
Java系列筆記(6)
目錄
在Java中,JVM、併發、容器、IO/NIO是我認為最重要的知識點,本章將介紹其中的併發,這也是從“會Java”到精通Java所必須經歷的一步。本章承接上一張《Java系列筆記(5) - 執行緒》,其中介紹了Java執行緒的相關知識,是本章介紹內容的基礎,如果對於執行緒不熟悉的,可以先閱讀以下這篇部落格瞭解一下。
在上一篇部落格《執行緒》中,我們講到了Java的記憶體模型,事實上,Java記憶體模型的建立,是圍繞著一個原則來進行的:在保證執行緒間合作的基礎上,避免執行緒的不良影響。而這一原則,也是本章所介紹的併發機制的最終目的。
本文大量參考了系列文章《深入淺出Java Concurrency,http://www.blogjava.net/xylz/archive/2010/07/08/325587.html》,這是一系列十分優秀也十分明晰的文章,我在學習java併發過程中,對這個系列的文章讀了很多遍,這個系列的文章作者寫的很容易理解而且很詳盡,想要進一步理解java併發的同學,可以仔細去拜讀一下《深入淺出Java Concurrency》這一系列文章。
在原來的計劃中,鎖和Condition等概念是放在一起的,不過限於篇幅問題,拆成兩個部分,上部分是本文,講解基本的併發概念、CountDownLatch,原子類、訊號量等類,下部分集中講鎖和併發異常。
本文在編寫過程中,參考、引用和總結了《深入淺出Java Concurrency》的內容以及其他Java併發書籍部落格的內容,篇幅有限,所以可能總結的不到位,敬請指正。
1,基本概念
Java併發的重要性毋庸置疑,Java併發的設計目的在於3個方面:
簡單,意味著程式設計師儘可能少的操作底層或者實現起來要比較容易;
高效,意味著耗用資源要少,程式處理速度要快;
執行緒安全,意味著在多執行緒下能保證資料的正確性。
在Java併發中,有幾個常見概念,需要在講述併發之前進行解釋:
臨界資源和臨界區
臨界資源是一般是一種記憶體資源,一個時刻只允許一個程序(在java中,是執行緒)訪問,一個執行緒正在使用臨界資源的時候,另一個執行緒不能使用。臨界資源是非可剝奪性資源,即使是作業系統(或JVM)也無法阻止這種資源的獨享行為。
臨界區是一種程序中範文臨界資源的那段程式程式碼,注意,是程式程式碼,不是記憶體資源了,這就是臨界資源與臨界區的區別。我們規定臨界區的使用原則(也即同步機制應遵循的準則)十六字訣:“空閒讓進,忙則等待,有限等待,讓權等待”–strling。讓我們分別來解釋一下:
(1)空閒讓進:臨界資源空閒時一定要讓程序進入,不發生“互斥禮讓”行為。
(2)忙則等待:臨界資源正在使用時外面的程序等待。
(3)有限等待:程序等待進入臨界區的時間是有限的,不會發生“餓死”的情況。
(4)讓權等待:程序等待進入臨界區是應該放棄CPU的使用。
併發
狹義的只就Java而言,Java多執行緒在訪問同一資源時,出現競爭的問題,叫做併發問題,Java併發模型是圍繞著在併發過程中如何處理原子性、可見性、有序性這3個特徵來設計的。
執行緒安全
如果一個操作序列,不考慮耗時和資源消耗,在單執行緒執行和多執行緒執行的情況下,最終得到的結果永遠是相同的,則這個操作序列叫做執行緒安全的。
如果存在不相同的概率,則就是非執行緒安全的。
原子性(Atomicity)
如果一個操作時不可分割的,那就是一個原子操作,也叫這個操作具有原子性。相反的,一個操作時可以分割的(如a++,它實際上是a=a+1),則就是非原子操作;原子操作是執行緒安全的,非原子操作都是非執行緒安全的,但是我們可以通過同步技術(lock)或同步資料模型(Concurrent容器等)把非原子操作序列變成執行緒安全的原子操作。
事實上,java併發主要研究的就是3個方面的問題:
1,怎麼更好的使用原子操作;
2,怎麼把非原子操作變得執行緒安全;
3,怎麼提高原子操作和非原子操作的效率並減少資源消耗。
可見性(Visibility)
一個變數被多個執行緒共享,如果一個執行緒修改了這個變數的值,其它執行緒能夠立即得知這個修改,則我們稱這個修改具有可見性。
(可參考上一章《Java系列筆記(5)-執行緒》中的Java執行緒記憶體模型部分),Java執行緒記憶體模型的設計,是每個執行緒擁有一份自己的工作記憶體,當變數修改之後,將新值同步到主記憶體。但是對於普通變數而言,這種同步,並不能保證及時性,所以可能出現工作記憶體以及更改,主記憶體尚未同步的情況。
Java中,最簡單的方法是使用volatile實現強制同步,它的實現方式是保證了變數在修改後立即同步到主記憶體,且每次使用該變數前,都先從主記憶體重新整理該值。
另外,可以採用synchronized或final關鍵字實現可見性;
synchronized的實現原理在於,一個變數如果要執行unlock操作,必須先把改變數同步到主記憶體中(執行store和write)。因此一個變數如果被synchronized實現強制同步,則即使不用volatile,也可以實現強制可見性。
final的實現原理在於,一個變數被final修飾,則其值(或引用地址)不可以再被修改,所以其它執行緒如果能看到,也只是能看到這個變數的這個唯一值(對於物件而言,是唯一引用)。
需要注意,一個操作被保證了可見性,並不一定能保證原子性,比如:
volatile int a; a++;
在上面這段程式碼中,a是滿足可見性的,但是a++仍然不是原子性操作。當有多個執行緒執行a++時,仍然存在併發問題。
有序性(Ordering)
Java執行緒的有序性,表現為兩個方面:
在一個執行緒內部觀察,所有操作都是有序的,所有指令按照“序列(as-if-serial,字面意思是“像排了序一樣”,as-if-serial的真正含義是不管怎麼重排序,一個單執行緒程式的執行結果都必須相同)” 的方式執行。
線上程間觀察,也就是從某個執行緒觀察另一個執行緒,則所有其他執行緒都可以交叉並行執行,是正序的,唯一例外的是被同步方法、同步塊、volatile等欄位修飾的強制同步的程式碼,需要線上程間保持有序。
注:關於指令重排序、as-if-serial、happens-before等,可以參考上一章《Java系列筆記(5)-執行緒》,也可以參考網上的眾多資料,這裡不再敘述。
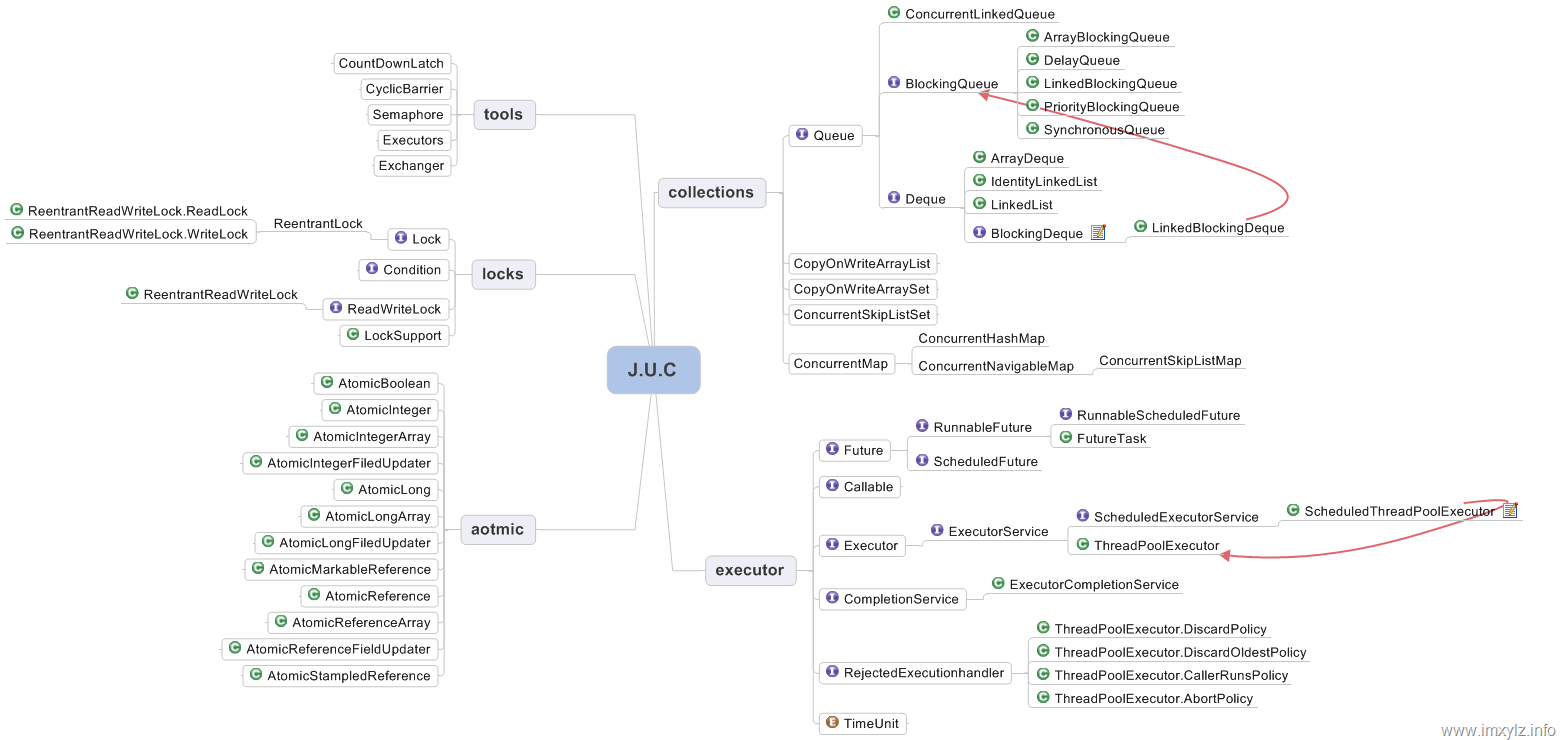
JUC
java.util.concurrent包,這個包是從JDK1.5開始引入的,在此之前,這個包獨立存在著,它是由Doug Lea開發的,名字叫backport-util-concurrent,在1.5開始引入java,命名路徑為java.util.concurrent,其中的基本實現方式,也有所改變。主要包括以下類:(來源於:深入淺出Java Concurreny(http://www.blogjava.net/xylz/archive/2010/06/30/324915.html))
JNI
Java native interface,java本地方法介面,由於Java本身是與平臺無關的,所以在效能等方面有可能存在影響(雖然隨著java的發展,這種情況很少),為了解決這種問題,使用C/C++編寫了JNI介面,在java中可以直接呼叫這些程式碼的產生的機器碼,從而避免嚴重影響效能的程式碼段。關於JNI,可以參考這篇文章:http://www.cnblogs.com/mandroid/archive/2011/06/15/2081093.html
CAS
CAS,compare and swap,比較和替換(也有人直接理解為compare and set,其實是一樣的)。CAS是一種樂觀鎖做法,而且整個JUC的實現都是基於CAS機制的。
如果直接用synchronized加鎖,這是一種悲觀鎖做法,所謂悲觀鎖,就是悲觀的認為執行緒是絕對不安全的,必須保證在swap值之前,沒有任何其它執行緒操作當前值。synchronized是一種獨佔鎖,效能受限於這種悲觀策略。這一點將在後面詳述。
而CAS是一種樂觀鎖機制,所謂樂觀鎖,就是相信在compare 和swap之間,被其它執行緒影響的可能性不大,只要compare校驗通過,就可以進行swap。
在Java中,compareAndSet的基本程式碼如下:
1 public final boolean compareAndSet(int expect, int update) { 2 return unsafe.compareAndSwapInt(this, valueOffset, expect, update); 3 }
從程式碼中看,java的compareAndSet使用使用JNI中的unsafe介面來實現的,這是因為,現代CPU基本都提供了特殊的指令,能夠做到自動更新共享資料的同時,檢測其它執行緒的干擾,也就是說,CPU本身提供了compareAndSet功能。所以才能提供JNI的CAS介面。
有了JNI的CAS介面,基於該介面的JUC就能獲得更高效能。
在 Intel 處理器中,比較並交換通過指令cmpxchg實現。比較是否和給定的數值一致,如果一致則修改,不一致則不修改。
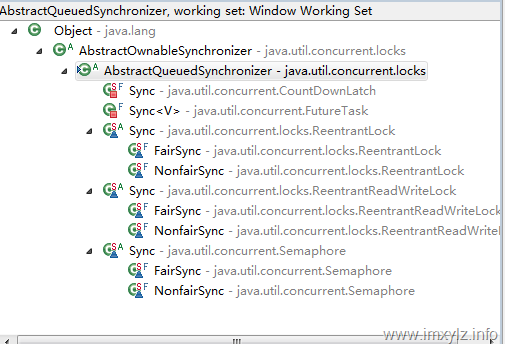
AQS
AbstractQueuedSynchronizer,簡稱AQS,是J.U.C最複雜的一個類。這個類是CountDownLatch/FutureTask /ReentrantLock/RenntrantReadWriteLock/Semaphore的基礎,是Lock和Executor實現的前提。參考:(http://www.blogjava.net/xylz/archive/2010/07/06/325390.html)
非阻塞演算法
任何一個執行緒的失敗或掛起不應該影響其他執行緒的失敗或掛起的演算法叫做非阻塞演算法。現代CPU能夠提供非阻塞功能,它可以在自動更新共享資料的同時,檢查其它執行緒的干擾。
2,volatile
正如前面所述,java中volatile欄位的作用是保證併發過程中某個變數的可見性。而volatile保證可見性的方法如下:
1,Java記憶體模型不會對volatile指令進行重排序,從而保證對volatile變數的執行順序,永遠是按照其出現順序執行的。重排序的依據是happens-before法則,happens-before法則共8條,其中有一條與volatile相關,就是:“對volatile欄位的寫入操作happens-before於每一個後續的同一個欄位的讀操作”。
