
雙目立體匹配流程——歸一化互相關(NCC)
原文連結 :http://www.cnblogs.com/yepeichu/p/7354083.html
歸一化相關性,normalization cross-correlation,因此簡稱NCC,下文中筆者將用NCC來代替這冗長的名稱。
NCC,顧名思義,就是用於歸一化待匹配目標之間的相關程度,注意這裡比較的是原始畫素。通過在待匹配畫素位置p(px,py)構建3*3鄰域匹配視窗,與目標畫素位置p'(px+d,py)同樣構建鄰域匹配視窗的方式建立目標函式來對匹配視窗進行度量相關性,注意這裡構建相關視窗的前提是兩幀影象之間已經校正到水平位置,即光心處於同一水平線上,此時極線是水平的,否則匹配過程只能在傾斜的極線方向上完成,這將消耗更多的計算資源
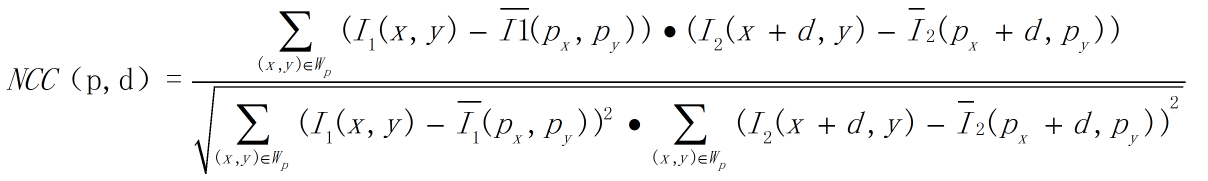
上式中的變數需要解釋一下:其中p點表示影象I1待匹配畫素座標(px,py),d表示在影象I2被查詢畫素位置在水平方向上與px的距離。如下圖所示:
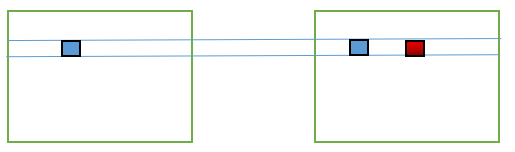
左邊為影象I1,右邊為影象I2。影象I1,藍色方框表示待匹配畫素座標(px,py),影象I2藍色方框表示座標位置為(px,py),紅色方框表示座標位置(px+d,py)。(由於畫圖水平有限,只能文字和圖片雙重說明來完成了~)
Wp表示以待匹配畫素座標為中心的匹配視窗,通常為3*3匹配視窗。
沒有上劃線的I1表示匹配視窗中某個畫素位置的畫素值,帶上劃線的I1表示匹配視窗所有畫素的均值。I2
上述公式表示度量兩個匹配視窗之間的相關性,通過歸一化將匹配結果限制在 [-1,1]的範圍內,可以非常方便得到判斷匹配視窗相關程度:
若NCC = -1,則表示兩個匹配視窗完全不相關,相反,若NCC = 1時,表示兩個匹配視窗相關程度非常高。
我們很自然的可以想到,如果同一個相機連續拍攝兩張影象(注意,此時相機沒有旋轉也沒有位移,此外光照沒有明顯變化,因為基於原始畫素的匹配方法通常對上述條件是不具備不變性的),其中有一個位置是重複出現在兩幀影象中的。比如桌子上的一個可樂瓶。那麼我們就可以對這個可樂瓶的位置做一下匹配。直觀的看,第一幀中可樂瓶上某一個點,它所構成鄰域視窗按理說應該是與第二幀相同的,就算不完全相同,也應該是具有非常高相關性的。基於這種感性的理解,於是才有前輩提出上述的NCC匹配方法。(純屬個人理解)
雙目立體匹配,這一部分是說明NCC如何用於雙目匹配。
假設有校正過的兩幀影象I1,、I2,由上述NCC計算流程的描述可知,對影象I1一個待匹配畫素構建3*3匹配視窗,在影象I2極線上對每一個畫素構建匹配視窗與待匹配畫素匹配視窗計算相關性,相關性最高的視為最優匹配。很明顯,這是一個一對多的過程。如果影象尺寸是640*480,則每一個畫素的匹配過程是是1對640,兩幀影象完全匹配需要計算640*480*640 = 196608000,即一億九千多萬次~ 儘管計算機計算速度非常快,但也著實是非常消耗計算資源的。由於NCC匹配流程是通過在同一行中查詢最優匹配,因此它可以並行處理,這大概也算是一種彌補吧~
雙目立體匹配流程如下:
1. 採集影象:通過標定好的雙目相機採集影象,當然也可以用兩個單目相機來組合成雙目相機。(標定方法下次再說)
2. 極線校正:校正的目的是使兩幀影象極線處於水平方向,或者說是使兩幀影象的光心處於同一水平線上。通過校正極線可以方便後續的NCC操作。
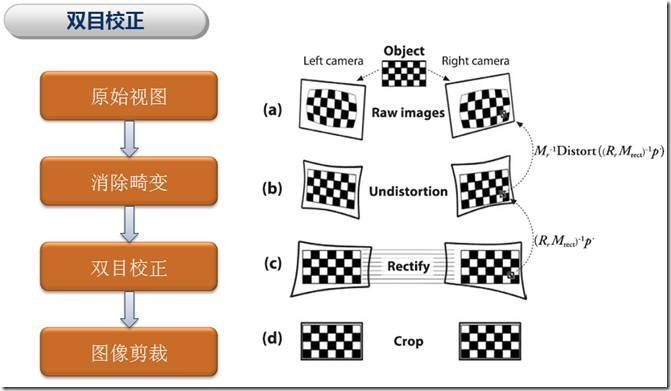
2.1 由標定得到的內參中畸變資訊中可以對影象去除畸變,在OpenCV中有函式對去畸變做了實現
void stereoRectify(InputArray cameraMatrix1, InputArray distCoeffs1, InputArray cameraMatrix2, InputArray distCoeffs2, Size imageSize, InputArray R, InputArray T, OutputArray R1, OutputArray R2, OutputArray P1, OutputArray P2, OutputArray Q, int flags=CALIB_ZERO_DISPARITY, double alpha=-1, Size