
explain使用+慢SQL分析
一、開啟慢查詢日誌,捕獲慢SQL
1、檢視慢查詢日誌是否開啟
- <span style="font-family:'Courier New';font-size:12px;">SHOW VARIABLES LIKE'%slow_query_log%';</span>
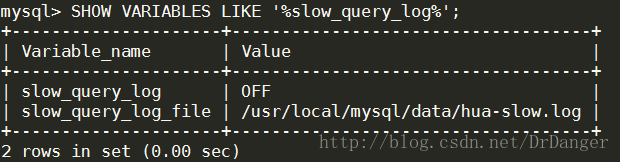
2、開啟慢查詢日誌
- <span style="font-family:'Courier New';font-size:12px;">SETGLOBAL slow_query_log=1;</span>
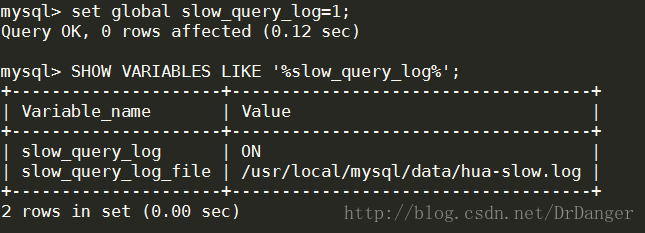
3、檢視慢查詢日誌闕值
- <span style="font-family:'Courier New';font-size:12px;">SHOW [GLOBAL] VARIABLES LIKE'%long_query_time%';</span>
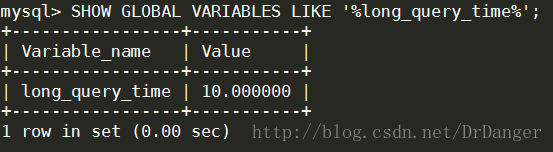
這個值表示超過多長時間的SQL語句會被記錄到慢查詢日誌中
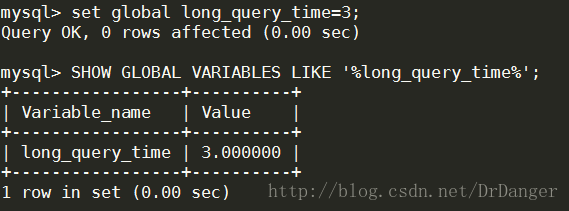
4、設定慢查詢日誌闕值
- <span style="font-family:'Courier New';font-size:12px;">SETGLOBAL long_query_time=3;</span>
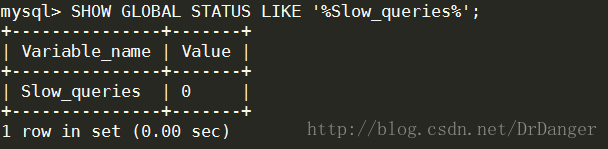
5、檢視多少SQL語句超過了闕值
- <span style="font-family:'Courier New';font-size:12px;">SHOW GLOBAL STATUS LIKE'%Slow_queries%';</span>
6、MySQL提供的日誌分析工具mysqldumpslow
進入MySQL的安裝目錄中的bin目錄下
執行 ./mysqldumpslow --help 檢視幫助命令常用參考: 得到返回記錄集最多的10個SQL
mysqldumpslow -s r -t 10 slow.log
得到訪問次數最多的10個SQL
mysqldumpslow -s c -t 10 slow.log
得到按照時間排序的前10條裡面含有左連線的查詢語句
mysqldumpslow -s t -t 10 -g "left join" slow.log
使用這些語句時結合| more使用
二、explain+慢SQL分析
使用EXPLAIN關鍵字可以模擬優化器執行SQL查詢語句,從而知道MySQL是 如何處理你的SQL語句的。分析你的查詢語句或是表結構的效能瓶頸。使用方式:Explain+SQL語句執行計劃包含的資訊:+----+-------------+-------+------+---------------+------+---------+------+------+-------+| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
1、id
SELECT查詢的序列號,包含一組數字,表示查詢中執行SELECT語句或操作表的順序包含三種情況:1.id相同,執行順序由上至下2.id不同,如果是子查詢,id序號會遞增,id值越大優先順序越高,越先被執行3.id既有相同的,又有不同的。id如果相同認為是一組,執行順序由上至下; 在所有組中,id值越大優先順序越高,越先執 行。
2、select_type
SIMPLE:簡單SELECT查詢,查詢中不包含子查詢或者UNIONPRIMARY:查詢中包含任何複雜的子部分,最外層的查詢
SUBQUERY:SELECT或WHERE中包含的子查詢部分
DERIVED:在FROM中包含的子查詢被標記為DERIVER(衍生), MySQL會遞迴執行這些子查詢,把結果放到臨時表中
UNION:若第二個SELECT出現UNION,則被標記為UNION, 若UNION包含在FROM子句的子查詢中,外層子查詢將被標記為DERIVED
UNION RESULT:從UNION表獲取結果的SELECT
3、table
顯示這一行資料是關於哪張表的4、type
type顯示的是訪問型別,是較為重要的一個指標,結果值從最好到最壞依次是:system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL
一般來說,得保證查詢至少達到range級別,最好能達到ref。system:表只有一行記錄(等於系統表),這是const型別的特例,平時不會出現const:如果通過索引依次就找到了,const用於比較主鍵索引或者unique索引。 因為只能匹配一行資料,所以很快。如果將主鍵置於where列表中,MySQL就能將該查詢轉換為一個常量
eq_ref:唯一性索引掃描,對於每個索引鍵,表中只有一條記錄與之匹配。常見於主鍵或唯一索引掃描
ref:非唯一性索引掃描,返回匹配某個單獨值的所有行。本質上也是一種索引訪問,它返回所有匹配 某個單獨值的行,然而它可能會找到多個符合條件的行,所以它應該屬於查詢和掃描的混合體
range:只檢索給定範圍的行,使用一個索引來選擇行。key列顯示使用了哪個索引,一般就是在你的where語句中出現between、<、>、in等的查詢,這種範圍掃描索引比全表掃描要好,因為只需要開始於縮印的某一點,而結束於另一點,不用掃描全部索引
index:Full Index Scan ,index與ALL的區別為index型別只遍歷索引樹,這通常比ALL快,因為索引檔案通常比資料檔案小。 (也就是說雖然ALL和index都是讀全表, 但index是從索引中讀取的,而ALL是從硬碟讀取的)
all:Full Table Scan,遍歷全表獲得匹配的行
5、possible_keys
顯示可能應用在這張表中的索引,一個或多個。 查詢涉及到的欄位上若存在索引,則該索引將被列出,但不一定被查詢實際使用6、key
實際使用的索引。如果為NULL,則沒有使用索引。查詢中若出現了覆蓋索引,則該索引僅出現在key列表中。
7、key_len
表示索引中使用的位元組數,可通過該列計算查詢中使用的索引的長度。在不損失精度的情況下,長度越短越好。key_len顯示的值為索引欄位的最大可能長度,並非實際使用長度,即key_len是根據表定義計算而得,不是通過表內檢索出的。
8、ref
顯示索引的哪一列被使用了,哪些列或常量被用於查詢索引列上的值。9、rows
根據表統計資訊及索引選用情況,大致估算出找到所需記錄多需要讀取的行數。10、Extra
包含不適合在其他列中顯示但十分重要的額外資訊:1、Using filesort: 說明MySQL會對資料使用一個外部的索引排序,而不是按照表內的索引順序進行讀取。MySQL中無法利用索引完成的排序操作稱為“檔案排序”
2、Using temporary: 使用了臨時表儲存中間結果,MySQL在對查詢結果排序時使用臨時表。常見於排序order by和分組查詢group by
3、Using index: 表示相應的SELECT操作中使用了覆蓋索引(Covering Index),避免訪問了表的資料行,效率不錯。 如果同時出現using where,表明索引被用來執行索引鍵值的查詢; 如果沒有同時出現using where,表明索引用來讀取資料而非執行查詢動作 覆蓋索引(Covering Index): 理解方式1:SELECT的資料列只需要從索引中就能讀取到,不需要讀取資料行,MySQL可以利用索引返回SELECT列表中 的欄位,而不必根據索引再次讀取資料檔案,換句話說查詢列要被所建的索引覆蓋 理解方式2:索引是高效找到行的一個方法,但是一般資料庫也能使用索引找到一個列的資料,因此他不必讀取整個行。 畢竟索引葉子節點儲存了他們索引的資料;當能通過讀取索引就可以得到想要的資料,那就不需要讀取行了,一個索引 包含了(覆蓋)滿足查詢結果的資料就叫做覆蓋索引 注意: 如果要使用覆蓋索引,一定要注意SELECT列表中只取出需要的列,不可SELECT *, 因為如果所有欄位一起做索引會導致索引檔案過大查詢效能下降
6、impossible where: WHERE子句的值總是false,不能用來獲取任何元組
7、select tables optimized away: 在沒有GROUP BY子句的情況下基於索引優化MIN/MAX操作或者對於MyISAM儲存引擎優化COUNT(*)操作, 不必等到執行階段再進行計算,查詢執行計劃生成的階段即完成優化
8、distinct: 優化distinct操作,在找到第一匹配的元祖後即停止找同樣值的操作
三、show profile查詢SQL語句在伺服器中的執行細節和生命週期
Show Profile是MySQL提供可以用來分析當前會話中語句執行的資源消耗情況,可以用於SQL的調優測量預設關閉,並儲存最近15次的執行結果
分析步驟
1、檢視狀態:SHOW VARIABLES LIKE 'profiling';
2、開啟:set profiling=on;
3、檢視結果:show profiles;
4、診斷SQL:show profile cpu,block io for query 上一步SQL數字號碼;
ALL:顯示所有開銷資訊
