
Lucene原理與程式碼分析解讀筆記
Lucene是一個基於Java的高效的全文檢索庫。
那麼什麼是全文檢索,為什麼需要全文檢索?
目前人們生活中出現的資料總的來說分為兩類:結構化資料和非結構化資料。很容易理解,結構化資料是有固定格式和結構的或者有限長度的資料,比如資料庫,元資料等。非結構化資料則是不定長或者沒有固定格式的資料,如圖片,郵件,文件等。還有一種較少的分類為半結構化資料,如XML,HTML等,在一定程度上我們可以將其按照結構化資料來處理,也可以抽取純文字按照非結構化資料來處理。
非結構化資料又稱為全文資料。,對其搜尋主要有兩種方式:
1) 順序掃描法(SerialScanning):顧名思義,要找內容包含某一個字串的文件,就挨著文件一個個找,對照每一個文件從頭到尾,一直掃描,指導掃描完所有的文件。類似於Windows中搜索檔案的功能。
2) 第二種則為索引。就是從非結構化資料中提取出資訊重新組織,使其變得有一定的組織,從而提高檢索效率。比如我們的電話簿,從電話簿中查詢聯絡人,我們根據首字母拼音可以索引定位到某一個聯絡人。
先建立索引在對索引進行搜尋的過程就叫做全文檢索(Full-text Search)。下圖為全文檢索的一般過程,也是Lucene檢索的過程。
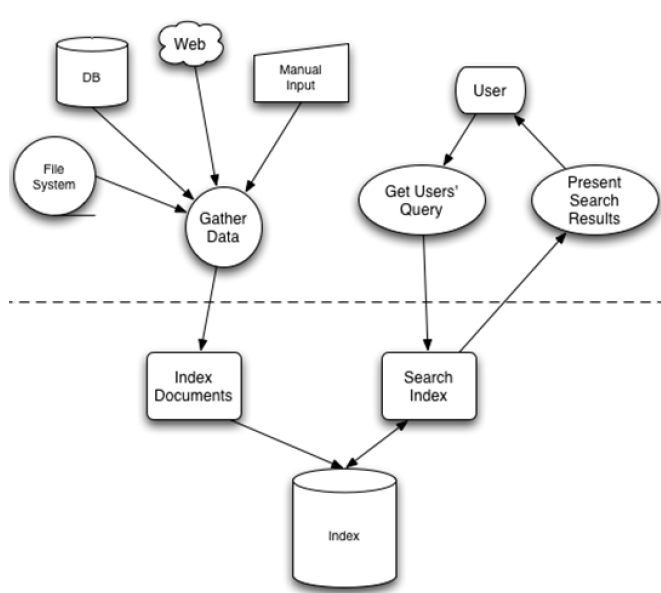
全文檢索主要分為兩個過程,索引建立和搜尋索引。
索引建立:將顯示中所有結構化和非結構化的資料提取資訊,建立索引的過程。
搜尋索引:就是得到使用者的查詢請求,搜尋建立的索引,然後返回結果的過程。
這裡引出全文檢索的三個問題:
1.索引中儲存了怎樣的資料
順序掃描速度慢的原因是由於使用者想要搜尋的資訊和非結構化資料中所儲存的資訊不一致。索引儲存從字串到檔案的對映,則會大大提高搜尋速度。從字串到檔案的對映是從檔案到字串對映的反向過程,因此儲存這種資訊的索引稱為反向索引。

左邊儲存稱為詞典的一系列字串,右邊每個字串指向包含自己的文件連結串列(倒排表,Posting List)。索引使得儲存的資訊與要搜尋的資訊一致,因而提高搜尋的速度。
對於大量資料來說,建立索引確實是一個耗時的過程,但是相比於順序掃描,建立索引只需要一次之後每次搜尋不需要再建立索引,而順序掃描是每一次都需要重新掃描。
2.如何建立索引
全文檢索建立索引有以下幾步:
1) 一些要索引的原文件(Document)
2) 將原文件傳給分片語件(Tokenizer)
分片語件主要做的事情是將文件分成一個一個單獨的單詞,去掉標點符號和停詞(句子中最普通的出現頻率最高的一些詞,沒有實際和特別的意義,比如冠詞the, a, an等)
3) 將得到的詞元(Token)傳給語言處理元件(LinguisticProcessor)
語言處理元件主要是對得到的詞元做一些處理:大寫變為小寫,將單詞縮寫成詞根形式(Stemming)和將單詞換邊為詞根形式(Lemmatization)
Stemming 和lemmatization的異同:
相同之處:Stemming 和lemmatization 都要使詞彙成為詞根形式。
兩者的方式不同:
