
Spark RPC 框架原始碼分析(二)執行時序
前情提要:
一. Spark RPC 概述概述
上一篇我們已經說明了 Spark RPC 框架的一個簡單例子,以及一些基本概念的說明。這一篇我們主要講述其執行時序,從而揭露 Spark RPC 框架的執行原理。我們將分為兩部分,分別從服務端和客戶端來看。
所用 spark 版本:spark 2.1.0
二. Spark RPC 服務端
我們以上一篇 HelloworldServer 為線索,深入到 Spark RPC 框架來看看啟動一個服務時都做了些什麼。
HelloworldServer{ ...... def main(args: Array[String]): Unit = { //val host = args(0) val host = "localhost" val config = RpcEnvServerConfig(new RpcConf(), "hello-server", host, 52345) val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config) val helloEndpoint: RpcEndpoint = new HelloEndpoint(rpcEnv) rpcEnv.setupEndpoint("hello-service", helloEndpoint) rpcEnv.awaitTermination() } ...... }
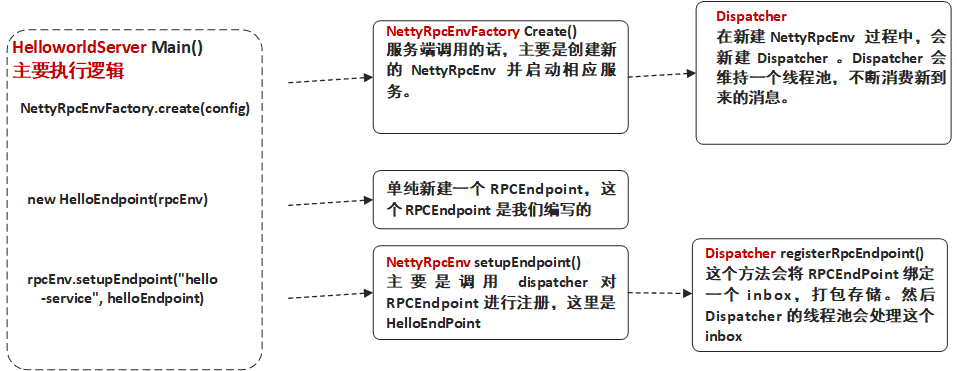
這段程式碼中有兩個主要流程,我們分別來說
2.1 Spark RPC 服務端 NettyRpcEnvFactory.create(config)
首先是下面這條程式碼的執行流程:
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
其實就是通過 NettyRpcEnvFactory 創建出一個 RPC Environment ,其具體類是 NettyRpcEnv 。
我們再來看看建立過程中會發生什麼。
object NettyRpcEnvFactory extends RpcEnvFactory { ...... def create(config: RpcEnvConfig): RpcEnv = { val conf = config.conf // Use JavaSerializerInstance in multiple threads is safe. However, if we plan to support // KryoSerializer in future, we have to use ThreadLocal to store SerializerInstance val javaSerializerInstance = new JavaSerializer(conf).newInstance().asInstanceOf[JavaSerializerInstance] //根據配置以及地址,new 一個 NettyRpcEnv , val nettyEnv = new NettyRpcEnv(conf, javaSerializerInstance, config.bindAddress) //如果是服務端建立的,那麼會啟動服務。服務端和客戶端都會通過這個方法建立一個 NettyRpcEnv ,但區別就在這裡了。 if (!config.clientMode) { val startNettyRpcEnv: Int => (NettyRpcEnv, Int) = { actualPort => //啟動服務的方法,下一步就是呼叫這個方法了 nettyEnv.startServer(config.bindAddress, actualPort) (nettyEnv, nettyEnv.address.port) } try { Utils.startServiceOnPort(config.port, startNettyRpcEnv, conf, config.name)._1 } catch { case NonFatal(e) => nettyEnv.shutdown() throw e } } nettyEnv } ...... }
還沒完,如果是服務端呼叫這段程式碼,那麼主要的功能是建立 RPCEnv ,即 NettyRpcEnv(客戶端在後面說) 。以及通過下面這行程式碼,
nettyEnv.startServer(config.bindAddress, actualPort)
去呼叫相應的方法啟動服務端的服務。下面進入到這個方法中去看看。
