
Structured Streaming VS Flink
flink是標準的實時處理引擎,而且Spark的兩個模組Spark Streaming和Structured Streaming都是基於微批處理的,不過現在Spark Streaming已經非常穩定基本都沒有更新了,然後重點移到spark sql和structured Streaming了。
Flink作為一個很好用的實時處理框架,也支援批處理,不僅提供了API的形式,也可以寫sql文字。這篇文章主要是幫著大家對於Structured Streaming和flink的主要不同點。文章建議收藏後閱讀。
1. 執行模型
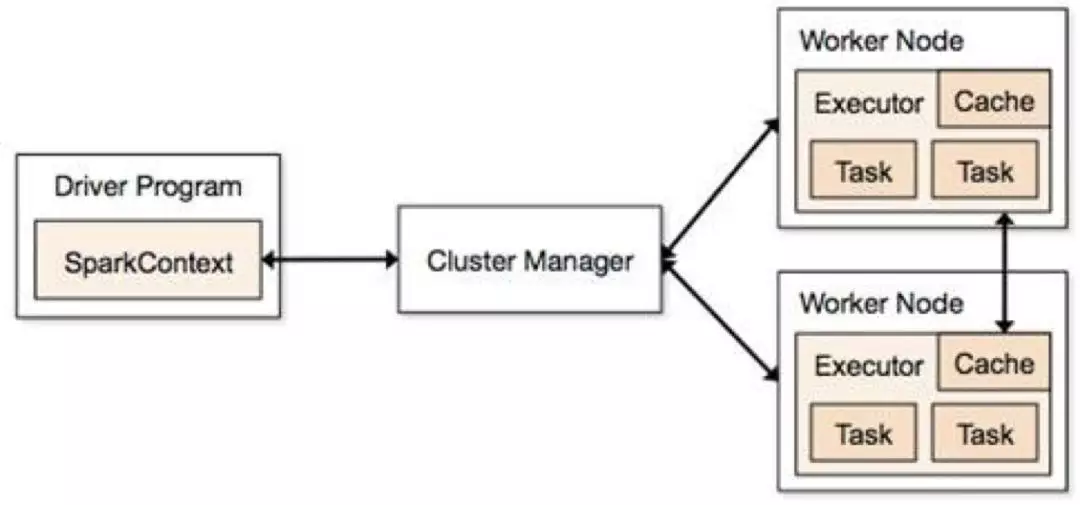
Structured Streaming 的task執行也是依賴driver 和 executor,當然driver和excutor也還依賴於叢集管理器Standalone或者yarn等。可以用下面一張圖概括:
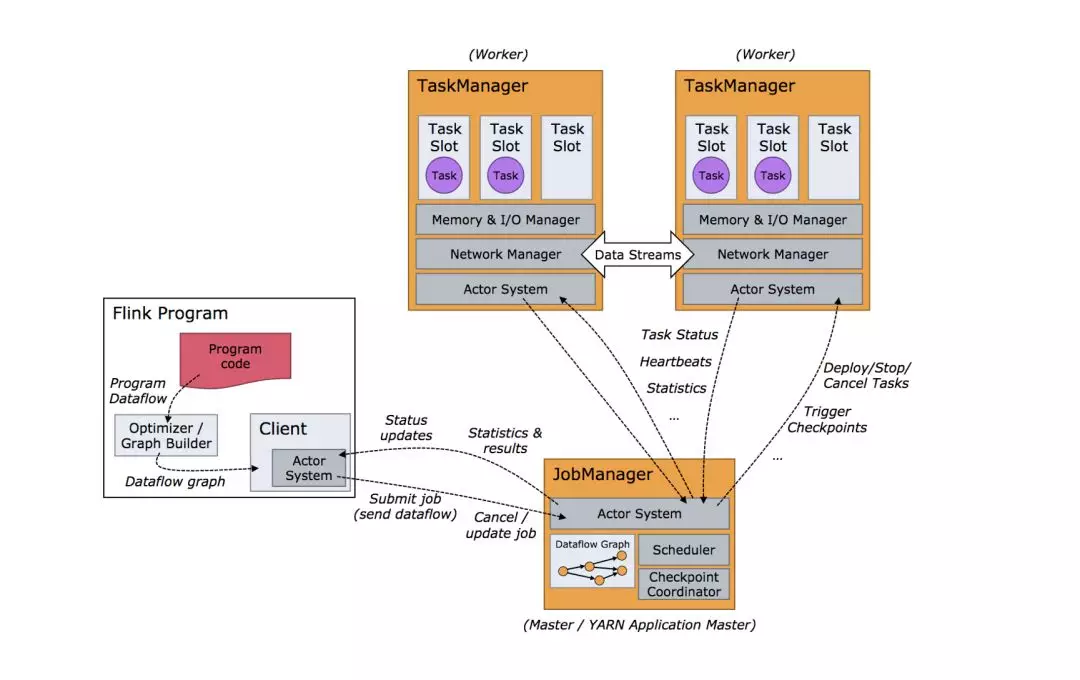
Flink的Task依賴jobmanager和taskmanager。官方給了詳細的執行架構圖,可以參考:
Structured Streaming 週期性或者連續不斷的生成微小dataset,然後交由Spark SQL的增量引擎執行,跟Spark Sql的原有引擎相比,增加了增量處理的功能,增量就是為了狀態和流表功能實現。由於是也是微批處理,底層執行也是依賴Spark SQL的。
Flink 中的執行圖可以分成四層:StreamGraph-> JobGraph -> ExecutionGraph -> 物理執行圖。細分:
StreamGraph: 是根據使用者通過 Stream API 編寫的程式碼生成的最初的圖。用來表示程式的拓撲結構。
JobGraph: StreamGraph經過優化後生成了JobGraph,提交給 JobManager 的資料結構。主要的優化為,將多個符合條件的節點 chain 在一起作為一個節點,這樣可以減少資料在節點之間流動所需要的序列化/反序列化/傳輸消耗。這個可以用來構建自己的自己的叢集任務管理框架。
ExecutionGraph: JobManager 根據 JobGraph 生成的分散式執行圖,是排程層最核心的資料結構。
物理執行圖: JobManager 根據ExecutionGraph 對 Job 進行排程後,在各個TaskManager 上部署 Task 後形成的“圖”,並不是一個具體的資料結構。
2. 程式設計風格
兩者的程式設計模型基本一致吧,都是鏈式呼叫。
3. 時間概念
三種處理時間:事件時間,注入時間,處理時間。
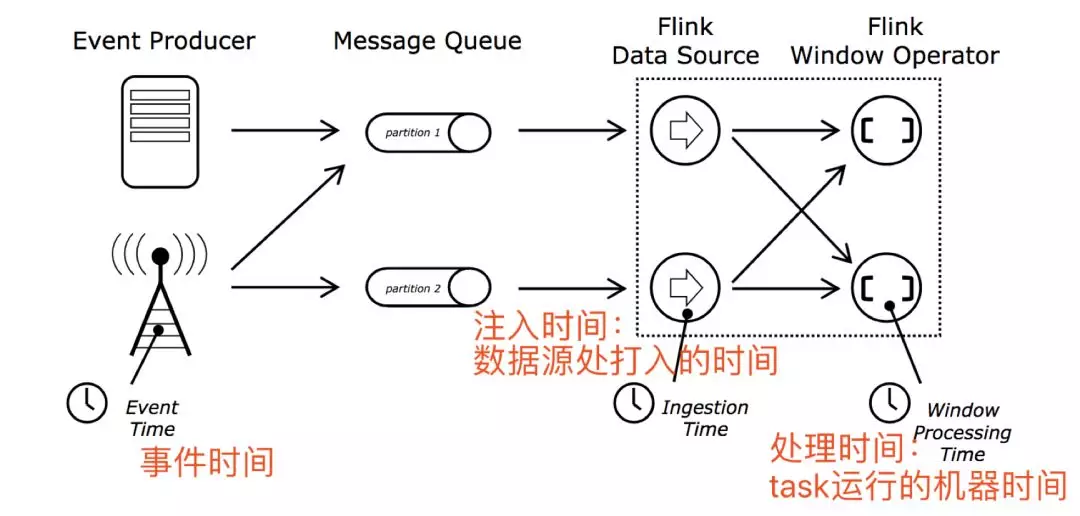
Flink支援三種時間,同時flink支援基於事件驅動的處理模型,同時在聚合等運算元存在的時候,支援狀態超時自動刪除操作,以避免7*24小時流程式計算狀態越來越大導致oom,使得程式掛掉。
Structured Streaming僅支援事件時間,處理時間。
