
linux排程器原始碼分析
引言
排程器作為作業系統的核心部件,具有非常重要的意義,其隨著linux核心的更新也不斷進行著更新。本系列文章通過linux-3.18.3原始碼進行排程器的學習和分析,一步一步將linux現有的排程器原原本本的展現出來。此篇文章作為開篇,主要介紹排程器的原理及重要資料結構。排程器介紹
隨著時代的發展,linux也從其初始版本穩步發展到今天,從2.4的非搶佔核心發展到今天的可搶佔核心,排程器無論從程式碼結構還是設計思想上也都發生了翻天覆地的變化,其普通程序的排程演算法也從O(1)到現在的CFS,一個好的排程演算法應當考慮以下幾個方面:- 公平:保證每個程序得到合理的CPU時間。
- 高效:使CPU保持忙碌狀態,即總是有程序在CPU上執行。
- 響應時間:使互動使用者的響應時間儘可能短。
- 週轉時間:使批處理使用者等待輸出的時間儘可能短。
- 吞吐量:使單位時間內處理的程序數量儘可能多。
- 負載均衡:在多核多處理器系統中提供更高的效能
程序
- 實時程序:對系統的響應時間要求很高,它們需要短的響應時間,並且這個時間的變化非常小,典型的實時程序有音樂播放器,視訊播放器等。
- 普通程序:包括互動程序和非互動程序,互動程序如文字編輯器,它會不斷的休眠,又不斷地通過滑鼠鍵盤進行喚醒,而非互動程序就如後臺維護程序,他們對IO,響應時間沒有很高的要求,比如編譯器。
排程策略
- SCHED_NORMAL:普通程序使用的排程策略,現在此排程策略使用的是CFS排程器。
- SCHED_FIFO:實時程序使用的排程策略,此排程策略的程序一旦使用CPU則一直執行,直到有比其更高優先順序的實時程序進入佇列,或者其自動放棄CPU,適用於時間性要求比較高,但每次執行時間比較短的程序。
- SCHED_RR:實時程序使用的時間片輪轉法策略,實時程序的時間片用完後,排程器將其放到佇列末尾,這樣每個實時程序都可以執行一段時間。適用於每次執行時間比較長的實時程序。
排程
首先,我們需要清楚,什麼樣的程序會進入排程器進行選擇,就是處於TASK_RUNNING狀態的程序,而其他狀態下的程序都不會進入排程器進行排程。系統發生排程的時機如下- 呼叫cond_resched()時
- 顯式呼叫schedule()時
- 從系統呼叫或者異常中斷返回使用者空間時
- 從中斷上下文返回使用者空間時
- 在系統呼叫或者異常中斷上下文中呼叫preempt_enable()時(多次呼叫preempt_enable()時,系統只會在最後一次呼叫時會排程)
- 在中斷上下文中,從中斷處理函式返回到可搶佔的上下文時(這裡是中斷下半部,中斷上半部實際上會關中斷,而新的中斷只會被登記,由於上半部處理很快,上半部處理完成後才會執行新的中斷訊號,這樣就形成了中斷可重入)
資料結構
在這一節中,我們都是以普通程序作為講解物件,因為普通程序使用的排程演算法為CFS排程演算法,它是以紅黑樹為基礎的排程演算法,其相比與實時程序的排程演算法複雜很多,而實時程序在組織結構上與普通程序沒有太大差別,演算法也較為簡單。組成形式
圖1
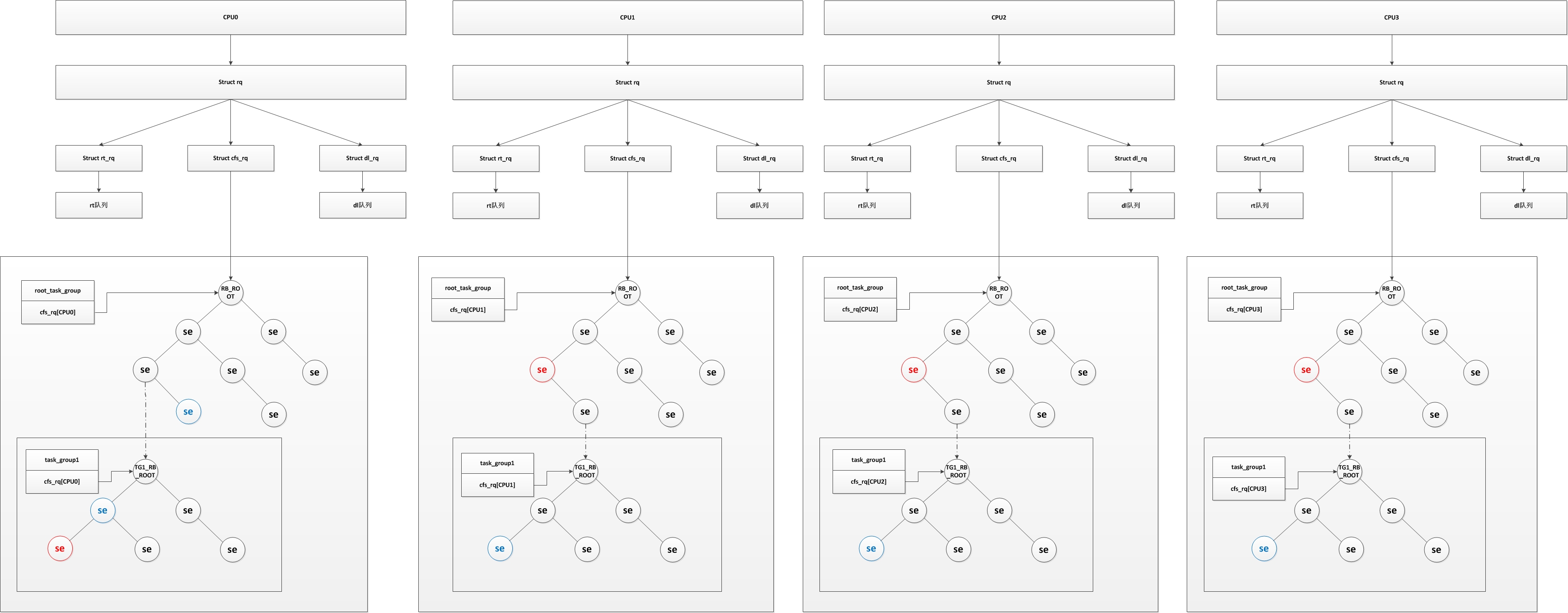
組排程(struct task_group)
我們知道,linux是一個多使用者系統,如果有兩個程序分別屬於兩個使用者,而程序的優先順序不同,會導致兩個使用者所佔用的CPU時間不同,這樣顯然是不公平的(如果優先順序差距很大,低優先順序程序所屬使用者使用CPU的時間就很小),所以核心引入組排程。如果基於使用者分組,即使程序優先順序不同,這兩個使用者使用的CPU時間都為50%。這就是為什麼圖1 中CPU0有兩個藍色將被排程的程式,如果task_group1中的執行時間還沒有使用完,而當前程序執行時間使用完後,會排程task_group1中的下一個被排程程序;相反,如果task_group1的執行時間使用結束,則呼叫上一層的下一個被排程程序。需要注意的是,一個組排程中可能會有一部分是實時程序,一部分是普通程序,這也導致這種組要能夠滿足即能在實時排程中進行排程,又可以在CFS排程中進行排程。linux可以以以下兩種方式進行程序的分組:
- 使用者ID:按照程序的USER ID進行分組,在對應的/sys/kernel/uid/目錄下會生成一個cpu.share的檔案,可以通過配置該檔案來配置使用者所佔CPU時間比例。
- cgourp(control group):生成組用於限制其所有程序,比如我生成一個組(生成後此組為空,裡面沒有程序),設定其CPU使用率為10%,並把一個程序丟進這個組中,那麼這個程序最多隻能使用CPU的10%,如果我們將多個程序丟進這個組,這個組的所有程序平分這個10%。
