
深入理解Java Stream流水線
前面我們已經學會如何使用Stream API,用起來真的很爽,但簡潔的方法下面似乎隱藏著無盡的祕密,如此強大的API是如何實現的呢?Pipeline是怎麼執行的,每次方法呼叫都會導致一次迭代嗎?自動並行又是怎麼做到的,執行緒個數是多少?本節我們學習Stream流水線的原理,這是Stream實現的關鍵所在。
首先回顧一下容器執行Lambda表示式的方式,以ArrayList.forEach()方法為例,具體程式碼如下:
// ArrayList.forEach() public void forEach(Consumer<? super E> action) { ... for (int i=0; modCount == expectedModCount && i < size; i++) { action.accept(elementData[i]);// 回撥方法 } ... }
我們看到ArrayList.forEach()方法的主要邏輯就是一個for迴圈,在該for迴圈裡不斷呼叫action.accept()回撥方法完成對元素的遍歷。這完全沒有什麼新奇之處,回撥方法在Java GUI的監聽器中廣泛使用。Lambda表示式的作用就是相當於一個回撥方法,這很好理解。
Stream API中大量使用Lambda表示式作為回撥方法,但這並不是關鍵。理解Stream我們更關心的是另外兩個問題:流水線和自動並行。使用Stream或許很容易寫入如下形式的程式碼:
int longestStringLengthStartingWithA = strings.stream() .filter(s -> s.startsWith("A")) .mapToInt(String::length) .max();
上述程式碼求出以字母A開頭的字串的最大長度,一種直白的方式是為每一次函式呼叫都執一次迭代,這樣做能夠實現功能,但效率上肯定是無法接受的。類庫的實現著使用流水線(Pipeline)的方式巧妙的避免了多次迭代,其基本思想是在一次迭代中儘可能多的執行使用者指定的操作。為講解方便我們彙總了Stream的所有操作。
| Stream操作分類 | ||
| 中間操作(Intermediate operations) | 無狀態(Stateless) | unordered() filter() map() mapToInt() mapToLong() mapToDouble() flatMap() flatMapToInt() flatMapToLong() flatMapToDouble() peek() |
| 有狀態(Stateful) | distinct() sorted() sorted() limit() skip() | |
| 結束操作(Terminal operations) | 非短路操作 | forEach() forEachOrdered() toArray() reduce() collect() max() min() count() |
