
21、Java併發類庫提供的執行緒池有哪幾種? 分別有什麼特點?(高併發程式設計----7)
目錄
今天我要問你的問題是,Java 併發類庫提供的執行緒池有哪幾種? 分別有什麼特點?
下面我就從原始碼角度,分析執行緒池的設計與實現,我將主要圍繞最基礎的 ThreadPoolExecutor 原始碼。
進一步分析,執行緒池既然有生命週期,它的狀態是如何表徵的呢?
我在專欄第 17 講中介紹過執行緒是不能夠重複啟動的(兩次呼叫start()),建立或銷燬執行緒存在一定的開銷,所以利用執行緒池技術來提高系統資源利用效率,並簡化執行緒管理,已經是非常成熟的選擇。
今天我要問你的問題是,Java 併發類庫提供的執行緒池有哪幾種? 分別有什麼特點?
典型回答
通常開發者都是利用 Executors 提供的通用執行緒池建立方法,去建立不同配置的執行緒池,主要區別在於不同的 ExecutorService 型別或者不同的初始引數。
Executors 目前提供了 5 種不同的執行緒池建立配置:
- newCachedThreadPool(),它是一種用來處理大量短時間工作任務的執行緒池,具有幾個鮮明特點:它會試圖快取執行緒並重用,當無快取執行緒可用時,就會建立新的工作執行緒;如果執行緒閒置的時間超過60 秒,則被終止並移出快取;長時間閒置時,這種執行緒池,不會消耗什麼資源。其內部使用 SynchronousQueue 作為工作佇列。
- newFixedThreadPool(int nThreads),重用指定數目(nThreads)的執行緒,其背後使用的是無界的工作佇列,任何時候最多有 nThreads 個工作執行緒是活動的。這意味著,如果任務數量超過了活動佇列數目,將在工作佇列中等待空閒執行緒出現;如果有工作執行緒退出,將會有新的工作執行緒被建立,以補足指定的數目 nThreads。
- newSingleThreadExecutor(),它的特點在於工作執行緒數目被限制為 1,操作一個無界的工作佇列,所以它保證了所有任務的都是被順序執行,最多會有一個任務處於活動狀態,並且不允許使用者改動執行緒池例項,因此可以避免其改變執行緒數目。
- newSingleThreadScheduledExecutor() 和 newScheduledThreadPool(int corePoolSize),建立的是個 ScheduledThreadPoolExecutor,可以進行定時或週期性的工作排程,區別在於單一工作執行緒還是多個工作執行緒。
- newWorkStealingPool(int parallelism),這是一個經常被人忽略的執行緒池,Java 8 才加入這個建立方法,其內部會構建ForkJoinPool,利用Work-Stealing演算法,並行地處理任務,不保證處理順序。
考點分析
Java 併發包中的 Executor 框架無疑是併發程式設計中的重點,今天的題目考察的是對幾種標準執行緒池的瞭解,我提供的是一個針對最常見的應用方式的回答。
在大多數應用場景下,使用 Executors 提供的 5 個靜態工廠方法就足夠了,但是仍然可能需要直接利用 ThreadPoolExecutor 等建構函式建立,這就要求你對執行緒構造方式有進一步的瞭解,你需要明白執行緒池的設計和結構。
另外,執行緒池這個定義就是個容易讓人誤解的術語,因為 ExecutorService 除了通常意義上“池”的功能,還提供了更全面的執行緒管理、任務提交等方法。
Executor 框架可不僅僅是執行緒池,我覺得至少下面幾點值得深入學習:
- 掌握 Executor 框架的主要內容,至少要了解組成與職責,掌握基本開發用例中的使用。
- 對執行緒池和相關併發工具型別的理解,甚至是原始碼層面的掌握。
- 實踐中有哪些常見問題,基本的診斷思路是怎樣的。
- 如何根據自身應用特點合理使用執行緒池。
