
讀書筆記-ZAB協議
本文屬於分散式系統學習筆記系列,上一篇筆記整理了paxos演算法,本文屬於原書第四章,梳理zookeeper的目標特性及ZAB協議。
1、介紹zookeeper
1.1ZooKeeper保證一致性特性
ZooKeeper是一個典型的分散式資料一致性的解決方案,分散式程式可以基於它實現諸如資料釋出/訂閱、負載均衡、命名服務、分散式協調通知、叢集管理、master選舉、分散式鎖、分散式佇列等功能。ZooKeeper可以保證如下分散式一致性特性。
1、順序一致性:
從同一個客戶端發起的事務請求,最終將嚴格按照其發起順序被應用到ZooKeeper中。
2、原子性:
更新操作要麼成功要麼失敗,沒有中間狀態。
3、單一檢視(Single system image):
不管客戶端連線哪一個伺服器,客戶端看到服務端的資料模型都是一致的(the same view of service)。
4、可靠性(Reliability):
一旦一個更新成功,那麼那就會被持久化,直到客戶端用新的更新覆蓋這個更新。
5、實時性(Timeliness):
Zookeeper僅保證在一定時間內,客戶端最終一定能夠從服務端讀到最新的資料狀態。
1.2Zookeeper設計目標
1.2.1簡單的資料模型
Zookeeper使得分散式程式能夠通過一個共享的、樹形結構的名字空間來進行相互協調。其有一系列的被稱為ZNODE的資料節點構成。類似於檔案系統,但是Zookeeper將全部資料都存放在記憶體中,以提高伺服器吞吐,減少延遲。
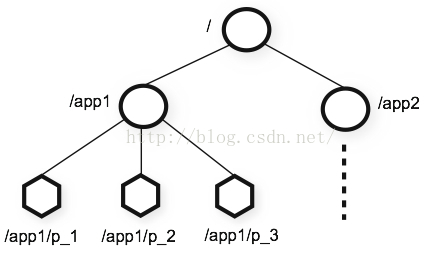
1.2.2構建叢集
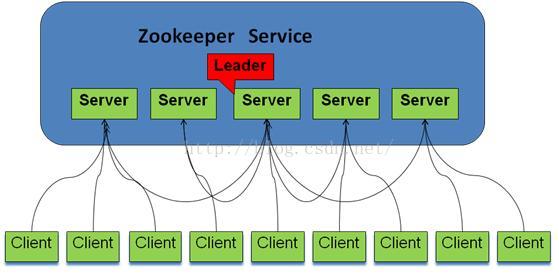
可以看出Zookeeper的實現是有Client、Server構成,Server端提供了一個一致性複製、儲存服務,Client端會提供一些具體的語義,如分散式鎖等。這裡不做過多說明,結合上圖:組成Zookeeper的叢集的的每臺機器都在記憶體中維護當前伺服器的狀態,並且每臺機器之間都互相保持著通訊,過半機器能夠正常工作,叢集就能對外提供服務。Zookeeper的client會選擇叢集內任意一臺機器建立TCP連線。
1.2.3:順序訪問
對於來自客戶端的每個更新請求,zookeeper會分配一個全域性唯一的遞增編號,這個編號反應了所有事物的操作先後順序,應用程式可以基於此實現更高層次的同步原語。
1.2.4:高效能
資料都在記憶體中存放,適合以讀為主的場景。
2、ZOOKEEPER的ZAB協議
2.1ZAB協議
ZooKeeper為高可用的一致性協調框架,並沒有完全採用paxos演算法,而是使用了ZAB(ZooKeeper Atomic Broadcast )原子訊息廣播協議作為資料一致性的核心演算法,ZAB協議是專為zookeeper設計的支援崩潰恢復原子訊息廣播演算法。
基於ZAB協議,zookeeper實現了一種基於主備模式的系統架構來保證叢集中各副本之間的資料一致性。具體的:ZooKeeper使用單一主程序Leader用於處理客戶端所有事務請求,採用ZAB協議將伺服器數狀態以事務形式廣播到所有Follower上,因此能很好的處理客戶端的大量併發請求(這裡我理解就是ZK通過使用TCP協議及一個事務ID來實現事務的全序特性,leader模式就是先到先執行解決因果順序);另一方面,由於事務間可能存在著依賴關係,ZAB協議保證Leader廣播的變更序列被順序的處理,一個狀態被處理那麼它所依賴的狀態也已經提前被處理;最後,考慮到住程序leader在任何時候可能崩潰或者異常退出,因此ZAB協議還要Leader程序崩潰的時候可以重新選出Leader並且保證資料的完整性;
