
【Machine Learning】決策樹案例:基於python的商品購買能力預測系統
作者:白寧超
2016年12月24日22:05:42
摘要:隨著機器學習和深度學習的熱潮,各種圖書層出不窮。然而多數是基礎理論知識介紹,缺乏實現的深入理解。本系列文章是作者結合視訊學習和書籍基礎的筆記所得。本系列文章將採用理論結合實踐方式編寫。首先介紹機器學習和深度學習的範疇,然後介紹關於訓練集、測試集等介紹。接著分別介紹機器學習常用演算法,分別是監督學習之分類(決策樹、臨近取樣、支援向量機、神經網路演算法)監督學習之迴歸(線性迴歸、非線性迴歸)非監督學習(K-means聚類、Hierarchical聚類)。本文采用各個演算法理論知識介紹,然後結合python具體實現原始碼和案例分析的方式
目錄
1 決策樹/判定樹(decision tree)
1 決策樹(Dicision Tree)是機器學習有監督演算法中分類演算法的一種,有關機器學習中分類和預測演算法的評估主要體現在:
- 準確率:預測的準確與否是本演算法的核心問題,其在徵信系統,商品購買預測等都有應用。
- 速度:一個好的演算法不僅要求具備準確性,其執行速度也是衡量重要標準之一。
- 強壯行:具備容錯等功能和擴充套件性等。
- 可規模性:能夠應對現實生活中的實際案例
- 可解釋性:執行結果能夠說明其含義。
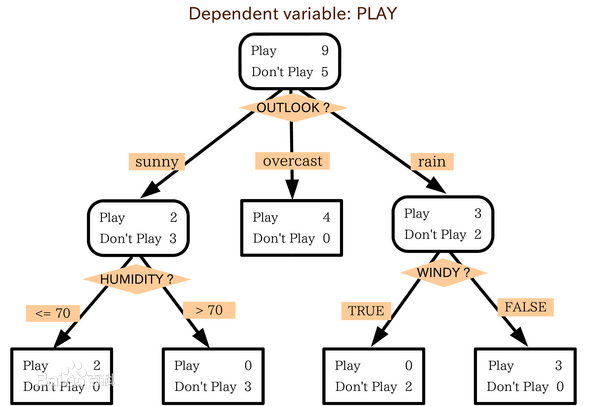
2 構造決策樹的基本演算法:判定顧客對商品購買能力
2.1 演算法結果圖:
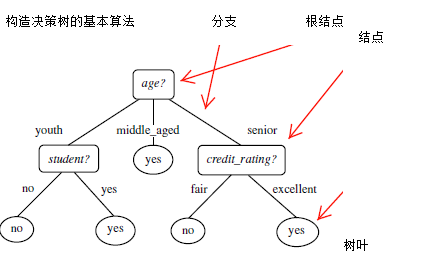
根據決策樹分析如下客戶資料,判定新客戶購買力。其中
客戶年齡age:青年、中年、老年
客戶收入income:低、中、高
客戶身份student:是學生,不是學生
客戶信用credit_rating:信用一般,信用好
是否購買電腦buy_computer:購買、不購買

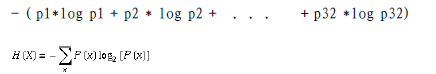 1 當每個球隊奪冠概率相等時候,32支參加世界盃奪冠球隊的資訊熵是5,計算是2^5=32,也就是你5次可以猜對那支球隊奪冠。
2 當球隊奪冠概率不相等,比如巴西、德國、荷蘭是強隊概率較大,資訊熵就小於5,也就是你用不到5次就可以猜出哪個球隊奪冠。
注:變數的不確定性越大,熵也就越大
2.3 決策樹歸納演算法 (ID3)
1970-1980, J.Ross. Quinlan首先提出ID3演算法,第一步是選擇屬性判斷結點,我們採用資訊熵的比較。第二步是資訊獲取量(Information Gain):Gain(A) = Info(D) - Infor_A(D)通過A來作為節點分類獲取了多少資訊
1 當每個球隊奪冠概率相等時候,32支參加世界盃奪冠球隊的資訊熵是5,計算是2^5=32,也就是你5次可以猜對那支球隊奪冠。
2 當球隊奪冠概率不相等,比如巴西、德國、荷蘭是強隊概率較大,資訊熵就小於5,也就是你用不到5次就可以猜出哪個球隊奪冠。
注:變數的不確定性越大,熵也就越大