BLOCK IO:顯示IO相關開銷
CONTEXT SWITCHES:顯示上下文切換相關開銷
CPU:顯示CPU相關開銷
IPC:顯示傳送接收相關開銷
MEMORY:顯示記憶體相關開銷
PAGE FAULTS:顯示頁面錯誤相關開銷
SOURCE:顯示和Source_function,Source_file,Source_line相關開銷
SWAPS:顯示交換次數相關開銷
注意(遇到這幾種情況要優化)
converting HEAP to MyISAM: 查詢結果太大,記憶體不夠用往磁碟上搬
Creating tmp table:建立臨時表
Copying to tmp table on disk:把記憶體中的臨時表複製到磁碟
locked
四、SQL資料庫伺服器引數調優
當order by 和 group by無法使用索引時,增大max_length_for_sort_data引數設定和增大sort_buffer_size引數的設定相關推薦
explain使用+慢SQL分析
一、開啟慢查詢日誌,捕獲慢SQL二、explain+慢SQL分析三、show profile查詢SQL語句在伺服器中的執行細節和生命週期四、SQL資料庫伺服器引數調優一、開啟慢查詢日誌,捕獲慢SQL1、檢視慢查詢日誌是否開啟<span style="font-famil
MySQL優化(3):慢SQL分析
正則 測試 ron 得到 引擎 sql tin 對數 xpl 對慢SQL優化一般可以按下面幾步的思路: 1、開啟慢查詢日誌,設置超過幾秒為慢SQL,抓取慢SQL 2、通過explain對慢SQL分析(重點) 3、show profile查詢SQL在Mysql服務器裏的執行細
explain和profiling分析查詢SQL時間
ati 打開 fix -c ret read 索引 -- title mysql可以通過profiling命令查看到執行查詢SQL消耗的時間。 默認情況下,mysql是關閉profiling的,命令: [sql] view plain copy select @@
如何對SQL進行優化查詢之使用explain關鍵字進行分析?
(一)通過關鍵字explain的分析我們可以得出什麼結果? 表的讀取順序 表的讀取操作的讀取型別 哪些索引有可能會被使用到 哪些索引被實際使用了 表之間的引用 每張表有多少行被優化器查詢 (二)大體
SQL慢查詢分析,原因及優化
問題描述 一個使用者反映線上一個SQL語句執行時間慢得無法接受。SQL語句看上去很簡單(本文描述中修改了表名和欄位名): SELECT count(*) FROM a JOIN b ON a.`S` = b.`S` WHERE a.`L` > '2014-
sql分析命令explain和desc
explain和desc命令的效果相同,命令格式如下: mysql> explain SELECT s.id sid, s.name sname , t.id tid ,t.name tname FROM student s LEFT JOIN teacher t ON
oracle 分析慢sql 並建立索引
第一步:explain plan for SELECT * from table //執行計劃(此處的表查詢由於隱私,所以沒拿出來) 第二步:select * from table(dbms_xplan.display)//查詢分析 select * from user_index
mysql開啟慢SQL並分析原因
方式一:修改配置檔案 Windows:Windows 的配置檔案為 my.ini,一般在 MySQL 的安裝目錄下或者 c:\Windows 下。 Linux:Linux 的配置檔案為 my.cnf ,一般在 /etc 下 在 my.ini 增加幾行: [mysqlld] long_qu
Mysql使用profiling分析慢sql語句的原因
CleverCode的同事最近給我推薦了一個分析mysql中sql語句的工具profiling,發現這個工具非常不錯,能夠很準確的分析出查詢的過程中sql語句具體的時間花在了哪裡。CleverCode在這裡總結一下,分享給大家。 1 簡介
mysql效能優化-慢查詢分析、優化索引和配置 (慢查詢日誌,explain,profile)
一、優化概述 二、查詢與索引優化分析 1效能瓶頸定位 Show命令 慢查詢日誌 explain分析查詢 profiling分析查詢 2索引及查詢優化 三、配置優化 1) max_connections 2) back_log 3) interactive_timeout 4)
神奇的 SQL 之 MySQL 效能分析神器 → EXPLAIN,SQL 起飛的基石!
