
《BI那點兒事》ETL中的關鍵技術
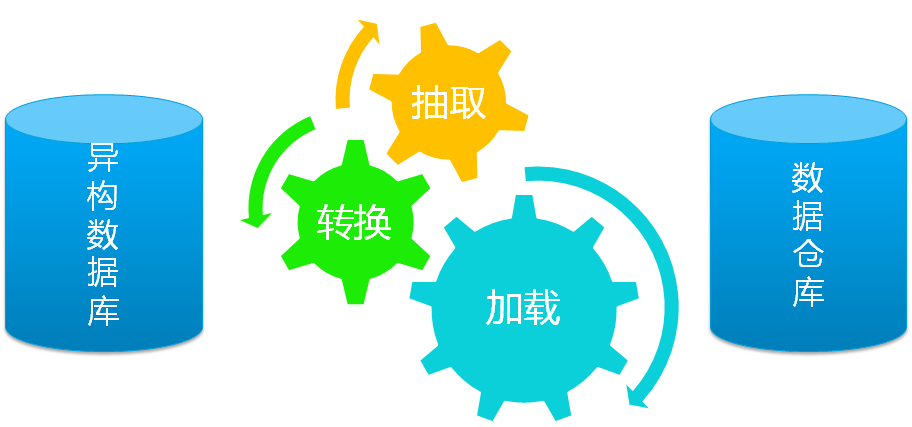
ETL(Extract/Transformation/Load)是BI/DW的核心和靈魂,按照統一的規則整合並提高資料的價值,是負責完成資料從資料來源向目標資料倉庫轉化的過程,是實施資料倉庫的重要步驟。
ETL過程中的主要環節就是資料抽取、資料轉換和加工、資料裝載。為了實現這些功能,各個ETL工具一般會進行一些功能上的擴充,例如工作流、排程引擎、規則引擎、指令碼支援、統計資訊等。
資料抽取
資料抽取是從資料來源中抽取資料的過程。實際應用中,資料來源較多采用的是關係資料庫。從資料庫中抽取資料一般有以下幾種方式。
(1)全量抽取 全量抽取類似於資料遷移或資料複製,它將資料來源中的表或檢視的資料原封不動的從資料庫中抽取出來,並轉換成自己的ETL工具可以識別的格式。全量抽取比較簡單。
(2)增量抽取 增量抽取只抽取自上次抽取以來資料庫中要抽取的表中新增或修改的資料。在ETL使用過程中。增量抽取較全量抽取應用更廣。如何捕獲變化的資料是增量抽取的關鍵。對捕獲方法一般有兩點要求:準確性,能夠將業務系統中的變化資料按一定的頻率準確地捕獲到;效能,不能對業務系統造成太大的壓力,影響現有業務。目前增量資料抽取中常用的捕獲變化資料的方法有:
a.觸發器:在要抽取的表上建立需要的觸發器,一般要建立插入、修改、刪除三個觸發器,每當源表中的資料發生變化,就被相應的觸發器將變化的資料寫入一個臨時表,抽取執行緒從臨時表中抽取資料,臨時表中抽取過的資料被標記或刪除。觸發器方式的優點是資料抽取的效能較高,缺點是要求業務表建立觸發器,對業務系統有一定的影響。
b.時間戳:它是一種基於快照比較的變化資料捕獲方式,在源表上增加一個時間戳欄位,系統中更新修改表資料的時候,同時修改時間戳欄位的值。當進行資料抽取時,通過比較系統時間與時間戳欄位的值來決定抽取哪些資料。有的資料庫的時間戳支援自動更新,即表的其它欄位的資料發生改變時,自動更新時間戳欄位的值。有的資料庫不支援時間戳的自動更新,這就要求業務系統在更新業務資料時,手工更新時間戳欄位。同觸發器方式一樣,時間戳方式的效能也比較好,資料抽取相對清楚簡單,但對業務系統也有很大的傾入性(加入額外的時間戳欄位),特別是對不支援時間戳的自動更新的資料庫,還要求業務系統進行額外的更新時間戳操作。另外,無法捕獲對時間戳以前資料的delete和update操作,在資料準確性上受到了一定的限制。
c.全表比對:典型的全表比對的方式是採用MD5校驗碼。ETL工具事先為要抽取的表建立一個結構類似的MD5臨時表,該臨時表記錄源表主鍵以及根據所有欄位的資料計算出來的MD5校驗碼。每次進行資料抽取時,對源表和MD5臨時表進行MD5校驗碼的比對,從而決定源表中的資料是新增、修改還是刪除,同時更新MD5校驗碼。MD5方式的優點是對源系統的傾入性較小(僅需要建立一個MD5臨時表),但缺點也是顯而易見的,與觸發器和時間戳方式中的主動通知不同,MD5方式是被動的進行全表資料的比對,效能較差。當表中沒有主鍵或唯一列且含有重複記錄時,MD5方式的準確性較差。
d.日誌對比:通過分析資料庫自身的日誌來判斷變化的資料。Oracle的改變資料捕獲(CDC,ChangedDataCapture)技術是這方面的代表。CDC特性是在Oracle9i資料庫中引入的。CDC能夠幫助你識別從上次抽取之後發生變化的資料。利用CDC,在對源表進行insert、update或delete等操作的同時就可以提取資料,並且變化的資料被儲存在資料庫的變化表中。這樣就可以捕獲發生變化的資料,然後利用資料庫檢視以一種可控的方式提供給目標系統。CDC體系結構基於釋出者/訂閱者模型。釋出者捕捉變化資料並提供給訂閱者。訂閱者使用從釋出者那裡獲得的變化資料。通常,CDC系統擁有一個釋出者和多個訂閱者。釋出者首先需要識別捕獲變化資料所需的源表。然後,它捕捉變化的資料並將其儲存在特別建立的變化表中。它還使訂閱者能夠控制對變化資料的訪問。訂閱者需要清楚自己感興趣的是哪些變化資料。一個訂閱者可能不會對釋出者釋出的所有資料都感興趣。訂閱者需要建立一個訂閱者檢視來訪問經發布者授權可以訪問的變化資料。CDC分為同步模式和非同步模式,同步模式實時的捕獲變化資料並存儲到變化表中,釋出者與訂閱都位於同一資料庫中。非同步模式則是基於Oracle的流複製技術。