2.3 決策樹歸納演算法 (ID3)
1970-1980, J.Ross. Quinlan首先提出ID3演算法,第一步是選擇屬性判斷結點,我們採用資訊熵的比較。第二步是資訊獲取量(Information Gain):Gain(A) = Info(D) - Infor_A(D)通過A來作為節點分類獲取了多少資訊
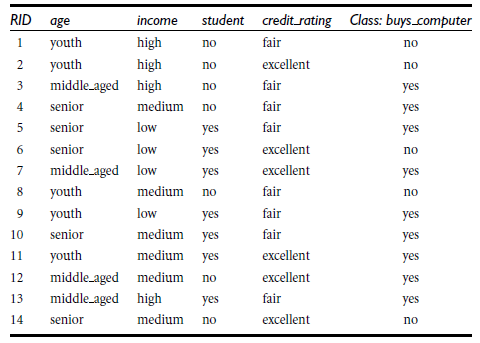
詳解:
資訊獲取量/資訊增益(Information Gain):Gain(A) = Info(D) - Infor_A(D),例如age的資訊增益,Gain(age) = Info(buys_computer) - Infor_age(buys_computer)。
Info(buys_computer)是這14個記錄中,購買的概率9/14,不購買的5/14,帶入到資訊熵公式。
Infor_age(buys_computer)是age屬性中,青年5/14購買概率是2/5,不購買3/5;中年4/14購買概率是1,不購買概率是0,老年5/14購買概率3/5,不購買概率是2/5.分別代入資訊熵公式
Info(buys_computer)與Infor_age(buys_computer)做差,即是age的資訊增益,具體如下:
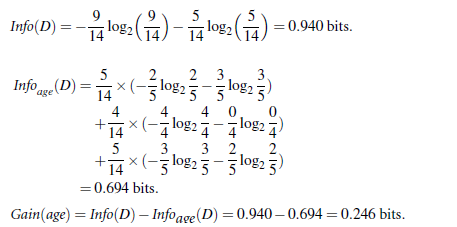
類似,Gain(income) = 0.029, Gain(student) = 0.151, Gain(credit_rating)=0.048
所以,選擇資訊增益最大的作為根節點即age作為第一個根節點 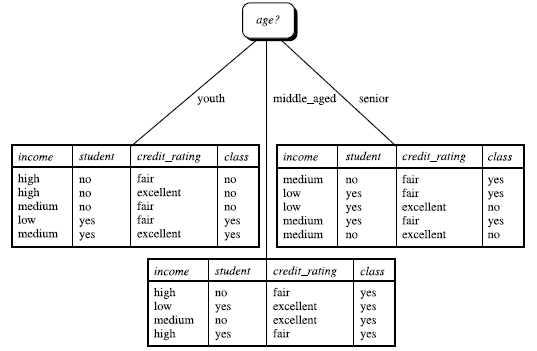
- 樹以代表訓練樣本的單個結點開始(步驟1)。
- 如果樣本都在同一個類,則該結點成為樹葉,並用該類標號(步驟2 和3)。
- 否則,演算法使用稱為資訊增益的基於熵的度量作為啟發資訊,選擇能夠最好地將樣本分類的屬性(步驟6)。該屬性成為該結點的“測試”或“判定”屬性(步驟7)。在演算法的該版本中,
- 所有的屬性都是分類的,即離散值。連續屬性必須離散化。
- 對測試屬性的每個已知的值,建立一個分枝,並據此劃分樣本(步驟8-10)。
- 演算法使用同樣的過程,遞迴地形成每個劃分上的樣本判定樹。一旦一個屬性出現在一個結點上,就不必該結點的任何後代上考慮它(步驟13)。
- 遞迴劃分步驟僅當下列條件之一成立停止:
- (a) 給定結點的所有樣本屬於同一類(步驟2 和3)。
- (b) 沒有剩餘屬性可以用來進一步劃分樣本(步驟4)。在此情況下,使用多數表決(步驟5)。
- 這涉及將給定的結點轉換成樹葉,並用樣本中的多數所在的類標記它。替換地,可以存放結
- 點樣本的類分佈。
- (c) 分枝
- test_attribute = a i 沒有樣本(步驟11)。在這種情況下,以 samples 中的多數類
- 建立一個樹葉(步驟12)