注:happens-before法則:http://www.blogjava.net/xylz/archive/2010/07/03/325168.html
2,volatile變數不會被快取在暫存器中(只有擁有執行緒可見)或者其他對CPU不可見的地方,每次總是從主存中讀取volatile變數的結果。
不過需要注意的是:volatile欄位只能保證可見性,不能保證原子性,也不能保證執行緒安全。
volatile的工作原理
下面這段話摘自《深入理解Java虛擬機器》:
“觀察加入volatile關鍵字和沒有加入volatile關鍵字時所生成的彙編程式碼發現,加入volatile關鍵字時,會多出一個lock字首指令”
lock字首指令實際上相當於一個記憶體屏障(也成記憶體柵欄),記憶體屏障會提供3個功能:
1)它確保指令重排序時不會把其後面的指令排到記憶體屏障之前的位置,也不會把前面的指令排到記憶體屏障的後面;即在執行到記憶體屏障這句指令時,在它前面的操作已經全部完成;
2)它會強制將對快取的修改操作立即寫入主存;
3)如果是寫操作,它會導致其他CPU中對應的快取行無效。
上面的說法解釋了volatile的工作原理的起源。不過,建議大家複習一下本系列文章第3章JVM記憶體分配和第5章執行緒的內容,來理解下面的解釋。與前面這兩章中巨集觀的講解記憶體分配和執行緒記憶體模型相區別,下面的部分專注於解析java記憶體模型和volatile的工作原理,但也能更好的理解以前的知識:
注:下面的圖參考了:http://www.cnblogs.com/aigongsi/archive/2012/04/01/2429166.html,其中描述了記憶體模型的6種操作,比上一章中介紹的8種操作少了lock、unlock 2 種,這6種操作都是原子性的。
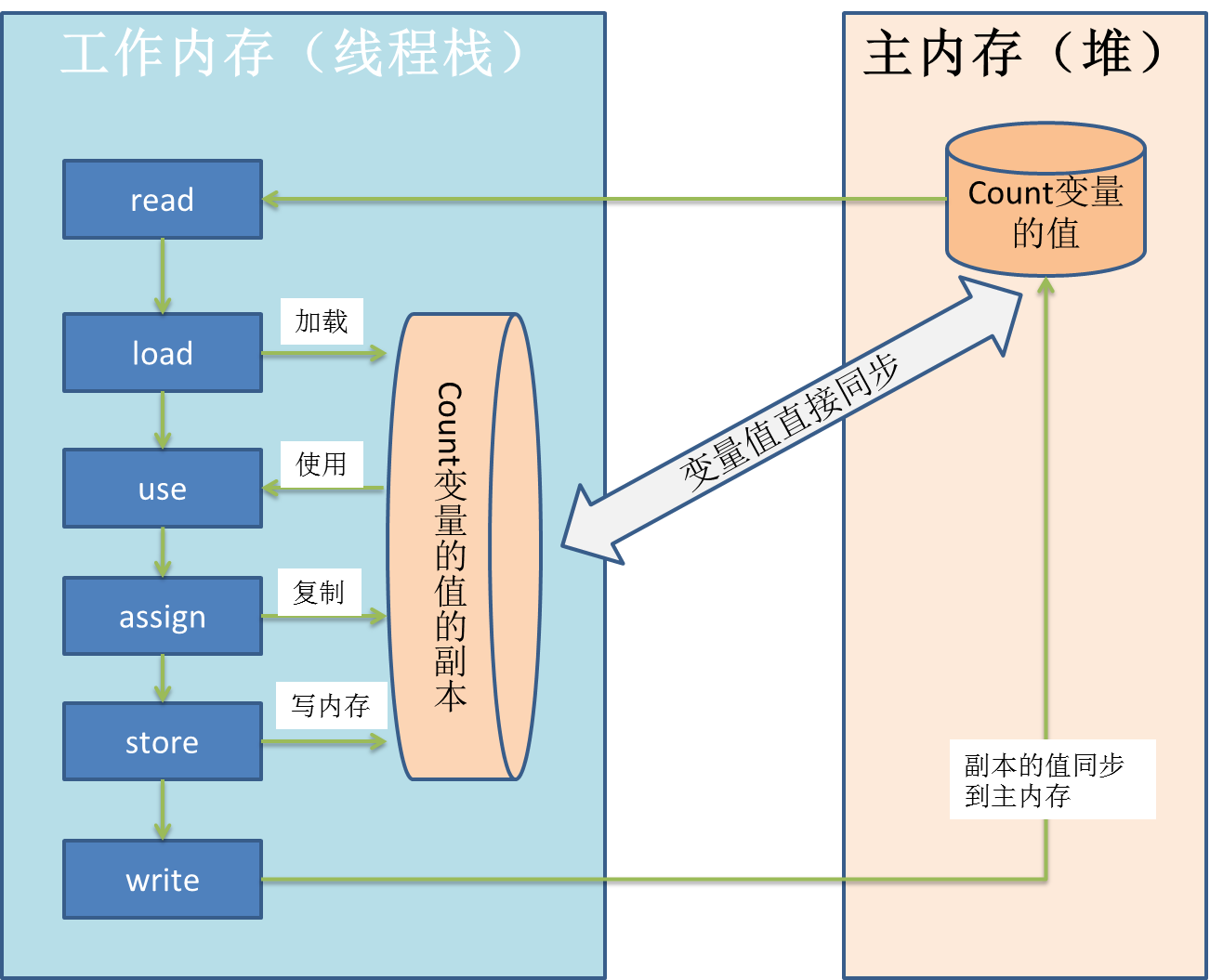
在上圖中,如果是普通變數:
1,變數值從主記憶體(在堆中)load到本地記憶體(在當前執行緒的棧楨中);
2,之後,執行緒就不再和該變數在主記憶體中的值由任何關係,而是直接操作在副本變數上(這樣速度很快),這時,如果主存中的count或本地記憶體中的副本發生任何變化,都不會影響到對方,也正是這個原因導致併發情況下出現資料不一致;
3,在修改完的某個時刻(執行緒退出之前),自動把本地記憶體中的變數副本值回寫到物件在堆中的對應變數。
這6步操作中:
read和load是將主存變數載入到當前本地記憶體;
use和assign是執行執行緒程式碼,改變副本值,可以多次執行;
store和write是用本地記憶體回寫到主存;
如果是volatile修飾的變數:
volatile仍然在執行一個從主存載入到工作記憶體,並且將變更的值寫回主存的操作,但是:
1,volatile保證每次讀取該變數前,都判斷當前值是否已經失效(即是否已經與主存不一致),如果已經失效,則從主存load最新的變數;
2,volatile保證每次對該變數做出修改時,都立即寫入主存;
需要注意的是,雖然volatile保證了上面的特性,但是它只是保證了可見性,卻沒有保證原子性,也就是說,read-load-use-assign-store-write,這些操作序列組合起來仍然是非原子操作。舉個例子:
共享變數當前在主存中的值為count=10;執行緒1和執行緒2都對該值進行自增操作,按如下步驟進行:
1,執行緒1和2都讀取最新值,得到值為count=10;
2,執行緒1被阻塞;
3,執行緒2執行自增,寫回count=11;
4,執行緒1喚醒,由於之前已經完成了讀取變數的操作,所以這裡直接進行自增。於是也自增到11,回寫主存,最終count=11;
與我們期望的兩次自增count=12衝突;
目前來說,要保證原子性,只能通過synchronized、Lock介面、Atomic*來實現。
說了這麼多,有同學可能會問,為什麼volatile這也不行那也不行,陷阱這麼多,我們還要用它呢?
volatile相對於synchronized,最大的好處是某些情況下它的效能高,而且使用起來直觀簡便。而且,如果你的“程式碼本身能保證原子性”,那麼用volatile是個不錯的選擇:
這裡所說的程式碼本身能保證原子性,是指:
1,對變數的寫操作,不依賴於當前的值(就是說,不會先讀取當前值,然後在當前值的基礎上進行改變,比如,不是自增,而是賦值);
2,變數沒有包含在其它變數的不變式中(這一點不是很好理解,可以參考這裡:http://www.ibm.com/developerworks/cn/java/j-jtp06197.html)
一個最常見的volatile的應用場景是boolean的共享狀態標誌位,或者單例模式的雙重檢查鎖(參考Java併發程式設計:volatile關鍵字解析,http://www.cnblogs.com/dolphin0520/p/3920373.html)
另外,有一個關於volatile的常見的坑就是:從上面的描述可以看出,volatile對於基本資料型別(值直接從主記憶體向工作記憶體copy)才有用。但是對於物件來說,似乎沒有用,因為volatile只是保證物件引用的可見性,而對物件內部的欄位,它保證不了任何事。即便是在使用ThreadLocal時,每個執行緒都有一份變數副本,這些副本本身也是儲存在堆中的,執行緒棧楨中儲存的仍然是基本資料型別和變數副本的引用。
