
kafka原始碼分析之一server啟動分析
0. 關鍵概念
關鍵概念
| Concepts | Function |
|---|---|
| Topic | 用於劃分Message的邏輯概念,一個Topic可以分佈在多個Broker上。 |
| Partition | 是Kafka中橫向擴充套件和一切並行化的基礎,每個Topic都至少被切分為1個Partition。 |
| Offset | 訊息在Partition中的編號,編號順序不跨Partition(在Partition內有序)。 |
| Consumer | 用於從Broker中取出/消費Message。 |
| Producer | 用於往Broker中傳送/生產Message。 |
| Replication | Kafka支援以Partition為單位對Message進行冗餘備份,每個Partition都可以配置至少1個Replication(當僅1個Replication時即僅該Partition本身)。 |
| Leader | 每個Replication集合中的Partition都會選出一個唯一的Leader,所有的讀寫請求都由Leader處理。其他Replicas從Leader處把資料更新同步到本地。 |
| Broker | Kafka中使用Broker來接受Producer和Consumer的請求,並把Message持久化到本地磁碟。每個Cluster當中會選舉出一個Broker來擔任Controller,負責處理Partition的Leader選舉,協調Partition遷移等工作。 |
| ISR | In-Sync Replica,是Replicas的一個子集,表示目前Alive且與Leader能夠“Catch-up”的Replicas集合。由於讀寫都是首先落到Leader上,所以一般來說通過同步機制從Leader上拉取資料的Replica都會和Leader有一些延遲(包括了延遲時間和延遲條數兩個維度),任意一個超過閾值都會把該Replica踢出ISR。每個Leader Partition都有它自己獨立的ISR。 |
1. 分析kafka原始碼的目的
深入掌握kafka的內部原理
深入掌握scala運用
2. server的啟動
如下所示(本來準備用時序圖的,但感覺時序圖沒有思維圖更能反映,故採用了思維圖):
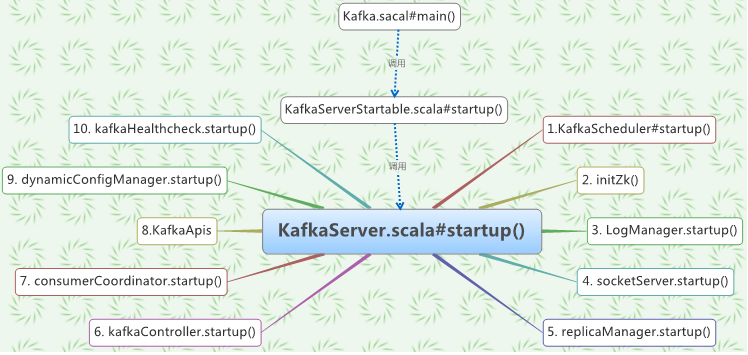
2.1 啟動入口Kafka.scala
從上面的思維導圖,可以看到Kafka的啟動入口是Kafka.scala的main()函式:
def main(args: Array[String]): Unit = { try { val serverProps = getPropsFromArgs(args) val kafkaServerStartable = KafkaServerStartable.fromProps(serverProps) // attach shutdown handler to catch control-c Runtime.getRuntime().addShutdownHook(new Thread() { override def run() = { kafkaServerStartable.shutdown } }) kafkaServerStartable.startup kafkaServerStartable.awaitShutdown } catch { case e: Throwable => fatal(e) System.exit(1) } System.exit(0) }
上面程式碼主要包含:
從配置檔案讀取kafka伺服器啟動引數的getPropsFromArgs()方法;
建立KafkaServerStartable物件;
KafkaServerStartable物件在增加shutdown控制代碼函式;
啟動KafkaServerStartable的starup()方法;
啟動KafkaServerStartable的awaitShutdown()方法;
2.2 KafkaServer的包裝類KafkaServerStartable
private val server = new KafkaServer(serverConfig) def startup() { try { server.startup() } catch { case e: Throwable => fatal("Fatal error during KafkaServerStartable startup. Prepare to shutdown", e) // KafkaServer already calls shutdown() internally, so this is purely for logging & the exit code System.exit(1) } }
2.3 具體啟動類KafkaServer
KafkaServer啟動的程式碼層次比較清晰,加上註釋,看懂基本沒有問題:
/** * Start up API for bringing up a single instance of the Kafka server. * Instantiates the LogManager, the SocketServer and the request handlers - KafkaRequestHandlers */ def startup() { try { info("starting") if(isShuttingDown.get) throw new IllegalStateException("Kafka server is still shutting down, cannot re-start!") if(startupComplete.get) return val canStartup = isStartingUp.compareAndSet(false, true) if (canStartup) { metrics = new Metrics(metricConfig, reporters, kafkaMetricsTime, true) brokerState.newState(Starting) /* start scheduler */ kafkaScheduler.startup() /* setup zookeeper */ zkUtils = initZk() /* start log manager */ logManager = createLogManager(zkUtils.zkClient, brokerState) logManager.startup() /* generate brokerId */ config.brokerId = getBrokerId this.logIdent = "[Kafka Server " + config.brokerId + "], " socketServer = new SocketServer(config, metrics, kafkaMetricsTime) socketServer.startup() /* start replica manager */ replicaManager = new ReplicaManager(config, metrics, time, kafkaMetricsTime, zkUtils, kafkaScheduler, logManager, isShuttingDown) replicaManager.startup() /* start kafka controller */ kafkaController = new KafkaController(config, zkUtils, brokerState, kafkaMetricsTime, metrics, threadNamePrefix) kafkaController.startup() /* start kafka coordinator */ consumerCoordinator = GroupCoordinator.create(config, zkUtils, replicaManager) consumerCoordinator.startup() /* Get the authorizer and initialize it if one is specified.