在決策樹ID3基礎上,又進行了演算法改進,衍生出 其他演算法如:C4.5: (Quinlan) 和Classification and Regression Trees (CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)。這些演算法
共同點:都是貪心演算法,自上而下(Top-down approach)
區別:屬性選擇度量方法不同: C4.5 (gain ratio,增益比), CART(gini index,基尼指數), ID3 (Information Gain,資訊增益) 2.5 如何處理連續性變數的屬性? 有些資料是連續性的,其不像如上實驗資料可以離散化表示。諸如根據天氣情況預測打球案例中,其溼度是一個連續值,我們的做法是將溼度70作為一個分界點,這裡就是連續變數離散化的體現。 2.6 補充知識 樹剪枝葉 (避免overfitting):為了避免擬合問題,我們可以對歸於繁瑣的樹進行剪枝(就是降低樹的高度),可以分為先剪枝和後剪枝。 決策樹的優點:直觀,便於理解,小規模資料集有效 決策樹的缺點:處理連續變數不好、類別較多時,錯誤增加的比較快、可規模性一般3 基於python程式碼的決策樹演算法實現:預測顧客購買商品的能力
3.1 機器學習的庫:scikit-learnPython
scikit-learnPython,其特性簡單高效的資料探勘和機器學習分析,簡單高效的資料探勘和機器學習分析,對所有使用者開放,根據不同需求高度可重用性,基於Numpy, SciPy和matplotlib,開源,商用級別:獲得 BSD許可。scikit-learn覆蓋分類(classification), 迴歸(regression), 聚類(clustering), 降維(dimensionality reduction),模型選擇(model selection), 預處理(preprocessing)等領域。
3.2 scikit-learn的使用:Anaconda集成了如下包,不需要安裝即可使用- 安裝scikit-learn: pip, easy_install, windows installer,安裝必要package:numpy, SciPy和matplotlib, 可使用Anaconda (包含numpy, scipy等科學計算常用package)
- 安裝注意問題:Python直譯器版本(2.7 or 3.4?), 32-bit or 64-bit系統
商品購買例子:
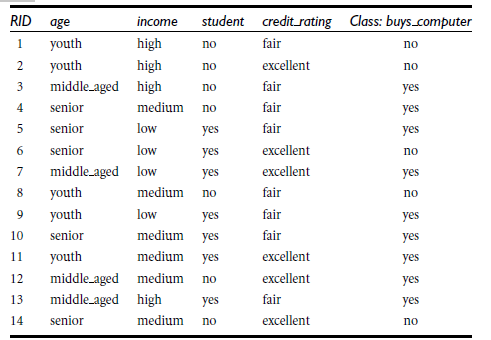
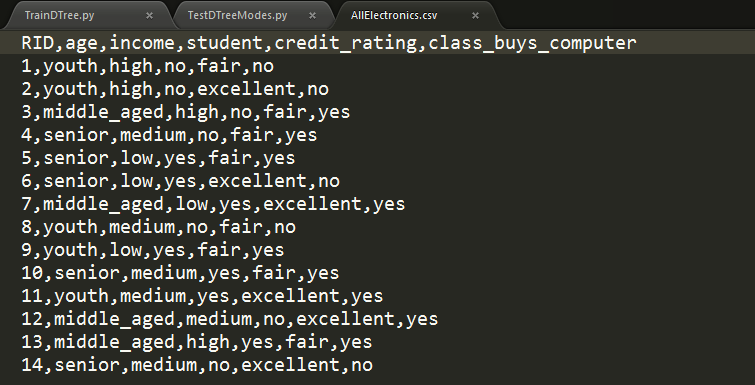
3.3 執行效果如下:

其中,datafile存放模型訓練資料集和測試資料集,TarFile是演算法生成文字形式的dot檔案和轉化後的pdf影象檔案,兩個py檔案,一個是訓練演算法一個是測試訓練結果。右側預測值【0 1 1】代表三條測試資料,其中後兩條具備購買能力。具體演算法和細節下節詳解。
3.4 具體演算法和細節
python中匯入決策樹相關包檔案,然後通過對csv格式轉化為sklearn工具包中可以識別的資料格式,再呼叫決策樹演算法,最後將模型訓練的結果以圖形形式展示。
