
Java集合之Map集合
Map是我們平時使用非常頻繁的一種集合,因為Map 提供了一個更通用的元素儲存方法。Map 集合類用於儲存元素對(稱作“鍵”和“值”),其中每個鍵對映到一個值,其主要的實現類有HashMap,Hashtable,ConcurrentHashMap(JDK1.8)
- HashMap
HashMap 是一個散列表,它儲存的內容是鍵值對(key-value)對映。
這裡要先了解兩個概念:“初始容量” 和 “載入因子”。容量 是雜湊表中桶的數量,初始容量 只是雜湊表在建立時的容量。載入因子 是雜湊表在其容量自動增加之前可以達到多滿的一種尺度。當雜湊表中的條目數超出了載入因子與當前容量的乘積時,則要對該雜湊表進行 rehash 操作(即重建內部資料結構),從而雜湊表將具有大約兩倍的桶數
//我們先看其構造方法
//預設的加在因子
static final float DEFAULT_LOAD_FACTOR = 0.75f;
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
public HashMap(Map< //再看其新增的方法
transient Node<K,V>[] table;
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
//先計算key的hashCode。這裡進行了非空判斷。所以key值可以為null。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab;
Node<K,V> p;
int n, i;
//這裡先判斷 tab陣列是不為null。如果為null則呼叫resize()。生成預設長度的node陣列。
//如果陣列不為null會將原來陣列的資料複製進新的擴容陣列。程式碼太長不貼了。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//通過hash值判斷物件應該儲存在哪個 陣列位置。如果陣列索引位置為null則直接放入。
//如果不為null。放入陣列的連結串列結構中
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
上面的儲存過程看著很暈。結合別人的理解可以大致理解為。
- 校驗table是否為空或者length等於0,如果是則呼叫resize方法進行初始化
- 通過hash值計算索引位置,將該索引位置的頭節點賦值給p節點,如果該索引位置節點為空則使用傳入的引數新增一個節點並放在該索引位置
- 判斷p節點的key和hash值是否跟傳入的相等,如果相等, 則p節點即為要查詢的目標節點,將p節點賦值給e節點
- 如果p節點不是目標節點,則判斷p節點是否為TreeNode,如果是則呼叫紅黑樹的putTreeVal方法查詢目標節點
- 走到這代表p節點為普通連結串列節點,則呼叫普通的連結串列方法進行查詢,並定義變數binCount來統計該連結串列的節點數
- 如果p的next節點為空時,則代表找不到目標節點,則新增一個節點並插入連結串列尾部,並校驗節點數是否超過8個,如果超過則呼叫treeifyBin方法將連結串列節點轉為紅黑樹節點
- 如果遍歷的e節點存在hash值和key值都與傳入的相同,則e節點即為目標節點,跳出迴圈
- 如果e節點不為空,則代表目標節點存在,使用傳入的value覆蓋該節點的value,並返回oldValue
- 如果插入節點後節點數超過閾值,則呼叫resize方法進行擴容
資料結構如下
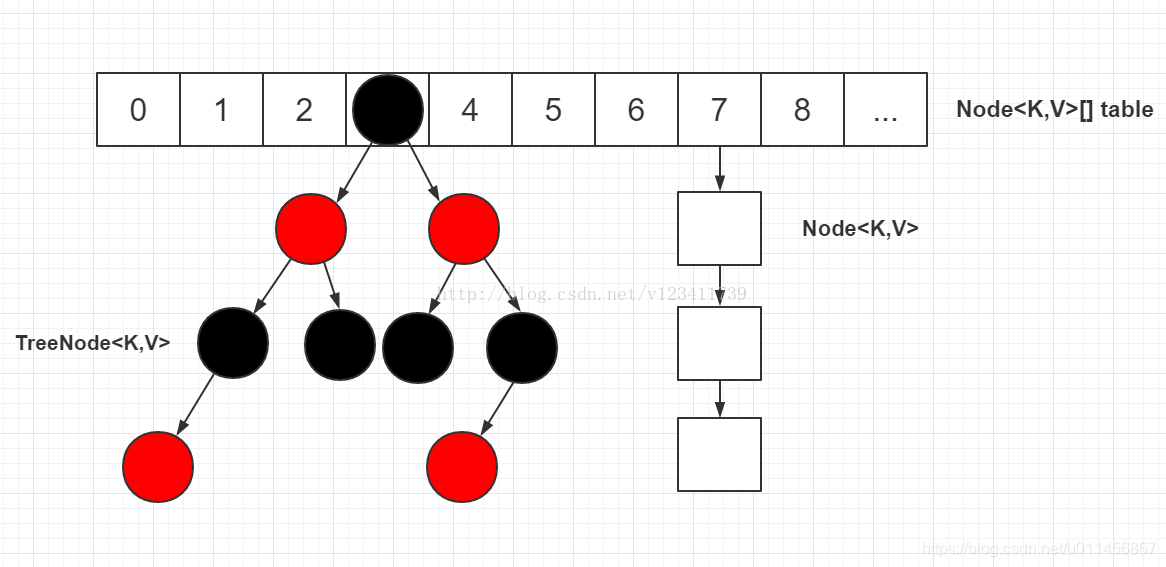
這裡再貼一個大神的擴容步驟總結
1.如果老表的容量大於0,判斷老表的容量是否超過最大容量值:如果超過則將閾值設定為Integer.MAX_VALUE,並直接返回老表(此時oldCap * 2比Integer.MAX_VALUE大,因此無法進行重新分佈,只是單純的將閾值擴容到最大);如果容量 * 2小於最大容量並且不小於16,則將閾值設定為原來的兩倍。
2.如果老表的容量為0,老表的閾值大於0,這種情況是傳了容量的new方法建立的空表,將新表的容量設定為老表的閾值(這種情況發生在新建立的HashMap第一次put時,該HashMap初始化的時候傳了初始容量,由於HashMap並沒有capacity變數來存放容量值,因此傳進來的初始容量是存放在threshold變數上(檢視HashMap(int initialCapacity, float loadFactor)方法),因此此時老表的threshold的值就是我們要新建立的HashMap的capacity,所以將新表的容量設定為老表的閾值。
3.如果老表的容量為0,老表的閾值為0,這種情況是沒有傳容量的new方法建立的空表,將閾值和容量設定為預設值。
4.如果新表的閾值為空,則通過新的容量 * 負載因子獲得閾值(這種情況是初始化的時候傳了初始容量,跟第2點相同情況,也只有走到第2點才會走到該情況)。
將當前閾值設定為剛計算出來的新的閾值,定義新表,容量為剛計算出來的新容量,將當前的表設定為新定義的表。
5.如果老表不為空,則需遍歷所有節點,將節點賦值給新表。
將老表上索引為j的頭結點賦值給e節點,並將老表上索引為j的節點設定為空。
如果e的next節點為空,則代表老表的該位置只有1個節點,通過hash值計算新表的索引位置,直接將該節點放在新表的該位置上。
6.如果e的next節點不為空,並且e為TreeNode,則呼叫split方法進行hash分佈。
如果e的next節點不為空,並且e為普通的連結串列節點,則進行普通的hash分佈。
如果e的hash值與老表的容量(為一串只有1個為2的二進位制數,例如16為0000 0000 0001 0000)進行位與運算為0,則說明e節點擴容後的索引位置跟老表的索引位置一樣(見例子1),進行連結串列拼接操作:如果loTail為空,代表該節點為第一個節點,則將loHead賦值為該節點;否則將節點新增在loTail後面,並將loTail賦值為新增的節點。
7.如果e的hash值與老表的容量(為一串只有1個為2的二進位制數,例如16為0000 0000 0001 0000)進行位與運算為1,則說明e節點擴容後的索引位置為:老表的索引位置+oldCap(見例子1),進行連結串列拼接操作:如果hiTail為空,代表該節點為第一個節點,則將hiHead賦值為該節點;否則將節點新增在hiTail後面,並將hiTail賦值為新增的節點。
8.老表節點重新hash分佈在新表結束後,如果loTail不為空(說明老表的資料有分佈到新表上原索引位置的節點),則將最後一個節點的next設為空,並將新表上原索引位置的節點設定為對應的頭結點;如果hiTail不為空(說明老表的資料有分佈到新表上原索引+oldCap位置的節點),則將最後一個節點的next設為空,並將新表上索引位置為原索引+oldCap的節點設定為對應的頭結點。
9.返回新表。
貼一個大神的詳細分解講解的很透徹:
https://blog.csdn.net/v123411739/article/details/78996181 - Hashtable
這個集合類在1.8中並無太大改變。主要是保證了執行緒的安全。這個我們在其方法中就可以看出。
先看構造方法
public Hashtable() {
this(11, 0.75f);
}
public Hashtable(int initialCapacity) {
this(initialCapacity, 0.75f);
}
public Hashtable(Map<? extends K, ? extends V> t) {
this(Math.max(2*t.size(), 11), 0.75f);
putAll(t);
}
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry<?,?>[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
//可以看出他的構造方法和hashMap提供的差不多。不同在於初始容量為11.負載因子均為0.75
//還有一個區別就是hashtable直接初始化了陣列。而hashMap是在放入第一個物件的時候呼叫擴容的方法進行陣列建立
再看其新增元素的方法
//方法加了同步鎖
public synchronized V put(K key, V value) {
// 所以value值不能為null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
@SuppressWarnings("unchecked")
Entry<K,V> entry = (Entry<K,V>)tab[index];
for(; entry != null ; entry = entry.next) {
if ((entry.hash == hash) && entry.key.equals(key)) {
V old = entry.value;
entry.value = value;
return old;
}
}
addEntry(hash, key, value, index);
return null;
}
//第一方法進行了同步鎖定,