1 /* 程序組,用於實現組排程 */ 2 struct task_group { 3 /* 用於程序找到其所屬程序組結構 */ 4 struct cgroup_subsys_state css; 5 6 #ifdef CONFIG_FAIR_GROUP_SCHED 7 /* CFS排程器的程序組變數,在 alloc_fair_sched_group() 中程序初始化及分配記憶體 */ 8 /* 該程序組在每個CPU上都有對應的一個排程實體,因為有可能此程序組同時在兩個CPU上執行(它的A程序在CPU0上執行,B程序在CPU1上執行) */ 9 struct sched_entity **se; 10 /* 程序組在每個CPU上都有一個CFS執行佇列(為什麼需要,稍後解釋) */ 11 struct cfs_rq **cfs_rq; 12 /* 用於儲存優先順序預設為NICE 0的優先順序 */ 13 unsigned long shares; 14 15 #ifdef CONFIG_SMP 16 atomic_long_t load_avg; 17 atomic_t runnable_avg; 18 #endif 19 #endif 20 21 #ifdef CONFIG_RT_GROUP_SCHED 22 /* 實時程序排程器的程序組變數,同 CFS */ 23 struct sched_rt_entity **rt_se; 24 struct rt_rq **rt_rq; 25 26 struct rt_bandwidth rt_bandwidth; 27 #endif 28 29 struct rcu_head rcu; 30 /* 用於建立程序連結串列(屬於此排程組的程序連結串列) */ 31 struct list_head list; 32 33 /* 指向其上層的程序組,每一層的程序組都是它上一層程序組的執行佇列的一個排程實體,在同一層中,程序組和程序被同等對待 */ 34 struct task_group *parent; 35 /* 程序組的兄弟結點連結串列 */ 36 struct list_head siblings; 37 /* 程序組的兒子結點連結串列 */ 38 struct list_head children; 39 40 #ifdef CONFIG_SCHED_AUTOGROUP 41 struct autogroup *autogroup; 42 #endif 43 44 struct cfs_bandwidth cfs_bandwidth; 45 };在struct task_group結構中,最重要的成員為 struct sched_entity ** se 和 struct cfs_rq ** cfs_rq。在圖1 中,root_task_group與task_group1都只有一個,它們在初始化時會根據CPU個數為se和cfs_rq分配空間,即在task_group1和root_task_group中會為每個CPU分配一個se和cfs_rq,同理用於實時程序的 struct sched_rt_entity ** rt_se 和 struct rt_rq ** rt_rq也是一樣。為什麼這樣呢,原因就是在多核多CPU的情況下,同一程序組的程序有可能在不同CPU上同時執行,所以每個程序組都必須對每個CPU分配它的排程實體(struct sched_entity 和 struct sched_rt_entity)和執行佇列(struct cfs_rq 和 struct rt_rq)。
排程實體(struct sched_entity)
在組排程中,也涉及到排程實體這個概念,它的結構為struct sched_entity(簡稱se),就是圖1 紅黑樹中的se。其實際上就代表了一個排程物件,可以為一個程序,也可以為一個程序組。對於根的紅黑樹而言,一個程序組就相當於一個排程實體,一個程序也相當於一個排程實體。我們可以先看看其結構,如下:1 /* 一個排程實體(紅黑樹的一個結點),其包含一組或一個指定的程序,包含一個自己的執行佇列,一個父親指標,一個指向需要排程的執行佇列指標 */ 2 struct sched_entity { 3 /* 權重,在陣列prio_to_weight[]包含優先順序轉權重的數值 */ 4 struct load_weight load; /* for load-balancing */ 5 /* 實體在紅黑樹對應的結點資訊 */ 6 struct rb_node run_node; 7 /* 實體所在的程序組 */ 8 struct list_head group_node; 9 /* 實體是否處於紅黑樹執行佇列中 */ 10 unsigned int on_rq; 11 12 /* 開始執行時間 */ 13 u64 exec_start; 14 /* 總執行時間 */ 15 u64 sum_exec_runtime; 16 /* 虛擬執行時間,在時間中斷或者任務狀態發生改變時會更新 17 * 其會不停增長,增長速度與load權重成反比,load越高,增長速度越慢,就越可能處於紅黑樹最左邊被排程 18 * 每次時鐘中斷都會修改其值 19 * 具體見calc_delta_fair()函式 20 */ 21 u64 vruntime; 22 /* 程序在切換進CPU時的sum_exec_runtime值 */ 23 u64 prev_sum_exec_runtime; 24 25 /* 此排程實體中程序移到其他CPU組的數量 */ 26 u64 nr_migrations; 27 28 #ifdef CONFIG_SCHEDSTATS 29 /* 用於統計一些資料 */ 30 struct sched_statistics statistics; 31 #endif 32 33 #ifdef CONFIG_FAIR_GROUP_SCHED 34 /* 代表此程序組的深度,每個程序組都比其parent排程組深度大1 */ 35 int depth; 36 /* 父親排程實體指標,如果是程序則指向其執行佇列的排程實體,如果是程序組則指向其上一個程序組的排程實體 37 * 在 set_task_rq 函式中設定 38 */ 39 struct sched_entity *parent; 40 /* 實體所處紅黑樹執行佇列 */ 41 struct cfs_rq *cfs_rq; 42 /* 實體的紅黑樹執行佇列,如果為NULL表明其是一個程序,若非NULL表明其是排程組 */ 43 struct cfs_rq *my_q; 44 #endif 45 46 #ifdef CONFIG_SMP 47 /* Per-entity load-tracking */ 48 struct sched_avg avg; 49 #endif 50 };
實際上,紅黑樹是根據 struct rb_node 建立起關係的,不過 struct rb_node 與 struct sched_entity 是一一對應關係,也可以簡單看為一個紅黑樹結點就是一個排程實體。可以看出,在 struct sched_entity 結構中,包含了一個程序(或程序組)排程的全部資料,其被包含在 struct task_struct 結構中的se中,如下:
1 struct task_struct { 2 ........ 3 /* 表示是否在執行佇列 */ 4 int on_rq; 5 6 /* 程序優先順序 7 * prio: 動態優先順序,範圍為100~139,與靜態優先順序和補償(bonus)有關 8 * static_prio: 靜態優先順序,static_prio = 100 + nice + 20 (nice值為-20~19,所以static_prio值為100~139) 9 * normal_prio: 沒有受優先順序繼承影響的常規優先順序,具體見normal_prio函式,跟屬於什麼型別的程序有關 10 */ 11 int prio, static_prio, normal_prio; 12 /* 實時程序優先順序 */ 13 unsigned int rt_priority; 14 /* 排程類,排程處理函式類 */ 15 const struct sched_class *sched_class; 16 /* 排程實體(紅黑樹的一個結點) */ 17 struct sched_entity se; 18 /* 排程實體(實時排程使用) */ 19 struct sched_rt_entity rt; 20 #ifdef CONFIG_CGROUP_SCHED 21 /* 指向其所在程序組 */ 22 struct task_group *sched_task_group; 23 #endif 24 ........ 25 }
在 struct sched_entity 結構中,值得我們注意的成員是:
- load:權重,通過優先順序轉換而成,是vruntime計算的關鍵。
- on_rq:表明是否處於CFS紅黑樹執行佇列中,需要明確一個觀點就是,CFS執行佇列裡面包含有一個紅黑樹,但這個紅黑樹並不是CFS執行佇列的全部,因為紅黑樹僅僅是用於選擇出下一個排程程式的演算法。很簡單的一個例子,普通程式執行時,其並不在紅黑樹中,但是還是處於CFS執行佇列中,其on_rq為真。只有準備退出、即將睡眠等待和轉為實時程序的程序其CFS執行佇列的on_rq為假。