*/ authorizer = Option(config.authorizerClassName).filter(_.nonEmpty).map { authorizerClassName => val authZ = CoreUtils.createObject[Authorizer](authorizerClassName) authZ.configure(config.originals()) authZ } /* start processing requests */ apis = new KafkaApis(socketServer.requestChannel, replicaManager, consumerCoordinator, kafkaController, zkUtils, config.brokerId, config, metadataCache, metrics, authorizer) requestHandlerPool = new KafkaRequestHandlerPool(config.brokerId, socketServer.requestChannel, apis, config.numIoThreads) brokerState.newState(RunningAsBroker) Mx4jLoader.maybeLoad() /* start dynamic config manager */ dynamicConfigHandlers = Map[String, ConfigHandler](ConfigType.Topic -> new TopicConfigHandler(logManager), ConfigType.Client -> new ClientIdConfigHandler(apis.quotaManagers)) // Apply all existing client configs to the ClientIdConfigHandler to bootstrap the overrides // TODO: Move this logic to DynamicConfigManager AdminUtils.fetchAllEntityConfigs(zkUtils, ConfigType.Client).foreach { case (clientId, properties) => dynamicConfigHandlers(ConfigType.Client).processConfigChanges(clientId, properties) } // Create the config manager. start listening to notifications dynamicConfigManager = new DynamicConfigManager(zkUtils, dynamicConfigHandlers) dynamicConfigManager.startup() /* tell everyone we are alive */ val listeners = config.advertisedListeners.map {case(protocol, endpoint) => if (endpoint.port == 0) (protocol, EndPoint(endpoint.host, socketServer.boundPort(protocol), endpoint.protocolType)) else (protocol, endpoint) } kafkaHealthcheck = new KafkaHealthcheck(config.brokerId, listeners, zkUtils) kafkaHealthcheck.startup() /* register broker metrics */ registerStats() shutdownLatch = new CountDownLatch(1) startupComplete.set(true) isStartingUp.set(false) AppInfoParser.registerAppInfo(jmxPrefix, config.brokerId.toString) info("started") } } catch { case e: Throwable => fatal("Fatal error during KafkaServer startup. Prepare to shutdown", e) isStartingUp.set(false) shutdown() throw e } }
2.3.1 KafkaScheduler
KafkaScheduler是一個基於java.util.concurrent.ScheduledThreadPoolExecutor的scheduler,它內部是以字首kafka-scheduler-xx的執行緒池處理真正的工作。
注意xx是執行緒序列號。
/** * A scheduler based on java.util.concurrent.ScheduledThreadPoolExecutor * * It has a pool of kafka-scheduler- threads that do the actual work. * * @param threads The number of threads in the thread pool * @param threadNamePrefix The name to use for scheduler threads. This prefix will have a number appended to it. * @param daemon If true the scheduler threads will be "daemon" threads and will not block jvm shutdown. */ @threadsafe class KafkaScheduler(val threads: Int, val threadNamePrefix: String = "kafka-scheduler-", daemon: Boolean = true) extends Scheduler with Logging { private var executor: ScheduledThreadPoolExecutor = null private val schedulerThreadId = new AtomicInteger(0) override def startup() { debug("Initializing task scheduler.") this synchronized { if(isStarted) throw new IllegalStateException("This scheduler has already been started!") executor = new ScheduledThreadPoolExecutor(threads) executor.setContinueExistingPeriodicTasksAfterShutdownPolicy(false) executor.setExecuteExistingDelayedTasksAfterShutdownPolicy(false) executor.setThreadFactory(new ThreadFactory() { def newThread(runnable: Runnable): Thread = Utils.newThread(threadNamePrefix + schedulerThreadId.getAndIncrement(), runnable, daemon) }) } }
2.3.2 zk初始化
zk初始化主要完成兩件事情:
val zkUtils = ZkUtils(config.zkConnect,
config.zkSessionTimeoutMs,
config.zkConnectionTimeoutMs,
secureAclsEnabled)
zkUtils.setupCommonPaths()
一個是連線到zk伺服器;二是建立通用節點。
通用節點包括:
// These are persistent ZK paths that should exist on kafka broker startup. val persistentZkPaths = Seq(ConsumersPath, BrokerIdsPath, BrokerTopicsPath, EntityConfigChangesPath, getEntityConfigRootPath(ConfigType.Topic), getEntityConfigRootPath(ConfigType.Client), DeleteTopicsPath, BrokerSequenceIdPath, IsrChangeNotificationPath)
2.3.3 日誌管理器LogManager
LogManager是kafka的子系統,負責log的建立,檢索及清理。所有的讀寫操作由單個的日誌例項來代理。
/** * Start the background threads to flush logs and do log cleanup */ def startup() { /* Schedule the cleanup task to delete old logs */ if(scheduler != null) { info("Starting log cleanup with a period of %d ms.".format(retentionCheckMs)) scheduler.schedule("kafka-log-retention", cleanupLogs, delay = InitialTaskDelayMs, period = retentionCheckMs, TimeUnit.MILLISECONDS) info("Starting log flusher with a default period of %d ms.".format(flushCheckMs)) scheduler.schedule("kafka-log-flusher", flushDirtyLogs, delay = InitialTaskDelayMs, period = flushCheckMs, TimeUnit.MILLISECONDS) scheduler.schedule("kafka-recovery-point-checkpoint", checkpointRecoveryPointOffsets, delay = InitialTaskDelayMs, period = flushCheckpointMs, TimeUnit.MILLISECONDS) } if(cleanerConfig.enableCleaner) cleaner.startup() }
2.3.4 SocketServer
SocketServer是nio的socket伺服器,執行緒模型是:1個Acceptor執行緒處理新連線,Acceptor還有多個處理器執行緒,每個處理器執行緒擁有自己的selector和多個讀socket請求Handler執行緒。handler執行緒處理請求併產生響應寫給處理器執行緒。
/** * Start the socket server */ def startup() { this.synchronized { connectionQuotas = new ConnectionQuotas(maxConnectionsPerIp, maxConnectionsPerIpOverrides) val sendBufferSize = config.socketSendBufferBytes val recvBufferSize = config.socketReceiveBufferBytes val maxRequestSize = config.socketRequestMaxBytes val connectionsMaxIdleMs = config.connectionsMaxIdleMs val brokerId = config.brokerId var processorBeginIndex = 0 endpoints.values.foreach { endpoint => val protocol = endpoint.protocolType val processorEndIndex = processorBeginIndex + numProcessorThreads for (i <- processorBeginIndex until processorEndIndex) { processors(i) = new Processor(i, time, maxRequestSize, requestChannel, connectionQuotas, connectionsMaxIdleMs, protocol, config.values, metrics ) } val acceptor = new Acceptor(endpoint, sendBufferSize, recvBufferSize, brokerId, processors.slice(processorBeginIndex, processorEndIndex), connectionQuotas) acceptors.put(endpoint, acceptor) Utils.newThread("kafka-socket-acceptor-%s-%d".format(protocol.toString, endpoint.port), acceptor, false).start() acceptor.awaitStartup() processorBeginIndex = processorEndIndex } } newGauge("NetworkProcessorAvgIdlePercent", new Gauge[Double] { def value = allMetricNames.map( metricName => metrics.metrics().get(metricName).value()).sum / totalProcessorThreads } ) info("Started " + acceptors.size + " acceptor threads") }
2.3.5 複製管理器
啟動ISR過期執行緒
def startup() { // start ISR expiration thread scheduler.schedule("isr-expiration", maybeShrinkIsr, period = config.replicaLagTimeMaxMs, unit = TimeUnit.MILLISECONDS) scheduler.schedule("isr-change-propagation", maybePropagateIsrChanges, period = 2500L, unit = TimeUnit.MILLISECONDS) }
2.3.6 kafka控制器
當kafka 伺服器的控制器模組啟動時啟用,但並不認為當前的代理就是控制器。它僅僅註冊了session過期監聽器和啟動控制器選主。
def startup() = { inLock(controllerContext.controllerLock) { info("Controller starting up") registerSessionExpirationListener() isRunning = true controllerElector.startup info("Controller startup complete") } }
session過期監聽器註冊:
