
CUDA程式設計-GPU架構軟硬體體系
掌握部分硬體知識,有助於程式設計師編寫更好的CUDA程式,提升CUDA程式效能,本文目的是理清sp,sm,thread,block,grid,warp之間的關係。由於作者能力有限,難免有疏漏,懇請讀者批評指正。
首先我們要明確:SP(streaming Process),SM(streaming multiprocessor)是硬體(GPU hardware)概念。而thread,block,grid,warp是軟體上的(CUDA)概念。
從硬體看
- SP:最基本的處理單元,streaming processor,也稱為CUDA core。最後具體的指令和任務都是在SP上處理的。GPU進行平行計算,也就是很多個SP同時做處理。
- SM:多個SP加上其他的一些資源組成一個streaming multiprocessor。也叫GPU大核,其他資源如:warp scheduler,register,shared memory等。SM可以看做GPU的心臟(對比CPU核心),register和shared memory是SM的稀缺資源。CUDA將這些資源分配給所有駐留在SM中的threads。因此,這些有限的資源就使每個SM中active warps有非常嚴格的限制,也就限制了並行能力。
需要指出,每個SM包含的SP數量依據GPU架構而不同,Fermi架構GF100是32個,GF10X是48個,Kepler架構都是192個,Maxwell都是128個。相同架構的GPU包含的SM數量則根據GPU的中高低端來定。下圖給出Nvidia GTX980 的一個SM示意圖,圖中每個綠色框框表示一個SP。注意,在Maxwell架構中,Nvidia已經把SM改叫SMM。下圖表示的僅僅是一個SMM,一個GPU可以有多個SM(比如16個),最終一個GPU可能包含有上千個SP。這麼多核心“同時執行”,速度可想而知,這個引號只是想表明實際上,軟體邏輯上是所有SP是並行的,但是物理上並不是所有SP都能同時執行計算,因為有些會處於掛起,就緒等其他狀態,這有關GPU的執行緒排程,以後再寫了。
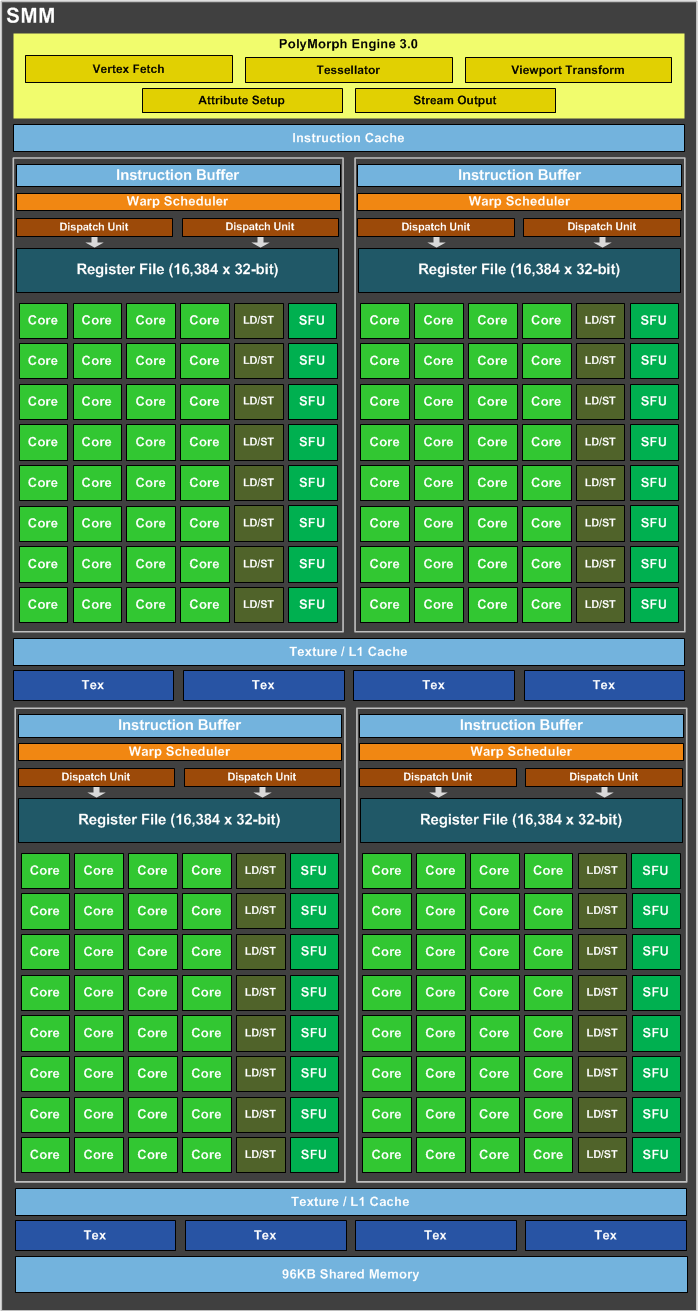
從軟體看
thread,block,grid,warp是CUDA程式設計上的概念,以方便程式設計師軟體設計,組織執行緒,同樣的我們給出一個示意圖來表示。
- thread:一個CUDA的並行程式會被以許多個threads來執行。
- block:數個threads會被群組成一個block,同一個block中的threads可以同步,也可以通過shared memory通訊。
- grid:多個blocks則會再構成grid。
- warp:GPU執行程式時的排程單位,目前cuda的warp的大小為32,同在一個warp的執行緒,以不同資料資源執行相同的指令,這就是所謂 SIMT。
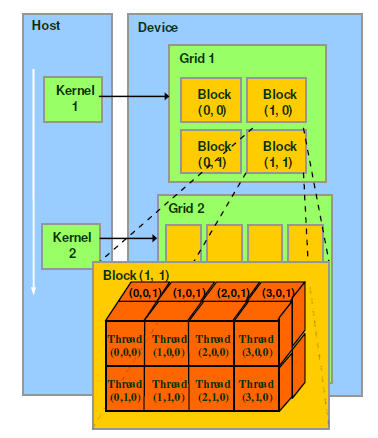
對應關係
從軟體上看,SM更像一個獨立的CPU core。SM(Streaming Multiprocessors)是GPU架構中非常重要的部分,GPU硬體的並行性就是由SM決定的。以Fermi架構為例,其包含以下主要組成部分:
- CUDA cores
- Shared Memory/L1Cache
- Register File
- Load/Store Units
- Special Function Units
- Warp Scheduler
GPU中每個sm都設計成支援數以百計的執行緒並行執行,並且每個GPU都包含了很多的SM,所以GPU支援成百上千的執行緒並行執行。當一個kernel啟動後,thread會被分配到這些SM中執行。大量的thread可能會被分配到不同的SM,同一個block中的threads必然在同一個SM中並行(SIMT)執行。每個thread擁有它自己的程式計數器和狀態暫存器,並且用該執行緒自己的資料執行指令,這就是所謂的Single Instruction Multiple Thread。
一個SP可以執行一個thread,但是實際上並不是所有的thread能夠在同一時刻執行。Nvidia把32個threads組成一個warp,warp是排程和執行的基本單元。warp中所有threads並行的執行相同的指令。一個warp需要佔用一個SM執行,多個warps需要輪流進入SM。由SM的硬體warp scheduler負責排程。目前每個warp包含32個threads(Nvidia保留修改數量的權利)。所以,一個GPU上resident thread最多隻有 SM*warp個。
SIMT和SIMD
CUDA是一種典型的SIMT架構(單指令多執行緒架構),SIMT和SIMD(Single Instruction, Multiple Data)類似,SIMT應該算是SIMD的升級版,更靈活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通過將同樣的指令廣播給多個執行官單元來實現並行。一個主要的不同就是,SIMD要求所有的vector element在一個統一的同步組裡同步的執行,而SIMT允許執行緒們在一個warp中獨立的執行。SIMT有三個SIMD沒有的主要特徵:
- 每個thread擁有自己的instruction address counter
- 每個thread擁有自己的狀態暫存器
- 每個thread可以有自己獨立的執行路徑
更細節的差異可以看這裡。
前面已經說block是軟體概念,一個block只會由一個sm排程,程式設計師在開發時,通過設定block的屬性,**“告訴”**GPU硬體,我有多少個執行緒,執行緒怎麼組織。而具體怎麼排程由sm的warps scheduler負責,block一旦被分配好SM,該block就會一直駐留在該SM中,直到執行結束。一個SM可以同時擁有多個blocks,但需要序列執行。下圖顯示了軟體硬體方面的術語對應關係:

需要注意的是,大部分threads只是邏輯上並行,並不是所有的thread可以在物理上同時執行。例如,遇到分支語句(if else,while,for等)時,各個thread的執行條件不一樣必然產生分支執行,這就導致同一個block中的執行緒可能會有不同步調。另外,並行thread之間的共享資料會導致競態:多個執行緒請求同一個數據會導致未定義行為。CUDA提供了cudaThreadSynchronize()來同步同一個block的thread以保證在進行下一步處理之前,所有thread都到達某個時間點。