- vruntime:虛擬執行時間,排程的關鍵,其計算公式:一次排程間隔的虛擬執行時間 = 實際執行時間 * (NICE_0_LOAD / 權重)。可以看出跟實際執行時間和權重有關,紅黑樹就是以此作為排序的標準,優先順序越高的程序在執行時其vruntime增長的越慢,其可執行時間相對就長,而且也越有可能處於紅黑樹的最左結點,排程器每次都選擇最左邊的結點為下一個排程程序。注意其值為單調遞增,在每個排程器的時鐘中斷時當前程序的虛擬執行時間都會累加。單純的說就是程序們都在比誰的vruntime最小,最小的將被排程。
- cfs_rq:此排程實體所處於的CFS執行佇列。
- my_q:如果此排程實體代表的是一個程序組,那麼此排程實體就包含有一個自己的CFS執行佇列,其CFS執行佇列中存放的是此程序組中的程序,這些程序就不會在其他CFS執行佇列的紅黑樹中被包含(包括頂層紅黑樹也不會包含他們,他們只屬於這個程序組的紅黑樹)。
而在 struct task_struct 結構中,我們注意到有個排程類,裡面包含的是排程處理函式,它具體如下:
1 struct sched_class { 2 /* 下一優先順序的排程類 3 * 排程類優先順序順序: stop_sched_class -> dl_sched_class -> rt_sched_class -> fair_sched_class -> idle_sched_class 4 */ 5 const struct sched_class *next; 6 7 /* 將程序加入到執行佇列中,即將排程實體(程序)放入紅黑樹中,並對 nr_running 變數加1 */ 8 void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags); 9 /* 從執行佇列中刪除程序,並對 nr_running 變數中減1 */ 10 void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags); 11 /* 放棄CPU,在 compat_yield sysctl 關閉的情況下,該函式實際上執行先出隊後入隊;在這種情況下,它將排程實體放在紅黑樹的最右端 */ 12 void (*yield_task) (struct rq *rq); 13 bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt); 14 15 /* 檢查當前程序是否可被新程序搶佔 */ 16 void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags); 17 18 /* 19 * It is the responsibility of the pick_next_task() method that will 20 * return the next task to call put_prev_task() on the @prev task or 21 * something equivalent. 22 * 23 * May return RETRY_TASK when it finds a higher prio class has runnable 24 * tasks. 25 */ 26 /* 選擇下一個應該要執行的程序執行 */ 27 struct task_struct * (*pick_next_task) (struct rq *rq, 28 struct task_struct *prev); 29 /* 將程序放回執行佇列 */ 30 void (*put_prev_task) (struct rq *rq, struct task_struct *p); 31 32 #ifdef CONFIG_SMP 33 /* 為程序選擇一個合適的CPU */ 34 int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags); 35 /* 遷移任務到另一個CPU */ 36 void (*migrate_task_rq)(struct task_struct *p, int next_cpu); 37 /* 用於上下文切換後 */ 38 void (*post_schedule) (struct rq *this_rq); 39 /* 用於程序喚醒 */ 40 void (*task_waking) (struct task_struct *task); 41 void (*task_woken) (struct