
基於內容的推薦演算法之關鍵詞提取
基於內容的推薦演算法是比較早期的易理解的推薦演算法,其主要思想就是:我們首先給根據資訊的特徵給資訊一些屬性(可以稱之為“標籤”)。對於一篇文章,或者一段話它的屬性就可以理解成它的關鍵詞,這篇文章的主講內容就是文章的關鍵詞提取。
一、TF-IDF方法
TF(Term Frequency)詞頻,直觀上指的是某個詞在文章中的出現次數,為了避免文章長短帶來的影響,對於不同的文章,詞頻的計算應該歸一化。

文章的標籤應該是文章中重要的詞,他應該在文章中多次出現,於是我們需要進行詞頻統計。
但是,在每篇文章中,往往出現次數最多的詞是“的”“是”“在”等等,這些詞我們稱為“停用詞”,表示對結果毫無用處,必須過濾掉的詞。
另外,在其他有實際意義的詞中,又會遇到一些問題。比如在《中國蜜蜂養殖》這篇文章中,“中國”“蜜蜂”“養殖”三個詞出現的次數一樣多,但很顯然,我們更想要的標籤是後兩個詞
所以,我們需要一個重要性調整係數,衡量一個詞是不是常見詞。如果某個詞比較少見,但是它在這篇文章中多次出現,那麼它很可能就反映了這篇文章的特性,正是我們所需要的標籤。
用統計學的語言表達,這個權重叫做"逆文件頻率"(IDF),在計算IDF時需要一個語料庫,用來模擬語言的使用環境。
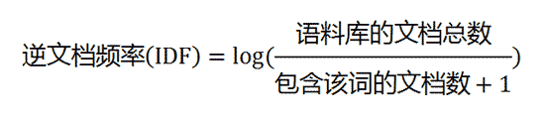
如果一個詞越關鍵,那麼包含這個詞的文件就會相對少,那麼該詞的逆文件頻率就越高。
綜上,TF和IDF都和詞的關鍵性成正比。
利用兩者的乘積來綜合考慮判斷一段文字的關鍵字成為了常用的關鍵詞提取法。
二、程式碼實現
這邊是對中文文章的關鍵詞提取,所以使用了jieba分詞器。
import os import numpy import jieba import jieba.posseg as pseg import string from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer import time start=time.clock() # 獲取檔案列表 def getfilelist(): path = "./input/" filelist = [] files = os.listdir(path) # 返回指定資料夾包含的檔案或資料夾的名字列表 for f in files: if (f[0] == '.'): pass else: filelist.append(f) return filelist, path # 對文件進行分詞處理 def fenci(argv, path): # 儲存分詞結果的目錄 sFilePath = './segfile' if not os.path.exists(sFilePath): os.mkdir(sFilePath) # 讀取文件 filename = argv#這裡的argv是文件 f = open(path + filename, 'r+') file_list = f.read() f.close() # 對文件進行分詞處理,採用預設模式 seg_list = jieba.cut(file_list, cut_all=True) # 對空格,換行符進行處理 result = [] for seg in seg_list: seg = ''.join(seg.split()) if (seg != '' and seg != "\n" and seg != "\n\n"): result.append(seg) # 將分詞後的結果用空格隔開,儲存至本地。 f = open(sFilePath + "/" + filename, "w+") f.write(' '.join(result)) f.close() # 讀取已分詞好的文件,進行TF-IDF計算 def Tfidf(filelist): # filename = argv # 這裡的argv是文件 path = './segfile/' corpus = [] # 存取100份文件的分詞結果 sFilePath = 'F:/fenciDoc/tfidffile' if not os.path.exists(sFilePath): os.mkdir(sFilePath) for ff in filelist: fname = path + ff f = open(fname, 'r+') print(fname) content = f.read() f.close() corpus.append(content) vectorizer = CountVectorizer() transformer = TfidfTransformer() tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus)) word = vectorizer.get_feature_names() # 所有文字的關鍵字 weight = tfidf.toarray() # 對應的tfidf矩陣 keyword=open(sFilePath + '/'+'keyword.txt','w+')#儲存關鍵詞的文件 # 這裡將每份文件詞語的TF-IDF寫入tfidffile資料夾中儲存 for i in range(len(weight)): print(u"--------Writing all the tf-idf in the", i, u" file into ", sFilePath + '/' + str(i+1) + '.txt', "--------") f = open(sFilePath + '/' + str(i+1) + '.txt', 'w+') #將每一篇的關鍵詞存入 keyword.write("第"+str(i+1)+"篇關鍵詞:"+'\n') x=weight[i] y=x.argsort()#返回從小到大的索引值 max=len(word) #print(y) keyword.write(word[y[max-1]]+ " " + str(x[y[max-1]])+"\n") keyword.write(word[y[max-2]]+ " " + str(x[y[max - 2]])+"\n") keyword.write(word[y[max-3]]+ " " + str(x[y[max - 3]])+"\n") keyword.write(word[y[max - 4]] + " " + str(x[y[max - 4]]) + "\n") keyword.write("\n") f.write("全部分詞和TFIDF值:"+"\n") for j in range(len(word)): f.write(word[j] + " " + str(weight[i][j]) + "\n") f.close() if __name__ == "__main__": (allfile, path) = getfilelist() for ff in allfile: print("Using jieba on " + ff) fenci(ff, path) Tfidf(allfile) end=time.clock() print("執行時間"+str(end-start)+"秒")
相關推薦
基於內容的推薦演算法之關鍵詞提取
基於內容的推薦演算法是比較早期的易理解的推薦演算法,其主要思想就是:我們首先給根據資訊的特徵給資訊一些屬性(可以稱之為“標籤”)。對於一篇文章,或者一段話它的屬性就可以理解成它的關鍵詞,這篇文章的主講內容就是文章的關鍵詞提取。一、TF-IDF方法TF(Term Frequen
python 基於TF-IDF演算法的關鍵詞提取
import jiaba.analyse jieba.analyse.extract_tags(content, topK=20, withWeight=False, allowPOS=()) content:為輸入的文字 topK:為返回tf-itf權重最大的關鍵詞,預設值為20個詞 wit
基於內容推薦演算法詳解(比較全面的文章)
Collaborative Filtering Recommendations (協同過濾,簡稱CF) 是目前最流行的推薦方法,在研究界和工業界得到大量使用。但是,工業界真正使用的系統一般都不會只有CF推薦演算法,Content-based Recommendations
基於內容推薦的個性化新聞閱讀實現(二):基於SVD的推薦演算法
一、前言 SVD前面已經說了好多次了,先不論其資訊檢索被宣稱的各種長處如何如何,在此最主要的作用是將稀疏的term-doc矩陣進行降維,當一篇篇文章變成簡短的向量化表示後,就可以用各種科學計算和機器學習演算法進行分析處理了。 之前的推薦演算法的設計是用的最大熵估計,他和諸如樸素貝葉斯、邏輯迴歸等,本質就
推薦系統之基於內容推薦CB
(個性化)推薦系統構建三大方法:基於內容的推薦content-based,協同過濾collaborative filtering,隱語義模型(LFM, latent factor model)推薦。這篇部落格主要講基於內容的推薦content-based。 基於內容的推薦
初談推薦演算法:基於內容推薦(CB)演算法
本章主要談談基於內容Content Based推薦演算法 CB推薦演算法主要有兩種子推薦演算法: 1、引入item屬性的Content Based推薦 2、引入user屬性的Content Bas
推薦演算法之基於物品的協同過濾