class NettyRpcEnv( val conf: RpcConf, javaSerializerInstance: JavaSerializerInstance, host: String) extends RpcEnv(conf) { ...... def startServer(bindAddress: String, port: Int): Unit = { // here disable security val bootstraps: java.util.List[TransportServerBootstrap] = java.util.Collections.emptyList() //TransportContext 屬於 spark.network 中的部分,負責 RPC 訊息在網路中的傳輸 server = transportContext.createServer(bindAddress, port, bootstraps) //在每個 RpcEndpoint 註冊的時候都會註冊一個預設的 RpcEndpointVerifier,它的作用是客戶端呼叫的時候先用它來詢問 Endpoint 是否存在。 dispatcher.registerRpcEndpoint( RpcEndpointVerifier.NAME, new RpcEndpointVerifier(this, dispatcher)) } ...... }
執行完畢之後這個 create 方法就結束。這個流程主要就是開啟一些服務,然後返回一個新的 NettyRpcEnv 。
2.2 Spark RPC 服務端 rpcEnv.setupEndpoint("hello-service", helloEndpoint)
這條程式碼會去呼叫 NettyRpcEnv 中相應的方法
class NettyRpcEnv(
val conf: RpcConf,
javaSerializerInstance: JavaSerializerInstance,
host: String) extends RpcEnv(conf) {
......
override def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef = {
dispatcher.registerRpcEndpoint(name, endpoint)
}
......
}我們看到,這個方法主要是呼叫 dispatcher 進行註冊的。dispatcher 的功能上一節已經說了,
Dispatcher 的主要作用是儲存註冊的RpcEndpoint、分發相應的Message到RpcEndPoint中進行處理。Dispatcher 即是上圖中 ThreadPool的角色。它同時也維繫一個 threadpool,用來處理每次接受到的 InboxMessage 。而這裡處理 InboxMessage 是通過 inbox 實現的。
,這裡我們就說一說 dispatcher 的流程。
dispatcher
dispatcher 在 NettyRpcEnv 被建立的時候創建出來。
class NettyRpcEnv(
val conf: RpcConf,
javaSerializerInstance: JavaSerializerInstance,
host: String) extends RpcEnv(conf) {
......
//初始化時建立 dispatcher
private val dispatcher: Dispatcher = new Dispatcher(this)
......
}dispatcher 類被建立的時候也有幾個屬性需要注意:
private[netty] class Dispatcher(nettyEnv: NettyRpcEnv) {
......
//每個 RpcEndpoint 其實都會被整合成一個 EndpointData 。並且每個 RpcEndpoint 都會有一個 inbox。
private class EndpointData(
val name: String,
val endpoint: RpcEndpoint,
val ref: NettyRpcEndpointRef) {
val inbox = new Inbox(ref, endpoint)
}
//一個阻塞佇列,當有 RpcEndpoint 相關請求(InboxMessage)的時候,就會將請求塞到這個佇列中,然後被執行緒池處理。
private val receivers = new LinkedBlockingQueue[EndpointData]
//初始化便創建出來的執行緒池,當上面的 receivers 佇列中沒內容時,會阻塞。當有 RpcEndpoint 相關請求(即 InboxMessage )的時候就會立刻執行。
//這裡處理 InboxMessage 本質上是呼叫相應 RpcEndpoint 的 inbox 去處理。
private val threadpool: ThreadPoolExecutor = {
val numThreads = nettyEnv.conf.getInt("spark.rpc.netty.dispatcher.numThreads",
math.max(2, Runtime.getRuntime.availableProcessors()))
val pool = ThreadUtils.newDaemonFixedThreadPool(numThreads, "dispatcher-event-loop")
for (i <- 0 until numThreads) {
pool.execute(new MessageLoop)
}
pool
}
......
}瞭解一些 Dispatcher 的邏輯流程後,我們來正式看看 Dispatcher 的 registerRpcEndpoint 方法。
顧名思義,這個方法就是將 RpcEndpoint 註冊到 Dispatcher 中去。當有 Message 到來的時候,便會分發 Message 到相應的 RpcEndPoint 中進行處理。
private[netty] class Dispatcher(nettyEnv: NettyRpcEnv) {
......
def registerRpcEndpoint(name: String, endpoint: RpcEndpoint): NettyRpcEndpointRef = {
val addr = RpcEndpointAddress(nettyEnv.address, name)
//註冊 RpcEndpoint 時需要的是 上面的 EndpointData ,其中就包含 endpointRef ,這個主要是供客戶端使用的。
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv)
//多執行緒環境下,註冊一個 RpcEndpoint 需要判斷現在是否處於 stop 狀態。
synchronized {
if (stopped) {
throw new IllegalStateException("RpcEnv has been stopped")
}
//新建 EndpointData 並存儲到一個 ConcurrentMap 中。
if (endpoints.putIfAbsent(name, new EndpointData(name, endpoint, endpointRef)) != null) {
throw new IllegalArgumentException(s"There is already an RpcEndpoint called $name")
}
val data = endpoints.get(name)
endpointRefs.put(data.endpoint, data.ref)
//將 這個 EndpointData 加入到 receivers 佇列中,此時 dispatcher 中的 threadpool 會去處理這個加進來的 EndpointData
//處理過程是呼叫它的 inbox 的 process()方法。然後 inbox 會等待訊息到來。
receivers.offer(data) // for the OnStart message
}
endpointRef
}
......
}Spark RPC 服務端邏輯小結:我們說明了 Spark RPC 服務端啟動的邏輯流程,分為兩個部分,第一個是 Spark RPC env ,即 NettyRpcEnv 的建立過程,第二個則是 RpcEndpoint 註冊到 dispatcher 的流程。
1. NettyRpcEnvFactory 建立 NettyRpcEnv
- 根據地址建立 NettyRpcEnv。
- NettyRpcEnv 開始啟動服務,包括 TransportContext 根據地址開啟監聽服務,向 Dispacther 註冊一個 RpcEndpointVerifier 等待。
2. Dispatcher 註冊 RpcEndpoint
- Dispatcher 初始化時便建立一個執行緒池並阻塞等待 receivers 佇列中加入新的 EndpointData
- 一旦新加入 EndpointData 便會呼叫該 EndpointData 的 inbox 去處理訊息。比如 OnStart 訊息,或是 RPCMessage 等等。
三.Spark RPC 客戶端
依舊是以上一節 Spark RPC 客戶端 HelloWorld 的為線索,我們來逐層深入 Spark RPC 客戶端 HelloworldClient 的 asyncCall() 方法。
object HelloworldClient {
......
def asyncCall() = {
val rpcConf = new RpcConf()
val config = RpcEnvClientConfig(rpcConf, "hello-client")
val rpcEnv: RpcEnv = NettyRpcEnvFactory.create(config)
val endPointRef: RpcEndpointRef = rpcEnv.setupEndpointRef(RpcAddress("localhost", 52345), "hello-service")
val future: Future[String] = endPointRef.ask[String](SayHi("neo"))
future.onComplete {
case scala.util.Success(value) => println(s"Got the result = $value")
case scala.util.Failure(e) => println(s"Got error: $e")
}
Await.result(future, Duration.apply("30s"))
rpcEnv.shutdown()
}
......
}
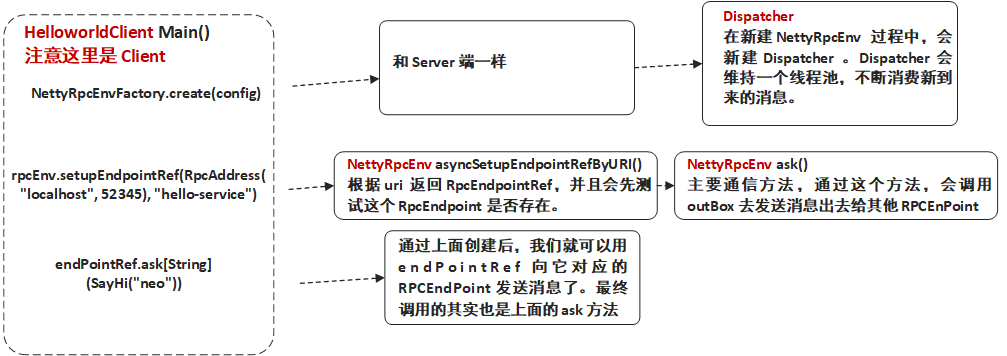
建立 Spark RPC 客戶端 Env(即 NettyRpcEnvFactory ) 部分和 Spark RPC 服務端是一樣的,只是不會開啟監聽服務,這裡就不詳細展開。
我們從這一句開始看,這也是 Spark RPC 客戶端和服務端區別的地方所在。
val endPointRef: RpcEndpointRef = rpcEnv.setupEndpointRef(RpcAddress("localhost", 52345), "hello-service")
setupEndpointRef()
上面的的 setupEndpointRef 最終會去呼叫下面 setupEndpointRef() 這個方法,這個方法中又進行一次跳轉,跳轉去 setupEndpointRefByURI 這個方法中 。需要注意的是這兩個方法都是 RpcEnv 裡面的,而 RpcEnv 是抽象類,它裡面只實現部分方法,而 NettyRpcEnv 繼承了它,實現了全部方法。
abstract class RpcEnv(conf: RpcConf) {
......