知識擴充套件
首先,我們來看看 Executor 框架的基本組成,請參考下面的類圖。
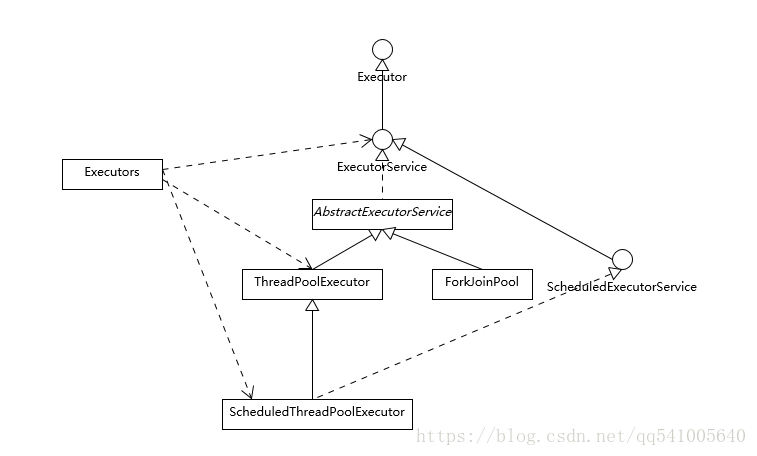
我們從整體上把握一下各個型別的主要設計目的:
- Executor 是一個基礎的介面,其初衷是將任務提交和任務執行細節解耦,這一點可以體會其定義的唯一方法。
void execute(Runnable command);Executor 的設計是源於 Java 早期執行緒 API 使用的教訓,開發者在實現應用邏輯時,被太多執行緒建立、排程等不相關細節所打擾。就像我們進行 HTTP 通訊,如果還需要自己操作 TCP 握手,開發效率低下,質量也難以保證。
- ExecutorService 則更加完善,不僅提供 service 的管理功能,比如 shutdown 等方法,也提供了更加全面的提交任務機制,如返回Future而不是 void 的 submit 方法。
<T> Future<T> submit(Callable<T> task);注意,這個例子輸入的可是Callable,它解決了 Runnable 無法返回結果的困擾。
- Java 標準類庫提供了幾種基礎實現,比如ThreadPoolExecutor、ScheduledThreadPoolExecutor、ForkJoinPool。這些執行緒池的設計特點在於其高度的可調節性和靈活性,以儘量滿足複雜多變的實際應用場景,我會進一步分析其構建部分的原始碼,剖析這種靈活性的源頭。
- Executors 則從簡化使用的角度,為我們提供了各種方便的靜態工廠方法。
下面我就從原始碼角度,分析執行緒池的設計與實現,我將主要圍繞最基礎的 ThreadPoolExecutor 原始碼。
ScheduledThreadPoolExecutor 是 ThreadPoolExecutor 的擴充套件,主要是增加了排程邏輯,如想深入瞭解,你可以參考相關教程。而 ForkJoinPool 則是為 ForkJoinTask 定製的執行緒池,與通常意義的執行緒池有所不同。
ThreadPoolExecutor 原始碼這部分內容比較晦澀,羅列概念也不利於你去理解,所以我會配合一些示意圖來說明。在現實應用中,理解應用與執行緒池的互動和執行緒池的內部工作過程,你可以參考下圖。
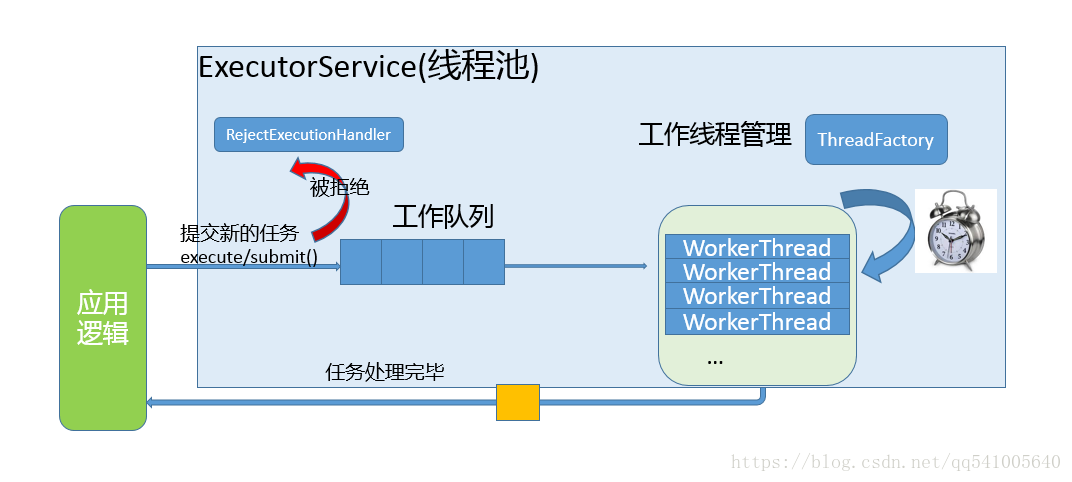
簡單理解一下:
- 工作佇列負責儲存使用者提交的各個任務,這個工作佇列,可以是容量為 0 的 SynchronousQueue(使用 newCachedThreadPool),也可以是像固定大小執行緒池(newFixedThreadPool)那樣使用 LinkedBlockingQueue。
private final BlockingQueue<Runnable> workQueue;- 內部的“執行緒池”,這是指保持工作執行緒的集合,執行緒池需要在執行過程中管理執行緒建立、銷燬。例如,對於帶快取的執行緒池,當任務壓力較大時,執行緒池會建立新的工作執行緒;當業務壓力退去,執行緒池會在閒置一段時間(預設,60 秒)後結束執行緒。
private final HashSet<Worker> workers = new HashSet<>();執行緒池的工作執行緒被抽象為靜態內部類 Worker,基於AQS實現。
- ThreadFactory 提供上面所需要的建立執行緒邏輯。
- 如果任務提交時被拒絕,比如執行緒池已經處於 SHUTDOWN 狀態,需要為其提供處理邏輯,Java 標準庫提供了類似ThreadPoolExecutor.AbortPolicy等預設實現,也可以按照實際需求自定義。