包的匯入:from sklearn.feature_extraction import DictVectorizer import csv from sklearn import tree from sklearn import preprocessing from sklearn.externals.six import StringIO
讀取csv檔案,將其特徵值儲存在列表featureList中,將預測的目標值儲存在labelList中
'''
Description:python呼叫機器學習庫scikit-learn的決策樹演算法,實現商品購買力的預測,並轉化為pdf影象顯示
Author:Bai Ningchao
DateTime:2016年12月24日14:08:11
Blog URL:http://www.cnblogs.com/baiboy/
'''
def trainDicisionTree(csvfileurl):
'讀取csv檔案,將其特徵值儲存在列表featureList中,將預測的目標值儲存在labelList中'
featureList = []
labelList = []
#讀取商品資訊
allElectronicsData=open(csvfileurl)
reader = csv.reader(allElectronicsData) #逐行讀取資訊
headers=str(allElectronicsData.readline()).split(',') #讀取資訊標頭檔案
print(headers)
執行結果:

儲存特徵數列和目標數列
'儲存特徵數列和目標數列'
for row in reader:
labelList.append(row[len(row)-1]) #讀取最後一列的目標資料
rowDict = {} #存放特徵值的字典
for i in range(1, len(row)-1):
rowDict[headers[i]] = row[i]
# print("rowDict:",rowDict)
featureList.append(rowDict)
print(featureList)
print(labelList)
執行結果:
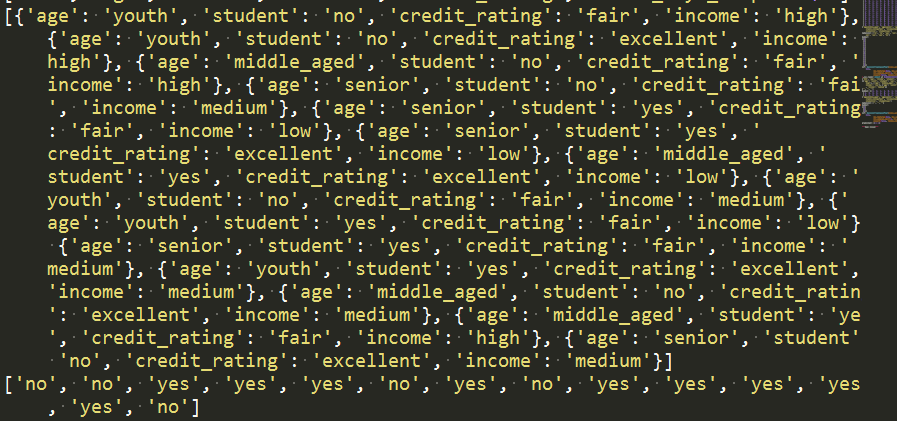
將特徵值數值化
'Vetorize features:將特徵值數值化'
vec = DictVectorizer() #整形數字轉化
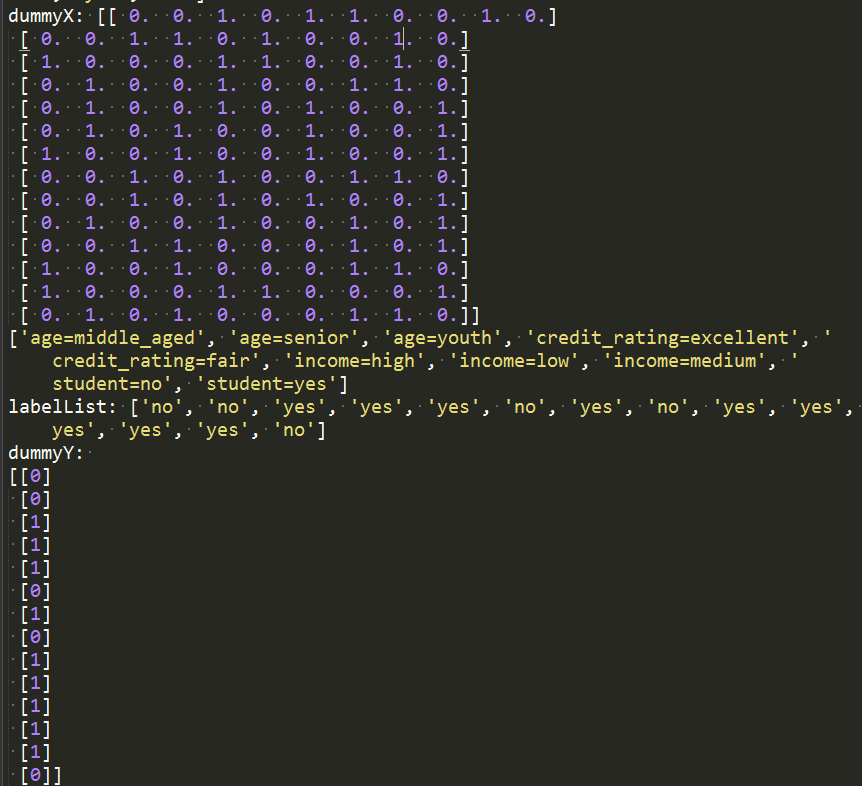
dummyX = vec.fit_transform(featureList) .toarray() #特徵值轉化是整形資料
print("dummyX: " + str(dummyX))
print(vec.get_feature_names())
print("labelList: " + str(labelList))
