
[轉]Hive開發經驗問答式總結
本文轉載自:http://www.crazyant.net/1625.html
本文是自己開發Hive經驗的總結,希望對大家有所幫助,有問題請留言交流。
Hive開發經驗思維導圖
Hive開發經驗總結思維導圖(點選檢視大圖)
文件目錄
- 向Hive程式傳遞變數的方式
- 方法1:字串、正則、模板引擎等暴力方式替換
- 方法2:使用系統變數或者環境變數
- 方法3:在執行Hive命令時傳入hivevar和hiveconf
- Order by和Sort by的區別?
- 遇到SQL無法實現的邏輯該怎麼辦?
- 怎樣使用指令碼語言來擴充套件HIVE
- Hive任務執行很慢,但是匯入資料非常的快?
- 要讀取的資料是tar.gz的格式怎麼辦?
- 已經有了Partitoin,為什麼需要Bucket?
- 欄位型別設定的越寬泛當然更好了?
- 有哪些針對HIVE的優化方法
- Join時大表寫在最後
- 如果Join表資料量小,使用MapJoin
- 資料的思維,多使用臨時表
- 怎樣實現In語法
- 其他的一些技巧
- 刪除整個資料庫的方法
- 檢視資料表的詳細資訊
- Hive中可以執行shell和hadoop dfs命令
- union all在資料對齊中的使用
- NULL和數字相加的問題
- 增加資料到HIVE表的兩種方法
1. 向Hive程式傳遞變數的方式
使用Hive編寫程式最常用的方法是將Hive語句寫到檔案中,然後使用hive -f filename.hql來批量執行查詢語句。經常需要將外部引數傳入到hql語句中替換其中的變數來動態執行任務,比如動態設定資料庫名、表名、時間值、欄位序列等變數,以達到指令碼泛化執行的目的。
方法1:字串、正則、模板引擎等暴力方式替換
最簡單也最暴力的方式,是在hql檔案中設定{table_name}這樣的變數佔位符,然後使用排程程式比如shell、python、java語言讀取整個hql檔案到一個字串,替換其中的變數。然後使用hive -e cmd_str來執行該Hive命令字串。舉例程式碼如表格 1和表格 2所示。
表格 1 hive ql檔案內容
表格 1 hive ql檔案內容| 1 2 3 4 | # 來源:瘋狂的螞蟻www.crazyant.net use test; select * from student limit {limit_count}; |
表格 2 Python指令碼讀取、替換和執行Hive程式
表格 2 Python指令碼讀取、替換和執行Hive程式 Python| 1 2 3 4 5 6 7 8 | import os #step1: 讀取query.ql整個檔案的內容 ql_source=open("query.ql","r").read() #step2:替換其中的佔位符變數 ql_target=ql_source.replace("{limit_count}","10") #step3:使用hive -e的方法執行替換後的Hql語句序列 os.system("hive -e '%s'"%ql_target) |
方法2:使用系統變數或者環境變數
通常情況是使用shell來排程執行hive程式的,Hive提供了可以直接讀取系統env和system變數的方法,如表格 3所示。
表格 3 使用env和system讀取外部環境變數
表格 3 使用env和system讀取外部環境變數 MySQL| 1 2 3 4 5 6 | use test; --使用${env:varname}的方法讀取shell中export的變數 select * from student limit ${env:g_limit_count}; --使用${system:varname}的方法讀取系統的變數 select ${system:HOME} as my_home from student; |
這種方式比較好,比如在shell中可以配置整個專案的各種路徑變數,hive程式中使用env就可以直接讀取這些配置了。
方法3:在執行Hive命令時傳入hivevar和hiveconf
第3種方法是在用hive命令執行hive程式時傳遞命令列引數,使用-hivevar和-hiveconf兩種引數選項給該次執行傳入外部變數,其中hivevar是專門提供給使用者自定義變數的,而hiveconf則包括了hive-site.xml中配置的hive全域性變數。
表格 4 hivevar和hiveconf傳遞變數的方法
| hive -hivevar -f file | hive -hivevar tbname=’a’ -hivevar count=10 -f filename.hql |
| hive -hivevar -e cmd | hive -hivevar tbname=’a’ -hivevar count=10 -e ‘select * from ${hivevar:tbname} limit ${hivevar:count}’ |
| hive -hiveconf -f file | hive -hiveconf tbname=’a’ – hiveconf count=10 -f filename.hql |
| hive -hiveconf -e cmd | hive -hiveconf tbname=’a’ -hiveconf count=10 -e ‘select * from ${hivevar:tbname} limit ${hivevar:count}’ |