private def registerSessionExpirationListener() = { zkUtils.zkClient.subscribeStateChanges(new SessionExpirationListener()) } public void subscribeStateChanges(final IZkStateListener listener) { synchronized (_stateListener) { _stateListener.add(listener); } }
class SessionExpirationListener() extends IZkStateListener with Logging {
this.logIdent = "[SessionExpirationListener on " + config.brokerId + "], "
@throws(classOf[Exception])
def handleStateChanged(state: KeeperState) {
// do nothing, since zkclient will do reconnect for us.
}
選主過程:
def startup { inLock(controllerContext.controllerLock) { controllerContext.zkUtils.zkClient.subscribeDataChanges(electionPath, leaderChangeListener) elect } } def elect: Boolean = { val timestamp = SystemTime.milliseconds.toString val electString = Json.encode(Map("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp)) leaderId = getControllerID /* * We can get here during the initial startup and the handleDeleted ZK callback. Because of the potential race condition, * it's possible that the controller has already been elected when we get here. This check will prevent the following * createEphemeralPath method from getting into an infinite loop if this broker is already the controller. */ if(leaderId != -1) { debug("Broker %d has been elected as leader, so stopping the election process.".format(leaderId)) return amILeader } try { val zkCheckedEphemeral = new ZKCheckedEphemeral(electionPath, electString, controllerContext.zkUtils.zkConnection.getZookeeper, JaasUtils.isZkSecurityEnabled()) zkCheckedEphemeral.create() info(brokerId + " successfully elected as leader") leaderId = brokerId onBecomingLeader() } catch { case e: ZkNodeExistsException => // If someone else has written the path, then leaderId = getControllerID if (leaderId != -1) debug("Broker %d was elected as leader instead of broker %d".format(leaderId, brokerId)) else warn("A leader has been elected but just resigned, this will result in another round of election") case e2: Throwable => error("Error while electing or becoming leader on broker %d".format(brokerId), e2) resign() } amILeader } def amILeader : Boolean = leaderId == brokerId
2.3.7 GroupCoordinator
GroupCoordinator處理組成員管理和offset管理,每個kafka伺服器初始化一個協作器來負責一系列組別。每組基於它們的組名來賦予協作器。
def startup() { info("Starting up.") heartbeatPurgatory = new DelayedOperationPurgatory[DelayedHeartbeat]("Heartbeat", brokerId) joinPurgatory = new DelayedOperationPurgatory[DelayedJoin]("Rebalance", brokerId) isActive.set(true) info("Startup complete.") }
注意:若同時需要一個組鎖和元資料鎖,請務必保證先獲取組鎖,然後獲取元資料鎖來防止死鎖。
2.3.8 KafkaApis訊息處理介面
/** * Top-level method that handles all requests and multiplexes to the right api */ def handle(request: RequestChannel.Request) { try{ trace("Handling request:%s from connection %s;securityProtocol:%s,principal:%s". format(request.requestObj, request.connectionId, request.securityProtocol, request.session.principal)) request.requestId match { case RequestKeys.ProduceKey => handleProducerRequest(request) case RequestKeys.FetchKey => handleFetchRequest(request) case RequestKeys.OffsetsKey => handleOffsetRequest(request) case RequestKeys.MetadataKey => handleTopicMetadataRequest(request) case RequestKeys.LeaderAndIsrKey => handleLeaderAndIsrRequest(request) case RequestKeys.StopReplicaKey => handleStopReplicaRequest(request) case RequestKeys.UpdateMetadataKey => handleUpdateMetadataRequest(request) case RequestKeys.ControlledShutdownKey => handleControlledShutdownRequest(request) case RequestKeys.OffsetCommitKey => handleOffsetCommitRequest(request) case RequestKeys.OffsetFetchKey => handleOffsetFetchRequest(request) case RequestKeys.GroupCoordinatorKey => handleGroupCoordinatorRequest(request) case RequestKeys.JoinGroupKey => handleJoinGroupRequest(request) case RequestKeys.HeartbeatKey => handleHeartbeatRequest(request) case RequestKeys.LeaveGroupKey => handleLeaveGroupRequest(request) case RequestKeys.SyncGroupKey => handleSyncGroupRequest(request) case RequestKeys.DescribeGroupsKey => handleDescribeGroupRequest(request) case RequestKeys.ListGroupsKey => handleListGroupsRequest(request) case requestId => throw new KafkaException("Unknown api code " + requestId) } } catch { case e: Throwable => if ( request.requestObj != null) request.requestObj.handleError(e, requestChannel, request) else { val response = request.body.getErrorResponse(request.header.apiVersion, e) val respHeader = new ResponseHeader(request.header.correlationId) /* If request doesn't have a default error response, we just close the connection. For example, when produce request has acks set to 0 */ if (response == null) requestChannel.closeConnection(request.processor, request) else requestChannel.sendResponse(new Response(request, new ResponseSend(request.connectionId, respHeader, response))) } error("error when handling request %s".format(request.requestObj), e) } finally request.apiLocalCompleteTimeMs = SystemTime.milliseconds }
我們以處理消費者請求為例:
/** * Handle a produce request */ def handleProducerRequest(request: RequestChannel.Request) { val produceRequest = request.requestObj.asInstanceOf[ProducerRequest] val numBytesAppended = produceRequest.sizeInBytes val (authorizedRequestInfo, unauthorizedRequestInfo) = produceRequest.data.partition { case (topicAndPartition, _) => authorize(request.session, Write, new Resource(Topic, topicAndPartition.topic)) } // the callback for sending a produce response def sendResponseCallback(responseStatus: Map[TopicAndPartition, ProducerResponseStatus]) { val mergedResponseStatus = responseStatus ++ unauthorizedRequestInfo.mapValues(_ => ProducerResponseStatus(ErrorMapping.TopicAuthorizationCode, -1)) var errorInResponse = false mergedResponseStatus.foreach { case (topicAndPartition, status) => if (status.error != ErrorMapping.NoError) { errorInResponse = true debug("Produce request with correlation id %d from client %s on partition %s failed due to %s".format( produceRequest.correlationId, produceRequest.clientId, topicAndPartition, ErrorMapping.exceptionNameFor(status.error))) } } def produceResponseCallback(delayTimeMs: Int) { if (produceRequest.requiredAcks == 0) { // no operation needed if producer request.required.acks = 0; however, if there is any error in handling // the request, since no response is expected by the producer, the server will close socket server so that // the producer client will know that some error has happened and will refresh its metadata if (errorInResponse) { val exceptionsSummary = mergedResponseStatus.map { case (topicAndPartition, status) => topicAndPartition -> ErrorMapping.exceptionNameFor(status.error) }.mkString(", ") info( s"Closing connection due to error during produce request with correlation id ${produceRequest.correlationId} " + s"from client id ${produceRequest.clientId} with ack=0\n" + s"Topic and partition to exceptions: $exceptionsSummary" ) requestChannel.closeConnection(request.processor, request) } else { requestChannel.noOperation(request.processor, request) } } else { val response = ProducerResponse(produceRequest.correlationId, mergedResponseStatus, produceRequest.versionId, delayTimeMs) requestChannel.sendResponse(new