
sql的分組統計與group by 日期的處理
阿新 • • 發佈:2019-01-14
to_char(date,'yyyy-mm-dd')處理日期,之後to_char(date,'yyyy-mm-dd')
近幾天補oracle的sql知識,這塊記錄下sql的分組統計
1.簡單的分組統計
建立STUDENT表:
CREATE TABLE STUDENT(
"NAME" VARCHAR2(10 BYTE),
"MAJOR" VARCHAR2(10 BYTE),
"SCORE" NUMBER(5,2),
"SEX" VARCHAR2(3 BYTE)
);
錄入資料:
Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (1,'邱君','語文',70,'女'); Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (2,'小狗','語文',76,'男'); Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (3,'混蛋','語文',60,'男'); Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (4,'邱君','數學',81,'女'); Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (5,'混蛋','數學',90,'男'); Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (6,'小狗','數學',77,'男'); Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (7,'邱君','外語',98,'女'); Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (8,'小狗','外語',71,'男'); Insert into STUDENT (ID,NAME,MAJOR,SCORE,SEX) values (9,'混蛋','外語',88,'男');
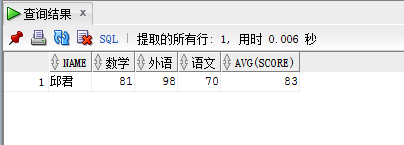
查詢語句(查找出有兩科分數大於80,並且平均平均成績大於80的同學):
SELECT name, SUM(CASE WHEN major = '數學' THEN score ELSE 0 END)數學 , SUM(CASE WHEN major = '外語' THEN score ELSE 0 END)外語 , SUM(CASE WHEN major = '語文' THEN score ELSE 0 END)語文, AVG(score) FROM student GROUP BY NAME HAVING AVG(score) > 80 AND SUM(CASE WHEN score > 80 THEN 1 ELSE 0 END) >= 2;
查詢結果:
2.group by 日期的處理:
select to_char(dt,'yyyy-mm-dd'),
SUM(case when re='勝' then 1 else 0 end)勝,
sum(case when re='負' then 1 else 0 end)負
from
test_tab
group by to_char(dt,'yyyy-mm-dd')
;to_char(date,'yyyy-mm-dd')處理日期,之後to_char(date,'yyyy-mm-dd')