# vectorize class labels
lb = preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(labelList)
print("dummyY: \n" + str(dummyY))
執行結果:
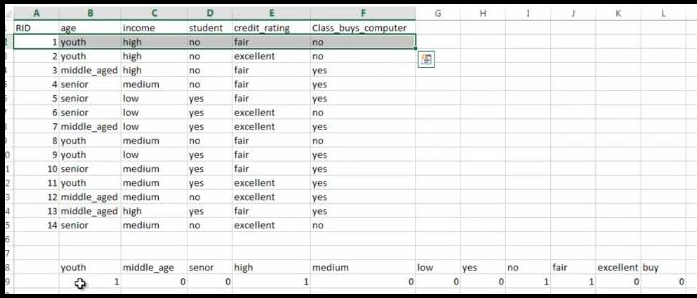
如上演算法就是將商品資訊轉化為機器學習決策樹庫檔案可以識別的形式,即如下形式:
使用決策樹進行分類預測處理
'使用決策樹進行分類預測處理'
# clf = tree.DecisionTreeClassifier()
#自定義採用資訊熵的方式確定根節點
clf = tree.DecisionTreeClassifier(criterion='entropy')
clf = clf.fit(dummyX, dummyY)
print("clf: " + str(clf))
# Visualize model
with open("../Tarfile/allElectronicInformationGainOri.dot", 'w') as f:
f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
執行結果:

將其轉化為影象形式展示,需要下載外掛:安裝 下載Graphviz:

一路安裝下來,然後開啟cmd進入dos環境下,並進入../Tarfile/Tname.dot路徑下;#2 輸入dot -Tname.dot -o name.pdf命令,將dos轉化為pdf格式
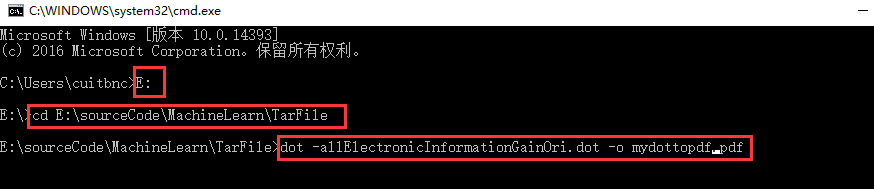
開啟檔案可見:

4 完整專案下載
擴充套件:銀行信用自動評估系統
相關推薦
【Machine Learning】決策樹案例:基於python的商品購買能力預測系統
作者:白寧超 2016年12月24日22:05:42 摘要:隨著機器學習和深度學習的熱潮,各種圖書層出不窮。然而多數是基礎理論知識介紹,缺乏實現的深入理解。本系列文章是作者結合視訊學習和書籍基礎的筆記所得。本系列文章將採用理論結合實踐方式編寫。首先介紹機器學習和深度學習的範疇,然後介紹關於訓練集、
【Machine learning】決策樹(decision tree )
三個問題: 怎樣選擇根節點 怎樣選擇後繼節點 什麼時候停止 (一顆決策樹=》一個分類準則=》一個模型) 基本的演算法: 對一開始提出來的三個問題進行解答: 1.選擇最優屬性 ID3: 最優屬性選擇資訊增益最大的屬性來作為最優屬性 設D為用
【Machine Learning】Python開發工具:Anaconda+Sublime
作者:白寧超 2016年12月23日21:24:51 摘要:隨著機器學習和深度學習的熱潮,各種圖書層出不窮。然而多數是基礎理論知識介紹,缺乏實現的深入理解。本系列文章是作者結合視訊學習和書籍基礎的筆記所得。本系列文章將採用理論結合實踐方式編寫。首先介紹機器學習和深度學習的範疇,然後介紹關於訓練集、測試