| 短路操作(short-circuiting) | anyMatch() allMatch() noneMatch() findFirst() findAny() | |
Stream上的所有操作分為兩類:中間操作和結束操作,中間操作只是一種標記,只有結束操作才會觸發實際計算。中間操作又可以分為無狀態的(Stateless)和有狀態的(Stateful),無狀態中間操作是指元素的處理不受前面元素的影響,而有狀態的中間操作必須等到所有元素處理之後才知道最終結果,比如排序是有狀態操作,在讀取所有元素之前並不能確定排序結果;結束操作又可以分為短路操作和非短路操作,短路操作是指不用處理全部元素就可以返回結果,比如找到第一個滿足條件的元素。之所以要進行如此精細的劃分,是因為底層對每一種情況的處理方式不同。
一種直白的實現方式
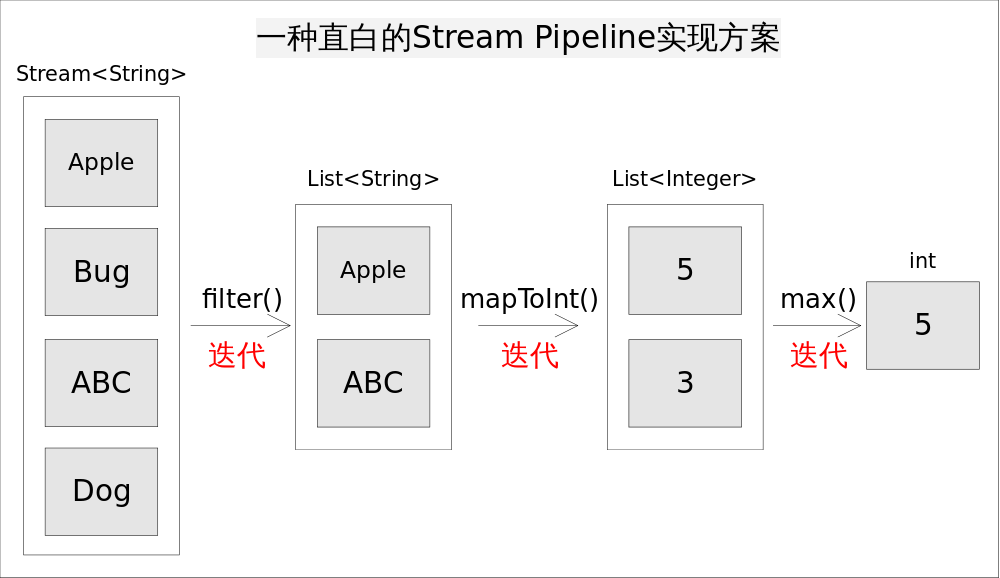
仍然考慮上述求最長字串的程式,一種直白的流水線實現方式是為每一次函式呼叫都執一次迭代,並將處理中間結果放到某種資料結構中(比如陣列,容器等)。具體說來,就是呼叫filter()方法後立即執行,選出所有以A開頭的字串並放到一個列表list1中,之後讓list1傳遞給mapToInt()方法並立即執行,生成的結果放到list2中,最後遍歷list2找出最大的數字作為最終結果。程式的執行流程如如所示:
這樣做實現起來非常簡單直觀,但有兩個明顯的弊端:
- 迭代次數多。迭代次數跟函式呼叫的次數相等。
- 頻繁產生中間結果。每次函式呼叫都產生一次中間結果,儲存開銷無法接受。
這些弊端使得效率底下,根本無法接受。如果不使用Stream API我們都知道上述程式碼該如何在一次迭代中完成,大致是如下形式:
int longest = 0;
for(String str : strings){
if(str.startsWith("A")){// 1. filter(), 保留以A開頭的字串
int len = str.length();// 2. mapToInt(), 轉換成長度
longest = Math.max(len, longest);// 3. max(), 保留最長的長度
}
}採用這種方式我們不但減少了迭代次數,也避免了儲存中間結果,顯然這就是流水線,因為我們把三個操作放在了一次迭代當中。只要我們事先知道使用者意圖,總是能夠採用上述方式實現跟Stream API等價的功能,但問題是Stream類庫的設計者並不知道使用者的意圖是什麼。如何在無法假設使用者行為的前提下實現流水線,是類庫的設計者要考慮的問題。
Stream流水線解決方案
我們大致能夠想到,應該採用某種方式記錄使用者每一步的操作,當用戶呼叫結束操作時將之前記錄的操作疊加到一起在一次迭代中全部執行掉。沿著這個思路,有幾個問題需要解決:
- 使用者的操作如何記錄?
- 操作如何疊加?
- 疊加之後的操作如何執行?
- 執行後的結果(如果有)在哪裡?
