
CUDA GPU架構-硬體和軟體
掌握部分硬體知識,有助於程式設計師編寫更好的CUDA程式,提升CUDA程式效能,本文目的是理清sp,sm,thread,block,grid,warp之間的關係。由於作者能力有限,難免有疏漏,懇請讀者批評指正。
首先我們要明確:SP(streaming Process),SM(streaming multiprocessor)是硬體(GPU hardware)概念。而thread,block,grid,warp是軟體上的(CUDA)概念。
從硬體看
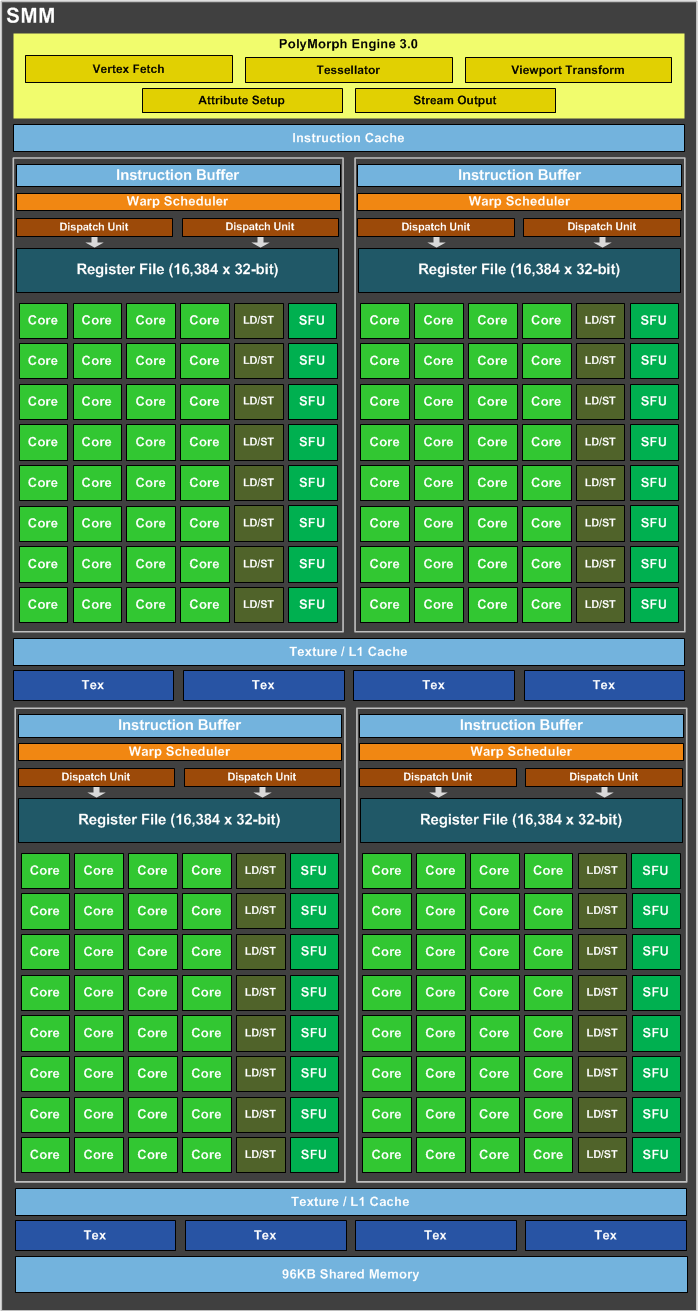
- SP:最基本的處理單元,streaming processor,也稱為CUDA core。最後具體的指令和任務都是在SP上處理的。GPU進行平行計算,也就是很多個SP同時做處理。
- SM:多個SP加上其他的一些資源組成一個streaming multiprocessor。也叫GPU大核,其他資源如:warp scheduler,register,shared memory等。SM可以看做GPU的心臟(對比CPU核心),register和shared memory是SM的稀缺資源。CUDA將這些資源分配給所有駐留在SM中的threads。因此,這些有限的資源就使每個SM中active warps有非常嚴格的限制,也就限制了並行能力。
需要指出,每個SM包含的SP數量依據GPU架構而不同,Fermi架構GF100是32個,GF10X是48個,Kepler架構都是192個,Maxwell都是128個。相同架構的GPU包含的SM數量則根據GPU的中高低端來定。下圖給出Nvidia GTX980 的一個SM示意圖,圖中每個綠色框框表示一個SP。注意,在Maxwell架構中,Nvidia已經把SM改叫SMM。下圖表示的僅僅是一個SMM,一個GPU可以有多個SM(比如16個),最終一個GPU可能包含有上千個SP。這麼多核心“同時執行”,速度可想而知,這個引號只是想表明實際上,軟體邏輯上是所有SP是並行的,但是物理上並不是所有SP都能同時執行計算,因為有些會處於掛起,就緒等其他狀態,這有關GPU的執行緒排程,以後再寫了。
從軟體看
thread,block,grid,warp是CUDA程式設計上的概念,以方便程式設計師軟體設計,組織執行緒,同樣的我們給出一個示意圖來表示。
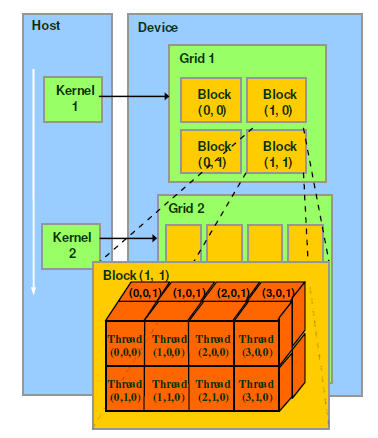
- thread:一個CUDA的並行程式會被以許多個threads來執行。
- block:數個threads會被群組成一個block,同一個block中的threads可以同步,也可以通過shared memory通訊。
- grid:多個blocks則會再構成grid。
- warp:GPU執行程式時的排程單位,目前cuda的warp的大小為32,同在一個warp的執行緒,以不同資料資源執行相同的指令,這就是所謂 SIMT。
對應關係
從軟體上看,SM更像一個獨立的CPU core。SM(Streaming Multiprocessors)是GPU架構中非常重要的部分,GPU硬體的並行性就是由SM決定的。以Fermi架構為例,其包含以下主要組成部分:
- CUDA cores
- Shared Memory/L1Cache
- Register File
- Load/Store Units
- Special Function Units