ETL處理的資料來源除了關係資料庫外,還可能是檔案,例如txt檔案、excel檔案、xml檔案等。對檔案資料的抽取一般是進行全量抽取,一次抽取前可儲存檔案的時間戳或計算檔案的MD5校驗碼,下次抽取時進行比對,如果相同則可忽略本次抽取。
資料轉換和加工
從資料來源中抽取的資料不一定完全滿足目的庫的要求,例如資料格式的不一致、資料輸入錯誤、資料不完整等等,因此有必要對抽取出的資料進行資料轉換和加工。 資料的轉換和加工可以在ETL引擎中進行,也可以在資料抽取過程中利用關係資料庫的特性同時進行。
(1)ETL引擎中的資料轉換和加工
ETL引擎中一般以元件化的方式實現資料轉換。常用的資料轉換元件有欄位對映、資料過濾、資料清洗、資料替換、資料計算、資料驗證、資料加解密、資料合併、資料拆分等。這些元件如同一條流水線上的一道道工序,它們是可插拔的,且可以任意組裝,各元件之間通過資料匯流排共享資料。 有些ETL工具還提供了指令碼支援,使得使用者可以以一種程式設計的方式定製資料的轉換和加工行為。
(2)在資料庫中進行資料加工
關係資料庫本身已經提供了強大的SQL、函式來支援資料的加工,如在SQL查詢語句中新增where條件進行過濾,查詢中重新命名欄位名與目的表進行對映,substr函式,case條件判斷等等。
相比在ETL引擎中進行資料轉換和加工,直接在SQL語句中進行轉換和加工更加簡單清晰,效能更高。對於SQL語句無法處理的可以交由ETL引擎處理。
資料裝載
將轉換和加工後的資料裝載到目的庫中通常是ETL過程的最後步驟。裝載資料的最佳方法取決於所執行操作的型別以及需要裝入多少資料。當目的庫是關係資料庫時,一般來說有兩種裝載方式:
(1)直接SQL語句進行insert、update、delete操作。
(2)採用批量裝載方法,如bcp、bulk、關係資料庫特有的批量裝載工具或api。 大多數情況下會使用第一種方法,因為它們進行了日誌記錄並且是可恢復的。但是,批量裝載操作易於使用,並且在裝入大量資料時效率較高。使用哪種資料裝載方法取決於業務系統的需要。
常見的資料質量問題
|
資料質量 |
問題 |
資料問題示例 |
|
格式 |
值是否按照一致的格式標準? |
電話號碼 # 可能顯示為 xxxxxxxxxx, (xxx) xxx-xxxx, 1.xxx.xxx.xxxx, 等. |
|
標準 |
資料元素是否一致性定義和理解 ? |
一個系統性別程式碼 = M, F, U ,另一個系統性別程式碼 = 0, 1, 2 |
|
一致性 |
值是否代表統一的含義? |
營業額是否總是顯示為美元還是也有可能為? |
|
完整性 |
是否所有必須的資料都包含? |
20% 的顧客的 last name 為空, |
|
精確性 |
資料是否準確地反映現實或可驗證的資料來源? |
供應商顯示為‘活動’,但是其實6年前已經和它沒有業務往來。 |
|
有效性 |
資料值是否在接受的範圍內? |
薪水值應該在 60,000-120,000 |
|
重複性 |
資料多次出現 |
John Ryan 和 Jack Ryan 都在系統中出現了 – 他們是同一個人嗎? |
相關推薦
《BI那點兒事》ETL中的關鍵技術
ETL(Extract/Transformation/Load)是BI/DW的核心和靈魂,按照統一的規則整合並提高資料的價值,是負責完成資料從資料來源向目標資料倉庫轉化的過程,是實施資料倉庫的重要步驟。 ETL過程中的主要環節就是資料抽取、資料轉換和加工、資料裝載。為了實現這些功能,各個ETL工具一般會