基於物品的協同過濾( item-based collaborative filtering )演算法是此前業界應用較多的演算法。無論是亞馬遜網,還是Netflix 、Hulu 、 YouTube ,其推薦演算法的基礎都是該演算法。為行文方便,下文以英文簡稱ItemCF表示。本文將從其基礎演算法講起,一步步進行
opencv 基於內容的視訊關鍵幀提取(以HSV總量為特徵量)
#include "stdafx.h" #include #include "opencv2/core/core.hpp" #include #include using namespace std; using namespace cv; void RGBtoHSV(float b
推薦演算法之相似性推薦
前文介紹了協同過濾演算法和基於內容的推薦演算法 協同過濾演算法要求要有很多使用者,使用者有很多操作 基於內容的推薦演算法使用者可以不用很多,但是使用者的操作也要有很多 但是,如果要推薦給新使用者(使用者的操作不多),應該要怎樣推薦呢?這裡就要用到相似性推薦了 相似性推薦定
推薦演算法之-皮爾遜相關係數計算兩個使用者喜好相似度
<?php /** * 餘玄相似度計算出3個使用者的相似度 * 通過7件產品分析使用者喜好相似度 * 相似度使用函式 sim(user1,user2) =cos∂ * * 設A、B為多維
推薦演算法之Jaccard相似度與Consine相似度
0-- 前言:對於個性化推薦來說,最核心、重要的演算法是相關性度量演算法。相關性從網站物件來分,可以針對商品、使用者、旺鋪、資訊、類目等等,從計算方式看可以分為文字相關性計算和行為相關性計算,具體的實現方法有很多種,最常用的方法有餘弦夾角(Cosine)方法、傑卡德(Jacc
協同過濾推薦演算法之Slope One的介紹
Slope One 之一 : 簡單高效的協同過濾演算法(轉)( 原文地址:http://blog.sina.com.cn/s/blog_4d9a06000100am1d.html 現在做的一個專案中需要用到推薦演算法, 在網上查了一下. Beyo
推薦演算法之-相似鄰居計算
在上面兩篇文章已經講了如何通過使用者對產品的評分分別計算出某個使用者與其他使用者之間的相似度,那麼在計算完相似度後如何才能獲取和該使用者相似度高的人呢,方法分為兩種: 1、固定數量的K個鄰居,(K-neighborhoods)。意思很明確,就是按分數高低降序取K個 2、基
推薦演算法之 slope one 演算法
1.示例引入 多個吃貨在某美團的某家飯館點餐,如下兩道菜: 可樂雞翅: 紅燒肉: 顧客吃過後,會有相關的星級評分。假設評分如下: 評分 可樂雞翅 紅燒肉 小明 4 5 小紅 4
推薦演算法之關聯規則例項
利用的知識 深度分箱 Apriori演算法 資料連線、聚合等處理 資料說明 本資料來源於last.fm的資料 資料包含: 1892 users 17632 artists 12717 bi-directional user frien
推薦機制 協同過濾和基於內容推薦的區別
來源 基於人口統計學的推薦 基於人口統計學的推薦機制(Demographic-based Recommendation)是一種最易於實現的推薦方法,它只是簡單的根據系統使用者的基本資訊發現使用者的相關程度,然後將相似使用者喜愛的其他物品推薦給當前使用者,圖 2 給出了
推薦演算法之協同過濾例項
接著上次的資料進行協同過濾演算法應用 應用的知識 python的surprise k折交叉驗證 R資料構建 KNNBasic KNNWithMeans KNNWithZScore 資料處理與演算法 # 協同過濾演算法資料構建 user
推薦演算法之CB,CF演算法
初學推薦演算法,以下是我的一些見解,如有不對請留言,後續還會更新,這個CSDN太坑了,寫了快一個下午的文章,發表了,結果沒儲存,神坑。。。。。 首先我們來明確一下,推薦系統主要是幹什麼用的:毋庸置疑,在這麼一個資訊爆炸的時代,許多資訊過載或是過剩,那麼我們不可能把全部給看一
資料探勘乾貨總結(六)--推薦演算法之CF
本文共計1245字,預計閱讀時長八分鐘推薦演算法(二)--CF演算法一、推薦的本質推薦分為非個性化和個性化,非個性化推薦比如各類榜單,而本系列主要介紹個性化推薦,即:在合適的場景,合適的時機,通過合適的渠道,把合適的內容,推薦給合適的使用者二、推薦演算法的種類1. 基於內容C
推薦演算法之FFM:原理及實現簡介
推薦系統一般可以分成兩個模組,檢索和排序。比如對於電影推薦,檢索模組會針對使用者生成一個推薦電影列表,而排序模組則負責對這個電影列表根據使用者的興趣做排序。當把FFM演算法應用到推薦系統中時,具體地是應用在排序模組。 FFM演算法,全稱是Field-aware