協議核心如下:
所有的事務請求必須一個全域性唯一的伺服器(leader)來協調處理,叢集其餘的伺服器稱為follower伺服器。leader伺服器負責將一個客戶端請求轉化為事務提議(Proposal),並將該proposal分發給叢集所有的follower伺服器。之後leader伺服器需要等待所有的follower伺服器的反饋,一旦超過了半數的follower伺服器進行了正確反饋後,那麼leader伺服器就會再次向所有的follower伺服器分發commit訊息,要求其將前一個proposal進行提交。
2.2協議介紹
書上這塊寫的比較詳細,我簡單整理重點。上面我們介紹了協議的核心內容,可以總結出ZAB協議的兩個基本模式:訊息廣播和崩潰恢復。
2.2.1訊息廣播:
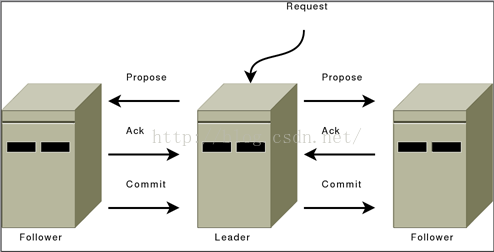
客戶端提交事務請求時Leader節點為每一個請求生成一個事務Proposal,將其傳送給叢集中所有的Follower節點,收到過半Follower的反饋後開始對事務進行提交,ZAB協議使用了原子廣播協議;在ZAB協議中只需要得到過半的Follower節點反饋Ack就可以對事務進行提交,這也導致了Leader幾點崩潰後可能會出現資料不一致的情況,ZAB使用了崩潰恢復來處理數字不一致問題;訊息廣播使用了TCP協議進行通訊所有保證了接受和傳送事務的順序性。廣播訊息時Leader節點為每個事務Proposal分配一個全域性遞增的ZXID(事務ID),每個事務Proposal都按照ZXID順序來處理;
之前我們我們介紹了2階段提交協議,ZAB協議有所不同簡化了協議:
- 去除了中斷邏輯,follower要麼ack,要麼拋棄Leader;
- leader不需要所有的Follower都響應成功,只要一個多數派ACK即可。
Follower收到proposal後,寫到磁碟,返回ACK。Leader收到大多數ACK後,廣播COMMIT訊息,自己也提交該訊息。Follower收到COMMIT之後,提交該訊息。
2.2.2崩潰恢復:
上面我們講了ZAB協議在正常情況下的訊息廣播過程,那麼一旦leader伺服器出現崩潰或者與過半的follower伺服器失去聯絡,就進入崩潰恢復模式。
崩潰恢復過程中,為了保證資料一致性需要處理特殊情況:已經被leader提交的proposal也能夠所有的follower提交,跳過已經被丟棄的事務proposal。針對這個要求,如果讓leader選舉演算法能保證選舉出來的leader伺服器擁有叢集中所有機器中編號最大(ZXID最大)的事務proposal,那麼就可以保證新選舉出來的leader伺服器一定擁有所有已提交的提案,省去了leader伺服器檢查proposal提交和丟棄的工作。
資料同步
完成了leader選舉這步,在正式接受新的事務請求之前,leader伺服器要確認事務日誌中的proposal是不是都已經被叢集過半的機器提交了,即是否完成了資料同步。
1. leader等待server連線;
2 .Follower連線leader,將最大的zxid傳送給leader;
3 .Leader根據follower的zxid確定同步點;
4 .完成同步後通知follower 已經成為uptodate狀態;
5 .Follower收到uptodate訊息後,又可以重新接受client的請求進行服務了。
ZAB協議中使用ZXID作為事務編號,ZXID為64位數字,低32位為一個遞增的計數器,每一個客戶端的一個事務請求時Leader產生新的事務後該計數器都會加1,高32位為Leader週期epoch編號,當新選舉出一個Leader節點時Leader會取出本地日誌中最大事務Proposal的ZXID解析出對應的epoch把該值加1作為新的epoch,將低32位從0開始生成新的ZXID;ZAB使用epoch來區分不同的Leader週期,能有效避免了不同的leader伺服器錯誤的使用相同的ZXID編號提出不同的事務proposal的異常情況,大大簡化了提升了資料恢復流程;
