
深度學習Deeplearning4j 入門實戰(5):基於多層感知機的Mnist壓縮以及在Spark實現
在上一篇部落格中,我們用基於RBM的的Deep AutoEncoder對Mnist資料集進行壓縮,應該說取得了不錯的效果。這裡,我們將神經網路這塊替換成傳統的全連線的前饋神經網路對Mnist資料集進行壓縮,看看兩者的效果有什麼異同。整個程式碼依然是利用Deeplearning4j進行實現,並且為了方便以後的擴充套件,我們將其與Spark平臺結合。下面,就具體來說一下模型的結構、訓練過程以及最終的壓縮效果。
首先,我們新建Maven工程並加入Deeplearning4j的相關依賴(這一塊內容在之前的文章中多次提及,因此這裡就不再囉嗦了)。接下來,我們新建Spark任務,讀取已經存放在HDFS上的Mnist資料集(和之前文章中提到的一樣,Mnist資料集已經事先以JavaRDD<DataSet>的形式儲存在HDFS上,具體操作可以參考之前的部落格。),並生成訓練資料集JavaRDD。具體程式碼如下:
- SparkConf conf = new SparkConf()
- .set("spark.kryo.registrator", "org.nd4j.Nd4jRegistrator")
- .setAppName("MLP AutoEncoder Mnist(Java)");
- JavaSparkContext jsc = new JavaSparkContext(conf);
- //
- final String inputPath = args[0];
-
final String savePath = args[1];
- double lr = Double.parseDouble(args[2]);
- finalint batchSize = Integer.parseInt(args[3]);
- finalint numEpoch = Integer.parseInt(args[4]);
- //
- JavaRDD<DataSet> javaRDDMnist = jsc.objectFile(inputPath);//read mnist data from HDFS
-
JavaRDD<DataSet> javaRDDTrain = javaRDDMnist.map(new Function<DataSet, DataSet>() {
- @Override
- public DataSet call(DataSet next) throws Exception {
- returnnew DataSet(next.getFeatureMatrix(),next.getFeatureMatrix());
- }
- });
構築完訓練資料集之後,我們就可以定義網路結構並配以相應的超引數:
- MultiLayerConfiguration netconf = new NeuralNetConfiguration.Builder()
- .seed(123)
- .iterations(1)
- .learningRate(lr)
- .learningRateScoreBasedDecayRate(0.5)
- .optimizationAlgo(OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT)