所以,千萬不要指望有了volatile修飾物件,物件就會像基本資料型別一樣整體呈現原子性的工作了。
事實上,如果一個物件被volatile修飾,那麼就表示它的引用具有了可見性。從而使得對於變數引用的任何變更,都線上程間可見。
這一點在後面將要介紹的AtomicReference中就有應用。
3,Atom
java中,可能有一些場景,操作非常簡單,但是容易存在併發問題,比如i++,此時,如果依賴鎖機制,可能帶來效能損耗等問題,於是,如何更加簡單的實現原子性操作,就成為java中需要面對的一個問題。
java中的atom操作,比如AtomicInteger,AtomicLong,AtomicBoolean,AtomicReference,AtomicIntegerArray/AtomicLongArray/AtomicReferenceArray;這些操作中旺旺提供一些原子化操作,比如incrementAndGet(相當於i++),compareAndSet(安全賦值)等,相關方法和用法就不再贅述,網上有很多類似資料,或者直接讀原始碼也很容易懂。
在backport-util-concurrent沒有被引入java1.5併成為JUC之前,這些原子類和原子操作方法,都是使用synchronized實現的。不過JUC出現之後,這些原子操作基於JNI提供了新的實現,以AtomicInteger為例,看看它是怎麼做到的:
如果是讀取值,很簡單,將value宣告為volatile的,就可以保證在沒有鎖的情況下,資料是執行緒可見的:
1 private volatile int value;public final int get() { 2 return value; 3 }
那麼,涉及到值變更的操作呢?以AtomicInteger實現:++i為例:
1 public final int incrementAndGet() { 2 for (;;) { 3 int current = get(); 4 int next = current + 1; 5 if (compareAndSet(current, next)) 6 return next; 7 } 8 }
在這裡採用了CAS操作,每次從記憶體中讀取資料然後將此資料和+1後的結果進行CAS操作,如果成功就返回結果,否則重試直到成功為止。
而這裡的comparAndSet(current,next)就是前面介紹CAS的時候所說的依賴JNI實現的樂觀鎖做法:
public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }
除了基本資料型別的原子化操作以外,JUC還提供了陣列的原子化、引用的原子化,以及Updater的原子化,分別為:

下面主要介紹這3類原子化操作為什麼要原子化以及分別是怎麼實現的。
陣列原子化
注意,Java中Atomic*Array,並不是對整個陣列物件實現原子化(也沒有必要這樣做),而是對陣列中的某個元素實現原子化。例如,對於一個整型原子陣列,其中的原子方法,都是對每個元素的:
1 public final int getAndDecrement(int i) { 2 while (true) { 3 int current = get(i); 4 int next = current - 1; 5 if (compareAndSet(i, current, next)) 6 return current; 7 } 8 }
引用原子化
有些同學可能會疑惑,引用的操作本身不就是原子的嗎?一個物件的引用,從A切換到B,本身也不會出現非原子操作啊?這種想法本身沒有什麼問題,但是考慮下嘛的場景:物件a,當前執行引用a1,執行緒X期望將a的引用設定為a2,也就是a=a2,執行緒Y期望將a的引用設定為a3,也就是a=a3。
如果執行緒X和執行緒Y都不在意a到底是從哪個引用通過賦值改變過來的,也就是說,他們不在意a1->a2->a3,或者a1->a3->a2,那麼就完全沒有關係。
但是,如果他們在乎呢?
X要求,a必須從a1變為a2,也就是說compareAndSet(expect=a1,setValue=a2);Y要求a必須從a1變為a3,也就是說compareAndSet(expect=a1,setValue=a3)。如果嚴格遵循要求,應該出現X把a的引用設定為a2後,Y執行緒操作失敗的情況,也就是說:
X:a==a1--> a=a2;
Y:a!=a1 --> Exception;
但是如果沒有原子化,那麼Y會直接將a賦值為a3,從而導致出現髒資料。
這就是原子引用AtomicReference存在的原因。
1 public final V getAndSet(V newValue) { 2 while (true) { 3 V x = get(); 4 if (compareAndSet(x, newValue)) 5 return x; 6 } 7 }
注意,AtomicReference要求引用也是volatile的。
Updater原子化