>> 操作如何記錄
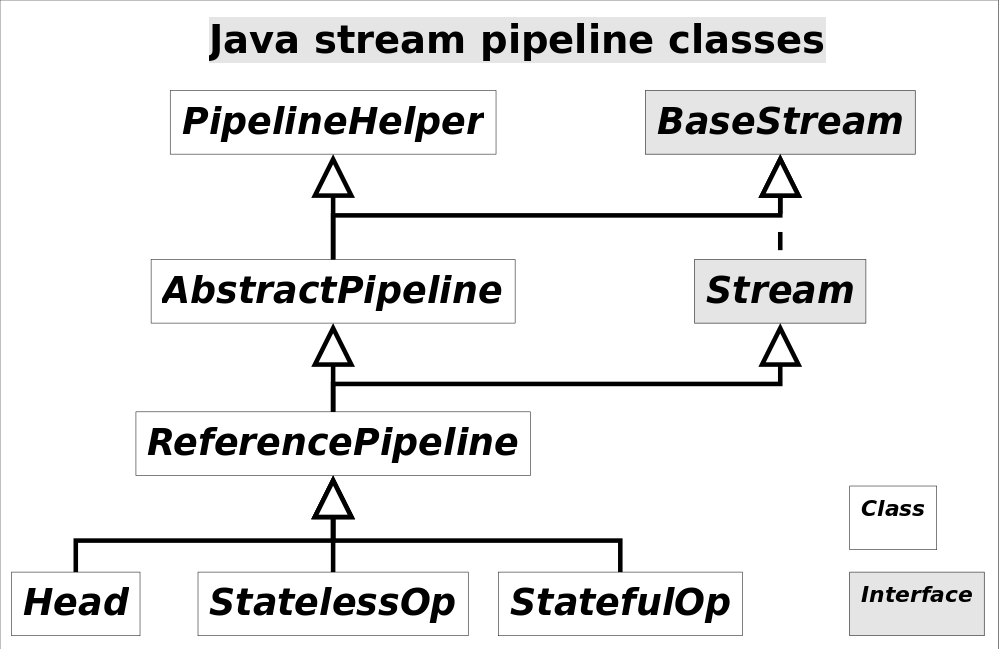
注意這裡使用的是“操作(operation)”一詞,指的是“Stream中間操作”的操作,很多Stream操作會需要一個回撥函式(Lambda表示式),因此一個完整的操作是<資料來源,操作,回撥函式>構成的三元組。Stream中使用Stage的概念來描述一個完整的操作,並用某種例項化後的PipelineHelper來代表Stage,將具有先後順序的各個Stage連到一起,就構成了整個流水線。跟Stream相關類和介面的繼承關係圖示。
還有IntPipeline, LongPipeline, DoublePipeline沒在圖中畫出,這三個類專門為三種基本型別(不是包裝型別)而定製的,跟ReferencePipeline是並列關係。圖中Head用於表示第一個Stage,即呼叫呼叫諸如Collection.stream()方法產生的Stage,很顯然這個Stage裡不包含任何操作;StatelessOp和StatefulOp分別表示無狀態和有狀態的Stage,對應於無狀態和有狀態的中間操作。
Stream流水線組織結構示意圖如下:
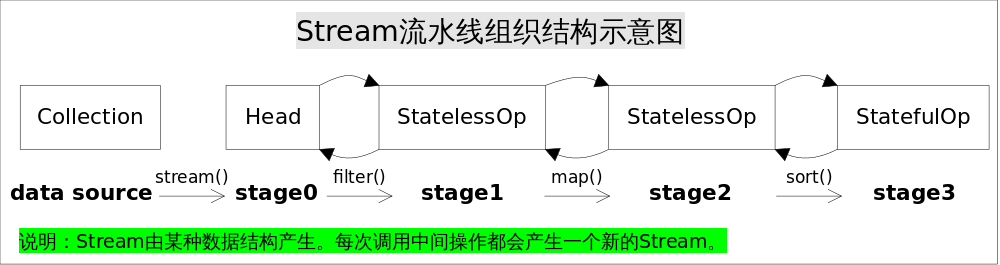
圖中通過Collection.stream()方法得到Head也就是stage0,緊接著呼叫一系列的中間操作,不斷產生新的Stream。這些Stream物件以雙向連結串列的形式組織在一起,構成整個流水線,由於每個Stage都記錄了前一個Stage和本次的操作以及回撥函式,依靠這種結構就能建立起對資料來源的所有操作。這就是Stream記錄操作的方式。
>> 操作如何疊加
以上只是解決了操作記錄的問題,要想讓流水線起到應有的作用我們需要一種將所有操作疊加到一起的方案。你可能會覺得這很簡單,只需要從流水線的head開始依次執行每一步的操作(包括回撥函式)就行了。這聽起來似乎是可行的,但是你忽略了前面的Stage並不知道後面Stage到底執行了哪種操作,以及回撥函式是哪種形式。換句話說,只有當前Stage本身才知道該如何執行自己包含的動作。這就需要有某種協議來協調相鄰Stage之間的呼叫關係。
這種協議由Sink介面完成,Sink介面包含的方法如下表所示:
| 方法名 | 作用 |
| void begin(long size) | 開始遍歷元素之前呼叫該方法,通知Sink做好準備。 |
| void end() | 所有元素遍歷完成之後呼叫,通知Sink沒有更多的元素了。 |
| boolean cancellationRequested() | 是否可以結束操作,可以讓短路操作儘早結束。 |
| void accept(T t) | 遍歷元素時呼叫,接受一個待處理元素,並對元素進行處理。Stage把自己包含的操作和回撥方法封裝到該方法裡,前一個Stage只需要呼叫當前Stage.accept(T t)方法就行了。 |
有了上面的協議,相鄰Stage之間呼叫就很方便了,每個Stage都會將自己的操作封裝到一個Sink裡,前一個Stage只需呼叫後一個Stage的accept()方法即可,並不需要知道其內部是如何處理的。當然對於有狀態的操作,Sink的begin()和end()方法也是必須實現的。比如Stream.sorted()是一個有狀態的中間操作,其對應的Sink.begin()方法可能建立一個乘放結果的容器,而accept()方法負責將元素新增到該容器,最後end()負責對容器進行排序。對於短路操作,Sink.cancellationRequested()也是必須實現的,比如Stream.findFirst()是短路操作,只要找到一個元素,cancellationRequested()就應該返回true,以便呼叫者儘快結束查詢。Sink的四個介面方法常常相互協作,共同完成計算任務。實際上Stream API內部實現的的本質,就是如何過載Sink的這四個介面方法。