Stemming 採用的是“縮減”的方式:“cars”到“car”,“driving”到“drive”。
Lemmatization 採用的是“轉變”的方式:“drove”到“drove”,“driving”到“drive”。
兩者的演算法不同:
Stemming 主要是採取某種固定的演算法來做這種縮減,如去除“s”,去除“ing”加“e”,
將“ational”變為“ate”,將“tional”變為“tion”。
Lemmatization 主要是採用儲存某種字典的方式做這種轉變。比如字典中有“driving”
到“drive”,“drove”到“drive”,“am, is,are”到“be”的對映,做轉變時,只要查字典就可以了。
Stemming 和lemmatization不是互斥關係,是有交集的,有的詞利用這兩種方式都能達到相同的轉換。
詞元轉換之後的詞,我們稱之為詞(Term)。
4) 將得到的詞(Term)傳給索引元件(Indexer)
索引元件主要做:
A. 將得到的詞(Term)建立一個字典;
B. 對字典按照字母順序進行排序;
C. 合併相同的詞(Term)成為文件倒排(PostingList)連結串列,在該表中需要注意兩個定義:一個是Document Frequency,文件頻次,表示總共有多少檔案包含該詞,另一個是Frequency詞頻,表示此檔案中包含了幾個該詞
3.如何搜尋索引
我們搜尋到的結果往往不是隻有幾個,也往往不一定就是我們想要找的那幾個,也可能返回成百上千上萬個檔案我們無法一眼就找到我們需要的文件。因此,我們需要在搜尋結果中找到和查詢語句最相關的文件才行。
因此搜尋分為以下幾步:
1) 使用者輸入查詢語句
查詢語句也是由語法的,基本的包含AND,OR,NOT等。例如:使用者輸入lucene AND learned NOT hadoop,則表示使用者想要尋找一個包含lucene和learned但是不包含hadoop的文件。
2) 對查詢語句進行詞法分析,語法分析和語言處理
詞法分析就是發現不合法的關鍵字會出現錯誤。比如關鍵字NOT拼寫錯誤的話就會被當作普通單詞參與查詢
語法分析主要是根據查詢語句的語法規則來形成一棵語法樹

語言處理的過程與索引過程中的語言處理幾乎相同,learned變為learn

3) 搜尋索引,得到符合語法樹的文件
該步驟有幾步:
A. 在反向索引表中,分別找出包含lucene,learn,hadoop的文件連結串列
B. 對包含lucene和learn的連結串列進行AND操作,得到一個包含兩個詞的文件連結串列
C. 將此連結串列與hadoop的文件連結串列進行差操作,去除包含hadoop的文件,得到的文件連結串列就是我們需要的文件
4) 根據得到的文件和查詢語句的相關性,對結果進行排序
