
利用Numpy的svd函式實現的PCA為什麼是對協方差矩陣進行SVD分解
眾所周知,PCA是資料分析中經常用到的一種方法,主要用途是對高維資料進行降維,有兩大目的:去相關和去冗餘。
其大致的原理是通過對資料協方差矩陣進行特徵分解找到使資料各維度方差最大的主成分,並將原資料投影到各主成分上達到去相關的目的,若在投影到各主成分時,僅選取特徵值最大的前若干個主成分,則可同時實現去冗餘的目的。
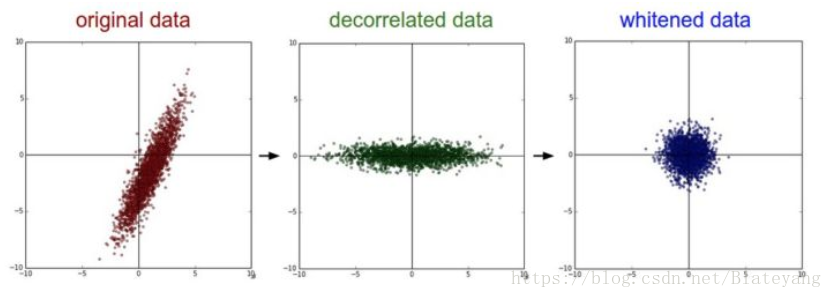
上圖的decorrelate data就是對原資料進行PCA去相關後的效果,其中x方向是第一主成分,y方向是第二主成分。
PCA的主要演算法如下:
- 組織資料形式,以便於模型使用;
- 計算樣本每個特徵的平均值;
- 每個樣本資料減去該特徵的平均值(歸一化處理);
- 求協方差矩陣;
- 找到協方差矩陣的特徵值和特徵向量;
- 對特徵值和特徵向量重新排列(特徵值從大到小排列);
- 對特徵值求取累計貢獻率或指定選取前若干個特徵向量(跳過8);
- 對累計貢獻率按照某個特定比例選取特徵向量集的子集合;
- 對原始資料(第三步後)進行轉換。
關於PCA的原理和推導網上有很多資料,比如主成分分析(PCA)原理詳解,博主在此想要討論的主要有兩點:
1. 為什麼PCA選擇處理的物件是協方差矩陣?
2. 為什麼用numpy的svd函式實現PCA要對協方差矩陣進行SVD分解?
對於第一個問題,即為什麼PCA選擇處理的物件是協方差矩陣?
引用部落格
降維的目的就是“降噪”和“去冗餘”。“降噪”的目的就是使保留下來的維度間的相關性儘可能小,而“去冗餘”的目的就是使保留下來的維度含有的“能量”即方差儘可能大。那首先的首先,我們得需要知道各維度間的相關性以及個維度上的方差啊!那有什麼資料結構能同時表現不同維度間的相關性以及各個維度上的方差呢?自然是協方差矩陣!
協方差矩陣度量的是維度與維度之間的關係,而非樣本與樣本之間。協方差矩陣的主對角線上的元素是各個維度上的方差(即能量),其他元素是兩兩維度間的協方差(即相關性)。我們要的東西協方差矩陣都有了。
對於第二個問題,為什麼用numpy的svd函式實現PCA要對協方差矩陣進行SVD分解?
