
Spark RDDs vs DataFrames vs SparkSQL
-
單條記錄的隨機查詢
-
aggregation聚合並且sorting後輸出
使用以下Spark的三種方式來解決上面的2個問題,對比效能。
-
Using RDD’s
-
Using DataFrames
-
Using SparkSQL
資料來源
-
在HDFS中3個檔案中儲存的9百萬不同記錄
- 每條記錄11個欄位
-
總大小 1.4 GB
實驗環境
-
HDP 2.4
-
Hadoop version 2.7
-
Spark 1.6
-
HDP Sandbox
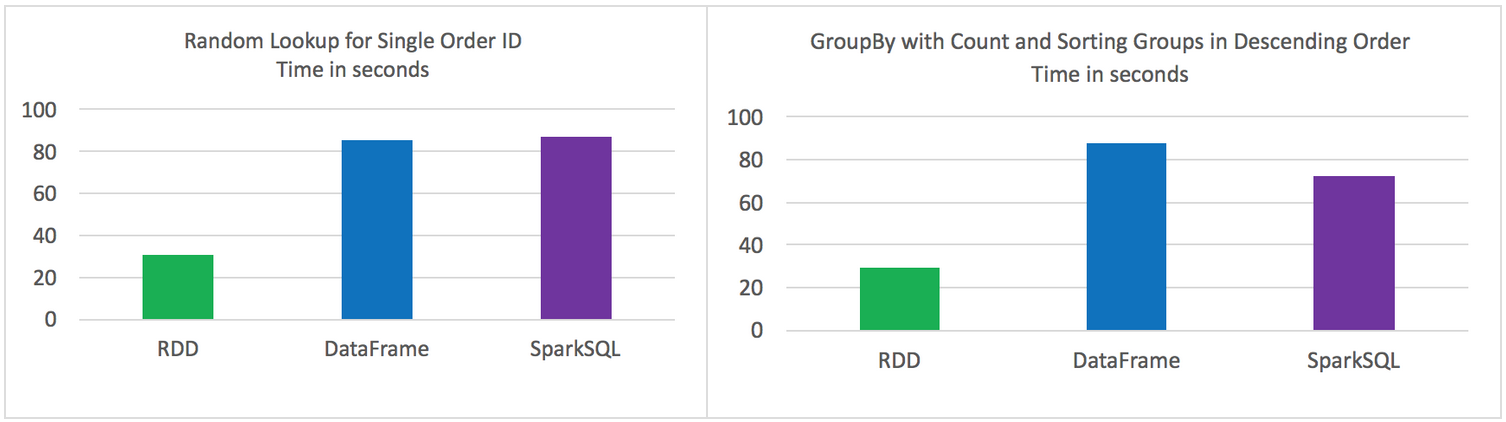
測試結果
-
原始的RDD 比 DataFrames 和 SparkSQL效能要好
-
DataFrames 和 SparkSQL 效能差不多
-
使用DataFrames 和 SparkSQL 比 RDD 操作更直觀
-
Jobs都是獨立執行,沒有其他job的干擾
2個操作
-
Random lookup against 1 order ID from 9 Million unique order ID's
-
GROUP all the different products with their total COUNTS and SORT DESCENDING by product name
程式碼
RDD Random Lookup
#!/usr/bin/env python from time import time from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("rdd_random_lookup") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## filter where the order_id, the second field, is equal to 96922894 print lines.map(lambda line: line.split('|')).filter(lambda line: int(line[1]) == 96922894).collect() tt = str(time() - t0) print "RDD lookup performed in " + tt + " seconds"
DataFrame Random Lookup
#!/usr/bin/env python from time import time from pyspark.sql import * from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("data_frame_random_lookup") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## create data frame orders_df = sqlContext.createDataFrame( \ lines.map(lambda l: l.split("|")) \ .map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \ country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) ## filter where the order_id, the second field, is equal to 96922894 orders_df.where(orders_df['order_id'] == 96922894).show() tt = str(time() - t0) print "DataFrame performed in " + tt + " seconds"
SparkSQL Random Lookup
#!/usr/bin/env python from time import time from pyspark.sql import * from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("spark_sql_random_lookup") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## create data frame orders_df = sqlContext.createDataFrame( \ lines.map(lambda l: l.split("|")) \ .map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \ country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) ## register data frame as a temporary table orders_df.registerTempTable("orders") ## filter where the customer_id, the first field, is equal to 96922894 print sqlContext.sql("SELECT * FROM orders where order_id = 96922894").collect() tt = str(time() - t0) print "SparkSQL performed in " + tt + " seconds"
RDD with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("rdd_aggregation_and_sort") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) counts = lines.map(lambda line: line.split('|')) \ .map(lambda x: (x[5], 1)) \ .reduceByKey(lambda a, b: a + b) \ .map(lambda x:(x[1],x[0])) \ .sortByKey(ascending=False) for x in counts.collect(): print x[1] + '\t' + str(x[0]) tt = str(time() - t0) print "RDD GroupBy performed in " + tt + " seconds"