需要對文件與文件之間的相關性進行打分,分數高的相關性好,應該排在前面。那麼如何判斷文件之間的關係呢?一個文件由許多片語成,對於不同的文件,不同的term重要性不同。因此,判斷文件之間的關係,首先找出哪些詞對於文件之間的關係最重要,然後判斷這些詞之間的關係,也就是計算詞的權重。計算詞的權重有兩個引數,第一個是詞(Term),第二個是文件(Document)。詞的權重(Term weight)表示此詞(Term)在此文件中的重要程度,越重要的詞(Term)有越大的權重(Term weight),因而在計算文件之間的相關性中將發揮更大的作用。判斷詞(Term)之間的關係從而得到文件相關性的過程應用一種叫做向量空間模型的演算法(Vector
Space Model)。計算權重的過程中,影響一個詞的重要性主要由Term Frequency (tf)(即此Term 在此文件中出現了多少次。tf 越大說明越重要。)和Document Frequency (df)(即有多少文件包含次Term。df 越大說明越不重要。)影響。然使用向量空間模型的演算法來判斷Term之間的關係從而得到文件相關性。
總結一下,建立索引和搜尋索引的過程如下圖:
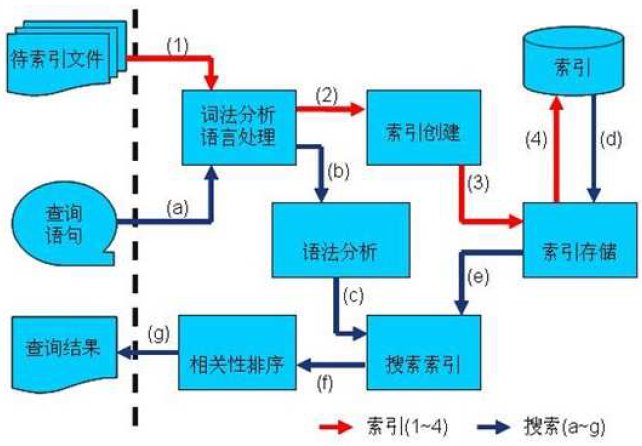
1. 索引過程:
1) 有一系列被索引檔案
2) 被索引檔案經過語法分析和語言處理形成一系列詞(Term)。
3) 經過索引建立形成詞典和反向索引表。
4) 通過索引儲存將索引寫入硬碟。
2. 搜尋過程:
a) 使用者輸入查詢語句。
b) 對查詢語句經過語法分析和語言分析得到一系列詞(Term)。
c) 通過語法分析得到一個查詢樹。
d) 通過索引儲存將索引讀入到記憶體。
e) 利用查詢樹搜尋索引,從而得到每個詞(Term)的文件連結串列,對文件連結串列進行交,差,並得到結果文件。
f) 將搜尋到的結果文件對查詢的相關性進行排序。
g) 返回查詢結果給使用者。
關於資訊檢索的相關理論差不多就是這些。
Lucene是對以上這種理論的一種基本實踐,是一個高效的可擴充套件的全文檢索庫,全部用java實現,無需配置,但是僅僅支援純文字檔案的索引的搜尋,不負責由其他格式的檔案抽取純文字檔案,或者從網路中抓取檔案的過程。
Lucene的構架如下圖所示:

從圖中而已看出,Lucene有索引和搜尋兩個過程,包含索引建立,索引,搜尋三個要點。
索引的元件:

被索引的文件用Document物件表示。
l IndexWriter通過函式addDocument將文件新增到索引中,實現建立索引的過程。
l Lucene的索引是應用反向索引。
l 當用戶有請求時,Query代表使用者的查詢語句。
l IndexSearcher通過函式search搜尋Lucene Index。
l IndexSearcher計算term weight和score並且將結果返回給使用者。
l 返回給使用者的文件集合用TopDocsCollector表示。
索引過程:
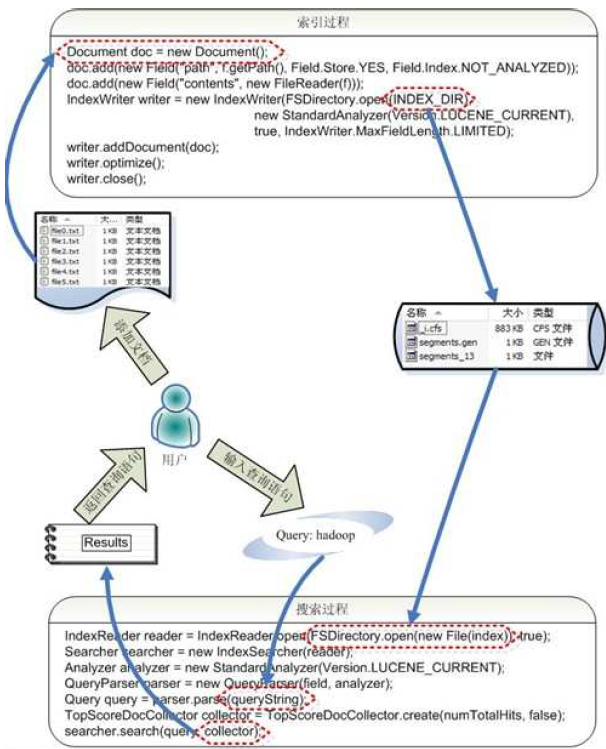
l 建立一個IndexWriter用來寫索引檔案,它有幾個引數,INDEX_DIR 就是索引檔案所存放的位置,Analyzer 便是用來對文件進行詞法分析和語言處理的。
l 建立一個Document 代表我們要索引的文件。
