cfd['romance']) 8452
訪問條件下的詞彙表
>>> from nltk.corpus import brown >>> import nltk >>> cfd=nltk.ConditionalFreqDist((genre,word) for genre in brown.categories() for word in brown.words(categories=genre)) >>> len(list(cfd['romance'])) 8452 >>> len(set(cfd['romance'])) 8452 >>> cfd['news']['The'] 806
繪製分佈圖和分佈表
>>> cfd=nltk.ConditionalFreqDist((target,fileid[:4]) for fileid in inaugural.fileids() for word in inaugural.words(fileid) for target in ['america','citizen'] if word.lower().startswith(target)) >>> cfd.plot(cumulative=True)
執行結果:

生成表格形式展示:
cfd.tabulate(conditions=['English','The'],samples=range(10),cumulative=True)
執行結果:

conditions=['English','The'],限定條件
samples=range(10),指定樣本數
8 更多關於python:程式碼重用
使用雙連詞生成隨機文字: bigrams()函式能接受一個詞彙連結串列,並建立一個連詞的詞對連結串列
>>> sent=['Emma', 'Woodhouse', ',', 'handsome', ',', 'clever', ',', 'and', 'rich', ',', 'with', 'a', 'comfortable', 'home', 'and', 'happy', 'disposition', ',', 'seemed', 'to', 'unite', 'some', 'of', 'the', 'best', 'blessings', 'of', ] >>> nltk.bigrams(sent) <generator object bigrams at 0x0103C180>
產生隨機文字:定義一個程式獲取《創世紀》文字中所有的雙連詞,然後構造一個條件頻率分佈來記錄哪些詞彙最有可能跟在後面,例如living後面可以是creature。定義一個這樣的函式如下:Crtl+N,編輯函式指令碼
import nltk
def generate_model(cfdist,word,num=15):
for i in range(num):
print(word)
word=cfdist[word].max()
text = nltk.corpus.genesis.words('english-kjv.txt')
bigrams = nltk.bigrams(text)
cfd=nltk.ConditionalFreqDist(bigrams)
F5呼叫執行函式:
========================== RESTART: E:/Python/1.py ==========================
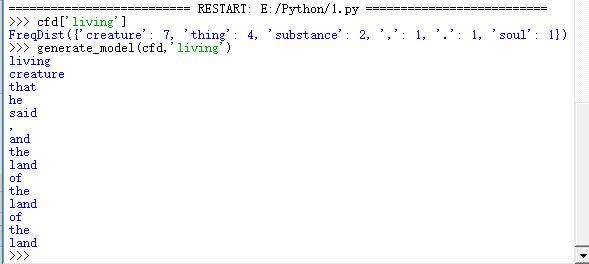
>>> cfd['living']
FreqDist({'creature': 7, 'thing': 4, 'substance': 2, ',': 1, '.': 1, 'soul': 1})
>>> generate_model(cfd,'living')
執行結果:
Crtl+N開啟IDE編輯器,輸入以下模組
class MyHello:
def hello():
print("Hello Python")
def bnc():
print("Hello BNC")
def add(num1,num2):
print("The sum is \t",str(num1+num2))
Crtl+S儲存到本地命名hello.py,並F5執行
============== RESTART: E:/sourceCode/NLPPython/day_03/hello.py ============== >>> from hello import * >>> MyHello.add(1,2) The sum is 3 >>> MyHello.hello() Hello Python
詞典資源: 詞典或者詞典資源是一個詞和短語及其相關資訊的集合。 詞彙列表語料庫:
過濾文字:此程式計算文字詞彙表,然後刪除所有出現在現有詞彙列表中出現的元素,只留下罕見的或者拼寫錯誤的詞彙 Crtl+N開啟IDE編輯器,輸入以下模組
class WordsPro:
def unusual_words(text):
text_vocab=set(w.lower() for w in text if w.isalpha())
english_vocab=set(w.lower() for w in nltk.corpus.words.words())
unusual=text_vocab.difference(english_vocab)
return sorted(unusual)
Crtl+S儲存到本地命名WordsPro.py,並F5執行
========================== RESTART: E:/Python/1.py ==========================
>>> import nltk
>>> from nltk.corpus import gutenberg
>>> len(WordsPro.unusual_words(nltk.corpus.gutenberg.words('austen-sense.txt')))
1601
>>>
停用詞語料庫:包括高頻詞如,the、to和and等。
>>> from nltk.corpus import stopwprds
>>> stopwords.words('english')
定義一個函式來計算文字中不包含停用詞列表的詞所佔的比例,Crtl+N開啟IDE編輯器,輸入以下模組
def content_faction(text):
stopwords=nltk.corpus.stopwords.words('english')
content = [w for w in text if w.lower() not in stopwords]
return len(content)/len(text)
Crtl+S儲存到本地命名WordsPro.py,並F5執行