rq *this_rq, struct task_struct *task); 42 /* 修改程序的CPU親和力(affinity) */ 43 void (*set_cpus_allowed)(struct task_struct *p, 44 const struct cpumask *newmask); 45 /* 啟動執行佇列 */ 46 void (*rq_online)(struct rq *rq); 47 /* 禁止執行佇列 */ 48 void (*rq_offline)(struct rq *rq); 49 #endif 50 /* 當程序改變它的排程類或程序組時被呼叫 */ 51 void (*set_curr_task) (struct rq *rq); 52 /* 該函式通常呼叫自 time tick 函式;它可能引起程序切換。這將驅動執行時(running)搶佔 */ 53 void (*task_tick) (struct rq *rq, struct task_struct *p, int queued); 54 /* 在程序建立時呼叫,不同調度策略的程序初始化不一樣 */ 55 void (*task_fork) (struct task_struct *p); 56 /* 在程序退出時會使用 */ 57 void (*task_dead) (struct task_struct *p); 58 59 /* 用於程序切換 */ 60 void (*switched_from) (struct rq *this_rq, struct task_struct *task); 61 void (*switched_to) (struct rq *this_rq, struct task_struct *task); 62 /* 改變優先順序 */ 63 void (*prio_changed) (struct rq *this_rq, struct task_struct *task, 64 int oldprio); 65 66 unsigned int (*get_rr_interval) (struct rq *rq, 67 struct task_struct *task); 68 69 void (*update_curr) (struct rq *rq); 70 71 #ifdef CONFIG_FAIR_GROUP_SCHED 72 void (*task_move_group) (struct task_struct *p, int on_rq); 73 #endif 74 };
這個排程類具體有什麼用呢,實際上在核心中不同的排程演算法它們的操作都不相同,為了方便修改、替換排程演算法,使用了排程類,每個排程演算法只需要實現自己的排程類就可以了,CFS演算法有它的排程類,SCHED_FIFO也有它自己的排程類,當一個程序建立時,用什麼排程演算法就將其 task_struct->sched_class 指向其相應的排程類,排程器每次排程處理時,就通過當前程序的排程類函式程序操作,大大提高了可移植性和易修改性。
CFS執行佇列(struct cfs_rq)
我們現在知道,在系統中至少有一個CFS執行佇列,其就是根CFS執行佇列,而其他的程序組和程序都包含在此執行佇列中,不同的是程序組又有它自己的CFS執行佇列,其執行佇列中包含的是此程序組中的所有程序。當排程器從根CFS執行佇列中選擇了一個程序組進行排程時,程序組會從自己的CFS執行佇列中選擇一個排程實體進行排程(這個排程實體可能為程序,也可能又是一個子程序組),就這樣一直深入,直到最後選出一個程序進行執行為止。對於 struct cfs_rq 結構沒有什麼好說明的,只要確定其代表著一個CFS執行佇列,並且包含有一個紅黑樹進行選擇排程程序即可。
1 /* CFS排程的執行佇列,每個CPU的rq會包含一個cfs_rq,而每個組排程的sched_entity也會有自己的一個cfs_rq佇列 */ 2 struct cfs_rq { 3 /* CFS執行佇列中所有程序的總負載 */ 4 struct load_weight load; 5 /* 6 * nr_running: cfs_rq中排程實體數量 7 * h_nr_running: 只對程序組有效,其下所有程序組中cfs_rq的nr_running之和 8 */ 9 unsigned int nr_running, h_nr_running; 10 11 u64 exec_clock; 12 /* 當前CFS佇列上最小執行時間,單調遞增 13 * 兩種情況下更新該值: 14 * 1、更新當前執行任務的累計執行時間時 15 * 2、當任務從佇列刪除去,如任務睡眠或退出,這時候會檢視剩下的任務的vruntime是否大於min_vruntime,如果是則更新該值。 