- Warp Scheduler
GPU中每個sm都設計成支援數以百計的執行緒並行執行,並且每個GPU都包含了很多的SM,所以GPU支援成百上千的執行緒並行執行。當一個kernel啟動後,thread會被分配到這些SM中執行。大量的thread可能會被分配到不同的SM,同一個block中的threads必然在同一個SM中並行(SIMT)執行。每個thread擁有它自己的程式計數器和狀態暫存器,並且用該執行緒自己的資料執行指令,這就是所謂的Single Instruction Multiple Thread。
一個SP可以執行一個thread,但是實際上並不是所有的thread能夠在同一時刻執行。Nvidia把32個threads組成一個warp,warp是排程和執行的基本單元。warp中所有threads並行的執行相同的指令。一個warp需要佔用一個SM執行,多個warps需要輪流進入SM。由SM的硬體warp scheduler負責排程。目前每個warp包含32個threads(Nvidia保留修改數量的權利)。所以,一個GPU上resident thread最多隻有
SM*warp個。
SIMT和SIMD
CUDA是一種典型的SIMT架構(單指令多執行緒架構),SIMT和SIMD(Single Instruction, Multiple Data)類似,SIMT應該算是SIMD的升級版,更靈活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通過將同樣的指令廣播給多個執行官單元來實現並行。一個主要的不同就是,SIMD要求所有的vector element在一個統一的同步組裡同步的執行,而SIMT允許執行緒們在一個warp中獨立的執行。SIMT有三個SIMD沒有的主要特徵:
- 每個thread擁有自己的instruction address counter
- 每個thread擁有自己的狀態暫存器
- 每個thread可以有自己獨立的執行路徑
更細節的差異可以看這裡。
前面已經說block是軟體概念,一個block只會由一個sm排程,程式設計師在開發時,通過設定block的屬性,**“告訴”**GPU硬體,我有多少個執行緒,執行緒怎麼組織。而具體怎麼排程由sm的warps scheduler負責,block一旦被分配好SM,該block就會一直駐留在該SM中,直到執行結束。一個SM可以同時擁有多個blocks,但需要序列執行。下圖顯示了軟體硬體方面的術語對應關係:

需要注意的是,大部分threads只是邏輯上並行,並不是所有的thread可以在物理上同時執行。例如,遇到分支語句(if else,while,for等)時,各個thread的執行條件不一樣必然產生分支執行,這就導致同一個block中的執行緒可能會有不同步調。另外,並行thread之間的共享資料會導致競態:多個執行緒請求同一個數據會導致未定義行為。CUDA提供了cudaThreadSynchronize()來同步同一個block的thread以保證在進行下一步處理之前,所有thread都到達某個時間點。
同一個warp中的thread可以以任意順序執行,active warps被sm資源限制。當一個warp空閒時,SM就可以排程駐留在該SM中另一個可用warp。在併發的warp之間切換是沒什麼消耗的,因為硬體資源早就被分配到所有thread和block,所以該新排程的warp的狀態已經儲存在SM中了。不同於CPU,CPU切換執行緒需要儲存/讀取執行緒上下文(register內容),這是非常耗時的,而GPU為每個threads提供物理register,無需儲存/讀取上下文。
