
大資料Hadoop叢集環境搭建(二)
第一部分 Linux環境安裝
一、Vmware網路模式介紹
參考:http://blog.csdn.net/collection4u/article/details/14127671
二、Linux環境VMware14與CenterOs7安裝版本
參考:https://blog.csdn.net/wth_97/article/details/81870587
三、Linux環境搭建VMware12與CenterOs6.9安裝
1.準備過程

2.
—>下一步即可。
3.新建虛擬機器
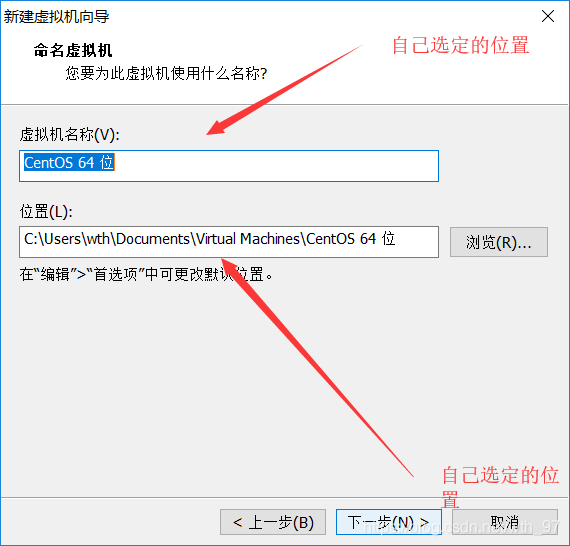
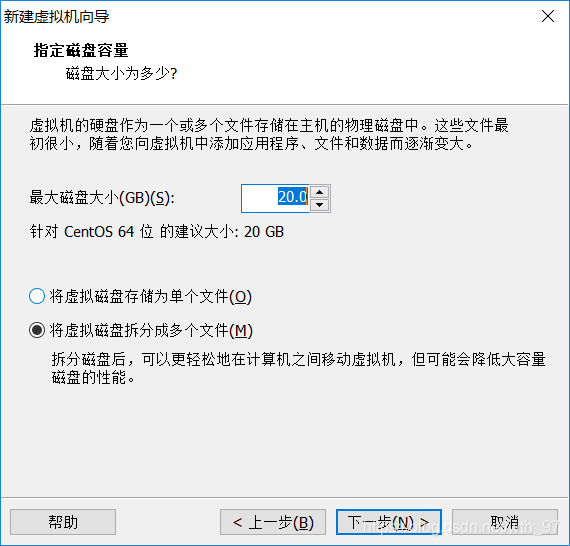
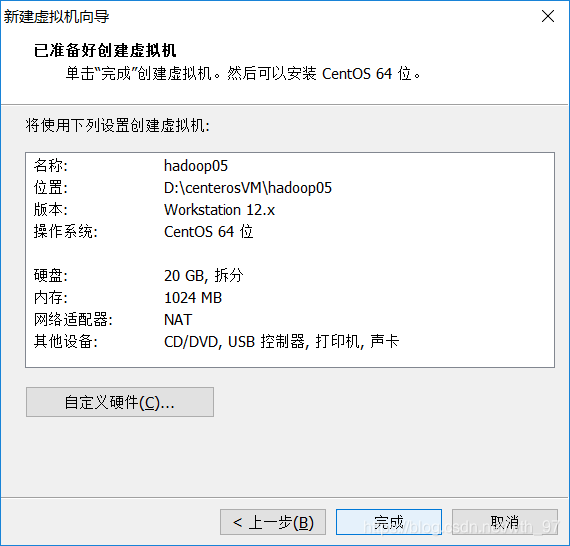
—>開啟虛擬機器
—>選擇第一個---->選擇skip–>選擇忽略資料—>選擇寫入—>主機名更改密碼設定
4.使用虛擬機器出現沒有IP問題
參考:https://blog.csdn.net/wth_97/article/details/85265692
如果使用14版本網路中沒有顯示可以安裝12版本嘗試一下
相關推薦
大資料Hadoop叢集環境搭建(二)
第一部分 Linux環境安裝 一、Vmware網路模式介紹 參考:http://blog.csdn.net/collection4u/article/details/14127671 二、Linux環境VMware14與CenterOs7安裝版本 參考:https://blo
大資料Hadoop叢集環境搭建(五)
Hadoop環境搭建Hadoop本地模式安裝 Hadoop部署模式 Hadoop部署模式有:本地模式、偽分佈模式、完全分散式模式。 區分的依據是NameNode、DataNode、ResourceManager、NodeManager等模組執行在幾個JVM程序、幾個機器。 一、本地模
大資料Hadoop叢集環境搭建(四)
安裝JDK 安裝Java JDK 1、 檢視是否已經安裝了java JDK。 [[email protected] Desktop]# java –version 注意:Hadoop機器上的JDK,最好是Oracle的Java JDK,不然會有一些問題,比如可能沒
大資料Hadoop叢集環境搭建(三)
在配置hadoop環境中 一、修改Hostname 1. 臨時修改hostname [[email protected] localhost]# hostname hadoop 這種修改方式,系統重啟後就會失效。 2、 永久修改hostname 想永久修改,應
大資料Hadoop叢集環境搭建(一)
前言 Hadoop在大資料技術體系中的地位至關重要,Hadoop是大資料技術的基礎,對Hadoop基礎知識的掌握的紮實程度,會決定在大資料技術道路上走多遠。 這是一篇入門文章,Hadoop的學習方法很多,網上也有很多學習路線圖。本文的思路是:以安裝部署Apache Hadoop2.x
Hadoop叢集化搭建(二)配置JAVA環境
軟體環境 作業系統 CentOS 6.4 64bit (Basic Server + 桌面環境) 虛擬機器 VMware Workstation 12.0
基於Hadoop生態圈的資料倉庫實踐 —— 環境搭建(二)
二、安裝Hadoop及其所需的服務 1. CDH安裝概述 CDH的全稱是Cloudera's Distribution Including Apache Hadoop,是Cloudera公司的Hadoop分發版本。有三種方式安裝CDH: . Path A - 通過Cloud
python下建立elasticsearch索引實現大資料搜尋——之環境搭建(一)
目錄 1.需求闡述 1)資料儲存在阿里雲內網的Mysql伺服器上,需要通過一臺伺服器SSH隧道穿透取得資料。 2)首先明確,一張設計圖需要多種素材來構成。資料量很大,需要操作的有兩個表,稱為stylepatternshow表,目前資料3w行(
Hadoop分散式環境搭建(二)
Hadoop偽分散式環境搭建(二) 安裝Hadoop 1. 下載hadoop壓縮包 2. 解壓 cd /usr/local sudo tar -vxzf hadoop-2.