DataFrame with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time from pyspark.sql import * from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("data_frame_aggregation_and_sort") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## create data frame orders_df = sqlContext.createDataFrame( \ lines.map(lambda l: l.split("|")) \ .map(lambda p: Row(cust_id=int(p[0]), order_id=int(p[1]), email_hash=p[2], ssn_hash=p[3], product_id=int(p[4]), product_desc=p[5], \ country=p[6], state=p[7], shipping_carrier=p[8], shipping_type=p[9], shipping_class=p[10] ) ) ) results = orders_df.groupBy(orders_df['product_desc']).count().sort("count",ascending=False) for x in results.collect(): print x tt = str(time() - t0) print "DataFrame performed in " + tt + " seconds"
SparkSQL with GroupBy, Count, and Sort Descending
#!/usr/bin/env python from time import time from pyspark.sql import * from pyspark import SparkConf, SparkContext conf = (SparkConf() .setAppName("spark_sql_aggregation_and_sort") .set("spark.executor.instances", "10") .set("spark.executor.cores", 2) .set("spark.dynamicAllocation.enabled", "false") .set("spark.shuffle.service.enabled", "false") .set("spark.executor.memory", "500MB")) sc = SparkContext(conf = conf) sqlContext = SQLContext(sc) t0 = time() path = "/data/customer_orders*" lines = sc.textFile(path) ## create data frame orders_df = sqlContext.createDataFrame(lines.map(lambda l: l.split("|")) \ .map(lambda r: Row(product=r[5]))) ## register data frame as a temporary table orders_df.registerTempTable("orders") results = sqlContext.sql("SELECT product, count(*) AS total_count FROM orders GROUP BY product ORDER BY total_count DESC") for x in results.collect(): print x tt = str(time() - t0) print "SparkSQL performed in " + tt + " seconds"
原文:https://community.hortonworks.com/articles/42027/rdd-vs-dataframe-vs-sparksql.html
相關推薦
Spark RDDs vs DataFrames vs SparkSQL
單條記錄的隨機查詢 aggregation聚合並且sorting後輸出 使用以下Spark的三種方式來解決上面的2個問題,對比效能。 Using RDD’s Using DataFrames Using SparkSQL 資料來源
Spark DataFrame 的 groupBy vs groupByKey
在使用 Spark SQL 的過程中,經常會用到 groupBy 這個函式進行一些統計工作。但是會發現除了 groupBy 外,還有一個 groupByKey(注意RDD 也有一個 groupByKey,而這裡的 groupByKey 是 DataFrame 的 ) 。這個 groupByKey 引起了我的好
spark RDD,reduceByKey vs groupByKey
Spark 中有兩個類似的api,分別是 reduceByKey 和 groupByKey 。這兩個的功能類似,但底層實現卻有些不同,那麼為什麼要這樣設計呢?我們來從原始碼的角度分析一下。 先看兩者的呼叫順序(都是使用預設的Partitioner,即defaultPartitioner) 所用 spark 版
RUN vs CMD vs ENTRYPOINT - 每天5分鐘玩轉 Docker 容器技術(17)
docker 教程 容器 RUN、CMD 和 ENTRYPOINT 這三個 Dockerfile 指令看上去很類似很容易混淆。本節將通過實踐詳細討論它們的區別。簡單的說RUN 執行命令並創建新的鏡像層RUN 經常用於安裝軟件包。CMD 設置容器啟動後默認執行的命令及其參數但 CMD 能夠被 doc