//第二他沒有采用hashMap的陣列+連結串列+紅黑樹的結構。它採用的是傳統的資料+連結串列結構。
//先計算hash值。查出陣列位置再進行連結串列迴圈判斷看是否存在。如果存在且key值相等則覆蓋。
private void addEntry(int hash, K key, V value, int index) {
modCount++;
Entry<?,?> tab[] = table;
if (count >= threshold) {
// 如果容量超出。則進行擴容操作,擴容會進行hash值從新計算。重新放置位置
rehash();
tab = table;
hash = key.hashCode();
index = (hash & 0x7FFFFFFF) % tab.length;
}
// Creates the new entry.
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>) tab[index];
//將新的物件放入頭部。並將原來的頭部entry變為其next;
tab[index] = new Entry<>(hash, key, value, e);
count++;
}
//再看擴容程式碼
protected void rehash() {
int oldCapacity = table.length;
Entry<?,?>[] oldMap = table;
// overflow-conscious code
int newCapacity = (oldCapacity << 1) + 1;
if (newCapacity - MAX_ARRAY_SIZE > 0) {
if (oldCapacity == MAX_ARRAY_SIZE)
// Keep running with MAX_ARRAY_SIZE buckets
return;
newCapacity = MAX_ARRAY_SIZE;
}
Entry<?,?>[] newMap = new Entry<?,?>[newCapacity];
modCount++;
threshold = (int)Math.min(newCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
table = newMap;
//這個迴圈進行了連結串列的重新分配。
for (int i = oldCapacity ; i-- > 0 ;) {
for (Entry<K,V> old = (Entry<K,V>)oldMap[i] ; old != null ; ) {
Entry<K,V> e = old;
old = old.next;
int index = (e.hash & 0x7FFFFFFF) % newCapacity;
e.next = (Entry<K,V>)newMap[index];
newMap[index] = e;
}
}
}
移除方法
//也是加入了同步鎖
public synchronized V remove(Object key) {
Entry<?,?> tab[] = table;
int hash = key.hashCode();
int index = (hash & 0x7FFFFFFF) % tab.length;
//先定位陣列位置
@SuppressWarnings("unchecked")
Entry<K,V> e = (Entry<K,V>)tab[index];
//迴圈遍歷連結串列
for(Entry<K,V> prev = null ; e != null ; prev = e, e = e.next) {
//找到對映的節點。並且移除它的節點關聯
if ((e.hash == hash) && e.key.equals(key)) {
modCount++;
if (prev != null) {
prev.next = e.next;
} else {
tab[index] = e.next;
}
count--;
V oldValue = e.value;
e.value = null;
return oldValue;
}
}
return null;
}
- ConcurrentHashMap
主要解決了HashMap執行緒安全問題。雖然hashtable也是安全的但是。從其安全處理方式以及資料結構來看。效能都極大的被降低。所以不推薦使用。ConcurrentHashMap其資料結構和HashMap結構類似。我們通過原始碼分析主要檢視其如何保證執行緒安全。