l 將不同的Field 加入到文件中。我們知道,一篇文件有多種資訊,如題目,作者,修改時間,內容等。不同型別的資訊用不同的Field 來表示,在本例子中,一共有兩類資訊進行了索引,一個是檔案路徑,一個是檔案內容。其中FileReader 的SRC_FILE 就表示要索引的原始檔。
l IndexWriter 呼叫函式addDocument 將索引寫到索引資料夾中。
搜尋過程如下:
l IndexReader 將磁碟上的索引資訊讀入到記憶體,INDEX_DIR 就是索引檔案存放的位置。
l 建立IndexSearcher準備進行搜尋。
l 建立Analyer 用來對查詢語句進行詞法分析和語言處理。
l 建立QueryParser用來對查詢語句進行語法分析。
l QueryParser 呼叫parser 進行語法分析,形成查詢語法樹,放到Query 中。
l IndexSearcher 呼叫search 對查詢語法樹Query 進行搜尋,得到結果TopScoreDocCollector。
Lucene的各個模組:
l Lucene 的analysis 模組主要負責詞法分析及語言處理而形成Term。
l Lucene的index模組主要負責索引的建立,裡面有IndexWriter。
l Lucene的store模組主要負責索引的讀寫。
l Lucene 的QueryParser主要負責語法分析。
l Lucene的search模組主要負責對索引的搜尋。
l Lucene的similarity模組主要負責對相關性打分的實現。
Lucene 的索引過程,就是按照全文檢索的基本過程,將倒排表寫成此檔案格式的過程。
Lucene 的搜尋過程,就是按照此檔案格式將索引進去的資訊讀出來,然後計算每篇文件打分(score)的過程。
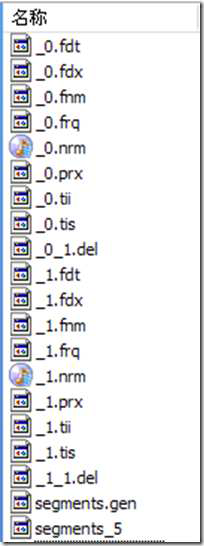
Lucene 的索引結構是有層次結構的,主要分以下幾個層次:
l 索引(Index):
Ø 在 Lucene 中一個索引是放在一個資料夾中的。
Ø 如上圖,同一資料夾中的所有的檔案構成一個Lucene 索引。
l 段(Segment):
Ø 一個索引可以包含多個段,段與段之間是獨立的,新增新文件可以生成新的段,不同的段可以合併。
Ø 如上圖,具有相同字首檔案的屬同一個段,圖中共兩個段 "_0" 和 "_1"。
Ø segments.gen 和segments_5 是段的元資料檔案,也即它們儲存了段的屬性資訊。
l 文件(Document):
Ø 文件是我們建索引的基本單位,不同的文件是儲存在不同的段中的,一個段可以包含多篇文件。
Ø 新新增的文件是單獨儲存在一個新生成的段中,隨著段的合併,不同的文件合併到同一個段中。
l 域(Field):
Ø 一篇文件包含不同型別的資訊,可以分開索引,比如標題,時間,正文,作者等,都可以儲存在不同的域裡。
Ø 不同域的索引方式可以不同,在真正解析域的儲存的時候,我們會詳細解讀。
l 詞(Term):
Ø 詞是索引的最小單位,是經過詞法分析和語言處理後的字串。
Lucene 儲存了從Index 到Segment 到Document 到Field 一直到Term 的正向資訊,也包括了從Term到Document 對映的反向資訊,還有其他一些Lucene 特有的資訊。