有了Sink對操作的包裝,Stage之間的呼叫問題就解決了,執行時只需要從流水線的head開始對資料來源依次呼叫每個Stage對應的Sink.{begin(), accept(), cancellationRequested(), end()}方法就可以了。一種可能的Sink.accept()方法流程是這樣的:
void accept(U u){
1. 使用當前Sink包裝的回撥函式處理u
2. 將處理結果傳遞給流水線下游的Sink
}Sink介面的其他幾個方法也是按照這種[處理->轉發]的模型實現。下面我們結合具體例子看看Stream的中間操作是如何將自身的操作包裝成Sink以及Sink是如何將處理結果轉發給下一個Sink的。先看Stream.map()方法:
// Stream.map(),呼叫該方法將產生一個新的Stream
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
...
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override /*opWripSink()方法返回由回撥函式包裝而成Sink*/
Sink<P_OUT> opWrapSink(int flags, Sink<R> downstream) {
return new Sink.ChainedReference<P_OUT, R>(downstream) {
@Override
public void accept(P_OUT u) {
R r = mapper.apply(u);// 1. 使用當前Sink包裝的回撥函式mapper處理u
downstream.accept(r);// 2. 將處理結果傳遞給流水線下游的Sink
}
};
}
};
}上述程式碼看似複雜,其實邏輯很簡單,就是將回調函式mapper包裝到一個Sink當中。由於Stream.map()是一個無狀態的中間操作,所以map()方法返回了一個StatelessOp內部類物件(一個新的Stream),呼叫這個新Stream的opWripSink()方法將得到一個包裝了當前回調函式的Sink。
再來看一個複雜一點的例子。Stream.sorted()方法將對Stream中的元素進行排序,顯然這是一個有狀態的中間操作,因為讀取所有元素之前是沒法得到最終順序的。拋開模板程式碼直接進入問題本質,sorted()方法是如何將操作封裝成Sink的呢?sorted()一種可能封裝的Sink程式碼如下:
// Stream.sort()方法用到的Sink實現
class RefSortingSink<T> extends AbstractRefSortingSink<T> {
private ArrayList<T> list;// 存放用於排序的元素
RefSortingSink(Sink<? super T> downstream, Comparator<? super T> comparator) {
super(downstream, comparator);
}
@Override
public void begin(long size) {
...