//被關鍵字volatile 修飾。保證了多執行緒之間的可見性
transient volatile Node<K,V>[] table;
private transient volatile Node<K,V>[] nextTable;
private transient volatile CounterCell[] counterCells;
//再看它的新增方法
public V put(K key, V value) {
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
//所以key和value不能為null
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//如果陣列為null則初始化陣列
if (tab == null || (n = tab.length) == 0)
tab = initTable();
//如果hash對應的索引陣列頭部為null。則加入進去
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//如果雜湊值計算不正確無法找到對應的陣列所以。則進行調整。如果無法調整則無法加入進去
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//鎖定這個索引陣列儲存的物件,這樣不會影響其他連結串列的操作。提高了效能。保證了安全性
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
//遍歷連結串列查詢hash對應的節點
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash
相關推薦
Java基礎之Map集合概述
Map集合和Collection集合是兩個體系的集合,但是Collection集合的子類Set集合中兩個子類HashSet,TreeSet的底層資料結 構和Map集合子類的HashMap,TreeMap的對應相同。
HashMap底層資料結構是雜湊表,要保證元
Java集合之Map集合
Map是我們平時使用非常頻繁的一種集合,因為Map 提供了一個更通用的元素儲存方法。Map 集合類用於儲存元素對(稱作“鍵”和“值”),其中每個鍵對映到一個值,其主要的實現類有HashMap,Hashtable,ConcurrentHashMap(JDK1.8)
HashMa
java集合之Map
map 增強for循環 keyset map.entry ear 覆蓋 integer pre 形式 1. Map集合之基礎增刪查等功能
1 public class Demo1_Map {
2
3 /*
4 * Map集合是以鍵值對的形式
Java 集合之 Map(轉載)
iter 估算 做的 sortedmap 的區別 復雜度 detail 四種 測試環境
原文鏈接 :http://www.importnew.com/20386.html
Map 就是另一個頂級接口了,總感覺 Map 是 Collection 的子接口呢。Map 主
java之Map集合遍歷幾種方法
package cn.com.javatest.collection;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
/**
* java之Map集合遍歷幾種方法
*
* @author:
thinking in java (十八) ----- 集合之Map(HashMap HashTable)總結
Map框架圖
Map概括
Map是鍵值對對映的抽象介面
AbstractMap實現了Map中的大部分介面,減少了Map實現類的重複程式碼
HashMap是基於拉鍊法實現的散列表,一般使用在單執行緒程式中
HashTable是基於拉鍊法
Java基礎系列(四十五):集合之Map
簡介
Map是一個介面,代表的是將鍵對映到值的物件。一個對映不能包含重複的鍵,每個鍵最多隻能對映到一個值。
Map 介面提供了三種collection檢視,允許以鍵集、值集或鍵-值對映關係集的形式檢視某個對映的內容。對映順序 定義為迭代器在對映的 collection 檢視上返回
黑馬程式設計師——Java集合框架(三)之Map集合、Collections與Arrays工具類
-----------android培訓、java培訓、java學習型技術部落格、期待與您交流!------------
Map集合
一、概述
Map集合儲存的元素是鍵值對,即將鍵和值一對一對往裡存,而且要保證鍵的唯一性。
問題思考:
1.如何保證鍵的唯一性?