2.3問題描述
上面我們介紹了ZAB協議的大體內容及訊息廣播和崩潰恢復基本模式,原書還從系統模型、問題描述等不同角度介紹了ZAB協議,這裡只貼出來問題描述相關概念:
主程序週期:
ZooKeeper使用單一主程序Leader用於處理客戶端所有事務請求,採用ZAB協議將伺服器數狀態以事務形式廣播到所有Follower上;為了保證所有主程序廣播的事務的一致性,我們需要確保主程序僅當Zab層的恢復都已完成的情況下,才會開始傳送狀態變化訊息。為了達到這個目的,我們假定所有程序都實現了一個ready(e)的呼叫,用以讓Zab層來通知應用(主程序和所有備份複製程序),Zab已經可以開始廣播狀態變化了。ready呼叫同時會為變數instance設值,讓主程序決定它的例項值。例項值用於唯一標識當前主程序的的週期,在廣播的時候,主程序用例項值來設定事務標識號的epoch欄位———我們假定e的值做所有的主程序例項中是唯一的。例項的唯一性由Zab來保證。
事務:
把主程序將狀態變化傳播給備份程序,我們稱做事務。我們假設存在一個類似於 transaction(V,Z)這樣的函式呼叫,用來實現主程序對於狀態變更的廣播。主程序每次對於transaction呼叫包含<v, z>有兩個部分:事務的值v以及事務的標識z(或叫做zxid)。每個事務標識z=<e, c>,即z由兩部分組成,時間標識e和計數器c。我們採用epoch(z)來標識事務標識號的時間部分,counter(z)來標識事務標識號的計數器值。我們說,時間(epoch)e是先於時間e’,即e<e’。對於一個給定的主程序例項ρe,epoch(z)
= instance = e。對於每一個新的事務,我們會遞增計數器c。我們說事務標識號z先於事務標識號z’,即要麼epoch(z)< epoch(z’),或者epoch(z) == epoch(z’)但counter(z) < counter(z’)。
2.4演算法描述
我們從演算法角度來看ZAB協議,可以細分為三個階段:發現(discovery)、同步(sync)、廣播(Broadcast),之前我們把發現(discovery)與同步(sync)合併為恢復(recovery) 階段。

階段一 發現
Follower節點向準Leader推送FOllOWERINFO,該資訊中包含了上一週期的epoch,接受準Leader的NEWLEADER指令,檢查newEpoch有效性,準Leader要確保Follower的epoch與ZXID小於或等於自身的;詳細步驟如下:F1.1 follower F將自己最後接受的事務proposal的epoch值CEPOCH(F.p)傳送給準leader L。
L1.1 當接受到過半follower的CEPOCH(F.p)訊息後,準leader L會生成NEWEPOCH(e')訊息給這些過半的follower。
其中e'= max(epoch)+1;
F1.2 當follower接受到來自準leader L的NEWEPOCH(e')訊息後,如果其檢測到當前的CEPOCH(F.p)小於e',就會把CEPOCH(F.p)賦值為e',同時向這個準leader L反饋ACK訊息,訊息中包含了該follower的epoch CEPOCH(F.p)及歷史事務集合hf.
當Leader L接受到過半follower的確認訊息ack後,會從這過半的伺服器中選取一個follower F,使用其作為初始化事務集合Ie.