// 建立一個存放排序元素的列表
list = (size >= 0) ? new ArrayList<T>((int) size) : new ArrayList<T>();
}
@Override
public void end() {
list.sort(comparator);// 只有元素全部接收之後才能開始排序
downstream.begin(list.size());
if (!cancellationWasRequested) {// 下游Sink不包含短路操作
list.forEach(downstream::accept);// 2. 將處理結果傳遞給流水線下游的Sink
}
else {// 下游Sink包含短路操作
for (T t : list) {// 每次都呼叫cancellationRequested()詢問是否可以結束處理。
if (downstream.cancellationRequested()) break;
downstream.accept(t);// 2. 將處理結果傳遞給流水線下游的Sink
}
}
downstream.end();
list = null;
}
@Override
public void accept(T t) {
list.add(t);// 1. 使用當前Sink包裝動作處理t,只是簡單的將元素新增到中間列表當中
}
}上述程式碼完美的展現了Sink的四個介面方法是如何協同工作的:
- 首先beging()方法告訴Sink參與排序的元素個數,方便確定中間結果容器的的大小;
- 之後通過accept()方法將元素新增到中間結果當中,最終執行時呼叫者會不斷呼叫該方法,直到遍歷所有元素;
- 最後end()方法告訴Sink所有元素遍歷完畢,啟動排序步驟,排序完成後將結果傳遞給下游的Sink;
- 如果下游的Sink是短路操作,將結果傳遞給下游時不斷詢問下游cancellationRequested()是否可以結束處理。
>> 疊加之後的操作如何執行
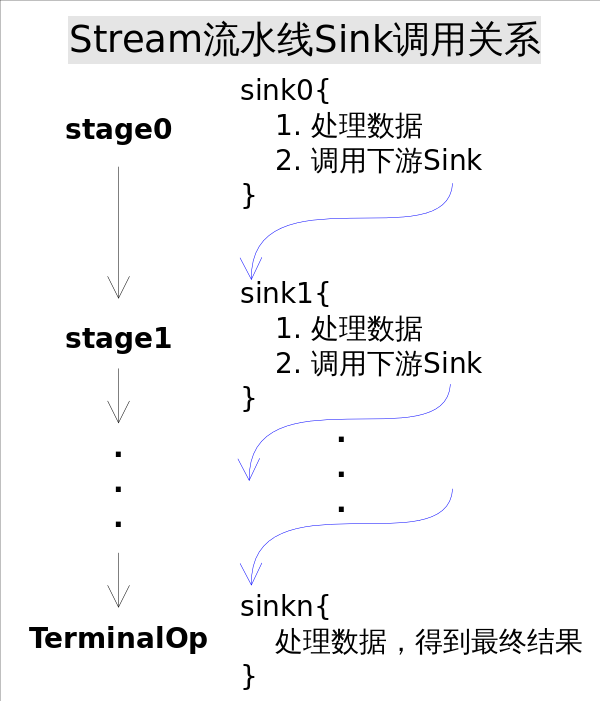
Sink完美封裝了Stream每一步操作,並給出了[處理->轉發]的模式來疊加操作。這一連串的齒輪已經咬合,就差最後一步撥動齒輪啟動執行。是什麼啟動這一連串的操作呢?也許你已經想到了啟動的原始動力就是結束操作(Terminal Operation),一旦呼叫某個結束操作,就會觸發整個流水線的執行。
結束操作之後不能再有別的操作,所以結束操作不會建立新的流水線階段(Stage),直觀的說就是流水線的連結串列不會在往後延伸了。結束操作會建立一個包裝了自己操作的Sink,這也是流水線中最後一個Sink,這個Sink只需要處理資料而不需要將結果傳遞給下游的Sink(因為沒有下游)。對於Sink的[處理->轉發]模型,結束操作的Sink就是呼叫鏈的出口。
我們再來考察一下上游的Sink是如何找到下游Sink的。一種可選的方案是在PipelineHelper中設定一個Sink欄位,在流水線中找到下游Stage並訪問Sink欄位即可。但Stream類庫的設計者沒有這麼做,而是設定了一個Sink AbstractPipeline.opWrapSink(int flags, Sink downstream)方法來得到Sink,該方法的作用是返回一個新的包含了當前Stage代表的操作以及能夠將結果傳遞給downstream的Sink物件。為什麼要產生一個新物件而不是返回一個Sink欄位?這是因為使用opWrapSink()可以將當前操作與下游Sink(上文中的downstream引數)結合成新Sink。試想只要從流水線的最後一個Stage開始,不斷呼叫上一個Stage的opWrapSink()方法直到最開始(不包括stage0,因為stage0代表資料來源,不包含操作),就可以得到一個代表了流水線上所有操作的Sink,用程式碼表示就是這樣:
// AbstractPipeline.wrapSink()
// 從下游向上遊不斷包裝Sink。如果最初傳入的sink代表結束操作,
// 函式返回時就可以得到一個代表了流水線上所有操作的Sink。
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
...