【java程式設計】Map集合之TreeMap按學生姓名進行升序排序
import java.util.*;
/*要對鍵值對進行排序,只能用TreeMap來排序
HashMap底層是雜湊表,雜湊表是隨機的*/
class TreeMapDemo
{
public static void main(String[] args)
{
深入理解Java集合之Map
Map筆錄 Map 提供了一個更通用的元素儲存方法。 Map 集合類用於儲存元素對(稱作“鍵”和“值”),其中每個鍵對映到一個值。標準的Java類庫中包含了Map的幾種基本實現,包括HashMap、TreeMap、LinkedHashMap、WeakHashMap、Co
【Java集合之Map】HashMap、HashTable、TreeMap、LinkedHashMap區別
前言
Java為資料結構中的對映定義了一個介面java.util.Map,它有四個實現類,分別是HashMap、HashTable、LinkedHashMap和TreeMap。本節例項主要介紹這4中例項的用法和區別
幾種Map類結構
public clas
thymeleaf 學習之map集合便利
tro class 集合 set leaf map集合 dash getc text 一直以來,對於集合數據在頁面中的便利是不論前端還是後臺都會經常碰到的.這裏做的是map集合的便利.
我這裏所需要便利的map集合數據結構是:
map{
[
JAVA-初步認識-常用對象API(集合框架-Map集合-hashmap存儲自定義對象)
自定義 。。 成對 ... 都差不多 post 哈希表 equals方法 例子 一.
把前面講到的三個集合使用一下。
交代一下需求,學生是鍵,歸屬地是值。到底歸屬地是不是String,有待商榷。如果歸屬地比較簡單,用天津,上海....這些就是字符串。如果歸屬地比較復雜,北京
java基礎筆記(9)----集合之list集合
類型安全 sta clas bsp i++ 效率 contains 有序 void 集合
對於集合的理解,集合是一個容器,用於存儲和管理其它對象的對象
集合,首先了解所有集合的父接口----collection
特點:存儲任意object元素
方法
boolean add(
Java中的Map集合以及Map集合遍歷例項
文章目錄
一、Map集合
二、Map集合遍歷例項
一、Map集合
Map<K,V>k是鍵,v是值 1、 將鍵對映到值的物件,一
java中的Map集合
什麼是Map集合?
Map用於儲存具有對映關係的資料,Map集合裡儲存著兩組值,一組用於儲存Map的ley,另一組儲存著Map的value。
圖解
map集合的作用 和查字典類似,通過key找到對應的value,通過頁數找到對應的資訊。用學生類來說,key相當於學號,value
Java基礎(二)集合之LinkedList(集合第三篇)
1、LinkedList底層實現原理
LinkedList底層的資料結構是基於雙向迴圈連結串列的,且頭結點中不存放資料,如下:
從圖中可以看出,有頭節點和資料節點,頭節點是結構必須的,資料節點即是存放資料的節點。
每一個節點都有三個元素,一個是當前節點的資料,也就是data
java中使用Map集合判斷字串中字元出現次數
import java.util.HashMap;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
import java.util.Scanner;
import java.util.S
Java修煉之道--集合框架
前言
Java集合框架 (Java Collections Framework, JCF) 也稱容器,這裡可以類比 C++ 中的 STL,在市面上似乎還沒能找到一本詳細介紹的書籍。在這裡主要對如下部分進行原始碼分析,及在面試中常見的問題。
例如,在阿里面試常
Java基礎之List集合(包含JUC)學習程序(一)
Java中重要的集合包主要有Collection和map
複習collectioon,主要是List,Queue和Set
List
首先要知道List是一個介面,繼承自collection
其中定義了是元素有序並且可以重複的集合,被稱為序列,並且List允許存放