
【神經網路】卷積層輸出大小計算(長、寬、深度)
先定義幾個引數
- 輸入圖片大小 W×W
- Filter大小 F×F
- 步長 S
- padding的畫素數 P
於是我們可以得出
N = (W − F + 2P )/S+1輸出圖片大小為 N×N
轉載:
卷積中的特徵圖大小計算方式有兩種,分別是‘VALID’和‘SAME’,卷積和池化都適用,除不盡的結果都向上取整。
1.如果計算方式採用'VALID',則:

其中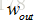
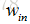
2.如果計算方式採用'SAME',輸出特徵圖的大小與輸入特徵圖的大小保持不變,
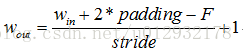
其中padding為特徵圖填充的圈數。
若採用'SAME'方式,kernel_size=1時,padding=0;kernel_size=3時,padding=1;kernel_size=5時,padding=3,以此類推。


tensorflow程式碼(Tensorflow官方文件)中:
w_conv1=weight_variable([5,5,1,32]),一直不明白這個32是怎麼來的,表示的是什麼?
後來看到cs231n-知乎課程翻譯的卷積神經網那一章的一段話:
引數共享:在卷積層中使用引數共享是用來控制引數的數量。就用上面的例子,在第一個卷積層就有55x55x96=290,400個神經元,每個有11x11x3=364個引數和1個偏差。將這些合起來就是290400x364=105,705,600個引數。單單第一層就有這麼多引數,顯然這個數目是非常大的。
作一個合理的假設:如果一個特徵在計算某個空間位置(x,y)的時候有用,那麼它在計算另一個不同位置(x2,y2)的時候也有用。基於這個假設,可以顯著地減少引數數量。換言之,就是將深度維度上一個單獨的2維切片看做深度切片(depth slice),比如一個數據體尺寸為[55x55x96]的就有96個深度切片,每個尺寸為[55x55]。在每個深度切片上的神經元都使用同樣的權重和偏差。在這樣的引數共享下,例子中的第一個卷積層就只有96個不同的權重集了,一個權重集對應一個深度切片,共有96x11x11x3=34,848個不同的權重,或34,944個引數(+96個偏差)。
可以看出,上面的32表示的是卷積層輸出的深度,因為大家都明白width和height都可以通過公式計算得到,但是很多文獻都沒有告訴深度是如何得到的,下面是我的認識:
1. 因為這個深度是沒有公式可以計算出來的,因為深度是一個經驗值,如上面程式碼的32 ,其實是一個經驗值,是通過調整引數發現32是一個最合適的值,可以得到最好的準確率,但是不同的影象的深度是不一樣的。
2.這個深度表示用了多少個卷積核,下面這個圖可以說明一下:
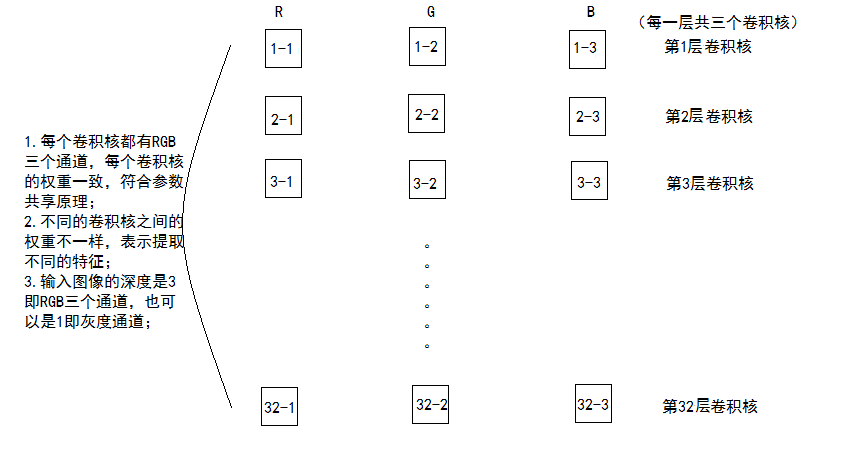
上圖就可以很有效的說明 :卷積層輸出的深度==卷積核的個數。
相關推薦
【神經網路】卷積層輸出大小計算(長、寬、深度)
先定義幾個引數 輸入圖片大小 W×W Filter大小 F×F 步長 S padding的畫素數 P 於是我們可以得出 N = (W − F + 2P )/S+1 輸出圖片大小為 N×N 轉載: 卷積中的特徵圖大小計算方式有兩種,分別是‘VALID’和‘SAM
【python實現卷積神經網路】卷積層Conv2D實現(帶stride、padding)
關於卷積操作是如何進行的就不必多說了,結合程式碼一步一步來看卷積層是怎麼實現的。 程式碼來源:https://github.com/eriklindernoren/ML-From-Scratch 先看一下其基本的元件函式,首先是determine_padding(filter_shape, ou
【深度學習】卷積神經網路的卷積層和池化層計算
一、簡介 \quad\quad 卷積神經網路(Convolutional neural network, CNN),
神經網路中卷積層的堆疊
在神經網路的設計中,經常會出現多個卷積層堆疊的情況,(例如VGGNet)通過VGG16/19的結構圖可以看出,每一段使用了很多卷積層堆疊,然後再經過池化層,這其實是非常有用的設計。如下圖所示:兩個3x3
【Deep learning】卷積神經網路CNN演算法原理
寫在前面在上一篇【Deep learning】卷積神經網路CNN結構中我們簡單地介紹了CNN的結構。接下來我們看看這種結構的CNN模型是怎麼執行的,包括CNN的前向傳播和反向傳播演算法。1.CNN前向傳播演算法(1)輸入層前向傳播到卷積層輸入層的前向傳播是CNN前向傳播演算法
【深度學習】卷積層提速Factorized Convolutional Neural Networks
Wang, Min, Baoyuan Liu, and Hassan Foroosh. “Factorized Convolutional Neural Networks.” arXiv preprint arXiv:1608.04337 (2016).