def setupEndpointRef(address: RpcAddress, endpointName: String): RpcEndpointRef = {
//會跳轉去呼叫下面的方法
setupEndpointRefByURI(RpcEndpointAddress(address, endpointName).toString)
}
def setupEndpointRefByURI(uri: String): RpcEndpointRef = {
//其中 asyncSetupEndpointRefByURI() 返回的是 Future[RpcEndpointRef]。 這裡就是阻塞,等待返回一個 RpcEndpointRef。
// defaultLookupTimeout.awaitResult 底層呼叫 Await.result 阻塞 直到結果返回或返回異常
defaultLookupTimeout.awaitResult(asyncSetupEndpointRefByURI(uri))
}
......
} 這裡最主要的程式碼其實就一句,
defaultLookupTimeout.awaitResult(asyncSetupEndpointRefByURI(uri))
這一段可以分為兩部分, 第一部分的 defaultLookupTimeout.awaitResult 其實底層是呼叫 Await.result 阻塞等待一個非同步操作,直到結果返回。
而asyncSetupEndpointRefByURI(uri) 則是根據給定的 uri 去返回一個 RpcEndpointRef ,它是在 NettyRpcEnv 中實現的:
class NettyRpcEnv(
val conf: RpcConf,
javaSerializerInstance: JavaSerializerInstance,
host: String) extends RpcEnv(conf) {
......
def asyncSetupEndpointRefByURI(uri: String): Future[RpcEndpointRef] = {
//獲取地址
val addr = RpcEndpointAddress(uri)
//根據地址等資訊新建一個 NettyRpcEndpointRef 。
val RpcendpointRef = new NettyRpcEndpointRef(conf, addr, this)
//每個新建的 RpcendpointRef 都有先有一個對應的verifier 去檢查服務端存不存在對應的 Rpcendpoint 。
val verifier = new NettyRpcEndpointRef(
conf, RpcEndpointAddress(addr.rpcAddress, RpcEndpointVerifier.NAME), this)
//向服務端傳送請求判斷是否存在對應的 Rpcendpoint。
verifier.ask[Boolean](RpcEndpointVerifier.createCheckExistence(endpointRef.name)).flatMap { find =>
if (find) {
Future.successful(endpointRef)
} else {
Future.failed(new RpcEndpointNotFoundException(uri))
}
}(ThreadUtils.sameThread)
}
......
}
asyncSetupEndpointRefByURI() 這個方法實現兩個功能,第一個就是新建一個 RpcEndpointRef 。第二個是新建一個 verifier ,這個 verifier 的作用就是先給服務端傳送一個請求判斷是否存在 RpcEndpointRef 對應的 RpcEndpoint 。
這段程式碼中最重要的就是 verifiter.ask[Boolean](...) 了。如果有找到之後就會呼叫 Future.successful 這個方法,反之則會 通過 Future.failed 丟擲一個異常。
ask 可以算是比較核心的一個方法,我們可以到 ask 方法中去看看。
class NettyRpcEnv{
......