【Machine Learning】機器學習:簡明入門指南
在聽到人們談論機器學習的時候,你是不是對它的涵義只有幾個模糊的認識呢?你是不是已經厭倦了在和同事交談時只能一直點頭?讓我們改變一下吧! 本指南的讀者物件是所有對機器學習有求知慾但卻不知道如何開頭的朋友。我猜很多人已經讀過了“機器學習”的維基百科詞條,倍感挫
【機器學習】決策樹剪枝優化及視覺化
前言 \quad\quad 前面,我們介紹了分類決策樹的實現,以及用 sklearn 庫中的 DecisionTre
【Machine :Learning】 樸素貝葉斯
1. 樸素貝葉斯: 條件概率在機器學習演算法的應用。理解這個演算法需要一點推導。不會編輯公式。。 核心就是 在已知訓練集的前提條件下,算出每個特徵的概率為該分類的概率, 然後套貝葉斯公式計算 預測集的所有分類概率,預測型別為概率最大的型別 from numpy import * def l
【機器學習】決策樹與隨機森林(轉)
文章轉自: https://www.cnblogs.com/fionacai/p/5894142.html 首先,在瞭解樹模型之前,自然想到樹模型和線性模型有什麼區別呢?其中最重要的是,樹形模型是一個一個特徵進行處理,之前線性模型是所有特徵給予權重相加得到一個新的值。決
【線上直播】決策樹與隨機森林
講師:段喜平 講師簡介: 研究生畢業於中山大學,曾就職於華為,百分點等公司,目前在魅族擔任NLP演算法工程師。 分享大綱: 1. 樹模型簡介 2. 常用決策樹演算法ID3, C4.5, CART,隨機森林等演算法介紹 3. 隨機森林程
【Machine Learning 】線性迴歸
線性迴歸 我們可以通過測量損耗來衡量線路的適合程度。 線性迴歸的目標是最小化損失。 為了找到最佳擬合線,我們嘗試找到最小化損失的b值(截距)和m值(斜率)。 收斂是指引數在每次迭代時停止變化時的引數 學習率是指每次迭代時引數的變化程度。 我們可以
【機器學習】決策樹演算法(二)— 程式碼實現
#coding=utf8 ‘’’ Created on 2018年11月4日 @author: xiaofengyang 決策樹演算法:ID3演算法 ‘’’ from sklearn.feature_extraction import DictVectorize
【機器學習】決策樹(基於ID3,C4.5,CART分類迴歸樹演算法)—— python3 實現方案
內含3種演算法的核心部分. 沒有找到很好的測試資料. 但就理清演算法思路來說問題不大 剪枝演算法目前只實現了CART迴歸樹的後剪枝. import numpy as np from collections import Counter from sklearn imp
【機器學習】決策樹(下)CART演算法分類樹、迴歸樹
CART同樣由特徵選擇、樹的生成、剪枝組成。既可以用於迴歸,又可以用於分類。 CART是在給定輸入隨機變數X條件下輸出隨機變數Y的條件概率分佈的學習方法。 CART假設決策樹是二叉樹,內部節點特徵的取值為“是“和“否“,左分支是取值為“是“的分支,右分支是取值為“否“的分支。這樣的決策樹
