
JAVA面試問題回答個人總結
JAVA面試問題回答個人總結
在此先感謝部落格上的各位大佬,基本上都是看了他們的博文提煉出來的答案,下面也有跳轉到他們博文的路徑,這裡做一個總結
如有侵權,請聯絡我,必定刪除
問題列表
1.資料庫的優化方法
1.選取最適用的欄位屬性
資料庫中的表越小,在它上面執行的查詢也就會越快,為了獲得更好的效能,在建立表的時候可以將表中欄位的寬度設得儘可能小,
例如,在定義郵政編碼這個欄位的時候,如果將其設為char(255),顯然給資料庫增加了不必要的空間,甚至使用VARCHAR也是多餘的,因為CHAR(6)就可以很好得完成任務了
2.使用連線(join)來代替子查詢
連線之所以更有效率一些,是因為MySQL不需要在記憶體中建立臨時表來完成這個邏輯上的需要兩個步驟的查詢工作
3.使用聯合(UNION)來代替手動建立的臨時表
它可以把需要使用臨時表的兩條或更多的select查詢合併到一個查詢中,在客戶端的查詢會話結束的時候,臨時表會被自動刪除,從而保證資料庫整齊、高效
4.事務
設想一下,可能會出現這種情況:第一個表更新成功後,資料庫出現異常,導致第二個表更新失敗,這樣就會造成資料的不完整,甚至會破壞資料庫中的資料
要避免這種情況,可以使用事務,它的作用是,要麼語句塊中的每條語句都成功,要麼都失敗
如下
BEGIN; INSERT INTO salesinfo SET CustomerID=14; UPDAT Einventory SET Quantity=11 WHERE item='book'; COMMIT;
5.鎖定表
LOCKTABL Einventory
WRITE
SELECT Quantity
FROMinventory WHEREItem='book';
...
UPDATE inventory
SET Quantity=11 WHERE Item='book';
UNLOCKTABLES
這裡,我們用一個select語句取出初始資料,通過一些計算,用update語句將新值更新到表中。包含有WRITE關鍵字的LOCKTABLE語句可以保證在UNLOCKTABLES命令被執行之前,不會有其它的訪問來對inventory進行插入、更新或者刪除的操作。
6.使用外來鍵
保證資料的關聯性
7.使用索引
join、where、orderby
8.優化的查詢語句
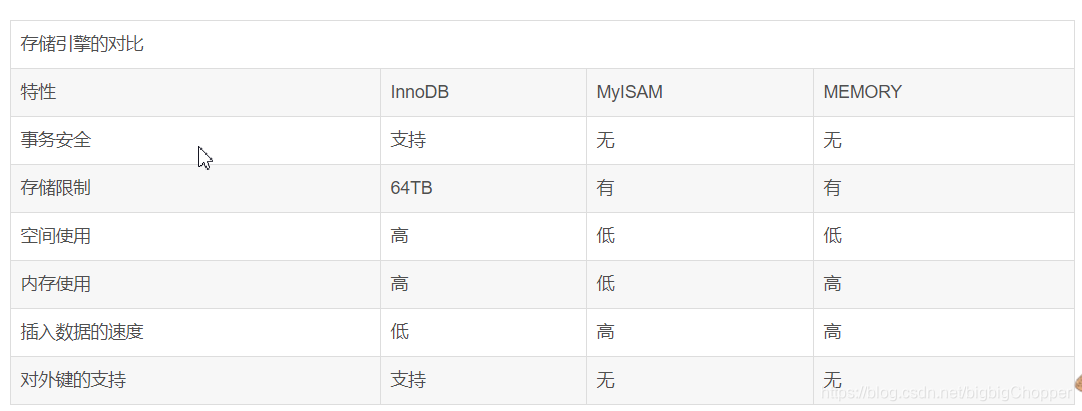
2.資料庫的三種引擎
1.InnoDB:支援事物處理,支援外來鍵,支援崩潰修復能力和併發控制。如果需要對事務的完整性要求比較高(如銀行),要求實現併發控制(如售票),那選擇InnoDB有很大的優勢。如果需要頻發的更新、刪除操作的資料庫,也可以選擇InnoDB,因為支援事務的提交和回滾
2.MyISAM:插入資料快,空間和記憶體使用比較低。如果表主要是用於插入新記錄和讀出記錄,那麼選擇MyISAM能實現處理高效率。如果應用的完整性、併發性要求比較低,也可以使用
3.MEMORY:所有的資料都在記憶體中,資料的處理速度很快,但是安全性不高。如果需要很快的讀寫速度,對資料的安全性要求較低,可以選擇MEMORY。它對錶的大小有要求,不能建立太大的表。
3.資料庫設計的原則:
第一正規化(確保每列保持原子性);
第二正規化(確保表中的每列都和主鍵相關);
第三正規化(確保每列都和主鍵列直接相關,而不是間接相關)。
4.資料庫索引原理