- .updater(Updater.ADAM).adamMeanDecay(0.9).adamVarDecay(0.999)
- .list()
- .layer(0, new DenseLayer.Builder().nIn(784).nOut(1000).activation("relu").build())
- .layer(1, new DenseLayer.Builder().nIn(1000).nOut(500).activation("relu").build())
- .layer(2, new DenseLayer.Builder().nIn(500).nOut(250).activation("relu").build())
- .layer(3, new DenseLayer.Builder().nIn(250).nOut(500).activation("relu").build())
- .layer(4, new DenseLayer.Builder().nIn(500).nOut(1000).activation("relu").build())
- .layer(5, new OutputLayer.Builder(LossFunctions.LossFunction.MSE)
- .nIn(1000)
- .nOut(784)
- .activation("relu")
- .build())
- .backprop(true).pretrain(false)
- .build();
- ParameterAveragingTrainingMaster trainMaster = new ParameterAveragingTrainingMaster.Builder(batchSize)
- .workerPrefetchNumBatches(0)
- .saveUpdater(true)
- .averagingFrequency(5)
- .batchSizePerWorker(batchSize)
- .build();
- MultiLayerNetwork net = new MultiLayerNetwork(netconf);
- net.init();
- SparkDl4jMultiLayer sparkNetwork = new SparkDl4jMultiLayer(jsc, net, trainMaster);
- sparkNetwork.setListeners(Collections.<IterationListener>singletonList(new ScoreIterationListener(1)));
那麼,接下來就是訓練的程式碼:
- for( int i = 0; i < numEpoch; ++i ){
- sparkNetwork.fit(javaRDDTrain); //train modek
- System.out.println("----- Epoch " + i + " complete -----");
- MultiLayerNetwork trainnet = sparkNetwork.getNetwork();
- System.out.println("Epoch " + i + " Score: " + sparkNetwork.getScore());
- List<DataSet> listDS = javaRDDTrain.takeSample(false, 50);