《BI那點兒事》淺析十三種常用的資料探勘的技術
一、前沿 資料探勘就是從大量的、不完全的、有噪聲的、模糊的、隨機的資料中,提取隱含在其中的、人們事先不知道的但又是潛在有用的資訊和知識的過程。資料探勘的任務是從資料集中發現模式,可以發現的模式有很多種,按功能可以分為兩大類:預測性(Predictive)模式和描述性(Descriptive)模式。在應用
《BI那點兒事》Microsoft 線性迴歸演算法
Microsoft 線性迴歸演算法是 Microsoft 決策樹演算法的一種變體,有助於計算依賴變數和獨立變數之間的線性關係,然後使用該關係進行預測。該關係採用的表示形式是最能代表資料序列的線的公式。例如,以下關係圖中的線是資料最可能的線性表示形式。 關係圖中的每個資料點都有一個與該資料點與迴歸線之間距離關
《BI那點兒事》資料探勘各類演算法——準確性驗證
準確性驗證示例1:——基於三國志11資料庫 資料準備: 挖掘模型:依次為:Naive Bayes 演算法、聚類分析演算法、決策樹演算法、神經網路演算法、邏輯迴歸演算法、關聯演算法提升圖: 依次排名為: 1. 神經網路演算法(92.69% 0.99)2. 邏輯迴歸演算法(92.39% 0.99)3. 決策
《BI那點兒事》資料探勘初探
什麼是資料探勘? 資料探勘(Data Mining),又稱資訊發掘(Knowledge Discovery),是用自動或半自動化的方法在資料中找到潛在的,有價值的資訊和規則。 資料探勘技術來源於資料庫,統計和人工智慧。 資料探勘能夠做什麼 對企業中產生的大量的資料進行分析,找出其中潛藏的規
《BI那點兒事》Microsoft 神經網路演算法
Microsoft神經網路是迄今為止最強大、最複雜的演算法。要想知道它有多複雜,請看SQL Server聯機叢書對該演算法的說明:“這個演算法通過建立多層感知神經元網路,建立分類和迴歸挖掘模型。與Microsoft決策樹演算法類似,在給定了可預測屬性的每個狀態時, Microsoft神經網路演算法計算輸入屬性
《BI那點兒事》Microsoft 順序分析和聚類分析演算法
Microsoft 順序分析和聚類分析演算法是由 Microsoft SQL Server Analysis Services 提供的一種順序分析演算法。您可以使用該演算法來研究包含可通過下面的路徑或“順序”連結到的事件的資料。該演算法通過對相同的順序進行分組或分類來查詢最常見的順序。下面是一些順序示例:
《BI那點兒事》資料流轉換——查詢轉換
查詢轉換通過聯接輸入列中的資料和引用資料集中的列來執行查詢。是完全匹配查詢。在源表中查詢與字表能關聯的所有源表記錄。準備資料。源表 T_QualMoisture_Middle_Detail字典表 T_DIC_QualProcess資料流任務設計圖: 設計步驟: (adsbygo
《BI那點兒事》資料流轉換——多播、Union All、合併、合併聯接
建立測試資料: CREATE TABLE FactResults ( Name VARCHAR(50) , Course VARCHAR(50) , Score INT ) INSERT INTO FactResults
《BI那點兒事》Microsoft 決策樹演算法——找出三國武將特性分佈,獻給廣大的三國愛好者們
根據遊戲《三國志11》武將資料,利用決策樹分析,找出三國武將特性分佈。其中變數包括統率、武力、智力、政治、魅力、身分。變數說明:統率:武將帶兵出征時的部隊防禦力。統帥越高受到普通攻擊與兵法攻擊越少。武力:武將帶兵出征時的部隊攻擊力,武力越高發動兵法或者普通攻擊時對地方部隊的傷害就越高;並且當發動單挑時雙方武將
《BI那點兒事》資料探勘的主要方法
一、迴歸分析目的:設法找出變數間的依存(數量)關係, 用函式關係式表達出來。所謂迴歸分析法,是在掌握大量觀察資料的基礎上,利用數理統計方法建立因變數與自變數之間的迴歸關係函式表示式(稱迴歸方程式)。迴歸分析中,當研究的因果關係只涉及因變數和一個自變數時,叫做一元迴歸分析;當研究的因果關係涉及因變數和兩個或兩個