for (AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}現在流水線上從開始到結束的所有的操作都被包裝到了一個Sink裡,執行這個Sink就相當於執行整個流水線,執行Sink的程式碼如下:
// AbstractPipeline.copyInto(), 對spliterator代表的資料執行wrappedSink代表的操作。
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
...
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());// 通知開始遍歷
spliterator.forEachRemaining(wrappedSink);// 迭代
wrappedSink.end();// 通知遍歷結束
}
...
}上述程式碼首先呼叫wrappedSink.begin()方法告訴Sink資料即將到來,然後呼叫spliterator.forEachRemaining()方法對資料進行迭代(Spliterator是容器的一種迭代器,參閱),最後呼叫wrappedSink.end()方法通知Sink資料處理結束。邏輯如此清晰。
>> 執行後的結果在哪裡
最後一個問題是流水線上所有操作都執行後,使用者所需要的結果(如果有)在哪裡?首先要說明的是不是所有的Stream結束操作都需要返回結果,有些操作只是為了使用其副作用(Side-effects),比如使用Stream.forEach()方法將結果打印出來就是常見的使用副作用的場景(事實上,除了列印之外其他場景都應避免使用副作用),對於真正需要返回結果的結束操作結果存在哪裡呢?
特別說明:副作用不應該被濫用,也許你會覺得在Stream.forEach()裡進行元素收集是個不錯的選擇,就像下面程式碼中那樣,但遺憾的是這樣使用的正確性和效率都無法保證,因為Stream可能會並行執行。大多數使用副作用的地方都可以使用歸約操作更安全和有效的完成。
// 錯誤的收集方式
ArrayList<String> results = new ArrayList<>();
stream.filter(s -> pattern.matcher(s).matches())
.forEach(s -> results.add(s)); // Unnecessary use of side-effects!