對於基於事件時間的處理flink和Structured Streaming都是支援watemark機制,視窗操作基於watermark和事件時間可以對滯後事件做相應的處理,雖然聽起來這是個好事,但是整體來說watermark就是雞肋,它會導致結果資料輸出滯後,比如watermark是一個小時,視窗一個小時,那麼資料輸出實際上會延遲兩個小時,這個時候需要進行一些處理。
4. 維表實現及非同步io
Structured Streaming不直接支援與維表的join操作,但是可以使用map、flatmap及udf等來實現該功能,所有的這些都是同步運算元,不支援非同步IO操作。但是Structured Streaming直接與靜態資料集的join,可以也可以幫助實現維表的join功能,當然維表要不可變。
Flink也不支援與維表進行join操作,除了map,flatmap這些運算元之外,flink還有非同步IO運算元,可以用來實現維表,提升效能。
5. 狀態管理
狀態維護應該是流處理非常核心的概念了,比如join,分組,聚合等操作都需要維護歷史狀態,那麼flink在這方面很好,structured Streaming也是可以,但是spark Streaming就比較弱了,只有個別狀態維護運算元upstatebykye等,大部分狀態需要使用者自己維護,雖然這個對使用者來說有更大的可操作性和可以更精細控制但是帶來了程式設計的麻煩。flink和Structured Streaming都支援自己完成了join及聚合的狀態維護。
Structured Streaming有高階的運算元,使用者可以完成自定義的mapGroupsWithState和flatMapGroupsWithState,可以理解類似Spark Streaming 的upstatebykey等狀態運算元。
就拿mapGroupsWithState為例:
由於Flink與Structured Streaming的架構的不同,task是常駐執行的,flink不需要狀態運算元,只需要狀態型別的資料結構。
首先看一下Keyed State下,我們可以用哪些原子狀態:
ValueState:即型別為T的單值狀態。這個狀態與對應的key繫結,是最簡單的狀態了。它可以通過update方法更新狀態值,通過value()方法獲取狀態值。
ListState:即key上的狀態值為一個列表。可以通過add方法往列表中附加值;也可以通過get()方法返回一個Iterable來遍歷狀態值。
ReducingState:這種狀態通過使用者傳入的reduceFunction,每次呼叫add方法新增值的時候,會呼叫reduceFunction,最後合併到一個單一的狀態值。
FoldingState:跟ReducingState有點類似,不過它的狀態值型別可以與add方法中傳入的元素型別不同(這種狀態將會在Flink未來版本中被刪除)。
MapState:即狀態值為一個map。使用者通過put或putAll方法新增元素。
6. join操作
flink的join操作沒有大的限制,支援種類豐富,比:
Inner Equi-join