16 */ 17 u64 min_vruntime; 18 #ifndef CONFIG_64BIT 19 u64 min_vruntime_copy; 20 #endif 21 /* 該紅黑樹的root */ 22 struct rb_root tasks_timeline; 23 /* 下一個排程結點(紅黑樹最左邊結點,最左邊結點就是下個排程實體) */ 24 struct rb_node *rb_leftmost; 25 26 /* 27 * 'curr' points to currently running entity on this cfs_rq. 28 * It is set to NULL otherwise (i.e when none are currently running). 29 */ 30 /* 31 * curr: 當前正在執行的sched_entity(對於組雖然它不會在cpu上執行,但是當它的下層有一個task在cpu上執行,那麼它所在的cfs_rq就把它當做是該cfs_rq上當前正在執行的sched_entity) 32 * next: 表示有些程序急需執行,即使不遵從CFS排程也必須執行它,排程時會檢查是否next需要排程,有就排程next 33 * 34 * skip: 略過程序(不會選擇skip指定的程序排程) 35 */ 36 struct sched_entity *curr, *next, *last, *skip; 37 38 #ifdef CONFIG_SCHED_DEBUG 39 unsigned int nr_spread_over; 40 #endif 41 42 #ifdef CONFIG_SMP 43 /* 44 * CFS Load tracking 45 * Under CFS, load is tracked on a per-entity basis and aggregated up. 46 * This allows for the description of both thread and group usage (in 47 * the FAIR_GROUP_SCHED case). 48 */ 49 unsigned long runnable_load_avg, blocked_load_avg; 50 atomic64_t decay_counter; 51 u64 last_decay; 52 atomic_long_t removed_load; 53 54 #ifdef CONFIG_FAIR_GROUP_SCHED 55 /* Required to track per-cpu representation of a task_group */ 56 u32 tg_runnable_contrib; 57 unsigned long tg_load_contrib; 58 59 /* 60 * h_load = weight * f(tg) 61 * 62 * Where f(tg) is the recursive weight fraction assigned to 63 * this group. 64 */ 65 unsigned long h_load; 66 u64 last_h_load_update; 67 struct sched_entity *h_load_next; 68 #endif /* CONFIG_FAIR_GROUP_SCHED */ 69 #endif /* CONFIG_SMP */ 70 71 #ifdef CONFIG_FAIR_GROUP_SCHED 72 /* 所屬於的CPU rq */ 73 struct rq *rq; /* cpu runqueue to which this cfs_rq is attached */ 74 75 /* 76 * leaf cfs_rqs are those that hold tasks (lowest schedulable entity in 77 * a hierarchy). Non-leaf lrqs hold other higher schedulable entities 78 * (like users, containers etc.) 79 * 80 * leaf_cfs_rq_list ties together list of leaf cfs_rq's in a cpu. This 81 * list is used during load balance. 