A*算法、導航網格、路徑點尋路對比(A-Star VS NavMesh VS WayPoint)
所有 -s mes 路徑 sta 常用 能夠 unity str 在Unity3d中,我們一般常用的尋路算法: 1.A*算法插件 與貪婪算法不一樣,貪婪算法適合動態規劃,尋找局部最優解,不保證最優解。A*是靜態網格中求解最短路最有效的方法。也是耗時的算法,不宜尋路頻
python:dict vs list vs set
blog ddb nbsp 得出 replace 我們 通過 自身 插入 list: 有序 tuple: 另一種有序列表叫元組:tuple。tuple和list非常類似,但是tuple一旦初始化就不能修改 dict: 無序 對比: 和list比較,dict有以下幾個特點
HashMap vs. TreeMap vs. Hashtable vs. LinkedHashMap
entry object類 ref feedback list dog ole exception line 本文由 ImportNew - 唐小娟 翻譯自 Programcreek。歡迎加入翻譯小組。轉載請見文末要求。Map是最重要的數據結
【VS】VS開發中遇到的問題的總結
包含 erro 問題 dir pre x64 blank 解決 直接 1. VS中經常會出現無法解析的外部符號,還有LINK ERROR 2019等 這類問題如果檢查代碼沒有錯誤,很大概率就是lib文件錯誤。調試程序找出問題函數,再找出問題函數使用到的lib文件,在項
Java Serialization vs JSON vs XML
com jackson gpo ati tran reading .com reference orm References: [1] http://rick-hightower.blogspot.co.uk/2014/04/which-is-faster-java-obj
pthread_cleanup_push vs Autorelease VS 異常處理
html 根據 www. div obj 正是 ext 原理 消息 http://www.cnblogs.com/feng9exe/p/7239552.html objc_autoreleasePoolPush的返回值正是這個哨兵對象的地址,被objc_autorelea
dip vs di vs ioc
htm docs HA -c view ans cnblogs 2.0 PE https://stackoverflow.com/questions/6766056/dip-vs-di-vs-ioc https://docs.microsoft.com/en-us/
異步 callback vs promise vs async/await
png tps cts .com settime src bubuko ID objects 1. callback var fn1=function(){console.log("func1")} var fn2=function(fn){ setTimeout(fun
Spark(十八)SparkSQL的自定義函數UDF
gen to_char field ssi pan hot new 繼承 extends 在Spark中,也支持Hive中的自定義函數。自定義函數大致可以分為三種: UDF(User-Defined-Function),即最基本的自定義函數,類似to_char,to_
Spark(十七)SparkSQL簡單使用
所表 txt 配置 2.0 contex dataframe div 相關 rop 一、SparkSQL的進化之路 1.0以前: Shark 1.1.x開始: SparkSQL(只是測試性的) SQL 1.3.x: SparkS
callback vs async.js vs promise vs async / await
reject fun ace 串行 完成 關系 https 正常 call 需求: A、依次讀取 A|B|C 三個文件,如果有失敗,則立即終止。 B、同時讀取 A|B|C 三個文件,如果有失敗,則立即終止。 一、callback 需求A: let read = fu
GM Diagnostic & Programming: Tech 2 vs MDI vs Snap On Solus
GM CanDi gm diagnostic scanner gm mdi gm tech 2 gm tech 2 scanner gm tech2 gm tech2 diagnostic tool gm tech2 scan tool GM Tech2win tech 2
Docker VS Kubernetes VS Mesos
基礎 tps 最適 任務 解決 系統 我們 負載 集成 如果你是一名開發人員,正需要一種科學的辦法來加速你的應用程序開發過程或者微服務的構建,那麽我們建議你選擇Docker 。 如果你是一個團隊領導者,想要構建一個專門的docker容器編排系統,並集成你的解決方案和基礎設施
API網關性能比較:NGINX vs. ZUUL vs. Spring Cloud Gateway vs. Linkerd(轉)
master 優點 進程間 ring 每次 32gb 性能比較 servlet 以及 前幾天拜讀了 OpsGenie 公司(一家致力於 Dev & Ops 的公司)的資深工程師 Turgay ?elik 博士寫的一篇文章(鏈接在文末),文中介紹了他們最初也是采用 N
presto .vs impala .vs HAWQ query engine
com 容易 支持 活性 維護成本 tor 架構圖 功能 明顯 大數據查詢引擎的選型,畫了幾張架構圖,和一些對比分析: 一、Presto 二、Impala 三、HAWQ 四、總體比較: 1)都是MPP架構,且沒有明顯性能差距2)HAWQ的功能、特性較P
魔術方法(一) __getattribute__ VS __getattr__ VS __getitem___
Python 中有三個看上去非常相似的魔法方法: __getattribute__, __getattr__, __getitem___, 就是前面這仨哥們兒了. 不同之處 首先來看看 __ getattribute__ 和 __getattr__, 這倆在一定程度上有先後呼叫的關係. 簡單來說, 在用.