
cuda學習從入門到精通-第一篇
在老闆的要求下,本博主從2012年上高效能運算課程開始接觸CUDA程式設計,隨後將該技術應用到了實際專案中,使處理程式加速超過1K,可見基於圖形顯示器的平行計算對於追求速度的應用來說無疑是一個理想的選擇。還有不到一年畢業,怕是畢業後這些技術也就隨畢業而去,準備這個暑假開闢一個CUDA專欄,從入門到精通,步步為營,順便分享設計的一些經驗教訓,希望能給學習CUDA的童鞋提供一定指導。個人能力所及,錯誤難免,歡迎討論。
PS:申請專欄好像需要先發原創帖超過15篇。。。算了,先寫夠再申請吧,到時候一併轉過去。
NVIDIA於2006年推出CUDA(Compute Unified Devices Architecture),可以利用其推出的GPU進行通用計算,將平行計算從大型叢集擴充套件到了普通顯示卡,使得使用者只需要一臺帶有Geforce顯示卡的筆記本就能跑較大規模的並行處理程式。
使用顯示卡的好處是,和大型叢集相比功耗非常低,成本也不高,但效能很突出。以我的筆記本為例,Geforce 610M,用DeviceQuery程式測試,可得到如下硬體引數:
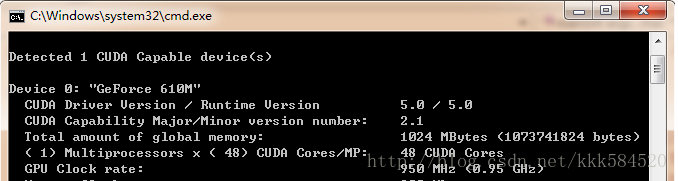
計算能力達48X0.95 = 45.6 GFLOPS。而筆記本的CPU引數如下:
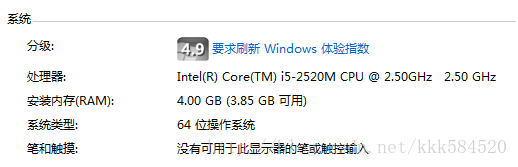
CPU計算能力為(4核):2.5G*4 = 10GFLOPS,可見,顯示卡計算效能是4核i5 CPU的4~5倍,因此我們可以充分利用這一資源來對一些耗時的應用進行加速。
好了,工欲善其事必先利其器,為了使用CUDA對GPU進行程式設計,我們需要準備以下必備工具:
1. 硬體平臺,就是顯示卡,如果你用的不是NVIDIA的顯示卡,那麼只能說抱歉,其他都不支援CUDA。
2. 作業系統,我用過windows XP,Windows 7都沒問題,本部落格用Windows7。
3. C編譯器,建議VS2008,和本部落格一致。
4. CUDA編譯器NVCC,可以免費免註冊免license從官網下載CUDA ToolkitCUDA下載,最新版本為5.0,本部落格用的就是該版本。
5. 其他工具(如Visual Assist,輔助程式碼高亮)
準備完畢,開始安裝軟體。VS2008安裝比較費時間,建議安裝完整版(NVIDIA官網說Express版也可以),過程不必詳述。CUDA Toolkit 5.0裡面包含了NVCC編譯器、設計文件、設計例程、CUDA執行時庫、CUDA標頭檔案等必備的原材料。
安裝完畢,我們在桌面上發現這個圖示:
不錯,就是它,雙擊執行,可以看到一大堆例程。我們找到Simple OpenGL這個執行看看效果:
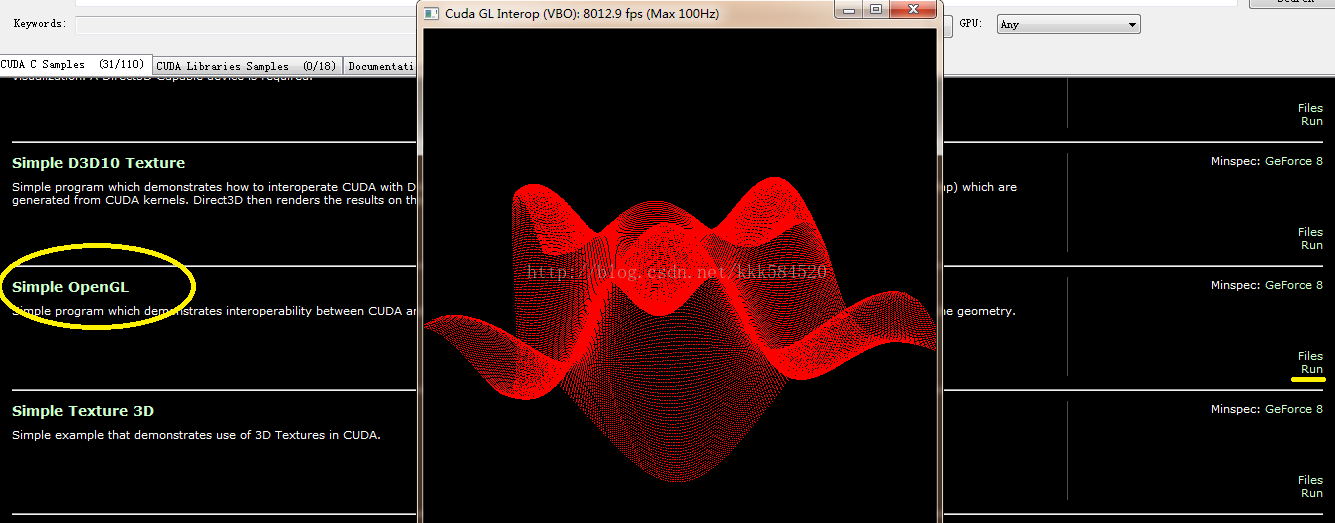
點右邊黃線標記處的Run即可看到美妙的三維正弦曲面,滑鼠左鍵拖動可以轉換角度,右鍵拖動可以縮放。如果這個執行成功,說明你的環境基本搭建成功。
出現問題的可能:
1. 你使用遠端桌面連線登入到另一臺伺服器,該伺服器上有顯示卡支援CUDA,但你遠端終端不能執行CUDA程式。這是因為遠端登入使用的是你本地顯示卡資源,在遠端登入時看不到伺服器端的顯示卡,所以會報錯:沒有支援CUDA的顯示卡!解決方法:1. 遠端伺服器裝兩塊顯示卡,一塊只用於顯示,另一塊用於計算;2.不要用圖形介面登入,而是用命令列介面如telnet登入。
2.有兩個以上顯示卡都支援CUDA的情況,如何區分是在哪個顯示卡上執行?這個需要你在程式裡控制,選擇符合一定條件的顯示卡,如較高的時鐘頻率、較大的視訊記憶體、較高的計算版本等。詳細操作見後面的部落格。
好了,先說這麼多,下一節我們介紹如何在VS2008中給GPU程式設計。書接上回,我們既然直接執行例程成功了,接下來就是了解如何實現例程中的每個環節。當然,我們先從簡單的做起,一般程式語言都會找個helloworld例子,而我們的顯示卡是不會說話的,只能做一些簡單的加減乘除運算。所以,CUDA程式的helloworld,我想應該最合適不過的就是向量加了。
開啟VS2008,選擇File->New->Project,彈出下面對話方塊,設定如下:
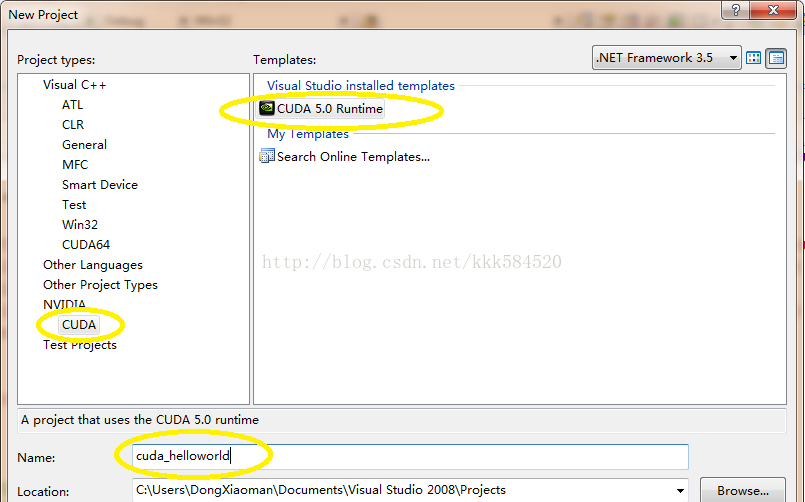
之後點OK,直接進入工程介面。
工程中,我們看到只有一個.cu檔案,內容如下:
- #include "cuda_runtime.h"
- #include "device_launch_parameters.h"
- #include <stdio.h>
- cudaError_t addWithCuda(int *c, constint *a, constint *b, size_t size);
- __global__ void addKernel(int *c, constint *a, constint *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
- int main()
- {
- constint arraySize = 5;
- constint a[arraySize] = { 1, 2, 3, 4, 5 };
- constint b[arraySize] = { 10, 20, 30, 40, 50 };
- int c[arraySize] = { 0 };
- // Add vectors in parallel.
- cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "addWithCuda failed!");
- return 1;
- }
- printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
- c[0], c[1], c[2], c[3], c[4]);
- // cudaThreadExit must be called before exiting in order for profiling and
- // tracing tools such as Nsight and Visual Profiler to show complete traces.
- cudaStatus = cudaThreadExit();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaThreadExit failed!");
- return 1;
- }
- return 0;
- }
- // Helper function for using CUDA to add vectors in parallel.
- cudaError_t addWithCuda(int *c, constint *a, constint *b, size_t size)
- {
- int *dev_a = 0;
- int *dev_b = 0;
- int *dev_c = 0;
- cudaError_t cudaStatus;
- // Choose which GPU to run on, change this on a multi-GPU system.
- cudaStatus = cudaSetDevice(0);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
- goto Error;
- }
- // Allocate GPU buffers for three vectors (two input, one output) .
- cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMalloc failed!");
- goto Error;
- }
- // Copy input vectors from host memory to GPU buffers.
- cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- // Launch a kernel on the GPU with one thread for each element.
- addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
- // cudaThreadSynchronize waits for the kernel to finish, and returns
- // any errors encountered during the launch.
- cudaStatus = cudaThreadSynchronize();
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
- goto Error;
- }
- // Copy output vector from GPU buffer to host memory.
- cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
- if (cudaStatus != cudaSuccess) {
- fprintf(stderr, "cudaMemcpy failed!");
- goto Error;
- }
- Error:
- cudaFree(dev_c);
- cudaFree(dev_a);
- cudaFree(dev_b);
- return cudaStatus;
- }
- __global__ void addKernel(int *c, constint *a, constint *b)
- {
- int i = threadIdx.x;
- c[i] = a[i] + b[i];
- }
這個函式就是在GPU上執行的函式,稱之為核函式,英文名Kernel Function,注意要和作業系統核心函式區分開來。
我們直接按F7編譯,可以得到如下輸出:
- 1>------ Build started: Project: cuda_helloworld, Configuration: Debug Win32 ------
- 1>Compiling with CUDA Build Rule...
- 1>"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\bin\nvcc.exe" -G -gencode=arch=compute_10,code=\"sm_10,compute_10\" -gencode=arch=compute_20,code=\"sm_20,compute_20\" --machine 32 -ccbin "C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\bin" -Xcompiler "/EHsc /W3 /nologo /O2 /Zi /MT " -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v5.0\\include" -maxrregcount=0 --compile -o "Debug/kernel.cu.obj" kernel.cu
- 1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.gpu
- 1>tmpxft_000000ec_00000000-14_kernel.compute_10.cudafe2.gpu
- 1>tmpxft_000000ec_00000000-5_kernel.compute_20.cudafe1.gpu
- 1>tmpxft_000000ec_00000000-17_kernel.compute_20.cudafe2.gpu
- 1>kernel.cu
- 1>kernel.cu
- 1>tmpxft_000000ec_00000000-8_kernel.compute_10.cudafe1.cpp
- 1>tmpxft_000000ec_00000000-24_kernel.compute_10.ii
- 1>Linking...
- 1