RequestChannel.Response(request, new RequestOrResponseSend(request.connectionId, response))) } } // When this callback is triggered, the remote API call has completed request.apiRemoteCompleteTimeMs = SystemTime.milliseconds quotaManagers(RequestKeys.ProduceKey).recordAndMaybeThrottle(produceRequest.clientId, numBytesAppended, produceResponseCallback) } if (authorizedRequestInfo.isEmpty) sendResponseCallback(Map.empty) else { val internalTopicsAllowed = produceRequest.clientId == AdminUtils.AdminClientId // call the replica manager to append messages to the replicas replicaManager.appendMessages( produceRequest.ackTimeoutMs.toLong, produceRequest.requiredAcks, internalTopicsAllowed, authorizedRequestInfo, sendResponseCallback) // if the request is put into the purgatory, it will have a held reference // and hence cannot be garbage collected; hence we clear its data here in // order to let GC re-claim its memory since it is already appended to log produceRequest.emptyData() } }
對應kafka producer的acks配置:
The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are common: acks=0 If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and the retries configuration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to -1. acks=1 This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost. acks=all This means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee.
2.3.9 動態配置管理DynamicConfigManager
利用zookeeper做動態配置中心
/** * Begin watching for config changes */ def startup() { zkUtils.makeSurePersistentPathExists(ZkUtils.EntityConfigChangesPath) zkUtils.zkClient.subscribeChildChanges(ZkUtils.EntityConfigChangesPath, ConfigChangeListener) processAllConfigChanges() } /** * Process all config changes */ private def processAllConfigChanges() { val configChanges = zkUtils.zkClient.getChildren(ZkUtils.EntityConfigChangesPath) import JavaConversions._ processConfigChanges((configChanges: mutable.Buffer[String]).sorted) } /** * Process the given list of config changes */ private def processConfigChanges(notifications: Seq[String]) { if (notifications.size > 0) { info("Processing config change notification(s)...") val now = time.milliseconds for (notification <- notifications) { val changeId = changeNumber(notification) if (changeId > lastExecutedChange) { val changeZnode = ZkUtils.EntityConfigChangesPath + "/" + notification val (jsonOpt, stat) = zkUtils.readDataMaybeNull(changeZnode) processNotification(jsonOpt) } lastExecutedChange = changeId } purgeObsoleteNotifications(now, notifications) } }
2.3.10 心跳檢測KafkaHealthcheck
心跳檢測也使用zookeeper維持:
def startup() { zkUtils.zkClient.subscribeStateChanges(sessionExpireListener) register() } /** * Register this broker as "alive" in zookeeper */ def register() { val jmxPort = System.getProperty("com.sun.management.jmxremote.port", "-1").toInt val updatedEndpoints = advertisedEndpoints.mapValues(endpoint => if (endpoint.host == null || endpoint.host.trim.isEmpty) EndPoint(InetAddress.getLocalHost.getCanonicalHostName, endpoint.port, endpoint.protocolType) else endpoint ) // the default host and port are here for compatibility with older client // only PLAINTEXT is supported as default // if the broker doesn't listen on PLAINTEXT protocol, an empty endpoint will be registered and older clients will be unable to connect val plaintextEndpoint = updatedEndpoints.getOrElse(SecurityProtocol.PLAINTEXT, new EndPoint(null,-1,null)) zkUtils.registerBrokerInZk(brokerId, plaintextEndpoint.host, plaintextEndpoint.port, updatedEndpoints, jmxPort) }
3. 小結
kafka中KafkaServer類,採用門面模式,是網路處理,io處理等得入口.