Index –> Segments (segments.gen,segments_N) –> Field(fnm, fdx, fdt) –> Term (tvx, tvd, tvf)
上面的層次結構不是十分的準確,因為segments.gen 和segments_N 儲存的是段(segment)
的元資料資訊(metadata),其實是每個Index 一個的,而段的真正的資料資訊,是儲存在域
(Field)和詞(Term)中的。
段的元資料資訊(segments_N)
域(Field)的元資料資訊(.fnm),域(Field)的資料資訊(.fdt,.fdx)
詞向量(Term Vector)的資料資訊(.tvx,.tvd,.tvf)
反向資訊是索引檔案的核心,也即反向索引。
反向索引包括兩部分,左面是詞典(Term Dictionary),右面是倒排表(Posting List)。
在Lucene 中,這兩部分是分檔案儲存的,詞典是儲存在tii,tis 中的,倒排表又包括兩部分,一部分是文件號及詞頻,儲存在frq 中,一部分是詞的位置資訊,儲存在prx 中。
Term Dictionary (tii, tis)
Frequencies (.frq)
Positions (.prx)
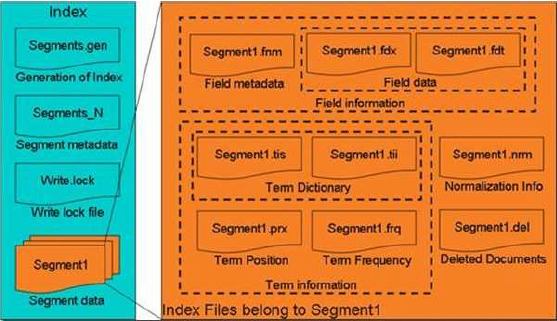
圖為其Lucene索引檔案的總體結構,
l 屬於整個索引(Index)的segment.gen,segment_N,其儲存的是段(segment)的元資料資訊,然後分多個segment儲存資料資訊,同一個segment 有相同的字首檔名。
l 對於每一個段,包含域資訊,詞資訊,以及其他資訊(標準化因子,刪除文件)
l 域資訊也包括域的元資料資訊,在fnm 中,域的資料資訊,在fdx,fdt 中。
l 詞資訊是反向資訊,包括詞典(tis,tii),文件號及詞頻倒排表(frq),詞位置倒排表(prx)。
參考連結:http://www.cnblogs.com/forfuture1978/archive/2009/12/14/1623594.html
相關推薦
Lucene原理與程式碼分析解讀筆記
Lucene是一個基於Java的高效的全文檢索庫。 那麼什麼是全文檢索,為什麼需要全文檢索? 目前人們生活中出現的資料總的來說分為兩類:結構化資料和非結構化資料。很容易理解,結構化資料是有固定格式和
Lucene 4.0 原理與程式碼分析
搜尋演算法的核心實際是對搜尋項之間相似度的打分策略,一個好的打分策略應該能夠綜合各種與搜尋項內容相關並對搜尋目的有幫助的所有因素,一般將這種策略叫做建模(modeling),由量化後的相關因素即特徵(feature)構成檢索(評分)模型,最後通過模型得到搜尋項之間的相似
《大型網站技術架構:核心原理與案例分析》筆記
· 大型網站軟體系統的特點 · 大型網站架構演化發展歷程 · 初始階段的網站架構 · 需求/解決問題 · 架構 · 應用服務和資料
程式碼雨實現原理與程式碼分析