其它幾個Atomic類,都是對被volatile修飾的基本資料型別的自身資料進行原子化操作,但是如果一個被volatile修飾的變數本身已經存在在類中,那要如何提供原子化操作呢?比如,一個Person,其中有個屬性為age,private volatile int age;,如何對age提供原子化操作呢?
1 private AtomicIntegerFieldUpdater<Person> updater = AtomicIntegerFieldUpdater.newUpdater(Person.class, "age"); 2 updater.getAndIncrement(5);//加5歲 3 updater.compareAndSet(person, 30, 35)//如果一個人的年齡是30,設定為35。
4,ThreadLocal
對於多執行緒的Java程式而言,難免存在多執行緒競爭資源的情況。對於競爭的資源,解決的方式往往分為以時間換空間或以空間換時間兩種方式。
1,後者的做法是將一份資源複製成多份,佔用多份空間,但是每個執行緒自己訪問自己的資源,從而消除競爭,這種做法是ThreadLocal的做法,它雖然消除了競爭,但它是通過資料隔離的方法實現的,所以被隔離的各份資料是無法同步的,本節就要介紹這種做法。
2,也有很多資源是無法複製成多份或者不適合複製成多份的,如印表機資源。因此以時間換空間的做法就是隻有一份資源,大家按照一定的順序序列的去訪問這個資源。這種方式的主要做法,就是在資源上加鎖,加鎖的方法,將在後面第9節介紹。
示例
下面通過一個典型的ThreadLocal的應用案例作為入口,來分析ThreadLocal的原理和用法(更詳細程式碼請參考《Java併發程式設計:深入剖析ThreadLocal》http://www.cnblogs.com/dolphin0520/p/3920407.html):
設想下面的場景:
編寫一個數據庫聯結器(或 http session管理器),要求多個執行緒能夠連線和關閉資料庫,優先考慮下面的方案:
1 class ConnectionManager { 2 private static Connection connect = null; 3 public static Connection openConnection() { 4 if(connect == null){ 5 connect = DriverManager.getConnection(); 6 } 7 return connect; 8 } 9 public static void closeConnection() { 10 if(connect!=null) 11 connect.close(); 12 } 13 }
這個方案中,多個執行緒公用ConnectionManager.openConnection()和ConnectionManager.closeConnnection(),由於沒有同步控制,所以很容易出現併發問題,比如,同時建立了多個連線,或者執行緒1openConnection時,執行緒2恰好在執行closeConnection。
解決這個問題有兩種方案:
1,對connectionManager中openConnection和closeConection加synchronized強制同步。這種方案解決了併發,卻帶來了新問題,由於synchronized導致了同一只可只有一個執行緒能訪問被鎖物件,所以其它執行緒只能等待。
2,去掉ConnectionManager中的static,使得每次訪問Connectionmanager,都必須new一個物件,這樣每個執行緒都用自己的獨立物件,相互不影響。eg:
1 public void insert() { 2 ConnectionManager connectionManager = new ConnectionManager(); 3 Connection connection = connectionManager.openConnection(); 4 5 //使用connection進行操作 6 7 connectionManager.closeConnection(); 8 }
這個確實解決了併發,並且也可以多執行緒同步執行,但是它存在嚴重的效能問題,每執行一次操作,就需要new一個物件然後再銷燬。
ThreadLocal的引入,恰當的解決了上面的問題,ThreadLocal不是執行緒,它是一種變數,不過,它是執行緒變數的副本,它是一個泛型物件,例如,執行緒A建立時,初始化了一個物件user,那麼ThreadLocal<User> userLocal就是user線上程A中的一個副本,userLocal中的值在初始時與user相同,但是線上程A執行過程中,userlocal的任何變化不會同步到user上,不會影響user的值。
如果採用ThreadLocal,上面的資料庫連線管理器問題的解決方案是:
1 class ConnectionManager { 2 private static ThreadLocal<Connection> connectionHolder = new ThreadLocal<Connection>() { 3 public Connection initialValue() { 4 return DriverManager.getConnection(DB_URL); 5 } 6 }; 7 public static Connection getConnection() { 8 return connectionHolder.get(); 9 } 10 11 public static void closeConnection() { 12 if(connectionHolder.get()!=null) 13 connectionHolder.get().close(); 14 } 15 }
ThreadLocal的方法
ThreadLocal提供的方法很簡單,主要有:
public T get() { }public void set(T value) { }public void remove() { }protected T initialValue() { }
ThreadLocal的原理
分析ThreadLocal的原始碼(分析過程參考這裡:http://www.cnblogs.com/dolphin0520/p/3920407.html),可得,ThreadLocal的原理是:
1,在每個執行緒Thread內部有一個ThreadLocal.ThreadLocalMap型別的成員變數threadLocals,這個threadLocals就是用來儲存實際的變數副本的,鍵值為當前ThreadLocal變數,value為變數副本(即T型別的變數)。
2,初始時,在Thread裡面,threadLocals為空,當通過ThreadLocal變數呼叫get()方法或者set()方法,就會對Thread類中的threadLocals進行初始化,並且以當前ThreadLocal變數為鍵值,以ThreadLocal要儲存的副本變數為value,存到threadLocals。
3,注意,一般在get之前,需要先執行set(),以保證threadlocals中有值,如果在get()之前,沒有執行過set(),則ThreadLocal會自動呼叫setInitialValue()方法,setInitialValue()的原始碼是這樣的:
1 private T setInitialValue() { 2 T value = initialValue(); 3 Thread t = Thread.currentThread(); 4 ThreadLocalMap map = getMap(t); 5 if (map != null) 6 map.set(this, value); 7 else 8 createMap(t, value); 9 return value; 10 }
它先取出當前執行緒的ThreadLocalMap,即threadLocals變數,然後將value set進去,所以,如果沒有提前執行過set方法,initialValue()預設返回的又是null,所以可能導致執行過程中出現NPE。建議最好在宣告ThreadLocal變數時,重寫initialValue()方法,這樣即使沒有提前執行set,也能有個初始值(如前面ConnectionHolder中的程式碼)。
4,然後在當前執行緒裡面,如果要使用副本變數,就可以通過get方法在threadLocals裡面查詢。
ThreadLocal泛型的變數型別,不能是基本資料型別,只能是類,如果一定要將基本上資料型別做泛型引數,則可以採用Integer、Long、Double等類。
使用ThreadLocal的步驟
1,、在多執行緒的類(如ThreadDemo類)中,建立一個ThreadLocal<Object>對物件xxxLocal,用來儲存執行緒間需要隔離處理的物件xxx。
2、在ThreadDemo類中,建立一個獲取要隔離訪問的資料的方法getXxx(),在方法中判斷,若ThreadLocal物件為null時候,應該new()一個隔離訪問型別的物件,並強制轉換為要應用的型別。
3、在ThreadDemo類的run()方法中,通過getXxx()方法獲取要操作的資料,這樣可以保證每個執行緒對應一個數據物件,在任何時刻都操作的是這個物件。
ThreadLocal實現變數副本的方法
ThreadLocal實現變數副本,並沒有真的將原來的變數clone一份出來,而是採用了一種很靈活的方法,假設對每個單獨的執行緒ThreadA而言,當前ThreadLocal為localXx(這是key),初始外部變數為va(這是value):
1,第一次執行set時,new了一個Entry(localXx, va),並新增到localXx的ThreadLocalMap中,此時,Entry.value的引用就是指向va的強引用;
2,此時如果執行localXx.get(),會得到va
3,此時,如果在當前執行緒ThreadA直接對va執行set操作,仍然會更新外部變數va的值,但如果在另外一個執行緒ThreadB中希望對va進行操作,則由於此時ThreadB直接執行get得到的是null,所以無法訪問va,除非我們將va宣告為final的,並set到ThreadB中;
3,後續再進行set時,比如set進來的新值為va1,則直接替換Entry中的value,得到Entry(localXx, va1),此時原來的va在ThreadLocal這裡,已經得到釋放了,當前ThreadLocal跟原來的va已經沒有任何關係了。