從上面的分析,就可以看出執行緒池的幾個基本組成部分,一起都體現線上程池的建構函式中,從字面我們就可以大概猜測到其用意:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)- corePoolSize,所謂的核心執行緒數,可以大致理解為長期駐留的執行緒數目(除非設定了 allowCoreThreadTimeOut)。對於不同的執行緒池,這個值可能會有很大區別,比如 newFixedThreadPool 會將其設定為 nThreads,而對於 newCachedThreadPool 則是為 0。
- maximumPoolSize,顧名思義,就是執行緒不夠時能夠建立的最大執行緒數。同樣進行對比,對於 newFixedThreadPool,當然就是 nThreads,因為其要求是固定大小,而 newCachedThreadPool 則是 Integer.MAX_VALUE。
- keepAliveTime 和 TimeUnit,這兩個引數指定了額外的執行緒能夠閒置多久,顯然有些執行緒池不需要它。
- workQueue,工作佇列,必須是 BlockingQueue。
通過配置不同的引數,我們就可以創建出行為大相徑庭的執行緒池,這就是執行緒池高度靈活性的基礎。
進一步分析,執行緒池既然有生命週期,它的狀態是如何表徵的呢?
這裡有一個非常有意思的設計,ctl 變數被賦予了雙重角色,通過高低位的不同,既表示執行緒池狀態,又表示工作執行緒數目,這是一個典型的高效優化。試想,實際系統中,雖然我們可以指定執行緒極限為 Integer.MAX_VALUE,但是因為資源限制,這只是個理論值,所以完全可以將空閒位賦予其他意義。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 真正決定了工作執行緒數的理論上限
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int COUNT_MASK = (1 << COUNT_BITS) - 1;
// 執行緒池狀態,儲存在數字的高位
private static final int RUNNING = -1 << COUNT_BITS;
…
// Packing and unpacking ctl
private static int runStateOf(int c) { return c & ~COUNT_MASK; }
private static int workerCountOf(int c) { return c & COUNT_MASK; }
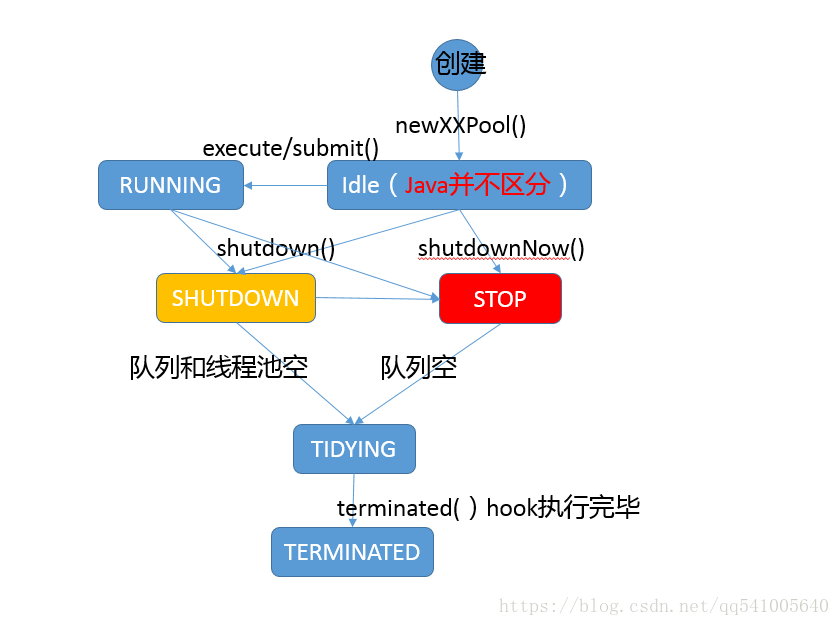
private static int ctlOf(int rs, int wc) { return rs | wc; }為了讓你能對執行緒生命週期有個更加清晰的印象,我這裡畫了一個簡單的狀態流轉圖,對執行緒池的可能狀態和其內部方法之間進行了對應,如果有不理解的方法,請參考 Javadoc。注意,實際 Java 程式碼中並不存在所謂 Idle 狀態,我新增它僅僅是便於理解。
前面都是對執行緒池屬性和構建等方面的分析,下面我選擇典型的 execute 方法,來看看其是如何工作的,具體邏輯請參考我新增的註釋,配合程式碼更加容易理解。
public void execute(Runnable command) {
…
int c = ctl.get();
// 檢查工作執行緒數目,低於 corePoolSize 則新增 Worker
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// isRunning 就是檢查執行緒池是否被 shutdown
// 工作佇列可能是有界的,offer 是比較友好的入隊方式
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 再次進行防禦性檢查