閒來無事,好奇程式碼雨是怎麼實現的,早就聽說是利用連結串列,但自己卻想不出實現的思路,花了兩個晚上把程式碼看完了,分析都在程式碼裡,先看下效果吧。 在貼程式碼之前先簡單說下程式碼,方便讀者加深理解。 程式碼雨所用到的知識=簡單的windows api + C/C++的迴圈
《大型網站技術架構:核心原理與案例分析》-- 讀書筆記 (5) :網購秒殺系統
案例 並發 刷新 隨機 url 對策 -- 技術 動態生成 1. 秒殺活動的技術挑戰及應對策略 1.1 對現有網站業務造成沖擊 秒殺活動具有時間短,並發訪問量大的特點,必然會對現有業務造成沖擊。對策:秒殺系統獨立部署 1.2 高並發下的應用、
免費的Lucene 原理與代碼分析完整版下載
一個個 圖片 重新 修改時間 結果 參數 擴展 提取 要點 Lucene是一個基於Java的高效的全文檢索庫。那麽什麽是全文檢索,為什麽需要全文檢索?目前人們生活中出現的數據總的來說分為兩類:結構化數據和非結構化數據。很容易理解,結構化數據是有固定格式和結構的或者有限長度的
OpenCV學習筆記(31)KAZE 演算法原理與原始碼分析(五)KAZE的原始碼優化及與SIFT的比較
KAZE系列筆記: 1. OpenCV學習筆記(27)KAZE 演算法原理與原始碼分析(一)非線性擴散濾波 2. OpenCV學習筆記(28)KAZE 演算法原理與原始碼分析(二)非線性尺度空間構建 3. Op
OpenCV學習筆記(30)KAZE 演算法原理與原始碼分析(四)KAZE特徵的效能分析與比較
KAZE系列筆記: 1. OpenCV學習筆記(27)KAZE 演算法原理與原始碼分析(一)非線性擴散濾波 2. OpenCV學習筆記(28)KAZE 演算法原理與原始碼分析(二)非線性尺度空間構
《大型網站技術架構之核心原理與案例分析》讀書筆記
架構!對於工作經驗尚淺的我是理應遠遠不用考慮的倆字。不過就像這本書所說到的一個好的網站架構體系,不僅僅是架構師個人的架構,而是和參與共同建設的人共同貢獻,讓參與的人覺得自己是架構體系的建設者之一,就越是自動承擔開發過程的責任和共同維護架構和改善軟體。
《大型網站技術架構:核心原理與案例分析》讀書筆記 - 第2篇 架構
第2篇 架構 4 瞬時響應:網站的高效能架構 34 4.1 網站效能測試 35 效能測試是效能優化的前提和基礎,也是效能優化結果的檢查和度量標準。 4.1.1 不同視角下的網站效能 35 使用者:直觀感受到的快慢 開發:應用程式本身 運維:基礎設施效能和資源利用率 4.1.2 效
《大型網站技術架構:核心原理與案例分析》讀書筆記
第六章伸縮性,網站的演化分離過程可以分為三類, 第一類大的系統級別的分離,例如資料庫系統,快取系統,檔案管理系統(靜態資源),演化過程為:為單一伺服器->資料庫分離->快取分離->靜態資源分離。 第二類業務流程的抽象分離,從下到上的模組為:資料庫->基礎技術服務->可複用業務
《大型網站技術架構核心原理與案例分析》讀書筆記之RAID技術
RAID(廉價磁碟冗餘陣列)技術主要是為了改善磁碟的訪問延遲,增強磁碟的可用性和容錯能力。目前伺服器級別的計算機都支援插入多塊磁碟(8塊或者更多),通過使用RAID技術,實現資料在多塊磁碟上的併發讀寫和資料備份。 假設伺服器有N塊磁碟。