主流的RDBMS都是把平衡樹(b tree或者 b+ tree)當做資料表預設的索引資料結構的
事實上, 一個加了主鍵的表,並不能被稱之為「表」。一個沒加主鍵的表,它的資料無序的放置在磁碟儲存器上,一行一行的排列的很整齊, 跟我認知中的「表」很接近。
如果給表上了主鍵,那麼表在磁碟上的儲存結構就由整齊排列的結構轉變成了樹狀結構,也就是上面說的「平衡樹」結構
一個帶有主鍵的表即為聚集索引
非聚集索引和聚集索引一樣, 同樣是採用平衡樹作為索引的資料結構。
非聚集索引和聚集索引的區別在於, 通過聚集索引可以查到需要查詢的資料, 而通過非聚集索引可以查到記錄對應的主鍵值 , 再使用主鍵的值通過聚集索引查詢到需要的資料
不管以任何方式查詢表, 最終都會利用主鍵通過聚集索引來定位到資料, 聚集索引(主鍵)是通往真實資料所在的唯一路徑。
然而, 有一種例外可以不使用聚集索引就能查詢出所需要的資料, 這種非主流的方法 稱之為「覆蓋索引」查詢, 也就是平時所說的複合索引或者多欄位索引查詢。
//建立索引
create index index_birthday on user_info(birthday);
//查詢生日在1991年11月1日出生使用者的使用者名稱
select user_name from user_info where birthday = '1991-11-1'
這是一個非聚集索引
首先,通過非聚集索引index_birthday查詢birthday等於1991-11-1的所有記錄的主鍵ID值
然後,通過得到的主鍵ID值執行聚集索引查詢,找到主鍵ID值對就的真實資料(資料行)儲存的位置
最後,從得到的真實資料中取得user_name欄位的值返回, 也就是取得最終的結果
create index index_birthday_and_user_name on user_info(birthday, user_name);
這是一個雙欄位的覆蓋索引
通過非聚集索引index_birthday_and_user_name查詢birthday等於1991-11-1的葉節點的內容,然而, 葉節點中除了有user_name表主鍵ID的值以外, user_name欄位的值也在裡面, 因此不需要通過主鍵ID值的查詢資料行的真實所在, 直接取得葉節點中user_name的值返回即可。
關於SQL查詢語句在聚集索引、非聚集索引平衡樹中怎麼工作,可以在以下連結中檢視
詳細內容出處
5.TCP粘包與拆包
什麼是粘包和拆包,這裡舉個簡單的例子:
首先要知道,TCP的過程是 1.伺服器與客戶端建立連線; 2.客戶端向伺服器傳送包; 3.伺服器與客戶端斷開連線
那麼假設現在有兩種情況
1.客戶端與伺服器建立連線,客戶端向伺服器傳送了一個包,客戶端與伺服器斷開連線;
2.客戶端與伺服器建立連線,客戶端向伺服器傳送了兩個包,客戶端與伺服器斷開連線;
我們先看第一種情況,這種情況下,只要斷開了連線,那麼伺服器就知道客戶端像伺服器傳送包的過程已經完成了,接下來只要對包進行拆分解析就可以得出自己想要得到的資訊
問題在於第二種情況,這種情況下,又分為三種情況
1.伺服器端收到兩個包裹,第一個包裹包含客戶端傳送出去的第一個包的全部資訊,第二個包裹包含客戶端傳送出去的第二個包的全部資訊,這種情況比較好處理,伺服器只需要簡單地從緩衝區讀就可以了
