
Welcome ! This is Guanpx's blog.
利用kmeans演算法進行非監督分類
1.聚類與kmeans
- 引例:2004美國普選布什51.52% 克里48.48% 實際上,如果加以妥善引導,那麼一有小部分人就會轉換立場,那麼如何找到這一小部分人以及如何在有限預算採取措施吸引他們呢?答案就是聚類(<<機器學習實戰>>第十章)
- kmeans,k均值演算法,屬於聚類演算法中的一種,屬於非監督學習。
- 聚類中的一個重要的知識就是”簇”,簡單說簇就是相似資料的集合,而在kmeans中主要是進行簇之間距離的運算,所以引入”質心”的概念,所謂質心就是代表這一簇的一個點(類比圓心),由於簇中有很多點,那麼質心的選取就是利用了”均值”,簇中所有點的平均值就是簇的質心,通過簇,一堆資料被分成k類,這就成了演算法的名字“k均值”的直觀解釋.
2.kmeans虛擬碼以及思想
Kmeans是發現給定資料集的k個簇的演算法,k是使用者給定的。
主要工作流程虛擬碼如下
create k個點作為質心 (通常是隨機選取)
while任意一個簇存在變化時
—— for 資料集中的資料點
——— for 每個質心
————- 計算質心到點的距離
————- 打擂臺 找到最小的兩者距離 記錄id
——— 將資料點分配到最近的簇(打擂臺記錄了id)
—— 更新分配後的簇的質心(簇中所有點的均值)
返回質心列表以及分配的結果矩陣
3.二分-kmeans虛擬碼以及思想
主要思想
將每個簇一分為二 選取最小更新
虛擬碼
while 簇個數小於k
—— for 每個簇
———- 記錄總誤差
———- 在給定的簇上進行k=2的kmeans演算法
———- 計算一分為二後的總誤差
—— 選擇最小誤差的那個簇進行劃分操作
返回簇以及分配情況

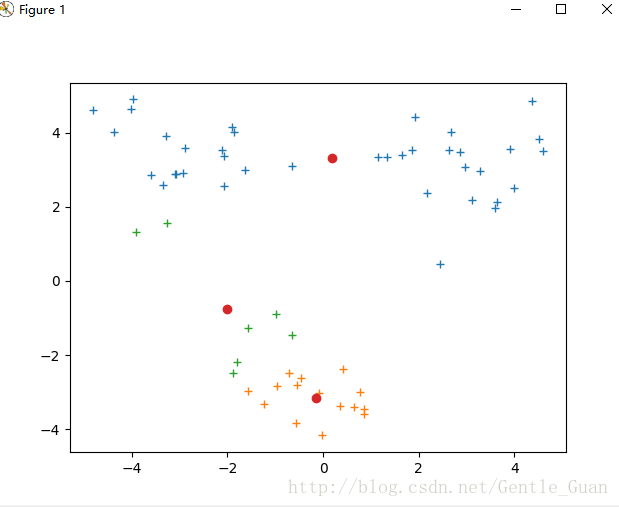
kmeans錯誤分類
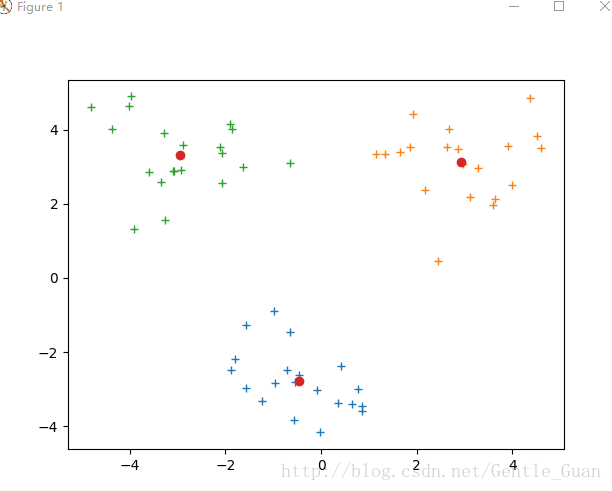
kmeans正確分類
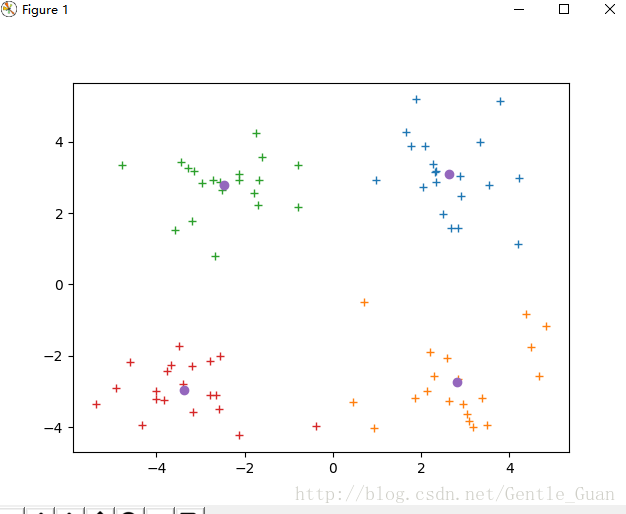
二分-kmeans未翻車
# -*- coding:utf-8 -*-
from numpy import *
import pylab as pl
# 讀取二維座標 存放在list中
def loadDataSet(fileName):
dataMat = []
with open(fileName, 'rb') as txtFile:
for line in txtFile.readlines():
init = map(float, line.split())
dataMat.append(init)
return 相關推薦
Welcome ! This is Guanpx's blog.