ReplicaManager 副本管理
KafkaApis 處理所有request的Proxy類,根據requestKey決定調⽤用具體的handler
KafkaRequestHandlerPool 處理request的執行緒池,請求處理池 <-- num.io.threads io執行緒數量
LogManager kafka檔案儲存系統管理,負責處理和儲存所有Kafka的topic的partiton資料
TopicConfigManager 監聽此zk節點的⼦子節點/config/changes/,通過LogManager更新topic的配置資訊,topic粒度配置管理,具體請檢視topic級別配置
KafkaHealthcheck 監聽zk session expire,在zk上建立broker資訊,便於其他broker和consumer獲取其資訊
KafkaController kafka叢集中央控制器選舉,leader選舉,副本分配。
KafkaScheduler 負責副本管理和日誌管理排程等等
ZkClient 負責註冊zk相關資訊.
BrokerTopicStats topic資訊統計和監控
ControllerStats 中央控制器統計和監控
參考文獻
【1】https://zqhxuyuan1.gitbooks.io/kafka/content/chapter1-intro.html
【2】http://blog.csdn.net/lizhitao/article/details/37911993
相關推薦
kafka原始碼分析之一server啟動分析
0. 關鍵概念 關鍵概念 ConceptsFunction Topic 用於劃分Message的邏輯概念,一個Topic可以分佈在多個Broker上。 Partition 是Kafka中橫向擴充套件和一切並行化的基礎,每個Topic都至少被切分為1個Partition。
架HSF分析之一容器啟動
http://iwinit.iteye.com/blog/1745132 大家平時都在用這個服務框架。簡單閱讀了下程式碼,瞭解其原理可以方便解決一些常見hsf的問題。限於篇幅,整個分析將分幾個系列釋出。第一篇將簡單介紹Hsf的啟動和各元件之間關係。 一. Hsf
Android原始碼解析之Launcher啟動分析
轉載自:http://blog.csdn.net/luoshengyang/article/details/6767736 在前面一篇文章中,我們分析了Android系統在啟動時安裝應用程式的過程,這些應用程式安裝好之後,還需要有一個Home應用
kafka原始碼之kafkaserver的啟動
KAFKA的啟動 Kafka啟動時,通過進入kafka的bin路徑下,執行如下指令碼: ./kafka-server-start.sh ../config/server.properties 這個指
Android系統程序間通訊 IPC 機制Binder中的Server啟動過程原始碼分析
在前面一篇文章中,介紹了在Android系統中Binder程序間通訊機制中的Server角色是如何獲得Service Manager遠端介面的,即defaultServiceManager函式的實現。Server獲得了Service Manager遠端介面之後,
zookeeper原始碼分析之一服務端啟動過程
zookeeper簡介 zookeeper是為分散式應用提供分散式協作服務的開源軟體。它提供了一組簡單的原子操作,分散式應用可以基於這些原子操作來實現更高層次的同步服務,配置維護,組管理和命名。zookeeper的設計使基於它的程式設計非常容易,若我們熟悉目錄樹結構的檔案系統,也會很容易使用zoo
[k8s]k8s api-server啟動systemd參數分析
config exp 關閉 pac -h 單位 審計日誌 dmi mes cat > kube-apiserver.service <<EOF [Unit] Description=Kubernetes API Server Documentation=
Android原始碼分析-Activity的啟動過程
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
Kafka 原始碼分析之LogSegment