相關推薦
CUDA GPU架構-硬體和軟體
掌握部分硬體知識,有助於程式設計師編寫更好的CUDA程式,提升CUDA程式效能,本文目的是理清sp,sm,thread,block,grid,warp之間的關係。由於作者能力有限,難免有疏漏,懇請讀者批評指正。 首先我們要明確:SP(streaming
1、藍芽核心技術瞭解(藍芽協議、架構、硬體和軟體筆記)
原文地址:http://www.cnblogs.com/zjutlitao/p/4742428.html 宣告:這篇文章是樓主beautifulzzzz學習網上關於藍芽的相關知識的筆記,其中比較多的受益於xubin341719的藍芽系列文章,同時還有其他網上作者的資料。由於有些文章只做參
HI3518E方案整體架構介紹(硬體和軟體支援)
以下內容源於朱有鵬嵌入式課程的學習,如有侵權,請告知刪除。1、硬體(1)HI3518E單晶片提供:CPU + DSP + 內建64MB DDR + ETHERNET MAC。(2)外接16MB的SPI介面的Flash用來存放程式(uboot、kernel、rootfs、app
藍芽核心技術瞭解(藍芽協議、架構、硬體和軟體筆記)
下面是摘抄筆記內容: 藍芽,是一種支援裝置短距離通訊(一般10m內)的無線電技術。能在包括行動電話、PDA、無線耳機、膝上型電腦、相關外設等眾多裝置之間進行無線資訊交換。利用“藍芽”技術,能夠有效地簡化行動通訊終端裝置之間的通訊,也能夠成功地
硬體堆疊和軟體堆疊
看法一: 關於硬體棧與軟體棧的看法: 一、在使用上 由 ss 與 esp 組成的棧結構已經可以算是硬體棧了,它們的 pop/push 行為都是由處理器去維護了。 軟體棧:軟體可以自己定義一個數據結構,pop/push 行為需由軟
資訊學奧賽系列教程:計算機硬體系統和軟體系統
計算機系統: 一個完整的計算機系統有硬體系統和軟體系統構成,如下圖所示 計算機硬體系統: 本節介紹計算機硬體系統,計算機硬體系統由以下四個部分構成: 運算器、控制器(CPU) 儲存器 輸入裝置 輸出裝置
Linux電源管理(2)_Generic PM之基本概念和軟體架構
1. 前言 這裡的Generic PM,是蝸蝸自己起的名字,指Linux系統中那些常規的電源管理手段,包括關機(Power off)、待機(Standby or Hibernate)、重啟(Reboot)等。這些手段是在嵌入式Linux普及之前的PC或者伺服器時代使用的。在那個電腦科學的蠻荒時
CUDA程式設計——GPU架構,由sp,sm,thread,block,grid,warp說起
掌握部分硬體知識,有助於程式設計師編寫更好的CUDA程式,提升CUDA程式效能,本文目的是理清sp,sm,thread,block,grid,warp之間的關係。由於作者能力有限,難免有疏漏,懇請讀者批評指正。 首先我們要明確:SP(streaming
CUDA程式設計-GPU架構軟硬體體系
掌握部分硬體知識,有助於程式設計師編寫更好的CUDA程式,提升CUDA程式效能,本文目的是理清sp,sm,thread,block,grid,warp之間的關係。由於作者能力有限,難免有疏漏,懇請讀者批評指正。 首先我們要明確:SP(streaming Process),SM(streaming
軟體框架和軟體架構的區別?