【機器學習】決策樹(上)
前言:決策樹是一種基本的分類與迴歸演算法。可以認為是if-then規則的集合,也可以認為是定義在特徵空間與類空間上的條件概率分佈。 學習時,利用訓練資料,根據損失函式最小化原則建立決策樹模型。 學習包括3個步驟:特徵選擇、決策樹的生成、決策樹的修建 一、決策樹模型 更多參照博文
【機器學習】決策樹 總結
具體的細節概念就不提了,這篇blog主要是用來總結一下決策樹的要點和注意事項,以及應用一些決策樹程式碼的。 一、決策樹的優點: • 易於理解和解釋。數可以視覺化。也就是說決策樹屬於白盒模型,如果一個情況被觀察到,使用邏輯判斷容易表示這種規則。相反,如
【Machine Learning】使用隨機森林進行特徵選擇
一、特徵選擇 在我們做特徵工程時,當我們提取完特徵後,可能存在並不是所有的特徵都能分類起到作用的問題,這個時候就需要使用特徵選擇的方法選出相對重要的特徵用於構建分類器。此外,使用特徵選擇這一步驟也大大減少了訓練的時間,而且模型的擬合能力也不會出現很大的降低問
【Machine Learning】【Python】三、PSO + PCA優化SVM引數C和gamma ---- 《SVM物體分類和定位檢測》
---------------------【6.27 更新libsvm使用方法】-------------------------------------------------------------
【機器學習】決策樹(上)——從原理到演算法實現
前言:決策樹(Decision Tree)是一種基本的分類與迴歸方法,本文主要討論分類決策樹。決策樹模型呈樹形結構,在分類問題中,表示基於特徵對例項進行分類的過程。它可以認為是if-then規則的集合,也可以認為是定義在特徵空間與類空間上的條件概率分佈。相比樸素
【machine learning】GMM演算法(Python版)
本文參考CSDN大神的博文,並在講述中引入自己的理解,純粹理清思路,並將程式碼改為了Python版本。(在更改的過程中,一方面理清自己對GMM的理解,一方面學習了numpy的應用,不過也許是Python粉指數超標才覺得有必要改(⊙o⊙)) 一、GMM模型
【Machine learning】引數估計(個人通俗理解)
問題背景: 我們知道了總體的分佈,但不知道分佈的引數,因此我們就要對未知的引數做出估計。 兩個型別的估計: 1.點估計 2.區間估計 1.點估計 包括矩估計和極大似然估計 1)矩估計: 用樣本矩去估計總體矩 這裡就可以用樣本一階矩(均值)估計整體一階矩(
【Machine Learning】【Python】一、HoG + SVM 物體分類 ---- 《SVM物體分類和定位檢測》
----------【2018.09.07更新】--- 如果你看到了這篇文章,並且從github下載了程式碼想走一遍整個流程。我強烈建議你把《SVM物體分類和定位檢測》這一系列的6篇文章都仔細看一遍。內容不多,但會對你理解演算法和程式碼有很大的幫助。 ----------