如何確定卷積神經網路的卷積核大小、卷積層數、每層map個數
卷積核大小 卷積層數確定的原則是 長而深,不知道怎麼就選3*3 三層3*3的卷積效果和一層7*7的卷積效果一致,我們知道一次卷積的複雜度是卷積長寬*影象長寬,3次卷積的複雜度為3*(3*3)*影象長寬《(7*7)*影象長寬,既然效果一樣,那當然選多次小卷積啊。 卷積
Deep learning-全連線層神經網路與卷積神經網路
全連線層神經網路與卷積神經網路 全連線層神經網路相比於卷積神經網路存在的問題:因為全連線,所以當相互連線的節點個數增加時,節點之間的邊個數會很多,而一條邊對應著一個引數,所以全連線層在神經網路節點個數多的時候會存在引數很多的情況。而對於神經網路引數過多帶來的影響有在計算上的,也有在模型的擬合程度
【神經網路】自編碼聚類演算法--DEC (Deep Embedded Clustering)
1.演算法描述 最近在做AutoEncoder的一些探索,看到2016年的一篇論文,雖然不是最新的,但是思路和方法值得學習。論文原文連結 http://proceedings.mlr.press/v48/xieb16.pdf,論文有感於t-SNE演算法的t-
【計算機網路】資料鏈路層總結
資料鏈路層 目錄 資料鏈路層概述 基本概念 資料鏈路層的三個基本問題 點對點通道的資料鏈路層 概述 PPP協議的組成 PPP幀的格式和要求 PPP協議的工作狀態 廣播通道的資料鏈路層 區域網和乙太
深度學習:卷積神經網路,卷積,啟用函式,池化
卷積神經網路——輸入層、卷積層、啟用函式、池化層、全連線層 https://blog.csdn.net/yjl9122/article/details/70198357?utm_source=blogxgwz3 一、卷積層 特徵提取 輸入影象是32*32*3,3是它的深度(即R
卷積神經網路之卷積計算、作用與思想
部落格:blog.shinelee.me | 部落格園 | CSDN 卷積運算與相關運算 在計算機視覺領域,卷積核、濾波器通常為較小尺寸的矩陣,比如\(3\times3\)、\(5\times5\)等,數字影象是相對較大尺寸的2維(多維)矩陣(張量),影象卷積運算與相關運算的關係如下圖所示(圖片來自連結)
卷積神經網路的卷積核的每個通道是否相同?
假設輸入資料的格式是[?,28,28,16],卷積核的尺寸是[3,3,16,32] 輸入資料的格式的含義是: &
神經網路6_CNN(卷積神經網路)、RNN(迴圈神經網路)、DNN(深度神經網路)概念區分理解
sklearn實戰-乳腺癌細胞資料探勘(部落格主親自錄製視訊教程,QQ:231469242) https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm
BP神經網路&卷積神經網路概念
1、BP神經網路 1.1 神經網路基礎 神經網路的基本組成單元是神經元。神經元的通用模型如圖 1所示,其中常用的啟用函式有閾值函式、sigmoid函式和雙曲正切函式。 圖 1 神經元模型 神經元的輸出為: y=f(∑i=1m
【計算機網路】資料鏈路層的代表協議PPP與區域網
1. 點對點協議PPP 概念:對於點對點的鏈路,簡單得多的點對點協議PPP是目前使用的最廣泛的資料鏈路層協議。 PP協議就是使用者計算機和ISP進行通訊時所使用的資料鏈路層協議。 特點: 簡單 封裝成幀 透明性 多種網路層協議 PPP還必須能夠在多種型別的鏈路
卷積神經網路經過卷積之後的影象尺寸
設輸入影象尺寸為WW3,卷積核尺寸為F,步幅為S,Padding使用P,共有M個卷積核,則經過該卷積層後輸出的影象尺寸為: (W-F+2P)/S + 1 * (W-F+2P)/S + 1 * M 注意:共有M個卷積核,比如第一個卷積核
Neural Networks and Convolutional Neural Networks Essential Training 神經網路和卷積神經網路基礎教程 Lynda課程中文字幕
Neural Networks and Convolutional Neural Networks Essential Training 中文字幕 神經網路和卷積神經網路基礎教程 中文字幕Neural Networks and Convolutional Neural Networks
深層神經網路和卷積神經網路的反向傳播過程推導
反向傳播過程是深度學習的核心所在,雖然現在很多深度學習架構如Tensorflow等,已經自帶反向傳播過程的功能。我們只需要完成網路結構的正向傳播的搭建,反向傳播過程以及引數更新都是由架構本身來完成的。但為了更好的瞭解深度學習的機理,理解反向傳播過程的原理還是很重要的。 在學
【神經網路】VGG、ResNet、GoogleLeNet、AlexNet等常用網路程式碼及預訓練模型
常用資料集: 模型們在ImageNet競賽上的top-5錯誤率概況: 常用預訓練模型池: AlexNet資訊如上圖 - 在當時第一次使用了ReLU - 使用了Norm層(在當時還不廣泛) - 訓練資料量增大 - dropout 0.5 - 每批資料