newImageSize=Size(), Rect* validPixROI1=0, Rect* validPixROI2=0 ) cameraMatrix1:第一個相機矩陣(這裡我們是雙目的左相機). cameraMatrix2: 第二個相機矩陣(雙目的右相機). distCoeffs1:第一個相機畸變引數. distCoeffs2: 第二個相機畸變引數. imageSize:用於校正的影象大小. R:第一和第二相機座標系之間的旋轉矩陣(左相機相對於右相機的旋轉) T:第一和第二相機座標系之間的平移矩陣(左相機相對於右相機的位移) R1:輸出第一個相機的3x3矯正變換(旋轉矩陣) . R2:輸出第二個相機的3x3矯正變換(旋轉矩陣) . P1:在第一臺相機的新的座標系統(矯正過的)輸出 3x4 的投影矩陣 P2:在第二臺相機的新的座標系統(矯正過的)輸出 3x4 的投影矩陣 Q:輸出深度視差對映矩陣 flags:操作的 flag可以是零或者是CV_CALIB_ZERO_DISPARITY。如果設定了CV_CALIB_ZERO_DISPARITY,函式的作用是使每個相機的主點在校正後的影象上有相同的畫素座標;如果未設定標誌,功能還可以改變影象在水平或垂直方向(取決於極線的方向)來最大化有用的影象區域。 alpha:自由縮放參數。如果是-1或沒有,該函式執行預設縮放。否則,該引數應在0和1之間。alpha=0,校正後的影象進行縮放和偏移,只有有效畫素是可見的(校正後沒有黑色區域);alpha= 1意味著校正影象的抽取和轉移,所有相機原始影象素像保留在校正後的影象(源影象畫素沒有丟失)。顯然,任何中間值產生這兩種極端情況之間的中間結果。 newImageSize:校正後新的影象解析度。 validPixROI1: 校正後的影象可選的輸出矩形,裡面所有畫素都是有效的。如果alpha= 0,ROIs覆蓋整個影象。否則,他們可能會比較小。 validPixROI2: 校正後的影象可選的輸出矩形,裡面所有畫素都是有效的。如果alpha= 0,ROIs覆蓋整個影象。否則,他們可能會比較小。 2.2 通過校正函式校正以後得到相機的矯正變換R和新的投影矩陣P,接下來是要對左右檢視進行去畸變,並得到重對映矩陣。這裡,我們還是用OpenCV函式 void initUndistortRectifyMap( InputArray cameraMatrix, InputArray distCoeffs, InputArray R, InputArray newCameraMatrix, Size size, int m1type, OutputArray map1, OutputArray map2 ) cameraMatrix:輸入的攝像機內參數矩陣 distCoeffs:輸入的攝像機畸變係數矩陣 R:輸入的第一和第二相機座標系之間的旋轉矩陣(我們這裡是利用上述校正得到的旋轉矩陣) newCameraMatrix:輸入的校正後的3X3攝像機矩陣(我們這裡是使用上述校正得到的投影矩陣) size:攝像機採集的無失真影象尺寸 m1type:map1的資料型別,可以是CV_32FC1或CV_16SC2 map1:輸出的X座標重對映引數 map2:輸出的Y座標重對映引數 2.2 根據上述得到的重對映引數map1,map2,我們需要進一步對原始影象進行重對映到新的平面中才能去除影象畸變,同樣,實現方式仍是使用現有的OpenCV函式void remap(InputArray src, OutputArray dst, InputArray map1, InputArray map2, int interpolation, intborderMode = BORDER_CONSTANT, const Scalar& borderValue = Scalar() )
src:輸入影象,即原影象,需要單通道8位或者浮點型別的影象
dst:輸出影象,即目標影象,需和原圖形一樣的尺寸和型別
map1:它有兩種可能表示的物件:(1)表示點(x,y)的第一個對映;(2)表示CV_16SC2,CV_32FC1等型別的x值矩陣
map2:它有兩種可能表示的物件:(1)若map1表示點(x,y)時,這個引數不代表任何值;(2)表示CV_16UC1,CV_32FC1等型別y值矩陣
interpolation:插值方式,有四中插值方式:(1)INTER_NEAREST——最近鄰插值,(2)INTER_LINEAR——雙線性插值(預設),(3)INTER_CUBIC——雙三樣條插值(預設),(4)INTER_LANCZOS4——lanczos插值(預設)