Outer Equi-join

Time-windowed Join

Expanding arrays into a relation

Join with Table Function
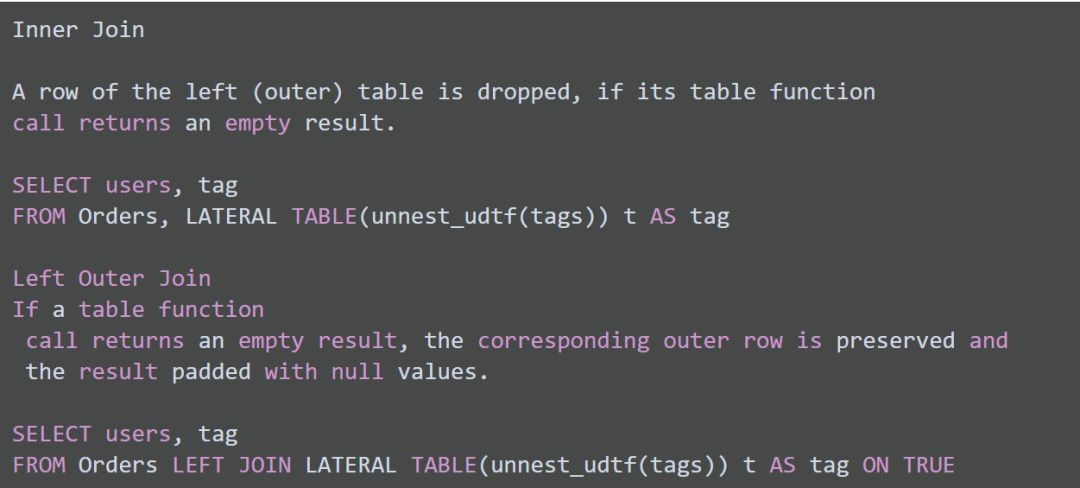
Join with Temporal Table
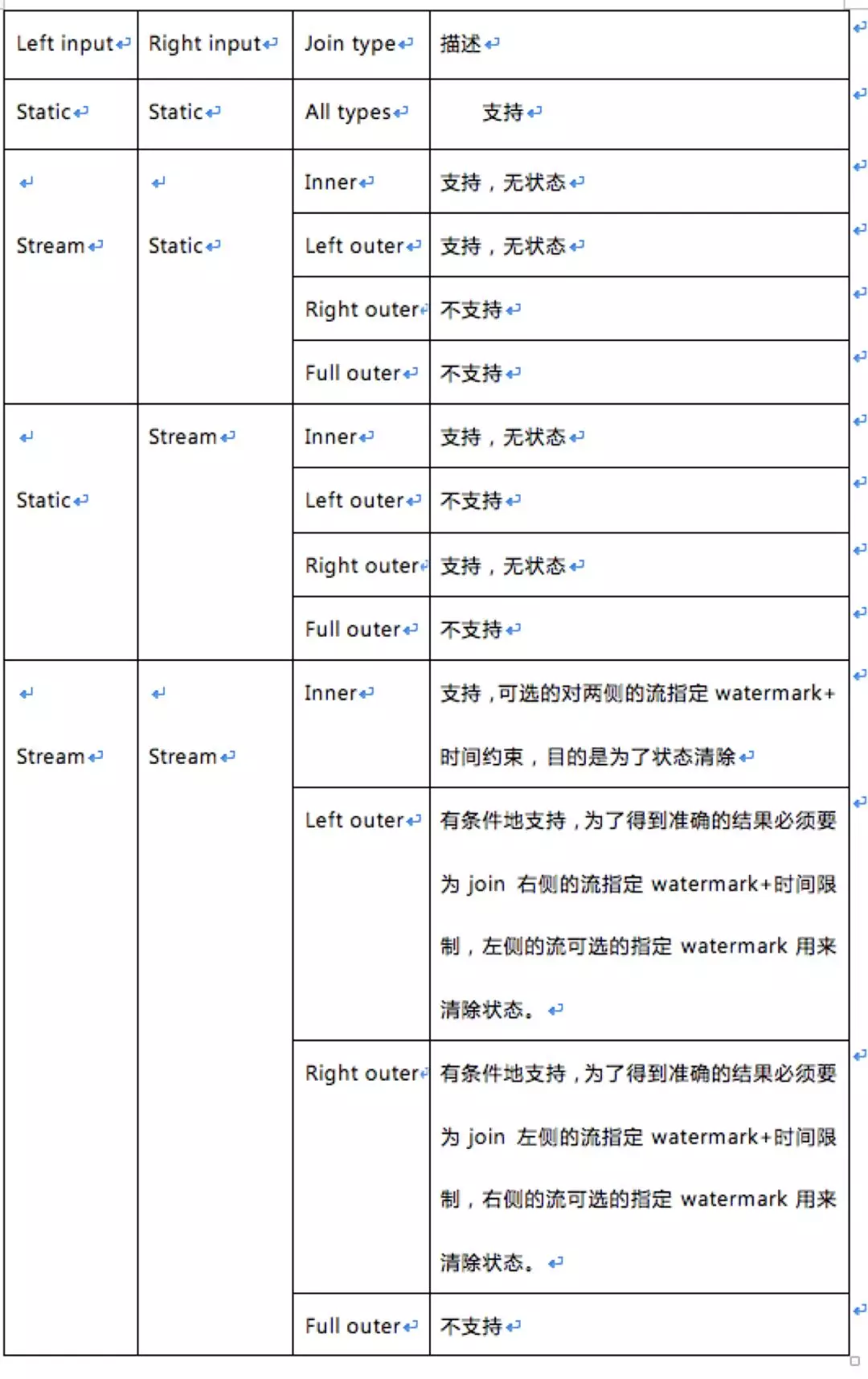
Structured Streaming的join限制頗多了,知識星球裡發過了join細則,限於篇幅問題在這裡只講一下join的限制。具體如下表格
還有另外細則需要說明一下:
join可以傳遞。比如df1.join(df2).join(df3)。
從spark2.3開始,只有在輸出模式為append的流查詢才能使用join,其他輸出模式暫不支援。
從spark2.3開始,在join之前不允許使用no-map-like操作。以下是不能使用的例子。
在join之前不能使用流聚合操作。
在join之前,無法在update模式下使用mapGroupsWithState和flatMapGroupsWithState。
7. 觸發處理模型
這個之所以講一下區別,實際緣由也很簡單,Structured Streaming以前是依據spark的批處理起家的實時處理,而flink是真正的實時處理。那麼既然Structured Streaming是批處理,那麼問題就簡單了,批次執行時間和執行頻率自然是有限制的,就產生了多種觸發模型,簡單稱其為triggers。Strucctured Streaming的triggers有以下幾種形式:
1). 支援單次觸發處理,類似於flink的批處理。
Trigger.Once()顧名思義這個僅處理一次,類似於flink的批處理。
2). 週期性觸發處理
Trigger.ProcessingTime(“2 seconds”)
查詢將以微批量模式執行,其中微批次將以使用者指定的間隔啟動:
a).如果先前的微批次在該間隔內完成,則引擎將等待該間隔結束,然後開始下一個微批次。
b).如果前一個微批次需要的時間超過完成的時間間隔(即如果錯過了區間邊界),那麼下一個微批次將在前一個完成後立即開始(即,它不會等待下一個間隔邊界))。
c).如果沒有可用的新資料,則不會啟動微批次。
3). 連續處理
指定一個時間間隔
Trigger.Continuous(“1 second”)
這個1秒鐘表示每秒鐘記錄一次連續處理查詢進度。
4). 預設觸發模型
一個批次執行結束立即執行下個批次。
Flink的觸發模式很簡單了,一旦啟動job一直執行處理,不存在各種觸發模式,當然假如視窗不算的話。
8. 表管理
flink和structured streaming都可以講流注冊成一張表,然後使用sql進行分析,不過兩者之間區別還是有些的。
Structured Streaming將流注冊成臨時表,然後用sql進行查詢,操作也是很簡單跟靜態的dataset/dataframe一樣。