4,如果此時再執行get操作,得到的就是新的va1;
從上面的步驟可以看出,ThreadLocal只是用原變數va做為初始值,但是它並未真的複製va,後續執行ThreadLocal.set之後,ThreadLocal中存放的已經是新set的物件了;
這也是為什麼ThreadLocal只能對類物件有效的原因了,因為它的set,改變的是value的引用。
具體例子可以參考下面的程式碼:
下面的例子中User包含兩個屬性:name、age,重寫了toString方法;
1 public class ThreadLocalTest { 2 ThreadLocal<User > userLocal = new ThreadLocal <User>(); 3 public void set(User user) { 4 userLocal.set(user); 5 } 6 public User get() { 7 return userLocal.get(); 8 } 9 public static void main( String[] args) throws InterruptedException { 10 final ThreadLocalTest test = new ThreadLocalTest(); 11 final User user1 = new User( "AAA", 5 );//注意這個user1被宣告成final的了 12 test.set(user1); 13 System.out.println(test.get()); //這裡得到的是user1的初始值:AAA,5 14 Thread thread1 = new Thread() { 15 public void run() { 16 test.set(user1); 17 test.get().setName( "BBB");//這裡get()得到的是user1,所以會影響外部主執行緒 18 System.out.println(test.get()); //BBB,5 19 User user2 = new User("CCC" , 5); 20 test.set(user2); //這裡thread1的ThreadLocal.userLocal中儲存的值變為user2了,外部主執行緒中仍然是user1 21 System.out.println(test.get()); // CCC, 5 22 test.get().setName( "DDD");//這裡get()得到的是user2,不會影響外部主執行緒 23 System.out.println(test.get()); //DDD,5 24 }; 25 }; 26 thread1.start(); 27 thread1.join(); 28 // 這裡得到的值user1,已經在上面設定BBB的時候已經被更新過了 29 // 但是不會受thread中更新CCC和DDD的影響,所以這裡得到的是BBB,5 30 System.out.println(test.get()); 31 } 32 }
得到的結果為:
[AAA,5]
[BBB,5]
[CCC,5]
[DDD,5]
[BBB,5]
ThreadLocal的記憶體洩露問題
在第一次將T型別的變數value set到ThreadLocal時,它是將value set到ThreadLocalMap 中去的,但是需要注意ThreadLocalMap並不是Map介面的子類,它是一個ThreadLocal的內部類,其中的Entry是一種特殊實現:static class Entry extends WeakReference< ThreadLocal>
對ThreadLocal.ThreadLocalMap.Entry執行set操作時,如果以前這個Entry(key,value)不存在,則會new一個Entry。如果這個Entry已經存在,則直接替換Entry.value的引用為新的value;
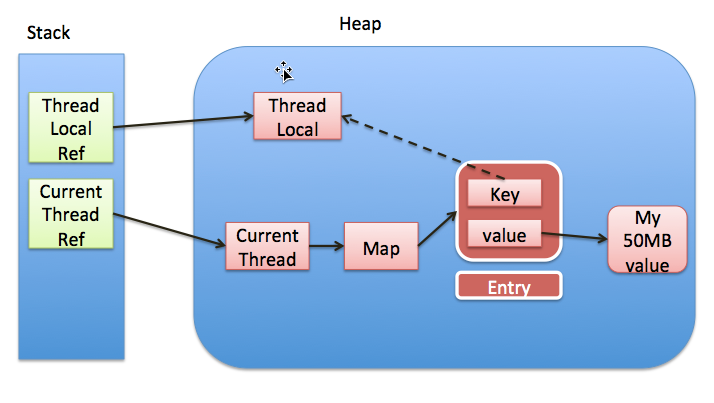
下面的分析和圖來自於:http://www.cnblogs.com/onlywujun/p/3524675.html
如下圖,每個thread中都存在一個map, map的型別是ThreadLocal.ThreadLocalMap. Map中的key為一個threadlocal例項. 這個Map的確使用了WeakReference(虛線),不過弱引用只是針對key. 每個key都弱引用指向threadlocal. 當把threadlocal例項置為null以後(或threadLocal例項被GC回收了,弱引用會被回收),沒有任何強引用指向threadlocal例項,所以threadlocal將會被gc回收. 但是,我們的value卻不能回收,因為存在一條從current thread連線過來的強引用. 只有當前thread結束以後, current thread就不會存在棧中,強引用斷開, Current Thread, Map, value將全部被GC回收.