- for( DataSet ds : listDS ){
- INDArray testFeature = ds.getFeatureMatrix();
- INDArray testRes = trainnet.output(testFeature);
- System.out.println("Euclidean Distance: " + testRes.distance2(testFeature));
- }
- DataSet first = listDS.get(0);
- INDArray testFeature = first.getFeatureMatrix();
- double[] doubleFeature = testFeature.data().asDouble();
- INDArray testRes = trainnet.output(testFeature);
- double[] doubleRes = testRes.data().asDouble();
- for( int j = 0; j < doubleFeature.length && j < doubleRes.length; ++j ){
- double f = doubleFeature[j]; double t = doubleRes[j];
- System.out.print(f + ":" + t + " ");
- }
- System.out.println();
- }
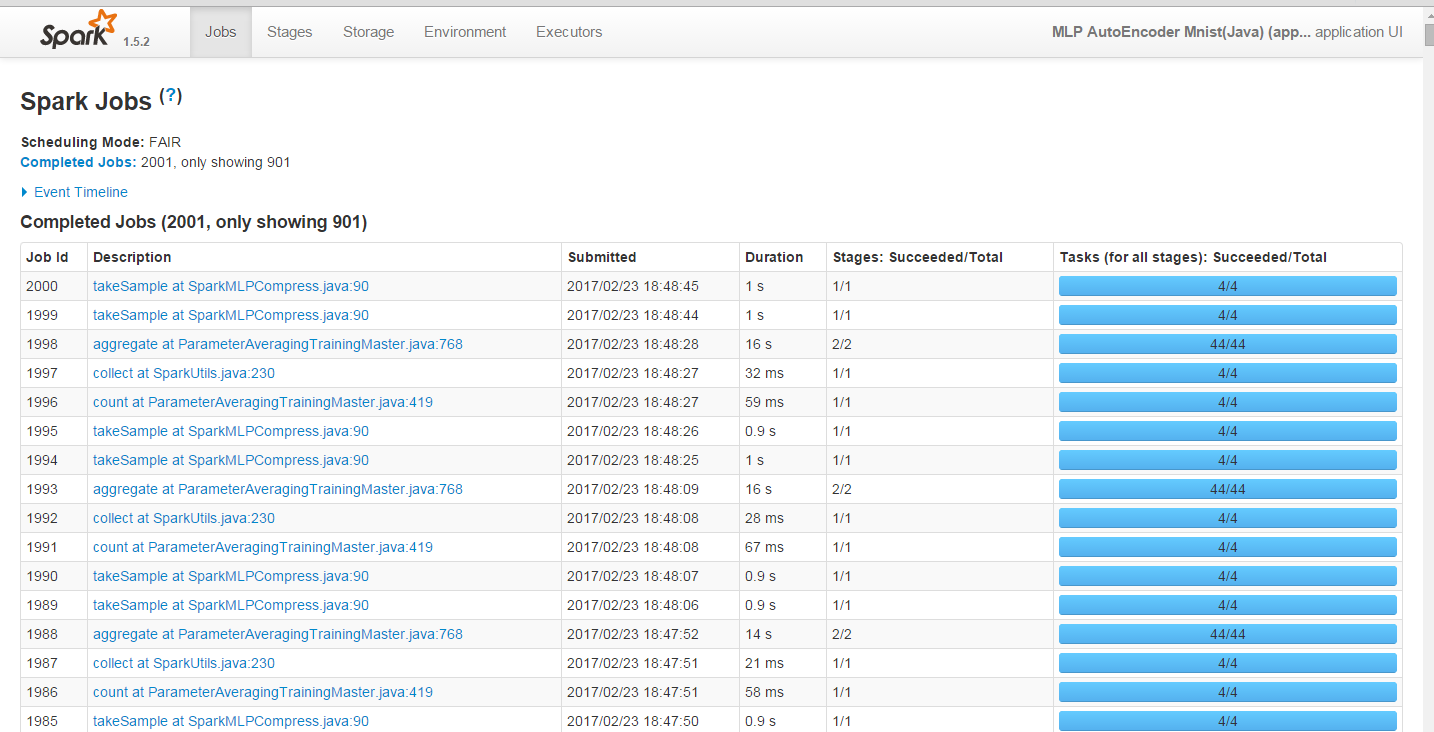
完整的訓練過程,Spark任務截圖:
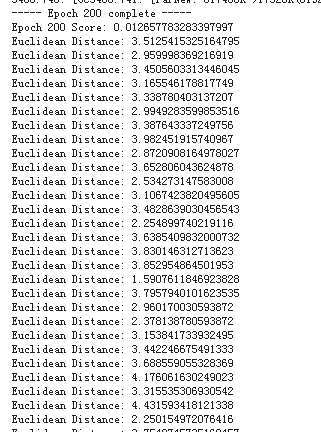
隨機抽取的資料的比較:
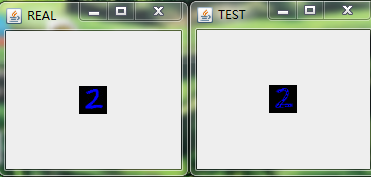
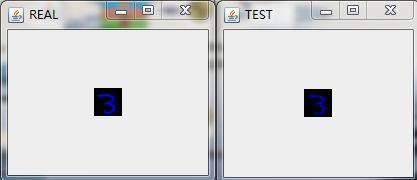
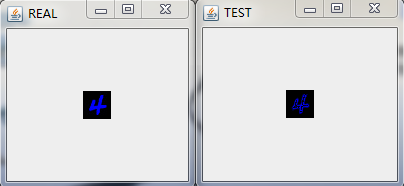
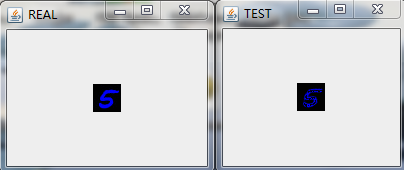
在經過多輪次的訓練後,我們將模型儲存在HDFS上(具體的程式碼實現可以參考之前的部落格)並且將其拉到本地後,隨機預測/重構一些圖片來看看效果,具體的,我隨機選擇了9張圖進行重構,如下圖:
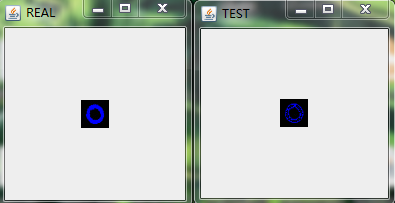
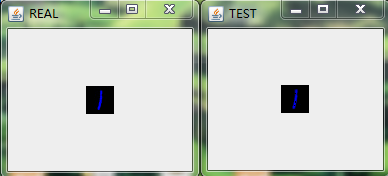
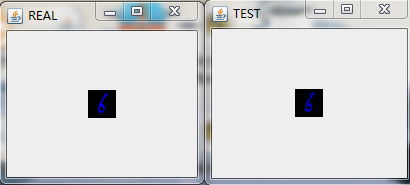
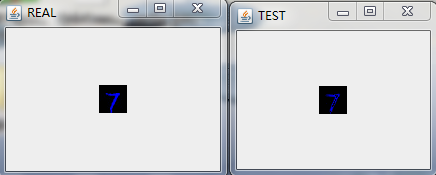
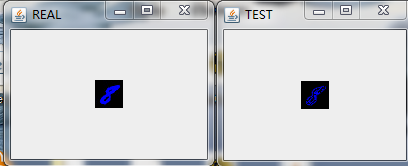
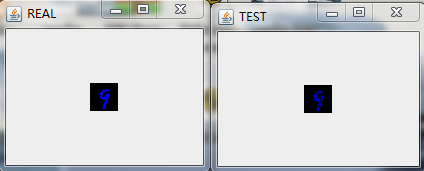
最後做下小結。
這裡我們用多層感知機來對Mnsit資料集進行壓縮,並且也取得不錯的壓縮效果。和之前利用Deep AutoEncoder進行資料進行壓縮的不同在於我們將每一層中RBM替換成了FNN。應當說,從肉眼的角度我們沒法分辨兩種網路對Mnist資料集壓縮的好壞程度,但是從理論上,基於RBM的壓縮網路應該會取得更好的效果,在Hinton教授的論文中,也拿兩者做了比較,結論也是基於RBM的Deep AutoEncoder效果更好,實際中,兩者都會應用到。所以還得還情況而定!