同一個warp中的thread可以以任意順序執行,active warps被sm資源限制。當一個warp空閒時,SM就可以排程駐留在該SM中另一個可用warp。在併發的warp之間切換是沒什麼消耗的,因為硬體資源早就被分配到所有thread和block,所以該新排程的warp的狀態已經儲存在SM中了。不同於CPU,CPU切換執行緒需要儲存/讀取執行緒上下文(register內容),這是非常耗時的,而GPU為每個threads提供物理register,無需儲存/讀取上下文。
總結
掌握部分硬體知識,有助於CUDA效能提升。
相關推薦
CUDA程式設計-GPU架構軟硬體體系
掌握部分硬體知識,有助於程式設計師編寫更好的CUDA程式,提升CUDA程式效能,本文目的是理清sp,sm,thread,block,grid,warp之間的關係。由於作者能力有限,難免有疏漏,懇請讀者批評指正。 首先我們要明確:SP(streaming Process),SM(streaming
CUDA程式設計——GPU架構,由sp,sm,thread,block,grid,warp說起
掌握部分硬體知識,有助於程式設計師編寫更好的CUDA程式,提升CUDA程式效能,本文目的是理清sp,sm,thread,block,grid,warp之間的關係。由於作者能力有限,難免有疏漏,懇請讀者批評指正。 首先我們要明確:SP(streaming
利用CUDA進行GPU程式設計(一)
安裝CUDA工具 進行GPU程式設計的第一步,是對程式設計環境進行搭建,小編選擇的是NVIDIA提供的CUDA toolkit, 使用該工具的硬體基礎是電腦顯示卡需要是N卡(即NVIDIA系列顯示卡),通過在電腦中工作管理員的顯示介面卡中檢視自己電腦的顯示卡資訊,也可以在魯大師等軟體中直
《CUDA並行程式設計:GPU程式設計指南》筆記 Chaper 4 環境搭建
關於平臺:Windows、Linux、Mac OS都支援 Windows下環境搭建順序: (1) VS 2010 (必須先安裝VS!,然後再安裝其他) (2) CUDA ToolKit (在9.0版本中
快來操縱你的GPU| CUDA程式設計入門極簡教程
作者: 葉 虎 編輯:李雪冬前
CUDA GPU架構-硬體和軟體
掌握部分硬體知識,有助於程式設計師編寫更好的CUDA程式,提升CUDA程式效能,本文目的是理清sp,sm,thread,block,grid,warp之間的關係。由於作者能力有限,難免有疏漏,懇請讀者批評指正。 首先我們要明確:SP(streaming
看cuda初級教程視訊筆記(周斌講的)--CUDA、GPU程式設計模型
主要內容:cpu和gpu互動模式,gpu執行緒組織模型(不停強化),gpu儲存模型,基本的程式設計問題 cpu-gpu互動 有各自的實體記憶體空間,通過PCIE匯流排互連8GB/s~16GB/s,互動開銷很大 訪存速度,之所以有訪存速度的層次劃分是在價格上和效能上的一個折
GPU程式設計(二): GPU架構瞭解一下!
目錄 前言 GPU架構 GPU處理單元 概念GPU GPU執行緒與SM GPU執行緒 SM 加法 統一記憶體 乘法 最後 前言 在實際CUDA程式設計之前,
《CUDA並行程式設計:GPU程式設計指南》
2014-11-22 實在是找不到英文版了,而現在的工作中又有這樣的迫切的需求,就只能買中文版的了。年初的時候,學習了一本《GPGPU程式設計技術:從GLSL、CUDA到OpenCL》,對C
CUDA程式設計(七)共享記憶體與Thread的同步
https://blog.csdn.net/sunmc1204953974/article/details/51078818 CUDA程式設計(七) 共享記憶體與Thread的同步 在之前我們通過block,繼續增大了執行緒的數量,結果還是比較令人滿意的,但是也產生了一
[轉]分散式系統架構知識體系
註明:原文由【薛定諤貓】發表於其個人微信公眾號【架構師是怎樣煉成的】中。 雙十一終於過去了,趁雙十二的需求還沒下來前,晚上稍微有點時間搞點自己的事情了,距離上篇微信公眾號文章已經過去快三個月了,今天決定寫一篇關於分散式知識體系的文章,分散式架構整個知識體系紛繁複雜,不加以總結很難形成知
CUDA程式設計之快速入門
CUDA(Compute Unified Device Architecture)的中文全稱為計算統一裝置架構。做影象視覺領域的同學多多少少都會接觸到CUDA,畢竟要做效能速度優化,CUDA是個很重要的工具,CUDA是做視覺的同學難以繞過的一個坑,必須踩一踩才踏實。CUDA程式設計真的是入門容易精通難,具有計
Cuda程式設計系列-Cuda程式設計基本概念&程式設計模型
原文連結 系列文章: Cuda程式設計101:Cuda程式設計的基本概念及程式設計模型 Cuda程式設計102:Cuda程式效能相關話題 Cuda程式設計103:Cuda多卡程式設計 Cuda tips: nvcc的-code、-arch、-gencode選項 基本想法 在介紹編
FP16 gemm on cpu not implemented! GPU架構中的半精度與單精度計算
FP16 gemm on cpu not implemented! Stack trace returned 10 entries: (0)/usr/local/lib/python2.7/dist-packages/mxnet-1.3.0-py2.7.egg/mxnet/
重灌Ubuntu 恢復 Cuda + cudnn + GPU driver + tensorflow 環境走過的坑
接上 最近要重現YOLOv3 實時線上物體檢測演算法,程式碼要求Python3.6及以上由於Ubuntu 自帶的Python版本是3.5.2於是索性直接給卸掉了, 由於是Ubuntu自帶的版本, 可能系統需要用到裡面的元件,再次重啟系統的時候產生登陸迴圈login
python並行程式設計 - GPU篇
目錄1 介紹篇 執行緒篇 程序篇 非同步篇 GPU篇 分散式篇 準備 需要有支援CUDA的Nvidia顯示卡 linux檢視顯示卡資訊:lspci | grep -i vga 使用nvidia顯示卡可以這樣檢視:lspci | grep -i
逃離x86架構-----CPU體系結構CISC與RISC之爭
轉載:http://hi.baidu.com/zaoyuan1217/blog/item/59015b11e8385d165baf534e.htmlx86架構誕生 Intel 8086是一個由Intel於1978年所設計的16位微處理器晶片,是x86架構的鼻祖。不久,Intel
Windows下CUDA + TensorFlow-gpu + Keras 配置的坑
最近在學習深度學習,然後在安裝CUDA,TensorFlow-gpu,Keras時遇到了一些坑...下面是我遇到的一些問題 首先我python這方面,是安裝的Anaconda3自帶的python v3.6.3,其實這裡也有個坑,順便說一下。在10月份的時候試了一下,wind
Android專案架構--知識體系簡單梳理(一)
Android專案結構按模組module來劃分 lib_base:包含各種Base基類,如 BaseActivty、BaseFragment、BaseApplication,這是一些專案的開始基礎。
CUDA程式設計--並行矩陣向量乘法【80+行程式碼】
簡述 矩陣向量乘法。 讀取檔案data.txt 並輸入到output.txt檔案中 用typedef方便的修改資料型別(要是寫成模板也是可以的) 程式碼 #include "cuda_runtime.h" #include "device_lau