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 嘗試新增一個 worker,如果失敗以為著已經飽和或者被 shutdown 了
else if (!addWorker(command, false))
reject(command);
}
執行緒池實踐
執行緒池雖然為提供了非常強大、方便的功能,但是也不是銀彈,使用不當同樣會導致問題。我這裡介紹些典型情況,經過前面的分析,很多方面可以自然的推匯出來。
- 避免任務堆積。前面我說過 newFixedThreadPool 是建立指定數目的執行緒,但是其工作佇列是無界的,如果工作執行緒數目太少,導致處理跟不上入隊的速度,這就很有可能佔用大量系統記憶體,甚至是出現 OOM。診斷時,你可以使用 jmap 之類的工具,檢視是否有大量的任務物件入隊。
- 避免過度擴充套件執行緒。我們通常在處理大量短時任務時,使用快取的執行緒池,比如在最新的 HTTP/2 client API 中,目前的預設實現就是如此。我們在建立執行緒池的時候,並不能準確預計任務壓力有多大、資料特徵是什麼樣子(大部分請求是 1K 、100K 還是 1M 以上?),所以很難明確設定一個執行緒數目。
- 另外,如果執行緒數目不斷增長(可以使用 jstack 等工具檢查),也需要警惕另外一種可能性,就是執行緒洩漏,這種情況往往是因為任務邏輯有問題,導致工作執行緒遲遲不能被釋放。建議你排查下執行緒棧,很有可能多個執行緒都是卡在近似的程式碼處。
- 避免死鎖等同步問題,對於死鎖的場景和排查,你可以複習專欄第 18 講。
- 儘量避免在使用執行緒池時操作 ThreadLocal,同樣是專欄第 17 講已經分析過的,通過今天的執行緒池學習,應該更能理解其原因,工作執行緒的生命週期通常都會超過任務的生命週期。
執行緒池大小的選擇策略
上面我已經介紹過,執行緒池大小不合適,太多會太少,都會導致麻煩,所以我們需要去考慮一個合適的執行緒池大小。雖然不能完全確定,但是有一些相對普適的規則和思路。
- 如果我們的任務主要是進行計算,那麼就意味著 CPU 的處理能力是稀缺的資源,我們能夠通過大量增加執行緒數提高計算能力嗎?往往是不能的,如果執行緒太多,反倒可能導致大量的上下文切換開銷。所以,這種情況下,通常建議按照 CPU 核的數目 N 或者 N+1。
- 如果是需要較多等待的任務,例如 I/O 操作比較多,可以參考 Brain Goetz 推薦的計算方法:
執行緒數 = CPU 核數 × (1 + 平均等待時間 / 平均工作時間)這些時間並不能精準預計,需要根據取樣或者概要分析等方式進行計算,然後在實際中驗證和調整。
- 上面是僅僅考慮了 CPU 等限制,實際還可能受各種系統資源限制影響,例如我最近就在 Mac OS X 上遇到了大負載時ephemeral 埠受限的情況。當然,我是通過擴大可用埠範圍解決的,如果我們不能調整資源的容量,那麼就只能限制工作執行緒的數目了。這裡的資源可以是檔案控制代碼、記憶體等。
另外,在實際工作中,不要把解決問題的思路全部指望到調整執行緒池上,很多時候架構上的改變更能解決問題,比如利用背壓機制的Reactive Stream、合理的拆分等。
今天,我從 Java 建立的幾種執行緒池開始,對 Executor 框架的主要組成、執行緒池結構與生命週期等方面進行了講解和分析,希望對你有所幫助。
一課一練
關於今天我們討論的題目你做到心中有數了嗎?今天的思考題是從邏輯上理解,執行緒池建立和生命週期。請談一談,如果利用 newSingleThreadExecutor() 建立一個執行緒池,corePoolSize、maxPoolSize 等都是什麼數值?ThreadFactory 可能線上程池生命週期中被使用多少次?怎麼驗證自己的判斷?