最經常使用的是env和-hivevar方法,前者直接在Hive指令碼中讀取shell export的變數,後者則對指令碼的當前執行進行引數設定。
2. Order by和Sort by的區別?
Hive基於HADOOP執行分散式程式,和普通單機程式不同的一個特點就是最終的資料會產生多個子檔案,每個reducer節點都會處理partition給自己的那份資料產生結果檔案,這導致了在HADOOP環境下很難對資料進行全域性排序,如果在HADOOP上進行order by全排序,會導致所有的資料集中在一臺reducer節點上,然後進行排序,這樣很可能會超過單個節點的磁碟和記憶體儲存能力導致任務失敗。
一種替代的方案則是放棄全域性有序,而是分組有序,比如不求全百度最高的點選詞排序,而是求每種產品線的最高點選詞排序。
表格 5 使用order by會引發全域性排序
| 1 | select * from baidu_click order by click desc; |
表格 6 使用distribute和sort進行分組排序
| 1 | select * from baidu_click distribute by product_line sort by click desc; |
distribute by + sort by就是該替代方案,被distribute by設定的欄位為KEY,資料會被HASH分發到不同的reducer機器上,然後sort by會對同一個reducer機器上的每組資料進行區域性排序。
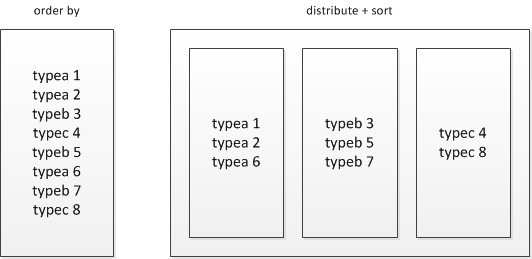
圖 2 order by是全域性有序而distribute+sort是分組有序
distribute+sort的結果是按組有序而全域性無序的,輸入資料經過了以下兩個步驟的處理:
1) 根據KEY欄位被HASH,相同組的資料被分發到相同的reducer節點;
2) 對每個組內部做排序
由於每組資料是按KEY進行HASH後的儲存並且組內有序,其還可以有兩種用途:
1) 直接作為HBASE的輸入源,匯入到HBASE;
2) 在distribute+sort後再進行orderby階段,實現間接的全域性排序;
不過即使是先distribute by然後sort by這樣的操作,如果某個分組資料太大也會超出reduce節點的儲存限制,常常會出現137記憶體溢位的錯誤,對大資料量的排序都是應該避免的。
3. 遇到SQL無法實現的邏輯該怎麼辦?
經常有Hive語句無法滿足的需求,比如將日期20140319轉換成2014Q1的季度字串、先按照KEY進行group然後取每個分組的limt N值等情景,最直接的實現是使用Hive的提供的Java UDF介面來實現。
Hive共提供了以下三種類型的UDF,分別對應處理不同的場景:
表格 7 Hive提供的3種UDF型別
| UDF型別 | 名稱 | 特點 | 舉例 |
| UDF | 使用者自定義函式 | 讀取一行,返回單個值 | abs求單行某欄位的絕對值 |
| UDAF | 使用者自定義聚合函式 | 讀取多行,返回單個值 | sum求多行的和 |
| UDTF | 使用者自定義表生成函式 | 讀取一行或多行,返回多行或這多列 | explode將一個欄位變成多行,每個元素是一行 |
這三類函式,最常用是UDF,其次是UDAF,而UDTF一般都不會遇到,如下是一個UDF的編寫與使用的完整例項,有以下幾個特點:
- 繼承apache.hadoop.hive.ql.exec.UDF父類;
- 覆蓋Text evaluate(Text str)方法;
表格 8 將日期轉換成季度字串的UDF
表格 8 將日期轉換成季度字串的UDF| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 | package myudf; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; /** * 來源:瘋狂的螞蟻 www.crazyant.net * UDF處理一行資料,產生一行資料 * step1:使用者需要繼承UDF父類;step2:需要實現evalute方法用於被Hive回撥; * @author www.crazyant.net */ public class DateToQuarter extends UDF { /** * 把YYMMDD形式的日期字串,轉換成'2014Q1'形式的季度字串; * @param str 輸入的日期 * @return '2014Q1'形式的季度字串值 */ public Text evaluate(Text str) { if (str == null) return null; //提取字串中的年份和月份 String year = str.toString().substring(0, 4); int month = Integer.parseInt(str.toString().substring(4, 6)); String quarter = ""; if (month >= 1 && month <= 3) { quarter = "Q1"; } else if (month >= 4 && month <= 6) { quarter = "Q2"; } else if (month >= 7 && month <= 9) { quarter = "Q3"; } else if (month >= 10 && month <= 12) { quarter = "Q4"; } // 要返回的2014Q1季度字串 return new Text(year + quarter); } } |
表格 9 Hive使用UDF的語法
表格 9 Hive使用UDF的語法| 1 2 3 4 5 6 7 | use test; add jar /home/users/crazyant/tmp/hive-udf-test-0.0.1-SNAPSHOT.jar; CREATE TEMPORARY FUNCTION datatoquarter as 'myudf.DateToQuarter.'; select sname, datatoquarter(enter_date) from student; |
UDF和UTAF是兩類非常常用的自定義函式,前者處理單個欄位,後者處理多行合併為1個欄位,如果熟悉JAVA可以用這種方法開發,優點是這些UDF程式會直接在MAP-REDUCE本身任務的JVM中執行效率較高,但是缺點在於開發複雜週期長,不如解釋性語言如Python的開發高效。
4. 怎樣使用指令碼語言來擴充套件HIVE
除了JAVA也可以使用其它語言來編寫Streaming程式擴充套件Hive,好處是開發速度快(省去了JAVA編譯、打包等步驟),缺點是Hadoop會多啟動一個子Streaming程序來和父Java程序來通訊,導致效能的降低。
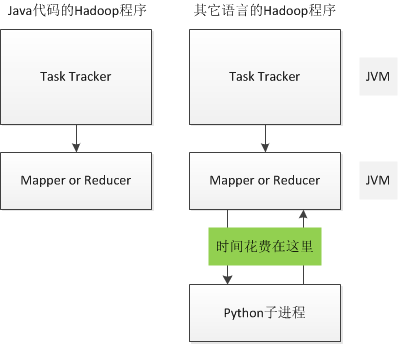
圖 3 Streaming UDF比JAVA UDF慢
開發Hive的Streaming程式和開發Hadoop的Streaming程式是相同的,都是從標準輸入中讀取按\t分割的資料,將\t分割的結果寫出到標準輸出中
表格 10 Hive Streaming的Python指令碼
表格 10 Hive Streaming的Python指令碼| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | # coding: utf8 ''' 來源:瘋狂的螞蟻 www.crazyant.net 將日期字串轉換成季度字串形式 輸入:YYYYMMDD或者YYYY-MM-DD的日期形式; 返回:YYYYQ1、YYYYQ2、YYYYQ3、YYYYQ4,季度字串形式 ''' import sys def get_date_year_quarter_str(pdate): '''獲取日期的季度字串形式 ''' (year_val, month_val) = (pdate[:4], pdate[4:6]) # 算出季度的序號 quarter_index = (int(month_val) - 1) / 3 + 1 quarter_str = "%sQ%d" % (year_val, quarter_index) return quarter_str def process_input(): '''主處理函式,每行最後一個欄位是日期''' for line in sys.stdin: line = str(line).strip() if not line: continue fields = line.split("\t") # 將YYYY-MM-DD轉換成YYYYMMDD date_val = str(fields[-1]).replace("-", "") # 重新組裝輸出欄位 output_fields = fields[:-1] + [get_date_year_quarter_str(date_val)] print '\t'.join(output_fields) if __name__ == "__main__": process_input() |
然後在Hive程式中可以這樣呼叫該Steaming指令碼
表格 11 Hive程式中呼叫Steaming的方法
表格 11 Hive程式中呼叫Steaming的方法| 1 2 3 4 5 6 7 8 9 10 | use test; -- 來源:瘋狂的螞蟻 www.crazyant.net -- step1:以絕對路徑的方式新增指令碼 add file /home/users/crazyant/workbench/streaming/date_to_quarter.py; -- step2:用TRANSFORM.. |