這裡分析kafka LogSegment原始碼 通過一步步分析LogManager,Log原始碼之後就會發現,最終的log操作都在LogSegment上實現.LogSegment負責分片的讀寫恢復重新整理刪除等動作都在這裡實現.LogSegment程式碼同樣在原始碼目錄log下. LogSe
dubbo原始碼分析-消費端啟動初始化過程-筆記
消費端的程式碼解析是從下面這段程式碼開始的 <dubbo:reference id="xxxService" interface="xxx.xxx.Service"/> ReferenceBean(afterPropertiesSet) ->getObject() ->ge
Spark2.2.2原始碼解析: 3.啟動worker節點啟動流程分析
本文啟動worker節點啟動流程分析 啟動命令: ${SPARK_HOME}/sbin/start-slave.sh spark://sysadmindeMacBook-Pro.local:7077 檢視start-slave.sh
Spark2.2.2原始碼解析: 2.啟動master節點流程分析
本文主要說明在啟動master節點的時候,程式碼的流程走向。 授予檔案執行許可權 chmod755 兩個目錄裡的檔案: /workspace/spark-2.2.2/bin --所有檔案 /workspace/spark-2.2.2/sb
Kafka原始碼之Sender分析
我們先來介紹一下Sender傳送訊息的整個流程:首先根據RecordAccumulator的快取情況,利用ready篩選出可以向哪些節點發送訊息,然後根據生產者和各個節點的連線愛你概況,過濾Node節點,之後,生成相應的請求,這裡要特別注意的是每個Node節點只
0x01 webpack原始碼分析之webpack啟動程式
序言(吹水) 之前一直想跟蹤一下webpack的原始碼,奈何沉迷遊戲,無法自拔。等我回過頭,webpack已經更新到4.0啦,這更新速度比英雄聯盟還快,瞬間就s4了。從今天開始對webpack(4.0)的原始碼進行探索,但隨時可能斷更,咳咳。這一章呢,主要記錄一
Kafka原始碼之KafkaConsumer分析之offset操作
當消費者正常消費過程中以及Rebalance操作開始之前,都會提交一次Offset記錄Consumer當前的消費位置。在SubscriptionState中使用TopicPartitionState記錄了每個TopicPartition的消費狀況,TopicPa
Kafka原始碼之服務端分析之SocketServer
前面我們介紹了消費者和生產者,從這篇文章開始我們來看一下它的服務端的設計。 Kafka的網路層是採用多執行緒,多個Selector的設計實現的。核心類是SocketServer,其中包含一個Acceptor 用於接收並處理所有的新連線,每個Acceptor對應多
從dubbo原始碼分析qos-server埠衝突問題
在這分散式系統架構盛行的時代,很多網際網路大佬公司開源出自己的分散式RPC系統框架,例如:阿里的dubbo,谷歌的gRPC,apache的Thrift。而在我們公司一直都在推薦使用dubbo,今天就來講講在使用dubbo過程出現的qos-server埠衝突問題。 首先什麼是dubbo的qos-s
live555 原始碼分析:播放啟動
本文分析 live555 中,流媒體播放啟動,資料開始通過 RTP/RTCP 傳輸的過程。 如我們在 live555 原始碼分析:子會話 SETUP 中看到的,一個流媒體子會話的播放啟動,由 StreamState::startPlaying 完成: v
Kafka原始碼分析--生產者
ps.本文所有原始碼都基於kafka-0.10.0.1Kafka提供了Java版本的生產者實現--KafkaProducer,使用KafkaProducer的API可以輕鬆實現同步/非同步傳送訊息、批量傳送、超時重發等複雜的功能,KafkaProducer是執行緒安全的,多個
kafka原始碼分析之consumer的原始碼
Consumer的client端 示例程式碼 Properties props = new Properties();props.put(ConsumerConfig.BOOTSTRAP_SER