《大型網站技術架構:核心原理與案例分析》【PDF】下載
優化 均衡 1.7 3.3 架設 框架 應用服務器 博客 分布式服務框架 《大型網站技術架構:核心原理與案例分析》【PDF】下載鏈接: https://u253469.pipipan.com/fs/253469-230062557 內容簡介 本書通過梳理大型網站技
線程池的工作原理與源碼解讀
分享 指定 blog 系統資源 時也 就會 起名字 服務端 面試 隨著cpu核數越來越多,不可避免的利用多線程技術以充分利用其計算能力。所以,多線程技術是服務端開發人員必須掌握的技術。 線程的創建和銷毀,都涉及到系統調用,比較消耗系統資源,所以就引入了線程池技術,避免
Redis實現分布式鎖原理與實現分析
數據表 防止 中一 csdn 訂單 not 產生 www 整體 一、關於分布式鎖 關於分布式鎖,可能絕大部分人都會或多或少涉及到。 我舉二個例子: 場景一:從前端界面發起一筆支付請求,如果前端沒有做防重處理,那麽可能在某一個時刻會有二筆一樣的單子同時到達系統後臺。 場
閱讀《大型網站技術架構:核心原理與案例分析》第五、六、七章,結合《河北省重大技術需求征集系統》,列舉實例分析采用的可用性和可修改性戰術
定時 並不會 表現 做出 span class 硬件 進行 情況 網站的可用性描述網站可有效訪問的特性,網站的頁面能完整呈現在用戶面前,需要經過很多個環節,任何一個環節出了問題,都可能導致網站頁面不可訪問。可用性指標是網站架構設計的重要指標,對外是服務承諾,對內是考核指
《大型網站技術架構:核心原理與案例分析》結合需求征集系統分析
運行 模塊 正常 一致性hash 產品 進行 OS 很多 層次 閱讀《大型網站技術架構:核心原理與案例分析》第五、六、七章,結合《河北省重大技術需求征集系統》,列舉實例分析采用的可用性和可修改性戰術,將上述內容撰寫成一篇1500字左右的博客闡述你的觀點。 閱
《大型網站技術架構:核心原理與案例分析》讀後感
TP bubuko 一個 nbsp 分享 架構 優化 技術分享 src 李智慧的著作《大型網站技術架構:核心原理與案例分析》,寫得非常好, 本著學習的態度,對於書中的關於性能優化的講解做了一個思維導圖,供大家梳理思路和學習之用。拋磚引玉。 《大型網站技術架構
速讀《文獻管理與資訊分析》筆記
由於是第一次接觸此類的書籍,加上研一的時間比較緊,並沒有多少時間進行有效的閱讀,只能對此進行簡單的介紹,希望自己在未來的時間裡可以仔細閱讀和慢慢品味這本書。 這本書分為七章的學習計劃,分別是: 第一章 科研工作者的資訊修煉 1.1 資訊社會的學習與科研 1.2 社會發展趨勢 1.3 課程由來及內容設計
Ceilometer Compute Agent 原理和程式碼分析
本部落格所有文章採用的授權方式為 自由轉載-非商用-非衍生-保持署名 ,轉載請務必註明出處,謝謝。 宣告: 本部落格歡迎轉發,但請註明出處,保留原作者資訊 部落格地址:孟阿龍的部落格 所有內容為本人學習、研究、總結。如有雷同,實屬榮幸 注: 本文以Opens