intborderMode :邊界模式,預設BORDER_CONSTANT
borderValue :邊界顏色,預設Scalar()黑色
2.3 通過上述兩步操作,我們成功地對影象去除了畸變,並且校正了影象極線。注意,在立體校正階段需要設定alpha = 0才能完成對影象的裁剪,否則會有黑邊。
3. 特徵匹配:這裡便是我們利用NCC做匹配的步驟啦,匹配方法如上所述,右檢視中與左檢視待測畫素同一水平線上相關性最高的即為最優匹配。完成匹配後,我們需要記錄其視差d,即待測畫素水平方向xl與匹配畫素水平方向xr之間的差值d = xr - xl,最終我們可以得到一個與原始影象尺寸相同的視差圖D。
4. 深度恢復:通過上述匹配結果得到的視差圖D,我們可以很簡單的利用相似三角形反推出以左檢視為參考系的深度圖。計算原理如下圖所示: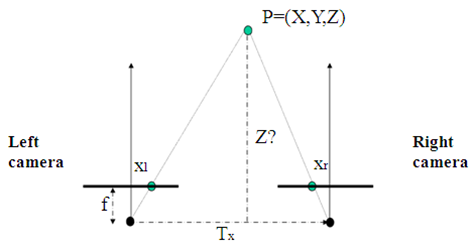
如圖,Tx為雙目相機基線,f為相機焦距,這些可以通過相機標定步驟得到。而xr - xl就是視差d。
通過公式 z = f * Tx / d可以很簡單地得到以左檢視為參考系的深度圖了。
至此,我們便完成了雙目立體匹配。倘若只是用於影象識別,那麼到步驟3時已經可以結束了。
OK,最後一部分就是程式碼實現部分了,哎~ 寫太累了,下次再補上。
未完待續。。。
相關推薦
雙目立體匹配流程——歸一化互相關(NCC)
原文連結 :http://www.cnblogs.com/yepeichu/p/7354083.html 歸一化相關性,normalization cross-correlation,因此簡稱NCC,下文中筆者將用NCC來代替這冗長的名稱。 NCC,顧名思義,就是
雙目立體匹配——歸一化互相關(NCC)
歸一化相關性,normalization cross-correlation,因此簡稱NCC,下文中筆者將用NCC來代替這冗長的名稱。 NCC,顧名思義,就是用於歸一化待匹配目標之間的相關程度,注意這裡比較的是原始畫素。通過在待匹配畫素位置p(px,py)構建3*3鄰域匹配視窗,
雙目立體匹配經典演算法之Semi-Global Matching(SGM)概述:匹配代價計算之互資訊(Mutual Information,MI)
半全域性立體匹配演算法Semi-Global Matching,SGM由學者Hirschmüller在2005年所提出1,提出的背景是一方面高效率的區域性演算法由於所基於的區域性視窗視差相同的假設在很多情況下並不成立導致匹配效果較差;而另一方面全域性演算法雖然通過二維相鄰畫素視差之間
影象匹配之歸一化積相關灰度匹配——opencv
#include<opencv2/opencv.hpp> #include<opencv2/highgui.hpp> #include<iostream> using namespace std; using namespac
Java8 - 定製歸一化收集器(reducing)得到自定義結果集
reducing簡介 reducing 是一個收集器(操作),從字面意義上可以理解為“減少操作”:輸入多個元素,在一定的操作後,元素減少。 reducing 有多個過載方法,其中一個方法如下: public static <T> Collector<T
雙目立體匹配經典演算法之Semi-Global Matching(SGM)概述:視差計算、視差優化
文章目錄 視差計算 視差優化 剔除錯誤匹配 提高視差精度 抑制噪聲 視差計算 在SGM演算法中,視差計算採用贏家通吃(WTA)演算法,每個畫素選擇最小聚
雙目立體匹配經典演算法之Semi-Global Matching(SGM)概述:代價聚合(Cost Aggregation)
由於代價計算步驟只考慮了局部的相關性,對噪聲非常敏感,無法直接用來計算最優視差,所以SGM演算法通過代價聚合步驟,使聚合後的代價值能夠更準確的反應畫素之間的相關性,如圖1所示。聚合後的新的代價值儲存在與匹配代價空間C同樣大小的聚合代價空間S中,且元素位置一一對應。 圖1:代價聚合
雙目立體匹配經典演算法之Semi-Global Matching(SGM)概述:匹配代價計算之Census變換(Census Transform,CT)