階段二 同步
在完成發現階段後,就進入同步階段。將Follower與Leader的資料進行同步,由Leader發起同步指令,最總保持叢集資料的一致性;
L2.1 leader L 將e' 及Ie''以NEWLEADER(e',Ie')訊息的形式傳送給所有的quorum中的follower。
F2.1 當follower接受到來自leader L的NEWLEADER(e',Ie')訊息後,如果follower發現自己的CEPOCH(F.p)≠e'時,直接接入下 一輪迴圈。
如果CEPOCH(F.p)=e',那麼follower會執行事務應用操作,最後會反饋給leader L。
L2.2 當leader L接受到超過半數的follower針對NEWLEADER(e',Ie')反饋訊息後,就會向所有的follower傳送commit訊息。
F2.2 當follower接受到來自leader的commit訊息後,會依次處理並提交所有所有Ie'中未處理的事務。
階段三 廣播
完成同步階段後,ZAB協議就可以正式接受客戶端新的事務請求,並進行訊息廣播流程。
leader收到一個request後,會生成一個propose。然後執行兩階段提交.Leader節點為每一個Follower節點分配一個佇列按事務ZXID順序放入到佇列中,且根據佇列的規則FIFO來進行事務的傳送。Follower節點收到事務Proposal後會將該事務以事務日誌方式寫入到本地磁碟中,成功後反饋Ack訊息給Leader節點,Leader在接收到過半Follower節點的Ack反饋後就會進行事務的提交,以此同時向所有的Follower節點廣播Commit訊息,Follower節點收到Commit後開始對事務進行提交;
這塊參見上面的2.2那個廣播流程圖,不展開。
下圖就是整個過程中各個程序之間的訊息收發情況,
圖:
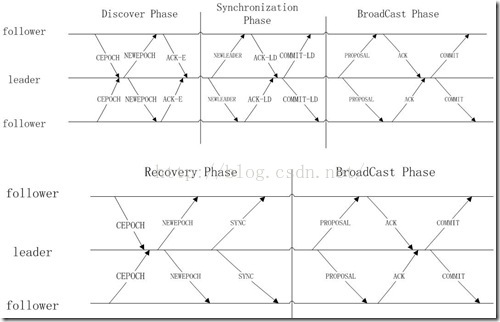
CEPOCH = Follower sends its last promise to the prospective leader
NEWEPOCH = Leader proposes a new epoch e'
ACK-E = Follower acknowledges the new epoch proposal
NEWLEADER = Prospective leader proposes itself as the new leader of epoch e'
ACK-LD = Follower acknowledges the new leader proposal
COMMIT-LD = Commit new leader proposal
PROPOSE = Leader proposes a new transaction
ACK = Follower acknowledges leader proosal
COMMIT = Leader commits proposal
書上只介紹了三個階段,這裡補充下選舉,選舉有多種方法,這裡只介紹預設的fast leader election:
限制條件:
就是之前崩潰恢復哪裡提到的,為了保證資料一致性,election階段必須確保選出的Leader具有最大ZXID,暗含的規則就是能看到所有歷史的commited 事務。
那麼fast leader election是如何選擇出一個擁有highest lastZxid的leader?
選舉流程:
1. 每個Follower都向其他節點發送選自身為Leader的Vote投票請求,等待回覆;
2. Follower接受到的Vote如果比自身的大(ZXID更新)時則投票,並更新自身的Vote,否則拒絕投票;
3. 每個Follower中維護著一個投票記錄表,當某個節點收到過半的投票時,結束投票並把該Follower選為Leader,投票結束;
2.5執行分析:
ZAB協議中存在著三種狀態,每個節點都屬於以下三種中的一種:
1. Looking:系統剛啟動時或者Leader崩潰後正處於選舉狀態
2. Following:Follower節點所處的狀態,Follower與Leader處於資料同步階段;
3. Leading:Leader所處狀態,當前叢集中有一個Leader為主程序;
ZooKeeper啟動時所有節點初始狀態為Looking,這時叢集會嘗試選舉出一個Leader節點,選舉出的Leader節點切換為Leading狀態;當節點發現叢集中已經選舉出Leader則該節點會切換到Following狀態,然後和Leader節點保持同步;當Follower節點與Leader失去聯絡時Follower節點則會切換到Looking狀態,開始新一輪選舉;在ZooKeeper的整個生命週期中每個節點都會在Looking、Following、Leading狀態間不斷轉換;