其實,此處回想Spark Streaming 如何註冊臨時表呢?在foreachRDD裡,講rdd轉換為dataset/dataframe,然後將其註冊成臨時表,該臨時表特點是代表當前批次的資料,而不是全量資料。Structured Streaming註冊的臨時表就是流表,針對整個實時流的。Sparksession.sql執行結束後,返回的是一個流dataset/dataframe,當然這個很像spark sql的sql文字執行,所以為了區別一個dataframe/dataset是否是流式資料,可以df.isStreaming來判斷。
當然,flink也支援直接註冊流表,然後寫sql分析,sql文字在flink中使用有兩種形式:

對於第一種形式,sqlQuery執行結束之後會返回一張表也即是Table物件,然後可以進行後續操作或者直接輸出,如:result.writeAsCsv("");。
而sqlUpdate是直接將結果輸出到了tablesink,所以要首先註冊tablesink,方式如下:

flink登錄檔的形式比較多,直接用資料來源登錄檔,如:

也可以從datastream轉換成表,如:

9. 監控管理
對於Structured Streaming一個SparkSession例項可以管理多個流查詢,可以通過SparkSession來管理流查詢,也可以直接通過start呼叫後返回的StreamingQueryWrapper物件來管理流查詢。
SparkSession.streams獲取的是一個StreamingQueryManager,然後通過start返回的StreamingQueryWrapper物件的id就可以獲取相應的流查詢狀態和管理相應的流查詢。當然,也可以直接使用StreamingQueryWrapper來做這件事情,由於太簡單了,我們就不貼了可以直接在原始碼裡搜尋該類。
對與Structured Streaming的監控,當然也可以使用StreamingQueryWrapper物件來進行健康監控和告警
其中,有些物件內部有更詳細的監控指標,比如lastProgress,這裡就不詳細展開了。
還有一種監控Structured Streaming的方式就是自定義StreamingQueryListener,然後監控指標基本一樣。註冊的話直接使用
spark.streams.addListener(new StreamingQueryListener())即可。
Flink的管理工具新手的話主要建議是web ui ,可以進行任務提交,job取消等管理操作,監控的話可以看執行圖的結構,job的執行狀態,背壓情況等。
當然,也可以通過比如flink的YarnClusterClient客戶端對jobid進行狀態查詢,告警,啟動,停止等操作。
總結
除了以上描述的這些內容,可能還關心kafka結合的時候新增topic或者分割槽時能否感知,實際上兩者都能感知,初次之外。flink還有很多特色,比如資料迴流,分散式事務支援,分散式快照,非同步增量快照,豐富的windows操作,側輸出,複雜事件處理等等。
對於視窗和join,兩者區別還是很大,限於篇幅問題後面浪尖會分別給出講解。
flink是一個不錯的流處理框架,雖然目前還有些bug和待完善的部分。