// 正確的收集方式
List<String>results =
stream.filter(s -> pattern.matcher(s).matches())
.collect(Collectors.toList()); // No side-effects!回到流水線執行結果的問題上來,需要返回結果的流水線結果存在哪裡呢?這要分不同的情況討論,下表給出了各種有返回結果的Stream結束操作。
| 返回型別 | 對應的結束操作 |
| boolean | anyMatch() allMatch() noneMatch() |
| Optional | findFirst() findAny() |
| 歸約結果 | reduce() collect() |
| 陣列 | toArray() |
- 對於表中返回boolean或者Optional的操作(Optional是存放 一個 值的容器)的操作,由於值返回一個值,只需要在對應的Sink中記錄這個值,等到執行結束時返回就可以了。
- 對於歸約操作,最終結果放在使用者呼叫時指定的容器中(容器型別通過收集器指定)。collect(), reduce(), max(), min()都是歸約操作,雖然max()和min()也是返回一個Optional,但事實上底層是通過呼叫reduce()方法實現的。
- 對於返回是陣列的情況,毫無疑問的結果會放在陣列當中。這麼說當然是對的,但在最終返回陣列之前,結果其實是儲存在一種叫做Node的資料結構中的。Node是一種多叉樹結構,元素儲存在樹的葉子當中,並且一個葉子節點可以存放多個元素。這樣做是為了並行執行方便。關於Node的具體結構,我們會在下一節探究Stream如何並行執行時給出詳細說明。
結語
本文詳細介紹了Stream流水線的組織方式和執行過程,學習本文將有助於理解原理並寫出正確的Stream程式碼,同時打消你對Stream API效率方面的顧慮。如你所見,Stream API實現如此巧妙,即使我們使用外部迭代手動編寫等價程式碼,也未必更加高效。
相關推薦
深入理解Java Stream流水線
前面我們已經學會如何使用Stream API,用起來真的很爽,但簡潔的方法下面似乎隱藏著無盡的祕密,如此強大的API是如何實現的呢?Pipeline是怎麼執行的,每次方法呼叫都會導致一次迭代嗎?自動並行又是怎麼做到的,執行緒個數是多少?本節我們學習Stream流水線的原理,這是Stream實現的關鍵所在。 首
深入理解 Java中的 流 (Stream)
重要 抽象 bool sta 也會 簡單 throws image true 首先,流是什麽? 流是個抽象的概念,是對輸入輸出設備的抽象,Java程序中,對於數據的輸入/輸出操作都是以“流”的方式進行。設備可以是文件,網絡,內存等。 流具有方向性,至於是輸入流還是輸出流則
深入理解Java虛擬機- 學習筆記 - 虛擬機類加載機制
支持 pub eth 獲取 事件 必須 string 沒有 字節碼 虛擬機把描述類的數據從Class文件加載道內存,並對數據進行校驗,轉換解析和初始化,最終形成可以被虛擬機直接使用的Java類型,這就是虛擬機的類加載機制。在Java裏,類型的加載、連接和初始化過程都是在程序
JVM運行時數據區--深入理解Java虛擬機 讀後感
出棧 很好 棧幀 最大 出錯 生命周期 所有 img 就會 程序計數器 程序計數器是線程私有的區域,很好理解嘛~,每個線程當然得有個計數器記錄當前執行到那個指令。占用的內存空間小,可以把它看成是當前線程所執行的字節碼的行號指示器。如果線程在執行Java方法
深入理解JAVA集合系列四:ArrayList源碼解讀
結束 了解 數組下標 size new 數組元素 開始 ini rem 在開始本章內容之前,這裏先簡單介紹下List的相關內容。 List的簡單介紹 有序的collection,用戶可以對列表中每個元素的插入位置進行精確的控制。用戶可以根據元素的整數索引(在列表中的位置)訪
深入理解JAVA集合系列三:HashMap的死循環解讀
現在 最新 star and 場景 所有 image cap 時也 由於在公司項目中偶爾會遇到HashMap死循環造成CPU100%,重啟後問題消失,隔一段時間又會反復出現。今天在這裏來仔細剖析下多線程情況下HashMap所帶來的問題: 1、多線程put操作後,get操作導
深入理解JAVA I/O系列三:字符流詳解
buffer 情況 二進制文件 感到 復制代碼 使用範圍 轉換 fileread 方式 字符流為何存在 既然字節流提供了能夠處理任何類型的輸入/輸出操作的功能,那為什麽還要存在字符流呢?容我慢慢道來,字節流不能直接操作Unicode字符,因為一個字符有兩個字節,字節流一次只