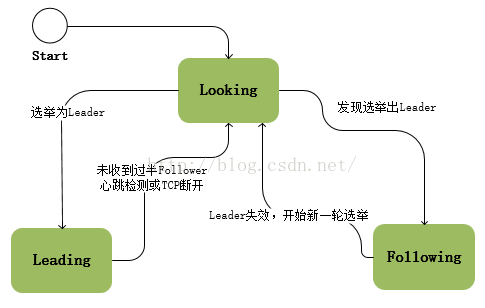
選舉出Leader節點後ZAB進入原子廣播階段,這時Leader為和自己同步的每個節點Follower建立一個操作序列,一個時期一個Follower只能和一個Leader保持同步,Leader節點與Follower節點使用心跳檢測來感知對方的存在;當Leader節點在超時時間內收到來自Follower的心跳檢測那Follower節點會一直與該節點保持連線;若超時時間內Leader沒有接收到來自過半Follower節點的心跳檢測或TCP連線斷開,那Leader會結束當前週期的領導,切換到Looking狀態,所有Follower節點也會放棄該Leader節點切換到Looking狀態,然後開始新一輪選舉;
3、ZAB與paxos區別與聯絡
作者認為ZAB不是paxos的一個典型實現,而是設計目標不同。
聯絡:
- 兩者都存在類似於Leader程序的角色,來負責協調多個follower程序執行。
- Leader都會等待超過半數的follower做出正確的反饋後,才將一個提案提交。
ZAB還額外引入了同步階段。Paxos演算法的確是不關心請求之間的邏輯順序,而只考慮資料之間的全序,但很少有人直接使用paxos演算法,都是進行簡化或者改進。可以認為ZAB是一種paxos演算法的簡化。
*******************************************************************************************
參考:
http://www.solinx.co/archives/435?utm_source=tuicool&utm_medium=referral
http://my.oschina.net/zhengyang841117/blog/186676
相關推薦
讀書筆記-ZAB協議
本文屬於分散式系統學習筆記系列,上一篇筆記整理了paxos演算法,本文屬於原書第四章,梳理zookeeper的目標特性及ZAB協議。 1、介紹zookeeper 1.1ZooKeeper保證一致性特性 ZooKeeper是一個典型的分散式資料一致性的解決方案,分散式程式可以
【讀書筆記】計算機網絡1章:課程介紹、協議、分層
視頻 打印 http dns 物理層 size cli 電子商務 ann 改變 這是我在Coursera上的學習筆記。課程名稱為《Computer Networks》。出自University of Washington。 因為計算機網絡才誕生不久
linux 高性能讀書筆記之應用層協議HTTP相關小知識
原理 連接 設置代理 客戶 代理服務 lin 不同 火墻 筆記 ####HTTP連襟:傳輸層協議默認使用TCP小知識:1.正向服務器要求客戶端自己設置代理服務器的地址。客戶端每次的請求都將直接發送到該代理服務器,並且由代理服務器來請求目標資源(常用於防火墻內的局域網機器要訪
PCIE協議解析 synopsys IP loopback 讀書筆記(1)
overview 沒有 發出 調試 期望 pci 附加 error edit 1 Overview Core支持單個Pcie內核的Loopback功能,該功能主要為了做芯片驗證,以及在沒有遠程接收器件的情況下完成自己的回環。同時,Core也支持有遠程接收器件的lo
《從 PAXOS 到 ZOOKEEPER:分散式一致性原理與實踐》讀書筆記[1]——一致性協議
1 分散式 1.1 定義 分散式系統是一個硬體或軟體元件分佈在不同的網路計算機上,彼此之間僅僅通過訊息傳遞進行通訊和協調的系統 1.2 特點 分佈性、對等性、併發性、缺乏全域性時鐘、故障總是會發生 2 CAP 和 BASE 2.1 CAP CAP 理論:一個分散式系統不可
HTTP圖解讀書筆記(第二章 簡單的HTTP協議)
一、HTTP協議用於客戶端和服務端的通訊 二、通過請求和響應的交換完成通訊 請求報文由請求方法、請求URL、協議版本、可選的請求首部欄位和內容實體組成 響應報文放由協議版本、狀態碼、用於解釋狀態碼原因的短語、可選的響應首部欄位和實體主體組成 三、HTTP協議是不儲存狀態的
軟考-架構師-第四章-計算機網路 第一節 網路架構與協議(讀書筆記)