hadoop spark 大資料叢集環境搭建(一)
大資料雲端計算現在比較熱門,未來的一個發展方向,在此分享下技術,有不對的地方歡迎指出 1、軟體環境(會分享到網盤) centos6.5 jdk1.7 hadoop2.4.1(這裡只用到hdfs,namenode不走ha) zookeeper3.4.5 spark1.3.0
Hadoop HA + HBase環境搭建(二)————HBase環境搭建
property hadoop zookeeper conf ado 文件 ice mes root HBase配置(只需要做一處修改) 修改HBase的 hbase-site.xml 配置文件種的一項 <property>
Hadoop叢集環境搭建(雲伺服器,虛擬機器都適用)
為了配置方便,為每臺電腦配置一個主機名: vim /etc/hostname 各個節點中,主節點寫入:master , 其他從節點寫入:slavexx 如果這樣修改不能生效,則繼續如下操作 vim /etc/cloud/cloud.cfg 做preserve_hostname: true 修改 reb
大資料hadoop叢集的搭建總結及步驟
CentOS6.5mini版hadoop叢集搭建流程 CentOS 7 系列: 關閉防火牆:systemctl stop firewalld 禁止防火牆開機啟動:systemctl disable firewalld 安裝
基於Hadoop生態圈的資料倉庫實踐 —— 環境搭建(三)
三、建立資料倉庫示例模型 Hadoop及其相關服務安裝配置好後,下面用一個小而完整的示例說明多維模型及其相關ETL技術在Hadoop上的具體實現。1. 設計ERD 操作型系統是一個銷售訂單系統,初始時只有產品、客戶、訂單三個表,ERD如下圖所示。
大資料Hadoop測試環境搭建(CM、CDH5離線安裝)
伺服器可用虛擬機器,記憶體8G,硬碟50G至少3臺伺服器,namenode1臺,datanode2臺主伺服器裝好cm後,scp到另2臺伺服器手動啟動cloudera-scm-server和cloudera-scm-agent,service容易出各種問題有服務要用到apache到httpd,需要安裝副本不足問
Hadoop+Flume+Kafka+Zookeeper叢集環境搭建(一)
Hadoop+Flume+Kafka+Zookeeper叢集環境搭建 1.部署基礎條件 1.1 硬體條件 IP hostname 192.168.100.103 mater 192.168.100.104 flumekafka1 192.168.1
Spring Data 開發環境搭建(二)
是不是 lns utf-8 void ext for 實體類 connect domain 首先咱們先創建一個maven工程 在pom.xml加入以下 依賴 <!--Mysql 驅動包--> <dependency> <
Appium python自動化測試系列之appium環境搭建(二)
ftp 自動化 手動 文件 搭建環境 做到 安裝python reg 成員 ?2.1 基礎環境搭建 當我們學習新的一項技術開始基本都是從環境搭建開始,本書除了第一章節也是的,如果你連最基礎的環境都沒有那麽我們也沒必要去說太多,大概介紹一下: 1、因為appium是支持and
一起寫框架-MVC框架-基礎功能-環境搭建(二)
utils src 編寫 con eclipse開發 aaa res text web測試 實現功能 搭建Eclipse開發環境 1.了解Eclipse工具普通項目是怎樣關聯依賴項目的 2.了解Eclipse工具WEB項目是怎樣關聯依賴項目的 實現步驟 1. 創建一個Jav
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。
centos 失敗 sco pan html top n 而且 div href Centos7出現異常:Failed to start LSB: Bring up/down networking. 按照《Kafka:ZK+Kafka+Spark Streaming集群環