重讀《深入理解Java虛擬機》
-xmx 垃圾收集 劃分 tac 棧內存 列表 進行 nbsp 申請 一、Java虛擬機內存區域如何劃分 1、Java虛擬機內存區域的劃分 區域名稱 作用(用途) 類型 特點 虛擬機規定異常情況 其他說明 1 程序計數器 指示當前正在執行的字節碼指
深入理解java關鍵字--static
ack col 之間 jvm -s nbsp 代碼 實例變量 family static 關鍵字是java中經常用到的一個關鍵字,在面試中也會經常遇到的一個問題,下面詳細描述這個關鍵字的相關知識點。
深入理解 Java 虛擬機之學習筆記(1)
over 信息 hotspot 體系 ima 模塊化 介紹 style 創建 本書結構: 從宏觀的角度介紹了整個Java技術體系、Java和JVM的發展歷程、模塊化,以及JDK的編譯 講解了JVM的自動內存管理,包括虛擬機內存區域的劃分原理以及各種內存溢出異常產
深入理解java虛擬機7---線程安全 & 鎖優化
err iou nan gpa egg aik risl cpn hang python%E5%AD%A6%E4%B9%A0%20%20%20%20%20%E5%8F%98%E9%87%8F%E7%9A%84%E6%93%8D%E4%BD%9C%20%E4%B8%8E%20
深入理解Java PriorityQueue
() 計算 ren span ring amp exception 刪除 聯系 深入理解Java PriorityQueue PriorityQueue 本文github地址 Java中PriorityQueue通過二叉小頂堆實現,可以用一棵完全二叉樹表示。本文從Queu
《深入理解Java虛擬機》筆記04 -- 並發鎖
server som 競爭 包括 系統 cap cnblogs blocks 嘗試 Java虛擬機在操作系統層面會先盡一切可能在虛擬機層面上解決競爭關系,盡可能避免真實的競爭發生。同時,在競爭不激烈的場合,也會試圖消除不必要的競爭。實現這些手段的方法包括:偏向鎖、輕量級鎖、
深入理解Java:類加載機制及反射
指定 請求 image vm虛擬機 常量池 使用 元素 靜態 創建 一、Java類加載機制 1.概述 Class文件由類裝載器裝載後,在JVM中將形成一份描述Class結構的元信息對象,通過該元信息對象可以獲知Class的結構信息:如構造函數,屬性和方法等,J
《深入理解Java虛擬機:JVM高級屬性與最佳實踐》讀書筆記(更新中)
pen 內存區域 深度 span 進化 ria 最短 描述 core 第一章:走進Java 概述 Java技術體系 Java發展史 Java虛擬機發展史 1996年 JDK1.0,出現Sun Classic VM HotSpot VM, 它是 Sun JDK 和 Open
深入理解JAVA虛擬機之JVM性能篇---基礎知識點
默認 生命周期 ima 線程 images 對象 情況 -- 是否 一、堆與棧 堆和棧是程序運行的關鍵,其間的關系有必要理清楚,兩者如下圖所示: 1. 堆: 所有線程共享,堆中只負責存儲對象信息。 2. 棧: 在Java中每個線程都會有一個相應的線
深入理解JAVA虛擬機之JVM性能篇---垃圾回收
小數據 alt tro 調優 permsize 多次 快速 com src 一、基本垃圾回收算法 1. 按基本回收策略分 1) 引用計數(Reference Counting) 對象增加一個引用,即增加一個計數,刪除一個引用則減少一個計數。垃圾回收時,只用收集計
深入理解Java:註解(Annotation)--註解處理器
fault this urn 復制代碼 lena ide set java lec 深入理解Java:註解(Annotation)--註解處理器 如果沒有用來讀取註解的方法和工作,那麽註解也就不會比註釋更有用處了。使用註解的過程中,很重要的一部分就是創建於
深入理解Java虛擬機——java內存區域與內存溢出異常(一)
線程 文件的 語言 沒有 虛擬 深入理解java 十倍 並且 周期 Java虛擬機全稱:java virtual machine;是Java開發語言中,用來運行Java字節碼文件的平臺;通俗的講,就是一個程序。它提供對Java字節碼的解釋及運行,從而使Java語言能獨立於各
深入理解Java虛擬機讀書筆記---運行時數據區域
強制 申請 異常 模型 分配內存 類信息 gist 運行時 過程 運行時數據區域 1.程序計數器 程序計數器(Program Counter Register)是一塊較小的內存空間,它可以看作是當前線程所執行的字節碼的行號指示器。字節碼解釋器工作時就是通過改變這