版權宣告 主要針對希賽出版的架構師考試教程《系統架構設計師教程(第4版)》,作者“希賽教育軟考學院”。完成相關的讀書筆記以便後期自查,僅供個人學習使用,不得用於任何商業用途。 版權宣告 第一節 網路架構與協議 說明
Http協議(圖解http讀書筆記)
什麼是Http協議: Http協議是用於客戶端與伺服器通訊的一種協議,首先它明確地區分了哪端是客戶端哪端是伺服器,協議規定了先發起請求的是客戶端,換句話說一定是從客戶端開始建立的通訊,服務端在接到請求之前不會主動和客戶端建立聯絡。然後,它規定了客戶端與服務端相
TCP/IP讀書筆記之動態選路協議
使用靜態選路,用預設方式生成路由表項或者通過ICMP重定向生成表項需要同時滿足三種情況。1.網路很小;2與其他網路只有單個連線點;3沒有多餘路由。如果這三個條件不能完全滿足,則通常使用動態選路。 動態選路是路由器之間採用選路協議進行通訊,從相鄰路由器接受
【讀書筆記-從Paxos到ZooKeeper分散式一致性原理與實踐】第二章 一致性協議
2PC與 3PC 在分散式系統中,每個節點都明確知道自己事務操作的成功或失敗,但無法獲取其他分散式節點的操作結果。因此當一個事務需要跨節點進行事務操作時,需要引入協調者(Coordinator)元件來統一排程所有分散式節點的執行邏輯,這些被排程的節點稱為參與者
《TCP/IP詳解 卷一:協議》讀書筆記--IP選路
9.1、引言 9.2、選路的原理 9.2.1、簡單路由器 svr4 % netstat -rn Routing tables Destination Gateway Flags
三、RabbitMQ如何實現AMQ協議(讀書筆記)
開發十年,就只剩下這套架構體系了! >>>
《代碼閱讀》讀書筆記(一)
需求 的人 一行 編碼 重要 流動 使用 分析 缺少 《代碼閱讀》讀書筆記(一) 《代碼閱讀》(《Code Reading The Open Source Perspective》)Diomidis Spinellis 著 ---------------------
《大型網站技術架構:核心原理與案例分析》-- 讀書筆記 (5) :網購秒殺系統
案例 並發 刷新 隨機 url 對策 -- 技術 動態生成 1. 秒殺活動的技術挑戰及應對策略 1.1 對現有網站業務造成沖擊 秒殺活動具有時間短,並發訪問量大的特點,必然會對現有業務造成沖擊。對策:秒殺系統獨立部署 1.2 高並發下的應用、
Java 線程第三版 第五章 極簡同步技巧 讀書筆記
prev ear ont java else 停止 第三版 不同的 結合 一、能避免同步嗎? 取得鎖會由於下面原因導致成本非常高: 取得由競爭的鎖須要在虛擬機的層面上執行很多其它的程序代碼。 要取得有競爭鎖的線程總是必須等到鎖被釋放後。 1. 寄
《Java並發編程實戰》第十章 避免活躍性危急 讀書筆記
for 分析 tac mage cas 系統 ron htm 發生 一、死鎖 所謂死鎖: 是指兩個或兩個以上的進程在運行過程中。因爭奪資源而造成的一種互相等待的現象。若無外力作用。它們都將無法推進下去。 百科百科 當兩個以上的運算單元,兩方都在等待對方停止執
css權威指南 讀書筆記
text ron :focus 表單 順序 系統 web letter 知識 網上看見推薦的書總是喜歡買回家,但是大多數時候都不會立即就看,都是在書櫥裏蒙上了一層灰塵。從畢業到現在,由於公司業務原因,寫js多余css,所以就想系統地看看css,並且做一些練習,於是就開始看《
Ajax與Comet-JavaScript高級程序設計第21章讀書筆記(1)
set activex .html 規範 sta php 協議 num 刷新 Ajax(Asynchronous Javascript + XML)技術的核心是XMLHttpRequest對象,即: XHR。雖然名字中包含XML,但它所指的僅僅是這種無須刷新頁面即可從服務器
構建之法——讀書筆記(5)
exp 時間 微軟 padding 層次結構 敏捷 參加 解決問題 企業 第七章 MSF What is MSF?——Microsoft Solution Framework(微軟解決方案框架)即一個方法論,也就是微軟推薦的軟件開發方法。 MSF基本原則: MSF沒有像敏捷
《構建之法》第四章讀書筆記
解決 更多 發現 開發 空白 知識點 相互 文字 人的 本章理論和知識點有:代碼規範、極限編程、結對編程、兩人合作的不同階段、影響他人的技巧 一、代碼規範 1、代碼風格規範。主要是文字上的規定,看似表面文章,實際上非常重要。 代碼風格的原則是:簡明,易讀,無二義性 。包括了