2.伺服器端收到一個包裹,這個包裹包含了客戶端傳送出去的第一個包和第二個包的全部資訊,這也就是所謂的粘包,這種情況下伺服器就蒙了,它完全不知道哪裡到哪裡是第一個包裹的內容,哪裡到哪裡是第二個包裹的內容
3.伺服器端收到兩個包裹,第一個包裹包含了客戶端傳送出去的第一個包的部分資訊,第二個包裹包含了客戶端傳送出去的第一個包的餘下的資訊以及第二個包的全部資訊,這就是所謂的拆包
發生TCP粘包、拆包主要是由於下面一些原因:
1.應用程式寫入的資料大於套接字緩衝區大小,這將會發生拆包
2.應用程式寫入資料小於套接字緩衝區大小,網絡卡將應用多次寫入的資料傳送到網路上,這將會發生粘包
3.進行mss(最大報文長度)大小的TCP分段,當TCP報文長度-TCP頭部長度>mss的時候將發生拆包
4.接受方法不及時讀取套接字緩衝區資料,發生粘包
解決方法:
1.使用帶訊息頭的協議、訊息頭儲存訊息開始標識及訊息長度資訊,服務端獲取訊息頭的時候解析出訊息長度,然後向後讀取該長度的內容。
2.設定定長訊息,服務端每次讀取既定長度的內容作為一條完整訊息。
3.設定訊息邊界,服務端從網路流中按訊息編輯分離出訊息內容。
6.Hashmap
Hashmap結構如下
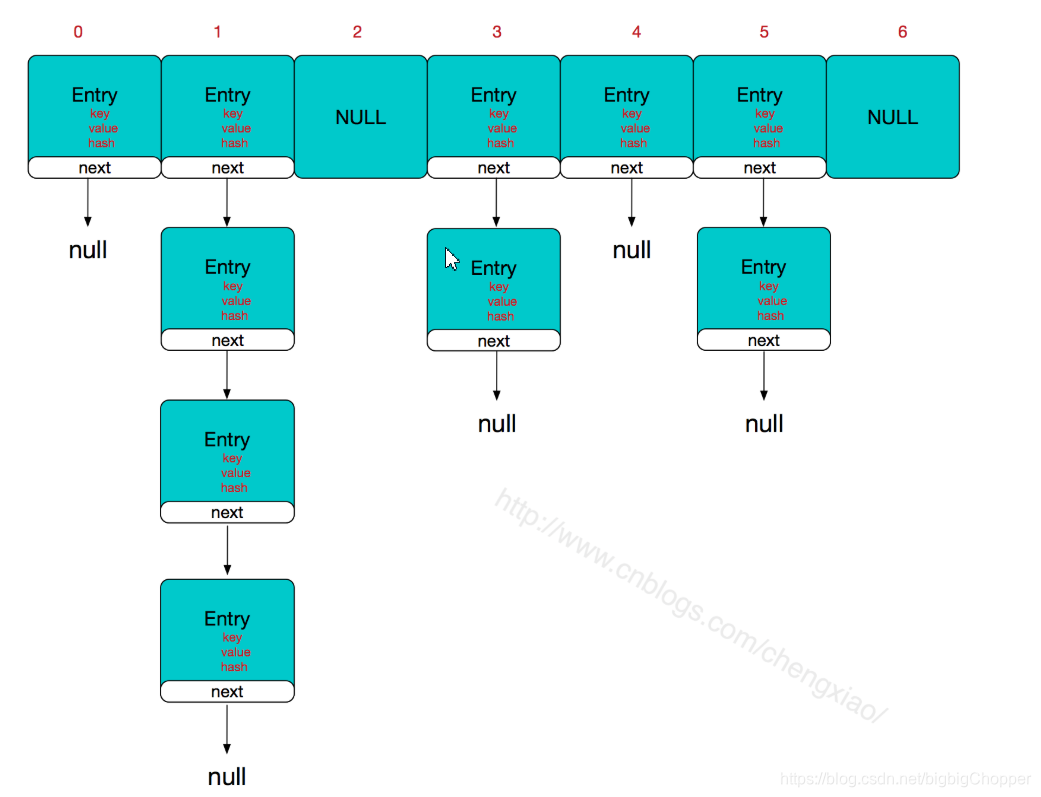
hashmap的結構是陣列+連結串列,它的主體是陣列,連結串列的存在是為了解決雜湊衝突,如果定位到的位置沒有連結串列,那麼查詢和新增的時間複雜度僅為O(1);如果定位到的位置含有連結串列,對於新增操作,其時間複雜度為O(n),首先遍歷連結串列,存在即覆蓋,否則新增;對於查詢操作來講,仍需遍歷連結串列,然後通過key物件的equals方法逐一比對查詢,時間複雜度也為O(n)
關於Hashmap:
(1) HashMap繼承於AbstractMap類,實現了Map介面。Map是"key-value鍵值對"介面,AbstractMap實現了"鍵值對"的通用函式介面。
(2) HashMap是通過"拉鍊法"實現的雜湊表。它包括幾個重要的成員變數:table, size, threshold, loadFactor, modCount。
table是一個Entry[]陣列型別,而Entry實際上就是一個單向連結串列。雜湊表的"key-value鍵值對"都是儲存在Entry陣列中的。
size是HashMap的大小,它是HashMap儲存的鍵值對的數量。
threshold是HashMap的閾值,用於判斷是否需要調整HashMap的容量。threshold的值=“容量*載入因子”,當HashMap中儲存資料的數量達到threshold時,就需要將HashMap的容量加倍。
loadFactor就是載入因子。
modCount是用來實現fail-fast機制的。
7.類載入過程
類載入過程:
類從被載入到JVM中開始,到解除安裝為止,整個生命週期包括:載入、驗證、準備、解析、初始化、使用和解除安裝,
其中類載入過程包括:載入、驗證、整備、解析、初始化五個階段
雙親委託模型:
一個類載入器收到一個類載入的請求時,不會立刻自己去嘗試載入這個類,而是把這個請求委託給它的父類載入器去完成,每一個層次的載入器都是如此,直至委託給最頂層的啟動類載入器為止,只有當父類載入器反饋自己無法完成這個載入請求時,子載入器才會嘗試自己去載入
雙親委託模型的好處:能夠有效確保一個類的全域性唯一性,當程式中出現多個限定名相同的類時,類載入器在執行載入時,始終只會載入其中一個類
8.JVM