其實實現PCA有多種方法,博主找到的至少有三種:
1. 直接對原資料矩陣進行SVD分解(sklearn中用的是這一種)
2. 基於協方差矩陣進行特徵分解(上面的演算法描述的就是這一種)
3. 基於協方差矩陣進行SVD分解(本問題指的是這一種)
前兩種實現方法比較容易理解,博主認為它們實際也是等價的,因為線性代數中對矩陣X進行SVD的分解過程其實就用到了對協方差矩陣
而第三種實現方法,就有些費解,明明對協方差矩陣用特徵分解就可以了,為什麼又可以用SVD分解。搜了一通資料後才知道SVD分解也是可以用來做特徵分解的,而且它比特徵分解的適用範圍更廣,特徵分解只能用於方陣,而SVD分解可用於任意m*n形狀的矩陣。另外,如果我們通過特徵值分解協方差矩陣,那麼我們只能得到一個方向的PCA降維。這個方向就是對資料矩陣X從行-對 進行特徵分解的情況(或列-對 進行特徵分解的情況)方向上壓縮降維。而用SVD對協方差矩陣進行特徵分解,可以得到兩個方向上的PCA降維(即行和列方向,只要用SVD分解得到的U或V分別去和X相乘即可,注意維度匹配)
下面附上以上三種實現的python程式碼
import numpy as np
from sklearn.decomposition import PCA
import sys
#returns choosing how many main factors
def index_lst(lst, component=0, rate=0):
#component: numbers of main factors
#rate: rate of sum(main factors)/sum(all factors)
#rate range suggest: (0.8,1)
#if you choose rate parameter, return index = 0 or less than len(lst)
if component and rate:
print('Component and rate must choose only one!')
sys.exit(0)
if not component and not rate:
print('Invalid parameter for numbers of components!')
sys.exit(0)
elif component:
print('Choosing by component, components are %s......'%component)
return component
else:
print('Choosing by rate, rate is %s ......'%rate)
for i in range(1, len(lst)):
if sum(lst[:i])/sum(lst) >= rate:
return i
return 0
def main():
# test data
mat = [[-1,-1,0,2,1],[2,0,0,-1,-1],[2,0,1,1,0]]
# simple transform of test data
Mat = np.array(mat, dtype='float64')
print('Before PCA transforMation, data is:\n', Mat)
print('\nMethod 1: PCA by original algorithm:')
p,n = np.shape(Mat) # shape of Mat
t = np.mean(Mat, 0) # mean of each column
# substract the mean of each column
for i in range(p):
for j in range(n):
Mat[i,j] = float(Mat[i,j]-t[j])
# covariance Matrix
cov_Mat = np.dot(Mat.T, Mat)/(p-1)
# PCA by original algorithm
# eigvalues and eigenvectors of covariance Matrix with eigvalues descending
U,V = np.linalg.eigh(cov_Mat)
# Rearrange the eigenvectors and eigenvalues
U = U[::-1]
for i in range(n):
V[i,:] = V[i,:][::-1]
# choose eigenvalue by component or rate, not both of them euqal to 0
Index = index_lst(U, component=2) # choose how many main factors
if Index:
v = V[:,:Index] # subset of Unitary matrix
else: # improper rate choice may return Index=0
print('Invalid rate choice.\nPlease adjust the rate.')
print('Rate distribute follows:')
print([sum(U[:i])/sum(U) for i in range(1, len(U)+1)])
sys.exit(0)
# data transformation
T1 = np.dot(Mat, v)
# print the transformed data
print('We choose %d main factors.'%Index)
print('After PCA transformation, data becomes:\n',T1)
# PCA by original algorithm using SVD
print('\nMethod 2: PCA by original algorithm using SVD:')
# u: Unitary matrix, eigenvectors in columns
# d: list of the singular values, sorted in descending order
u,d,v = np.linalg.svd(cov_Mat)
Index = index_lst(d, rate=0.95) # choose how many main factors
T2 = np.dot(Mat, u[:,:Index]) # transformed data
print('We choose %d main factors.'%Index)
print('After PCA transformation, data becomes:\n',T2)
# PCA by Scikit-learn
pca = PCA(n_components=2) # n_components can be integer or float in (0,1)
pca.fit(mat) # fit the model
print('\nMethod 3: PCA by Scikit-learn:')
print('After PCA transformation, data becomes:')
print(pca.fit_transform(mat)) # transformed data
main()參考資料:
1. 三種方法實現PCA演算法(Python)
2. 主成分分析(PCA)原理詳解
3. PCA為什麼要用協方差矩陣
4. 機器學習中的數學(5)-強大的矩陣奇異值分解(SVD)及其應用