>>> import nltk >>> from nltk.corpus import reuters >>> WordsPro.content_faction(nltk.corpus.reuters.words()) 0.735240435097661
詞迷遊戲:3*3的方格出現不同的9個字母,隨機選擇一個字母並利用這個字母組詞,要求如下:
1)詞長大於或等於4,且每個字母只能使用一次
2)至少有一個9字母的詞
3)能組成21個詞為好,32個詞很好,42個詞非常好
python 程式:
>>> import nltk
>>> puzzle_letters = nltk.FreqDist('egivrvonl')
>>> obligatory = 'r'#預設選擇r
>>> wordlist=nltk.corpus.words.words()
>>> [w for w in wordlist if len(w) >=6 and obligatory in w and nltk.FreqDist(w)<=puzzle_letters]
執行結果

詞彙工具:Toolbox和Shoebox
Toolbox下載http://www-01.sil.org/computing/toolbox/
9 python 實戰:資料文字分詞並去除停用詞操作:停用詞包下載
1 對資料文字進行分詞
2 構建自己停用詞語料庫
3 去除停用詞
>>> from nltk.tokenize.stanford_segmenter import StanfordSegmenter
>>> segmenter = StanfordSegmenter(
path_to_jar=r"E:\tools\stanfordNLTK\jar\stanford-segmenter.jar",
path_to_slf4j=r"E:\tools\stanfordNLTK\jar\slf4j-api.jar",
path_to_sihan_corpora_dict=r"E:\tools\stanfordNLTK\jar\data",
path_to_model=r"E:\tools\stanfordNLTK\jar\data\pku.gz",
path_to_dict=r"E:\tools\stanfordNLTK\jar\data\dict-chris6.ser.gz"
)
>>> with open(r"C:\Users\cuitbnc\Desktop\dqdg.txt","r+") as f:
str=f.read()
>>> result = segmenter.segment(str)
>>> with open(r"C:\Users\cuitbnc\Desktop\text1.txt","w") as wf:
wf.write(result)
1122469
>>> from nltk.corpus import PlaintextCorpusReader
>>> corpus_root=r'E:\dict\StopWord'
>>> wordlists=PlaintextCorpusReader(corpus_root,'.*')
>>> wordlists.fileids()
['baidu.txt', 'chuangda.txt', 'hagongda.txt', 'zhongwen.txt', '中文停用詞庫.txt', '四川大學機器智慧實驗室停用詞庫.txt']
>>> len(wordlists.words('hagongda.txt'))
977
>>> wordlists.words('hagongda.txt')[:100]
['———', '》),', ')÷(', '1', '-', '”,', ')、', '=(', ':', ...]
>>> stopwords=wordlists.words('hagongda.txt')
>>> content = [w for w in result if w not in stopwords]
相關推薦
【NLP】Python NLTK獲取文字語料和詞彙資源
作者:白寧超 2016年11月7日13:15:24 摘要:NLTK是由賓夕法尼亞大學計算機和資訊科學使用python語言實現的一種自然語言工具包,其收集的大量公開資料集、模型上提供了全面、易用的介面,涵蓋了分詞、詞性標註(Part-Of-Speech tag, POS-tag)、命名實體識別(Name
【NLP】Python NLTK處理原始文字
作者:白寧超 2016年11月8日22:45:44 摘要:NLTK是由賓夕法尼亞大學計算機和資訊科學使用python語言實現的一種自然語言工具包,其收集的大量公開資料集、模型上提供了全面、易用的介面,涵蓋了分詞、詞性標註(Part-Of-Speech tag, POS-tag)、命名實體識別(Name
【NLP】Python NLTK 走進大秦帝國
sorted([w for w in set(text1) if w.endswith('ableness')]) sorted([term for term in set(text4) if 'gnt' in term]) sorted([item for item in set(text6) if
獲得文字語料和詞彙資源(一)
#python3 import nltk nltk.corpus.gutenberg.fileids()#古騰堡專案 emma=nltk.corpus.gutenberg.words('austen-e
【NLP】Python例項:基於文字相似度對申報專案進行查重設計
作者:白寧超 2017年5月18日17:51:37 摘要:關於查重系統很多人並不陌生,無論本科還是碩博畢業都不可避免涉及論文查重問題,這也對學術不正之風起到一定糾正作用。單位主要針對科技專案申報稽核,傳統的方式人力物力比較大,且伴隨季度性的繁重工作,效率不高。基於此,單位覺得開發一款可以達到實用的
【NLP】Python實例:基於文本相似度對申報項目進行查重設計
用戶 strip() 字符串 執行 原創 這樣的 string 得到 亂碼問題 Python實例:申報項目查重系統設計與實現 作者:白寧超 2017年5月18日17:51:37 摘要:關於查重系統很多人並不陌生,無論本科還是碩博畢業都不可避免涉及論文查重問題,這也
【轉】python中獲取python版本號的方法
n) https href light nor body true print brush 原文 python3 #!/usr/bin/python # 第1種方法 import platform print(platform.python_version())
NLP之路-檢視獲取文字語料庫
繼續學習NLP in Python #coding=UTF-8 #上面一句解決中文註釋編碼錯誤問題 import nltk #檢視獲取到的文字語料庫 nltk.corpus.gutenberg.fil
【轉載】Python tips: 什麼是*args和**kwargs? Python tips: 什麼是*args和**kwargs?