JVM是基於棧執行的虛擬機器,除基本型別外的所有JAVA型別(類和介面)都是通過符號引用取得關聯的,而非顯式的基於記憶體地址的引用。類的例項通過使用者程式碼進行顯式建立,但卻通過垃圾回收機制自動銷燬。JVM通過明確清晰基本型別確保了平臺無關性,在JAVA class中的二進位制使用的是網路位元組序
常見錯誤:
記憶體溢位 out of memory,是指程式在申請記憶體時,沒有足夠的記憶體空間供其使用,出現out of memory;
記憶體洩露 memory leak,是指程式在申請記憶體後,無法釋放已申請的記憶體空間,一次記憶體洩露危害可以忽略,但記憶體洩露堆積後果很嚴重,無論多少記憶體,遲早會被佔光。
Java記憶體洩露根本原因
長生命週期的物件持有短生命週期物件的引用就很可能發生記憶體洩露,儘管短生命週期物件已經不再需要,但是因為長生命週期物件持有它的引用而導致不能被回收
9.java高併發簡單處理
1、儘量使用快取技術來做。使用者快取,頁面快取等一切快取,使用特定的機制進行重新整理。利用消耗記憶體空間來換取使用者的效率,同時減少資料庫的訪問次數。
2、把資料庫的查詢語句進行優化,一般複雜的SQL語句就不要使用ORM框架自帶的做法來寫,採用自己來寫SQL,例如hibernate的hql中的複雜語句就會很耗時。
3、優化資料庫的表結構,在關鍵字、主鍵、訪問率極高的欄位中加入索引。但儘量只是在數字型別上面加,因為使用欄位is null 的時候,索引的效果就會失效。
4、報表統計的模組,儘量使用定時任務執行,如果非要實時進行重新整理,那麼就可以採用快取來做資料。
5、可以使用靜態頁面的地方,儘量使用靜態頁面,減少頁面的解析時間。同時頁面中的圖片過多時,可以考慮把圖片單獨做成一個伺服器,這樣可以減少業務伺服器的壓力。
6、使用叢集的方式來解決單臺伺服器的效能問題。
7、把專案拆分成多個應用小型伺服器的形式來進行部署。採用資料同步機制(可以使用資料庫同步形式來做)達到資料一致性。
8、使用負載均衡模式來讓每一個伺服器資源進行合理的利用。
9、快取機制中,可以使用redis來做記憶體資料庫快取起來。也可以使用映象分擔,這樣可以讓兩臺伺服器進行訪問,提高伺服器的訪問量。
10.post和get的區別
1.get引數通過url傳遞,而post通過request body傳遞
2.get傳遞的引數長度有限制,而post沒有
3.get只能進行url編碼,而post可以進行多種編碼
4.get產生的url可以被bookmark,而post不可以
5.get請求會被瀏覽器主動cache,而post不會
6.get請求的引數會被完整地保留在瀏覽記錄裡,而post不會
7.get的引數型別只支援ASCII字元,而post沒有限制
8.get回退時是無害的,而post會再次提交請求
最本質的是:
對於GET方式的請求,瀏覽器會把http header和data一併傳送出去,伺服器響應200(返回資料);
而對於POST,瀏覽器先發送header,伺服器響應100 continue,瀏覽器再發送data,伺服器響應200 ok(返回資料)。
11.四次揮手最後服務端沒收到客戶端的ack怎麼辦
四次揮手,客戶端最後一次傳送ack給服務端後,不會立刻關閉連線,而是進入TIME_WAIT(等待)狀態,過了2MSL(報文最長壽命)後,才會斷開連線,如果過程中服務端沒有收到ack,客戶端將會重發
12.hashmap是執行緒安全的嗎?