所以得出一個結論就是隻要這個執行緒物件被gc回收,就不會出現記憶體洩露,但在threadLocal設為null和執行緒結束這段時間不會被回收的,就發生了我們認為的記憶體洩露。其實這是一個對概念理解的不一致,也沒什麼好爭論的。最要命的是執行緒物件不被回收的情況,這就發生了真正意義上的記憶體洩露。比如使用執行緒池的時候,執行緒結束是不會銷燬的,會再次使用的。就可能出現記憶體洩露。
注意:Java為了最小化減少記憶體洩露的可能性和影響,在ThreadLocal的get,set的時候都會執行一個for迴圈,遍歷其中所有的entiry,清除執行緒Map裡所有key為null的value。這也大大減小了出現記憶體洩露的風險。但最怕的情況就是,threadLocal物件設null了,開始發生“記憶體洩露”,然後使用執行緒池,這個執行緒結束,執行緒放回執行緒池中不銷燬,這個執行緒一直不被使用,或者分配使用了又不再呼叫get,set方法,那麼這個期間就會發生真正的記憶體洩露。
關於ThreadLocal記憶體洩露問題的資料,有興趣的可以參考這裡:http://liuinsect.iteye.com/blog/1827012
5,CountDownLatch和CyclicBarrier
CountDownLatch
CountDownLatch是一種Latch(門閂),它的操作類似於洩洪,或聚會。主要有兩種場景:
1,洩洪:即一個門閂(計數器為1)擋住所有執行緒,放開後所有執行緒開始執行。在門閂開啟之前,所有執行緒在池子裡等著,等著這個門閂的計數器減少到0,門閂開啟之後,所有執行緒開始同時執行;
這種場景一個典型例子是併發測試器(啟動多個執行緒去執行測試用例,一聲令下,同步開始執行,即下面的beginLatch):
1 int threadNum =10; //併發執行緒數 2 CountDownLatch beginLatch = new CountDownLatch(1 );// 用於觸發各執行緒同時開始 3 CountDownLatch waitLatch = new CountDownLatch(threadNum);// 用於等待各執行緒執行結束 4 ExecutorService executor = Executors. newFixedThreadPool(threadNum); 5 for (int i = 0; i < threadNum; i++) { 6 Callable<String> thread = new SubTestThread(beginLatch, waitLatch, method, notifier); 7 executor. submit(thread); 8 } 9 beginLatch.countDown(); // 開始執行! 10 waitLatch.await(); // 等待結束 11 private class SubTestThread implements Callable< String> { 12 private CountDownLatch begin; 13 private CountDownLatch wait; 14 private FrameworkMethod method; 15 public SubTestThread(CountDownLatch begin, CountDownLatch wait, FrameworkMethod method) { 16 this.begin = begin; 17 this.wait = wait; 18 this.method = method; 19 } 20 @Override 21 public String call() throws Exception { 22 try { 23 begin.await(); 24 runTest(method); 25 } catch (Exception e) { 26 throw e; 27 } finally { 28 wait.countDown(); 29 } 30 return null ; 31 } 32 }
2,聚會:即N個執行緒正在執行,一個門閂(計數器為N)擋住了後續操作,每個執行緒執行完畢後,計數器減1,當門閂計數器減到0時,表示所有執行緒都執行完畢(所有人到齊,party開始),可以開始執行後續動作了。
這種場景一個典型的例子是記賬彙總,即多個子公司的賬目,都要一一算完之後,才彙總到一起算總賬。上面例子中的waitLatch就是這樣的latch;
countDownLatch的真正原理在於latch是一種計數器,它的兩個方法分別是countDown()和await(),其中countDown()是減數1,await()是等待減到0,當每次呼叫countDown()時,當前latch計數器減1,減到0之前,當前執行緒的await()會一直卡著(阻塞,WAITING狀態),當計數器減少到0,喚醒當前執行緒,繼續執行await()後面的程式碼;
await(long timeout, TimeUtil unit)是另一個await方法,特點是可以指定wait的時間,
-如果超出指定的等待時間,await()不再等待,返回值為false;
-如果在指定時間內,計數器減到0,則返回值為true;
-如果執行緒在等待中被中斷或進入方法時已經設定了中斷狀態,則丟擲InterruptedException異常。
CyclicBarrier是一種迴環柵欄,它的作用類似於上面例子中的的waitLatch,即等到多個執行緒達到同一個點才繼續執行後續操作,如:
1 public class CyclicBarrierTest { 2 public static class ComponentThread implements Runnable { 3 CyclicBarrier barrier;// 計數器 4 int ID; // 元件標識 5 int[] array; // 資料陣列 6 // 構造方法 7 public ComponentThread(CyclicBarrier barrier, int[] array, int ID) { 8 this.barrier = barrier; 9 this.ID = ID; 10 this.array = array; 11 } 12 public void run() { 13 try { 14 array[ID] = new Random().nextInt(100); 15 System.out.println("Component " + ID + " generates: " + array[ID]); 16 // 在這裡等待Barrier處 17 System.out.println("Component " + ID + " sleep"); 18 barrier.await(); 19 System.out.println("Component " + ID + " awaked"); 20 // 計算資料陣列中的當前值和後續值 21 int result = array[ID] + array[ID + 1]; 22 System.out.println("Component " + ID + " result: " + result); 23 } catch (Exception ex) { 24 } 25 } 26 } 27 /** 28 * 測試CyclicBarrier的用法 29 */ 30 public static void testCyclicBarrier() { 31 final int[] array = new int[3]; 32 CyclicBarrier barrier = new CyclicBarrier(2, new Runnable() { 33 // 在所有執行緒都到達Barrier時執行 34 public void run() { 35 System.out.println("testCyclicBarrier run"); 36 array[2] = array[0] + array[1]; 37 } 38 }); 39 // 啟動執行緒 40 new Thread(new ComponentThread(barrier, array, 0)).start(); 41 new Thread(new ComponentThread(barrier, array, 1)).start(); 42 } 43 public static void main(String[] args) { 44 CyclicBarrierTest.testCyclicBarrier(); 45 } 46 }
可見,cyclicBarrier與countDownLatch的後一種使用方法(聚會)很像,其實兩者能夠達到相同的目的。區別在於,cyclicBarrier可以重複使用,也就是說,當一次cyclicBarrier到達彙總點之後,可以再次開始,每次cyclicbarrier減數到0之後,會觸發彙總任務執行,然後,會把計數器再恢復成原來的值,這也是“迴環”的由來。
CountDownLatch的作用是允許1或N個執行緒等待其他執行緒完成執行;而CyclicBarrier則是允許N個執行緒相互等待。
在實現方式上也有所不同,CountDownLatch是直接基於AQS編寫的,他的await和countDown過程,分別是一次acquireShared和releaseShared的過程;而cyclicBarrier是基於鎖、condition來實現的,讓當前執行緒阻塞,直到“有parties個執行緒到達barrier” 或 “當前執行緒被中斷” 或 “超時”這3者之一發生,當前執行緒才繼續執行。
(CyclicBarrier的原理,參考:Java多執行緒系列--“JUC鎖”10之 CyclicBarrier原理和示例:http://www.cnblogs.com/skywang12345/p/3533995.html?utm_source=tuicool)
6,訊號量
訊號量(Semaphore)與鎖類似,鎖是一次允許一次一個執行緒訪問(readWrite鎖除外),而訊號量用來控制一組資源有多個執行緒訪問,比如一個店鋪最多能接受5個客戶 ,有10個客戶要求訪問的話,那麼可以用訊號量來控制。
Semaphore可以控同時訪問的執行緒個數,通過 acquire() 獲取一個許可,如果沒有就等待,而 release() 釋放一個許可。
Semaphore類位於j