基於互資訊的匹配代價計算由於需要初始視差值,所以需要通過分層迭代的方式得到較為準確的匹配代價值,而且概率分佈計算稍顯複雜,這導致代價計算的效率並不高。學者Zabih和Woodfill 1 提出的基於Census變換法也被廣泛用於匹配代價計算。Census變換是使用畫素鄰域內的區域性灰
定製歸一化收集器(reducing)得到自定義結果集
reducing簡介 reducing 是一個收集器(操作),從字面意義上可以理解為“減少操作”:輸入多個元素,在一定的操作後,元素減少。 reducing 有多個過載方法,其中一個方法如下: public static <T> Collector<
雙目立體匹配流程詳解
雙目立體匹配一直是雙目視覺的研究熱點,雙目相機拍攝同一場景的左、右兩幅視點影象,運用立體匹配匹配演算法獲取視差圖,進而獲取深度圖。而深度圖的應用範圍非常廣泛,由於其能夠記錄場景中物體距離攝像機的距離,可以用以測量、三維重建、以及虛擬視點的合成等。
影象匹配 | NCC 歸一化互相關損失 | 程式碼 + 講解
- 文章轉載自:微信公眾號「機器學習煉丹術」 - 作者:煉丹兄(已授權) - 作者聯絡方式:微信cyx645016617(歡迎交流共同進步) 本次的內容主要講解NCC**Normalized cross-correlation** 歸一化互相關。 兩張圖片是否是同一個內容,現在深度學習的方案自然是用神經網
Python基礎day-18[面向對象:繼承,組合,接口歸一化]
ini 關系 acl 報錯 子類 wan 使用 pytho 減少 繼承: 在Python3中默認繼承object類。但凡是繼承了object類以及子類的類稱為新式類(Python3中全是這個)。沒有繼承的稱為經典類(在Python2中沒有繼承object以及他的子類都是
轉:數據標準化/歸一化normalization
簡單 此外 urn csdn bsp center sum 又能 超出 轉自:數據標準化/歸一化normalization 這裏主要講連續型特征歸一化的常用方法。離散參考[數據預處理:獨熱編碼(One-Hot Encoding)]。 基礎知識參考: [均值、方差與協方
numpy 矩陣歸一化
ges 矩陣歸一化 mali zeros sha ati ret turn tile new_value = (value - min)/(max-min) def normalization(datingDatamat): max_arr = datingData
【深度學習】批歸一化(Batch Normalization)
學習 src 試用 其中 put min 平移 深度 優化方法 BN是由Google於2015年提出,這是一個深度神經網絡訓練的技巧,它不僅可以加快了模型的收斂速度,而且更重要的是在一定程度緩解了深層網絡中“梯度彌散”的問題,從而使得訓練深層網絡模型更加容易和穩定。所以目前
Hulu機器學習問題與解答系列 | 二十三:神經網絡訓練中的批量歸一化
導致 xsl 泛化能力 恢復 不同 詳細 過程 ice ini 來看看批量歸一化的有關問題吧!記得進入公號菜單“機器學習”,復習之前的系列文章噢。 今天的內容是 【神經網絡訓練中的批量歸一化】 場景描述 深度神經網絡的訓練中涉及諸多手調參數,如學習率,權重衰減系數,
softmax_loss的歸一化問題
outer bubuko prot 歸一化 實現 大小 定義 num blog cnn網絡中,網絡更新一次參數是根據loss反向傳播來,這個loss是一個batch_size的圖像前向傳播得到的loss和除以batch_size大小得到的平均loss。 softmax_l
機器學習數據預處理——標準化/歸一化方法總結
目標 out enc 並不是 depend 區間 standards ima HA 通常,在Data Science中,預處理數據有一個很關鍵的步驟就是數據的標準化。這裏主要引用sklearn文檔中的一些東西來說明,主要把各個標準化方法的應用場景以及優缺點總結概括,以來充當
python 圖像歸一化作業代碼代編程代寫圖python作業
一個 return clas contents eth AR ips port cto python 圖像歸一化作業代碼代編程代寫圖python作業from PIL import Image import os import sys import numpy as np i