不是的。
1.在hashmap做put操作的時候,會執行addEntry方法,如果執行緒A和執行緒B對同一個陣列同時addEntry,會同時產生新的頭結點,那麼他們其中一個的寫入就會使另一個的寫入丟失
2.在hashmap做刪除鍵值對的時候,多個執行緒同時操作同一個陣列位置,也都會先取得現在狀態下該位置儲存的頭結點,然後各自去進行計算操作,之後再把結果寫會到該陣列位置去,其實寫回的時候可能其他的執行緒已經就把這個位置給修改過了,就會覆蓋其他執行緒的修改
3. 當多個執行緒同時檢測到總數量超過門限值的時候就會同時呼叫resize操作,各自生成新的陣列並rehash後賦給該map底層的陣列table,結果最終只有最後一個執行緒生成的新陣列被賦給table變數,其他執行緒的均會丟失。而且當某些執行緒已經完成賦值而其他執行緒剛開始的時候,就會用已經被賦值的table作為原始陣列,這樣也會有問題。
13.如何實現hashmap執行緒安全
1.替換成Hashtable,Hashtable通過對整個表上鎖實現執行緒安全,因此效率比較低
2.使用Collections類的synchronizedMap方法包裝一下。方法如下:
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) 返回由指定對映支援的同步(執行緒安全的)對映
3.使用ConcurrentHashMap,它使用分段鎖來保證執行緒安全
14.單向連結串列
單鏈表的初始化
public class Node{
Object element; //資料域
Node next;
//結點構造
public Node(Object element){
this.element = element;
}
}
public class linkList{
Node head;
//初始化
public static void initLink(){
this.head = new Node(null);
}
}
單鏈表中增加結點
//尾插
public void addNodeT(Node node){
//判斷是否為第一次增加
if(head.next == null)
head.next = node;
else{
Node tmp = head;
//遍歷連結串列
while(tmp.next!=null)
tmp = tmp.next
tmp.next = node;
}
}
//頭插
public void addNodeH(Node node){
if(head.next == null)
head.next = node;
else{
node.next = head.next;
head.next = node;
}
}
插入結點到指定位置
public void insert(int index,Node node){
//判斷
if(index<1||indext>length()+1){
System.out.println("位置不合理");
return;
}
//判斷插入位置是否是第一個位置
else if(index==1){
//判斷此時連結串列是否為空
if(head.next == null)
head.next = node;
else
node.next = head.next;
head.next = node;
}
else{
int length = 1;
Node tmp = head;
while(tmp.next!=null){
if(index == length++){
//此時tmp為位置上一個結點
node.next = tmp.next;
tmp.next = node;
return;
}
tmp = tmp.next;
}
}
}
刪除結點
public static void delete(int index){
if(index<1||index>length()){
System.out.println("輸入位置不合理");
return;
}
else{
int length = 1;
Node tmp = head;
while(tmp.next!=null){
if(index == length++){
tmp.next = tmp.next.next;
return;
}
tmp = tmp.next;
}
}
}
15.二分查詢
public static int search(int[] arr,int key,int low,int high){
if(key<arr[low]||key>arr[high]||low>high){