利用kmeans演算法進行非監督分類 1.聚類與kmeans 引例:2004美國普選布什51.52% 克里48.48% 實際上,如果加以妥善引導,那麼一有小部分人就會轉換立場,那麼如何找到這一小部分人以及如何在有限預算採取措施吸引他們呢?答案就是聚類(&l
This is Chuanqi‘s Blog
1. 費米架構 FERMI架構圖 SM SM Streaming multi-processor
【Welcome to Smile-Huang 's Blog.】This Blog aims to share my experience with you. Please leave comments if you have any thoughts.
This Blog aims to share my experience with you. Please leave comments if you have any thoughts.
Welcome to Smile-Huang 's Blog.
#include<iostream> #include<string> #include<fstream> using namespace std; //字元數目為n的詞項k-gram數目為n+1-k //預定的閾值為0.1 #define threshold 0.1
Welcome to Feng.Chang's Blog
1、檢視當前登入使用者 [[email protected] ~]$ whatis w w (1) - Show who is logged on
welcome to 浩·C's blog
#include <iostream> using namespace std; /* 思路: 注意題中說的“好晶片比壞晶片多”,所以對於每個晶片,可以記錄其他行的晶片對該
This file's format is not supported or you don't specify a correct format. 解決辦法
版本問題 body ecif 新版 ted you cor spec asp string path = @"c:\請假統計表.xlsx"; Workbook workBook = new Workbook(); workBoo
Welcome to JRX2015U43's blog!
【英文題目】 A sequence of N positive integers (10 < N < 100 000), each of them less than or equal 10000, and a positive integer S (S <
Welcome to yjjr's blog!
T1 yyy點餐 題意 給出長度為nnn的序列,求有所有不同的組合的代價總和(每種組合的代價為該組合內所有數之和) 對於全部資料,有1≤n≤1000000,0≤ai<9982443531\
Kaspars Grosu on LinkedIn: "This is happening now it's not a dream not even Science fiction #innovation #tech #ai #tesla "
This is happening now it's not a dream not even Science fiction #innovation #tech #ai #tesla Friday 7 September 2018 Real life incident.. What happens whe
What is your life purpose? @ Alex Pliutau's Blog
Each of us has a story. Own your story, it’s yours. Don’t pretend to be something you are not. Worrying about what people think blocks us from b
This is how Tesla's Autopilot system sees the idyllic streets of Paris
Navigating Paris' chaotic streets requires a high level of attentiveness to avoid colliding with another car, a herd of scooters, a pedestrian, or a garbag
This Is The Robot Being Used To Prevent Tomorrow's Car Crashes
There's a hell of a lot of testing that needs to be done to not only get to fully-autonomous cars, but to even have the sort of technology that a lot of mo
This is what it’s like to fail your interviews at Google.
The entire interview process was to take about a month, and if all went well, would encompass a series of five interviews for the role. Google’s courtship
Welcome to oopos's Blog
/*最大子段和問題:對於一個序列: -6,9,8,-10,100,-99其中:最大子段和為:100 子段長度為:10*/#include <stdio.h>#include <stdlib.h>#define MAX 101int main(void){ int i,j,k,n,
Welcome to ray's blog home page
在Java中,一個物件在可以被使用之前必須要被正確地初始化,這一點是Java規範規定的。本文試圖對Java如何執行物件的初始化做一個詳細深入地介紹(與物件初始化相同,類在被載入之後也是需要初始化的,本文在最後也會對類的初始化進行介紹,相對於物件初始化來說,類的初始化要相對
Welcome to DaxinPai's Blog
在資料分析中,遇到統計問題的時候,基本可以按照下表來: (圖片來源自網上,出處不詳) 那麼首先我們需要判斷是否是正態分佈(Normal Distribution), 四種方法: 繪製資料的直方圖,看疊加線——這是一種粗略的方法,且不是硬性( ha
Xcode 真機調試報錯:This application's application-identifier entitleme
報錯 調試 win cati app itl ati 刪除 allow This application‘s application-identifier entitlement does not match that of the installed applicatio
The Struts dispatcher cannot be found. This is usually caused by using Struts
without through san sans word needed ice ffffff per 對於struts2中的問題: org.apache.jasper.JasperException: The Struts dispatcher cannot be fou
[SQL] - Attempted to read or write protected memory. This is often an indication that other memory is corrupt. 問題之解決
img png .com 異常 hresult image select att blog 場景: 使用 Oracle.DataAccess.dll 訪問數據庫時,OracleDataAdapter 執行失敗。 異常: System.AccessViolationExce