轉自Python tips: 什麼是*args和**kwargs? 先來看個例子: def foo(*args, **kwargs): print 'args = ', args print 'kwargs = ', kwargs print '------------------
【爬蟲】Python Scrapy 基礎概念 —— 請求和響應
Typically, spiders 中會產生 Request 物件,然後傳遞 across the system, 直到他們到達 Downloader, which 執行請求並返回一個 Response 物件 which travels back to the
奮戰聊天機器人(二)語料和詞彙資源
當代自然語言處理都是基於統計的,統計自然需要很多樣本,因此語料和詞彙資源是必不可少的 1. NLTK語料庫 NLTK包含多種語料庫,比如:Gutenberg語料庫 nltk.corpus.gutenberg.fileids() nltk.cor
【NLP】乾貨!Python NLTK結合stanford NLP工具包進行文字處理
Python 3.5.2 (v3.5.2:4def2a2901a5, Jun 25 2016, 22:01:18) [MSC v.1900 32 bit (Intel)] on win32 Type "copyright", "credits" or "license()" for more infor
【NLP】CNN文字分類原理及python程式碼實現
CNN分類模型架構 python程式碼實現: #!/usr/bin/python # -*- coding: utf-8 -*- import tensorflow as tf class TCNNConfig(object): #class TCNNConfig(
【NLP】3000篇搜狐新聞語料資料前處理器的python實現
#coding=utf-8 import os import jieba import sys import re import time import jieba.posseg as pseg sys.path.append("../") jieba.load_userdict(".
【NLP】【十一】基於RNN和tf.keras 實現文字生成
【一】宣告 本文源自TensorFlow官方指導(https://tensorflow.google.cn/tutorials/sequences/text_generation),增加了部分細節說明。 【二】綜述 1. tf.keras與keras有如下三個較大的不同點 1):op
python自然語言處理——2.1 獲取文字語料庫
微信公眾號:資料運營人本系列為博主的讀書學習筆記,如需轉載請註明出處。 第二章 獲取文字預料和詞彙資源 2.1 獲取文字語料庫古騰堡語料庫網路和聊天文字布朗語料庫路透社語料庫就職演說語料庫標註文字語料庫其他文字語料庫文字語料庫結構 2.1 獲取文字語料庫 一個文字語料庫是一
【NLP】知乎文字分類比賽第一名筆記
知乎“看山杯” 奪冠記 陳雲 研究僧 537 人讚了該文章 知乎看山杯奪冠記 Update:2017-09-03: 新增2.6訓練方法說明 七月,酷暑難耐,認識的幾位同學參加知乎看山杯,均取得不錯的排名。當時天池AI醫療大賽初賽結束,官方正在為
【NLP】Tika 文字預處理:抽取各種格式檔案內容
作者 白寧超 2016年3月30日18:57:08 摘要:本文主要針對自然語言處理(NLP)過程中,重要基礎部分抽取文字內容的預處理。首先我們要意識到預處理的重要性。在大資料的背景下,越來越多的非結構化半結構化文字。如何從海量文字中抽取我們需要的有價值的知識顯得尤為重要。另外文字格式常常不一,諸
【Python】python檔案或文字加密(4種方法)
Date: 2018.6.17 端午 1、參考 2、python下編譯py成pyc和pyo (檔案加密) 將python檔案.py編譯成pyc二進位制檔案: python -m py_file.py 或者通過指令碼執行: imp
【nlp】文字情感分析
基於詞典的情感分析 情感分析物件的粒度最小是詞彙,但是表達一個情感的最基本的單位則是句子,詞彙雖然能描述情感的基本資訊,但是單一的詞彙缺少物件,缺少關聯程度,並且不同的詞彙組合在一起所得到的情感程度不同甚至情感傾向都相反。所以以句子為最基本的情感分析粒度是較為