《BI那點兒事—資料的藝術》理解維度資料倉庫——事實表、維度表、聚合表
事實表 在多維資料倉庫中,儲存度量值的詳細值或事實的表稱為“事實表”。一個按照州、產品和月份劃分的銷售量和銷售額儲存的事實表有5個列,概念上與下面的示例類似。 Sate Product Mouth Units Dollars
《BI那點兒事》SSRS圖表和儀表——雷達圖分析三國超一流謀士、統帥資料(圖文並茂)
雷達圖分析三國超一流謀士、統帥資料,獻給廣大的三國愛好者們,希望喜歡三國的朋友一起討論,加深對傳奇三國時代的瞭解 建立資料環境: -- 抽取三國超一流謀士TOP 10資料 DECLARE @t1 TABLE ( [姓名] NVARCHAR(255) , [統率]
《BI那點兒事》運用標準計分和離差——分析三國超一流統帥綜合實力排名 絕對客觀,資料說話
資料分析基礎概念:標準計分: 1、無論作為變數的滿分為幾分,其標準計分的平均數勢必為0,而其標準差勢必為1。2、無論作為變數的單位是什麼,其標準計分的平均數勢必為0,而其標準差勢必為1。公式為: 離差:離差就是應用標準計分所得的數值。1、無論作為變數的滿分為幾分,其離差的平均數勢必為50,而其標準差勢必為1
《BI那點兒事》Microsoft 決策樹演算法
Microsoft 決策樹演算法是由 Microsoft SQL Server Analysis Services 提供的分類和迴歸演算法,用於對離散和連續屬性進行預測性建模。對於離散屬性,該演算法根據資料集中輸入列之間的關係進行預測。它使用這些列的值(也稱之為狀態)預測指定為可預測的列的狀態。具體地說,該演
《BI那點兒事》資料流轉換——OLE DB 命令轉換
OLE DB命令對資料流中的資料行執行一個OLE DB命令。它針對資料表中的每一行進行更新操作,可以事先將要更新的資料存放在表中。或者針對一個有輸入引數的儲存過程,可以將這些引數存放在一個數據表中,不用每次都輸入引數。示例資料準備: CREATE TABLE SourceParametersForSt
《BI那點兒事》SQL Server 2008體系架構
Microsoft SQL Server是一個提供了聯機事務處理、資料倉庫、電子商務應用的資料庫和資料分析的平臺。體系架構是描述系統組成要素和要素之間關係的方式。Microsoft SQL Server系統的體系結構是對Microsoft SQL Server的主要組成部分和這些組成部分之間關係的描述。Mic
《BI那點兒事》Cube的儲存
關係 OLAP (ROLAP)ROLAP的基本資料和聚合資料均存放在關係資料庫中;ROLAP 儲存模式使得分割槽的聚合儲存在關係資料庫的表(在分割槽資料來源中指定)中。但是,可為分割槽資料使用 ROLAP 儲存模式,而不在關係資料庫中建立聚合。使用 ROLAP 的維度的資料實際上儲存在用於定義維度的表中。相對
《BI那點兒事》資料流轉換——排序
排序轉換允許對資料流中的資料按照某一列進行排序。這是五個常用的轉換之一。連線資料來源開啟編輯介面,編輯這種任務。不想設定為排序列的欄位不要選中,預設情況下所有列都會選中。如圖所示,按照TotalSugar_Cnt排序,並將所有列輸出。 在底部的表格中,可以設定輸出列的別名,是否按照列來排序。Sort Ord
《BI那點兒事》三國資料分析系列——蜀漢五虎上將與魏五子良將武力分析,絕對的經典分析
獻給廣大的三國愛好者們,希望喜歡三國的朋友一起討論,加深對傳奇三國時代的瞭解 資料分析基礎概念:集中趨勢分析是指在大量測評資料分佈中,測評資料向某點集中的情況。總體(population)是指客觀存在的,並在同一性質的基礎上結合起來的許多個別單位的整體,即具有某一特性的一類事物的全體,又叫母體或全域。簡單地