private[netty] def ask[T: ClassTag](message: RequestMessage, timeout: RpcTimeout): Future[T] = {
val promise = Promise[Any]()
val remoteAddr = message.receiver.address
//
def onFailure(e: Throwable): Unit = {
// println("555");
if (!promise.tryFailure(e)) {
log.warn(s"Ignored failure: $e")
}
}
def onSuccess(reply: Any): Unit = reply match {
case RpcFailure(e) => onFailure(e)
case rpcReply =>
println("666");
if (!promise.trySuccess(rpcReply)) {
log.warn(s"Ignored message: $reply")
}
}
try {
if (remoteAddr == address) {
val p = Promise[Any]()
p.future.onComplete {
case Success(response) => onSuccess(response)
case Failure(e) => onFailure(e)
}(ThreadUtils.sameThread)
dispatcher.postLocalMessage(message, p)
} else {
//跳轉到這裡執行
//封裝一個 RpcOutboxMessage ,同時 onSuccess 方法也是在這裡註冊的。
val rpcMessage = RpcOutboxMessage(serialize(message),
onFailure,
(client, response) => onSuccess(deserialize[Any](client, response)))
postToOutbox(message.receiver, rpcMessage)
promise.future.onFailure {
case _: TimeoutException => println("111");rpcMessage.onTimeout()
// case _ => println("222");
}(ThreadUtils.sameThread)
}
val timeoutCancelable = timeoutScheduler.schedule(new Runnable {
override def run(): Unit = {
// println("333");
onFailure(new TimeoutException(s"Cannot receive any reply in ${timeout.duration}"))
}
}, timeout.duration.toNanos, TimeUnit.NANOSECONDS)
//promise 對應的 future onComplete時會去呼叫,但當 successful 的時候,上面的 run 並不會被呼叫。
promise.future.onComplete { v =>
// println("4444");
timeoutCancelable.cancel(true)
}(ThreadUtils.sameThread)
} catch {
case NonFatal(e) =>
onFailure(e)
}
promise.future.mapTo[T].recover(timeout.addMessageIfTimeout)(ThreadUtils.sameThread)
}
......
}這裡涉及到使用一些 scala 多執行緒的高階用法,包括 Promise 和 Future。如果想要對這些有更加深入的瞭解,可以參考這篇文章。
這個函式的作用從名字中就可以看得出,其實就是將要 傳送的訊息封裝成一個 RpcOutboxMessage ,然後交給 OutBox 去傳送,OutBox 和前面所說的 InBox 對應,對應 Actor 模型中的 MailBox(信箱)。用於傳送和接收訊息。
其中使用到了 Future 和 Promise 進行非同步併發以及錯誤處理,比如當傳送時間超時的時候 Promise 就會返回一個 TimeoutException ,而我們就可以設定自己的 onFailure 函式去處理這些異常。
OK,註冊完 RpcEndpointRef 後我們便可以用它來向服務端傳送訊息了,而其實 RpcEndpointRef 傳送訊息還是呼叫 ask 方法,就是上面的那個 ask 方法。上面也有介紹,本質上就是通過 OutBox 進行處理。
我們來梳理一下客戶端的傳送流程。
客戶端邏輯小結:客戶端和服務端比較類似,都是需要建立一個 NettyRpcEnv 。不同的是接下來客戶端建立的是 RpcEndpointRef ,並用之向服務端對應的 RpcEndpoint 傳送訊息。
1. NettyRpcEnvFactory 建立 NettyRpcEnv
- 根據地址建立 NettyRpcEnv。 根據地址開啟監聽服務,向 Dispacther 註冊一個 RpcEndpointVerifier 等待。
2. 建立 RpcEndpointRef
- 建立一個新的 RpcEndpointRef
- 建立對應的 verifier ,使用 verifier 向服務端傳送請求,判斷對應的 RpcEndpoint 是否存在。若存在,返回該 RpcEndpointRef ,否則丟擲異常。
3. RpcEndpointRef 使用同步或者非同步的方式傳送請求。
OK,以上就是 Spark RPC 時序的原始碼分析。下一篇會將一個實際的例子,Spark 的心跳機制和程式碼。喜歡的話就關注一波吧
推薦閱讀 :
從分治演算法到 MapReduce
Actor併發程式設計模型淺析
大資料儲存的進化史 --從 RAID 到 Hadoop Hdfs
一個故事告訴你什麼才是好的程式設計師