初學java,遇到jdk,sdk概念:(外語首字母縮寫:SDK、外語全稱:Software Development Kit)一般都是一些軟體工程師為特定的軟體包、軟體框架、硬體平臺、作業系統等建立應用軟體時的開發工具的集合。 軟體包:(SoftWare Package)是指具有特定的功能,用來完成特定
Dronecode 平臺硬體及軟體架構
想要入坑PX4之前,提前理解下面這張圖能少走很多彎路。以下是翻譯,圖上是個人註解 下圖就是Dronecode 平臺的從頂層視角的一個概覽。左邊淡藍色的是可能的飛控硬體,它可以通過RTPS連線到右邊深藍色的感知計算機。感知計算機能利用攝像頭感測器陣列進行視覺控制和自動避障,
硬體IIC和軟體IIC區別
所謂硬體I2C對應晶片上的I2C外設,有相應I2C驅動電路,其所使用的I2C管腳也是專用的;軟體I2C一般是用GPIO管腳,用軟體控制管腳狀態以模擬I2C通訊波形。 硬體I2C的效率要遠高於軟體的,而軟體I2C由於不受管腳限制,介面比較靈活。 模擬I2C 是通過GPI
【GPU程式設計系列之一】從深度學習選擇什麼樣的gpu來談談gpu的硬體架構
轉自:http://chenrudan.github.io/blog/2015/12/20/introductionofgpuhardware.html 從深度學習在2012年大放異彩,gpu計算也走入了人們的視線之中,它使得大規模計算神經網路成為可能。人們可以通過07
關於NSA病毒的啟示:由硬體到軟體的自主化和基於安全的特殊訂製化會不會是一個必然趨勢?
最近爆發大規模的NSA病毒。這是一個常規的病毒攻擊。但是出現了戲劇性的彈出介面表現非常惡劣。之前的病毒不外乎獲取使用者隱私,盜取賬號,或者把電腦變成再次攻擊的支點。這次的病毒致使區域網聯網方式的電腦和缺乏防範意識的電腦紛紛中毒,包括加油站,醫院,校園網等基礎網路。到目前為止
ubuntu 上檢視硬體配置和軟體環境
通過命令 inxi -FxzSystem: Host: K29 Kernel: 4.10.0-37-generic x86_64 (64 bit gcc: 5.4.0) Desktop: Cinnamon 3.4.3 (Gtk 3.18.9-1ub
硬體堆疊和軟體堆疊在AVR中的理解
關於棧和堆的一些資料。 首先是從理論上的東西。。網上轉載來的,後面是看AVR程式碼時得出的一些東西。 硬體堆疊:或許也可以稱作系統堆疊,是位於片內RAM區。有人說,只要能使用PUSH,POP指令的微控制器,都可以說含有硬體堆疊。這樣的說法我個人覺得不是很全面。通過指令進行壓
cuda GPU 編程之共享內存的使用
ret 指定大小 最新 宏定義 編程 int 重要 core 申請 原理上來說,共享內存是GPU上可受用戶控制的一級緩存。在一個SM中,存在著若幹cuda core + DP(雙精度計算單元) + SFU(特殊函數計算單元)+共享內存+常量內存+紋理內存。相對於全局內存
《Netty5.0架構剖析和源碼解讀》【PDF】下載
推薦 作者 服務 inux 推廣 內容 關註 bootstra 中間件 《Netty5.0架構剖析和源碼解讀》【PDF】下載鏈接: https://u253469.pipipan.com/fs/253469-230062545 內容簡介 Netty 是個異步的事件
數據中心架構ToR和EoR【總結】
需要 lan des blog 從服務器 總結 業務 解決 tor 1、前言 最近在看《雲數據中心網絡技術》,學習了企業數據中心網絡建設過程,看到有ToR和EoR兩種布線方式,之前沒有接觸過,今天總結一下。 2、布線方式 ToR:(Top of Rack)接入方式
轉載:大型網站架構演變和知識體系
什麽 伸縮 mage 就會 夢想 靜態 結構 獲取 復用性 https://wenku.baidu.com/view/42081217581b6bd97e19ea04 架構演變第一步:物理分離 webserver 和數據庫 最開始,由於某些想法,於是在互聯網上搭建了一個網