return -1;
}
int middle = (low+high)/2;
if(key == arr[middle])
return middle;
else if(key>arr[middle])
return search(arr,key,middle+1,high);
else
return search(arr,key,low,middle);
}
16.查詢和排序時間複雜度比較
| 查詢方法 | 時間複雜度 |
|---|---|
| 順序查詢 | O(n) |
| 二分查詢(折半查詢) | O( n) |
| 二叉排序樹查詢 | O( n) |
| 分塊查詢 | O( n) |
| 雜湊表查詢 | O(1) |
| 排序方法 | 最差時間 | 平均時間複雜度 | 穩定性 |
|---|---|---|---|
| 氣泡排序 | O( ) | O( ) | 穩定 |
| 插入排序 | O( ) | O( ) | 穩定 |
| 選擇排序 | O( ) | O( ) | 穩定 |
| 二叉樹排序 | O( ) | O(n* ) | 不一定 |
| 快速排序 | O( ) | O(n* ) | 不穩定 |
| 堆排序 | O( ) | O(n* ) | 不穩定 |
| 希爾排序 | O( ) | O(n* )~ O( ) | 不穩定 |
17.氣泡排序
舉例說明:要排序陣列:int[] arr={6,3,8,2,9,1};
第一趟排序:
第一次排序:6和3比較,6大於3,交換位置: 3 6 8 2 9 1
第二次排序:6和8比較,6小於8,不交換位置:3 6 8 2 9 1
第三次排序:8和2比較,8大於2,交換位置: 3 6 2 8 9 1
第四次排序:8和9比較,8小於9,不交換位置:3 6 2 8 9 1
第五次排序:9和1比較:9大於1,交換位置: 3 6 2 8 1 9
第一趟總共進行了5次比較, 排序結果: 3 6 2 8 1 9
第二趟排序:
第一次排序:3和6比較,3小於6,不交換位置:3 6 2 8 1 9
第二次排序:6和2比較,6大於2,交換位置: 3 2 6 8 1 9
第三次排序:6和8比較,6大於8,不交換位置:3 2 6 8 1 9
第四次排序:8和1比較,8大於1,交換位置: 3 2 6 1 8 9
第二趟總共進行了4次比較, 排序結果: 3 2 6 1 8 9
第三趟排序:
第一次排序:3和2比較,3大於2,交換位置: 2 3 6 1 8 9
第二次排序:3和6比較,3小於6,不交換位置:2 3 6 1 8 9
第三次排序:6和1比較,6大於1,交換位置: 2 3 1 6 8 9
第二趟總共進行了3次比較, 排序結果: 2 3 1 6 8 9
第四趟排序:
第一次排序:2和3比較,2小於3,不交換位置:2 3 1 6 8 9
第二次排序:3和1比較,3大於1,交換位置: 2 1 3 6 8 9
第二趟總共進行了2次比較, 排序結果: 2 1 3 6 8 9
第五趟排序:
第一次排序:2和1比較,2大於1,交換位置: 1 2 3 6 8 9
第二趟總共進行了1次比較, 排序結果: 1 2 3 6 8 9
最終結果:1 2 3 6 8 9
由此可見:N個數字要排序完成,總共進行N-1趟排序,每i趟的排序次數為(N-i)次,所以可以用雙重迴圈語句,外層控制迴圈多少趟,內層控制每一趟的迴圈次數,即
程式碼:
public static void main(String[] args){
int[] arr = {6,3,8,2,9,1};
for(int i=0;i<arr.length()-1;i++)
for(int j=0;j<arr.length()-1-i;j++){
if(arr[j]>arr[j+1]){
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
}
18.插入排序
0.初始狀態 3,1,5,7,2,4,9,6(共8個數)
有序表:3;無序表:1,5,7,2,4,9,6
1.第一次迴圈,從無序表中取出第一個數 1,把它插入到有序表中,使新的數列依舊有序
有序表:1,3;無序表:5,7,2,4,9,6
2.第二次迴圈,從無序表中取出第一個數 5,把它插入到有序表中,使新的數列依舊有序
有序表:1,3,5;無序表:7,2,4,9,6
3.第三次迴圈,從無序表中取出第一個數 7,把它插入到有序表中,使新的數列依舊有序
有序表:1,3,5,7;無序表:2,4,9,6
4.第四次迴圈,從無序表中取出第一個數 2,把它插入到有序表中,使