前言 開心一刻 某人養了一頭豬,煩了想放生,可是豬認識回家的路,放生幾次它都自己回來了。一日,這個人想了個狠辦法,開車帶著豬轉了好多路進山區放生,放生後又各種打轉,然後掏出電話給家裡人打了個電話,問道:“豬回去了嗎?”,家裡人:“早回來了,你在哪了,怎麼還沒
天兔(Lepus)監控系統慢查詢分析平臺安裝配置
fig align fxaa comm one 平臺 back ria pri 轉http://suifu.blog.51cto.com/9167728/1770672 被監控端要安裝pt工具 1 2 3 4 [[email protec
避免寫慢SQL
程序員 cal red 信息 計算 建議 個數 today 次數 最近在整理數據庫中的慢SQL,同時也查詢了相關資料。記錄一下,要學會使用執行計劃來分析SQL。 1. 為查詢緩存優化你的查詢 大多數的MySQL服務器都開啟了查詢緩存。這是提高性最有效的方法之一,而且這是被M
mysql慢查詢分析工具和分析方法
mysql 慢查詢 分析工具 1.mysql慢查詢分析工具1.參考文檔:http://www.ttlsa.com/mysql/analyse-slow-query-log-using-anemometer/http://isadba.com/?p=655官方文檔:https://github.co
查詢慢SQL
list ati order mysql select 查詢 連接 當前時間 sql 可以查看當前時間訪問庫的所有請求SQL SELECT COUNT(*) AS c,state,info FROM `information_schema`.processlist G
mysqlsla安裝與慢查詢分析
mysqlsla安裝mysqlsla是一款幫助語句分析、過濾、和排序的功能,能夠處理MySQL慢查詢日誌、二進制日誌等。整體來說, 功能非常強大. 能制作SQL查詢數據報表,分析包括執行頻率, 數據量, 查詢消耗等且該工具自帶相似SQL語句去重的功能,能按照指定方式進行排序(比如分析慢查詢日誌的時候,讓其按照
mysql慢sql報警系統
同事 mysql 問題 引號 技術分享 根據 傳輸 進行 圖片 前言:最近有同事反應有的接口響應時間時快時慢,經過排查有的數據層響應時間過長,為了加快定位定位慢sql的準確性,決定簡單地搭建一個慢sql報警系統 具體流程如下架構圖 第一步:記錄日誌 每個業務
show processlist中kill鎖表語句與慢sql
log rep cat -h echo read 0.10 1.2 line show processlist中kill鎖表語句與慢sql1 單個killmysql> show processlist;mysql > kill 251;#批量kill1)查找Lo
MySQL慢查詢(二) - pt-query-digest詳解慢查詢日誌 pt-query-digest 慢日誌分析
進行 www summary exec 存儲 response 狀態 rep ota 隨筆 - 66 文章 - 0 評論 - 19 MySQL慢查詢(二) - pt-query-digest詳解慢查詢日誌 一、簡介 pt-que
DB2性能優化- REORG慢的分析
數據庫 DB2 什麽是REORG?我們知道,數據庫中有許多表的存在,而我們可能會經常地需要對表數據進行增刪改等操作,經過一系列更改後,邏輯上連續的數據可能會位於不連續的物理數據頁上,在許多插入操作創建了溢出記錄時尤其如此。按這種方式組織數據時,數據庫管理器必須執行其他讀操作才能訪問順序數據。而在刪除大