82 */ 83 int on_list; 84 struct list_head leaf_cfs_rq_list; 85 /* 擁有該CFS執行佇列的程序組 */ 86 struct task_group *tg; /* group that "owns" this runqueue */ 87 88 #ifdef CONFIG_CFS_BANDWIDTH 89 int runtime_enabled; 90 u64 runtime_expires; 91 s64 runtime_remaining; 92 93 u64 throttled_clock, throttled_clock_task; 94 u64 throttled_clock_task_time; 95 int throttled, throttle_count; 96 struct list_head throttled_list; 97 #endif /* CONFIG_CFS_BANDWIDTH */ 98 #endif /* CONFIG_FAIR_GROUP_SCHED */ 99 };
- load:其儲存的是程序組中所有程序的權值總和,需要注意子程序計算vruntime時需要用到程序組的load。
CPU執行佇列(struct rq)
每個CPU都有自己的 struct rq 結構,其用於描述在此CPU上所執行的所有程序,其包括一個實時程序佇列和一個根CFS執行佇列,在排程時,排程器首先會先去實時程序佇列找是否有實時程序需要執行,如果沒有才會去CFS執行佇列找是否有進行需要執行,這就是為什麼常說的實時程序優先順序比普通程序高,不僅僅體現在prio優先順序上,還體現在排程器的設計上,至於dl執行佇列,我暫時還不知道有什麼用處,其優先順序比實時程序還高,但是建立程序時如果建立的是dl程序建立會錯誤(具體見sys_fork)。
1 /* CPU執行佇列,每個CPU包含一個struct rq */ 2 struct rq { 3 /* 處於執行佇列中所有就緒程序的load之和 */ 4 raw_spinlock_t lock; 5 6 /* 7 * nr_running and cpu_load should be in the same cacheline because 8 * remote CPUs use both these fields when doing load calculation. 9 */ 10 /* 此CPU上總共就緒的程序數,包括cfs,rt和正在執行的 */ 11 unsigned int nr_running; 12 #ifdef CONFIG_NUMA_BALANCING 13 unsigned int nr_numa_running; 14 unsigned int nr_preferred_running; 15 #endif 16 #define CPU_LOAD_IDX_MAX 5 17 /* 根據CPU歷史情況計算的負載,cpu_load[0]一直等於load.weight,當達到負載平衡時,cpu_load[1]和cpu_load[2]都應該等於load.weight */ 18 unsigned long cpu_load[CPU_LOAD_IDX_MAX]; 19 /* 最後一次更新 cpu_load 的時間 */ 20 unsigned long last_load_update_tick; 21 #ifdef CONFIG_NO_HZ_COMMON 22 u64 nohz_stamp; 23 unsigned long nohz_flags; 24 #endif 25 #ifdef CONFIG_NO_HZ_FULL 26 unsigned long last_sched_tick; 27 #endif 28 /* 是否需要更新rq的執行時間 */ 29 int skip_clock_update; 30 31 /* capture load from *all* tasks on this cpu: */ 32 /* CPU負載,該CPU上所有可執行程序的load之和,nr_running更新時這個值也必須更新 */ 33 struct load_weight load; 34 unsigned long nr_load_updates; 35 /* 進行上下文切換次數,只有proc會使用這個 */ 36 u64 nr_switches; 37 38 /* cfs排程執行佇列,包含紅黑樹的根 */ 39 struct cfs_rq cfs; 40 /*