Coursea吳恩達《結構化機器學習專案》課程筆記(1)機器學習策略上篇
阿新 • • 發佈:2019-01-14
轉載自http://blog.csdn.net/column/details/17767.html
結構化機器學習專案 — 機器學習策略(1)
1. 正交化
表示在機器學習模型建立的整個流程中,我們需要根據不同部分反映的問題,去做相應的調整,從而更加容易地判斷出是在哪一個部分出現了問題,並做相應的解決措施。
正交化或正交性是一種系統設計屬性,其確保修改演算法的指令或部分不會對系統的其他部分產生或傳播副作用。 相互獨立地驗證使得演算法變得更簡單,減少了測試和開發的時間。
當在監督學習模型中,以下的4個假設需要真實且是相互正交的:
- 系統在訓練集上表現的好
- 否則,使用更大的神經網路、更好的優化演算法
- 否則,使用更大的神經網路
- 系統在開發集上表現的好
- 否則,使用正則化、更大的訓練集
- 系統在測試集上表現的好
- 否則,使用更大的開發集
- 在真實的系統環境中表現的好
- 否則,修改開發測試集、修改代價函式
2. 單一數字評估指標
在訓練機器學習模型的時候,無論是調整超引數,還是嘗試更好的優化演算法,為問題設定一個單一數字評估指標,可以更好更快的評估模型。
example1
下面是分別訓練的兩個分類器的Precision、Recall以及F1 score。

由上表可以看出,以Precision為指標,則分類器A的分類效果好;以Recall
這裡以Precision和Recall為基礎,構成一個綜合指標F1 Score,那麼我們利用F1 Score便可以更容易的評判出分類器A的效果更好。
指標介紹:
在二分類問題中,通過預測我們得到下面的真實值
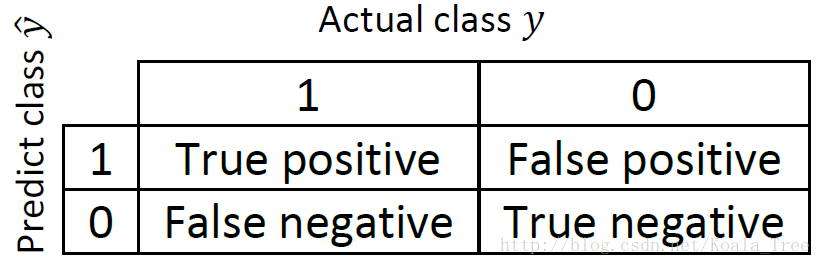
- Precision(查準率):
Precision=TruepositiveNumberofpredictedpositive×100%=TruepositiveTruepositive+Falsepositive
假設在是否為貓的分類問題中,查準率代表:所有模型預測為貓的圖片中,確實為貓的概率。 - Recall(查全率):
Recall=TruepositiveNumberofactuallypositive×100%=TruepositiveTruepositive+Falsepositive
假設在是否為貓的分類問題中,查全率代表:真實為貓的圖片中,預測正確的概率。 - F1 Score:
F1−Socre=21p+1r
相當與查準率和查全率的一個特別形式的平均指標。
example2
下面是另外一個問題多種分類器在不同的國家中的分類錯誤率結果: