
Microsoft Naive Bayes 演算法——三國人物身份劃分
Microsoft樸素貝葉斯是SSAS中最簡單的演算法,通常用作理解資料基本分組的起點。這類處理的一般特徵就是分類。這個演算法之所以稱為“樸素”,是因為所有屬性的重要性是一樣的,沒有誰比誰更高。貝葉斯之名則源於Thomas Bayes,他想出了一種運用算術(可能性)原則來理解資料的方法。對此演算法的另一個理解就是:所有屬性都是獨立的,互不相關。從字面來看,該演算法只是計算所有屬性之間的關聯。雖然該演算法既可用於預測也可用於分組,但最常用於模型構建的早期階段,更常用於分組而不是預測某個具體的值。通過要將所有屬性標記為簡單輸入或者既是輸入又是可預測的,因為這就可以演算法在執行的時候考慮到所有屬性。在標記屬性時的工作量可能有些大。很常見的情況是,在輸入中包含大量屬性,然後處理模型再評估結果。如果結果看起來沒什麼意義,我們經常減少包含的屬性數量,以便更好地理解關聯最緊密的關係。
如果擁有大量資料,而對資料的瞭解又很少,這時可以使用樸素貝葉斯演算法。例如,公司可能由於兼併了一家競爭對手而獲得了大量銷售資料。在處理這類資料的時候,可以用樸素貝葉斯作為起點。
應該瞭解的是,這個演算法有一個明顯的侷限,只能處理離散(或離散化)的內容型別。如果選擇的資料結構中包含有內容型別不是Discrete(如Continuous)的資料列,那麼樸素貝葉斯建立的挖掘模型會忽略這些資料。
樸素貝葉斯演算法有4個可以配置的引數:MAXIMUM_INPUT_ATTRIBUTE、MAXIMUM_OUTPUT_ATTRIBUTE、MAXIMUM_STATUS、MINIMUM_DEPENDENCY_PROBABILITY。可以在“值”中輸入新值來修改配置的(預設)值。這個資訊在“演算法引數”對話方塊的“說明”區中有說明。
有人可能想知道是否經常需要調整演算法引數的預設值。我們發現,隨著對各個演算法功能的逐漸瞭解,我們開始傾向於手動調節。因為樸素貝葉斯頻繁地用於資料探勘專案,尤其用於專案的早期,所以我們發現自己經常要調整它的相關引數。前3個引數的作用一目瞭然:調整配置的值為的是減少輸入值、輸出值或分組狀態的最大數量。最後的依賴關係可能性的意義不太明顯。在減小這個值的時候,實際是在要求減少模型生成的節點或分組的數量。
下面我們進入主題,同樣我們繼續利用上次的解決方案,依次步驟如下:


選擇所需輸入變數與預測變數,以及索引鍵。此例以序列為索引,身份為預測變數,選中統率、武力、智力、政治、魅力五個變數為輸入變數,完成後點選“確定”按鈕,這時會到原來的頁面,點選“下一步”按鈕,如圖所示。
選擇正確的資料屬性,修正了變數的資料屬性後點擊“下一步”按鈕。
更改挖掘結構名稱,點選“完成”按鈕。
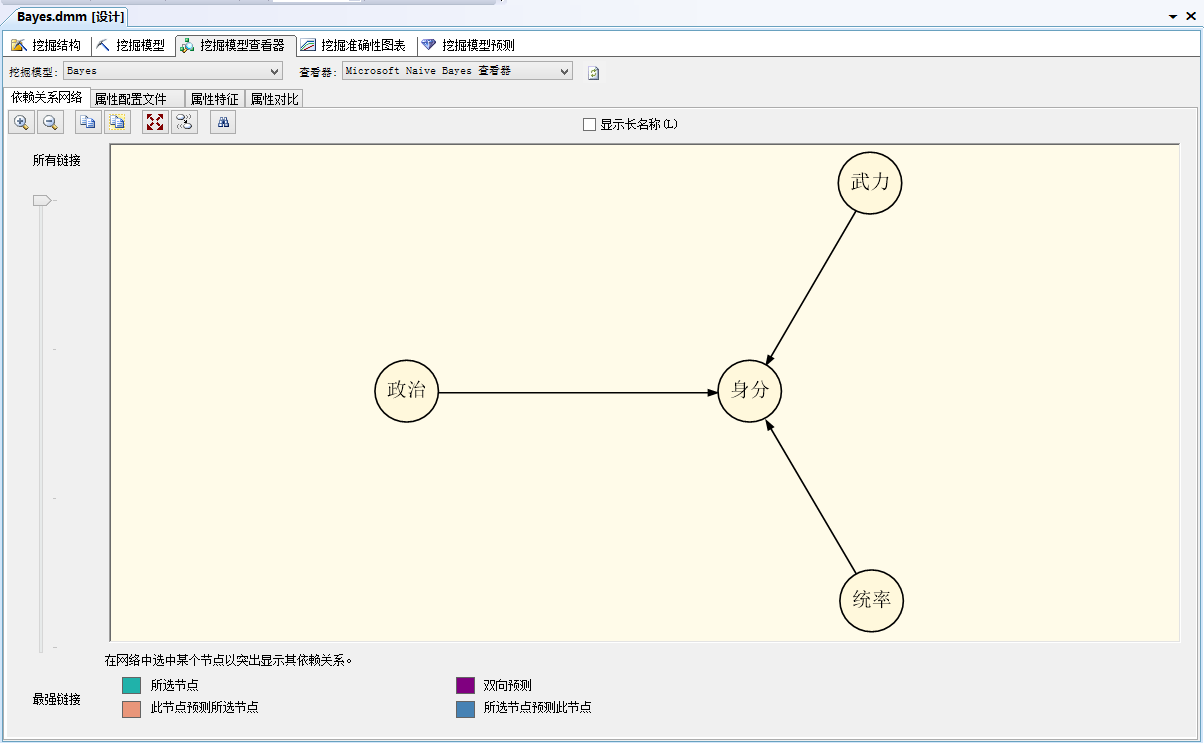
挖掘模型檢視器則是呈現此依賴關係網路,對於資料的分佈進一步加以瞭解。
從“屬性配置”檔案可以瞭解每個變數的特性分佈狀況。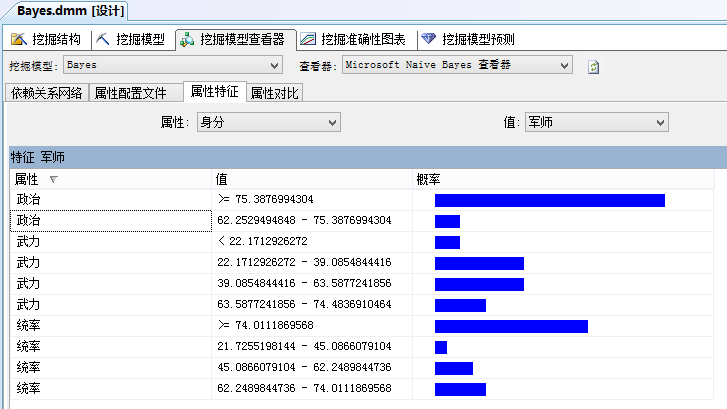
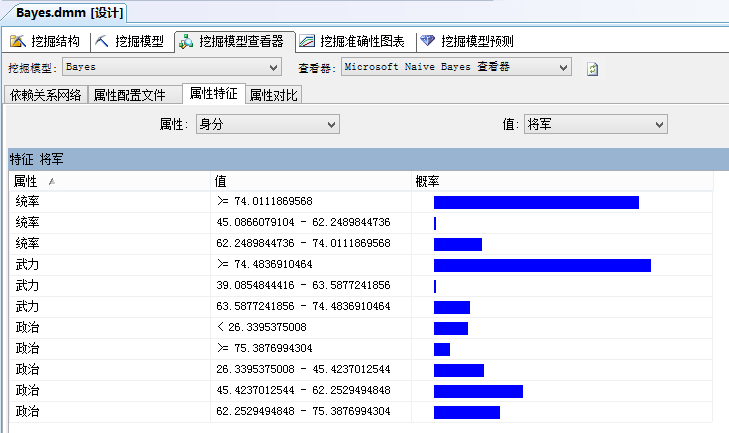
而從“屬性特性”可以看出,不同群的基本特性概率。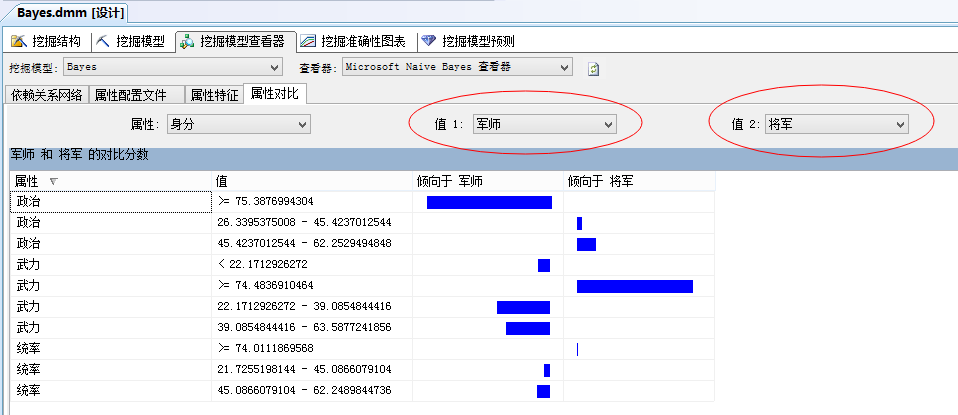
而從“屬性對比”中,主要可以比較不同群體的特性。
參考文獻:
Microsoft Naive Bayes 演算法
http://msdn.microsoft.com/zh-cn/library/ms174806(v=sql.105).aspx
相關推薦
Microsoft Naive Bayes 演算法——三國人物身份劃分
Microsoft樸素貝葉斯是SSAS中最簡單的演算法,通常用作理解資料基本分組的起點。這類處理的一般特徵就是分類。這個演算法之所以稱為“樸素”,是因為所有屬性的重要性是一樣的,沒有誰比誰更高。貝葉斯之名則源於Thomas Bayes,他想出了一種運用算術(可能性)原則來理解資料的方法。對此演算法的另一個
《BI那點兒事》Microsoft 聚類分析演算法——三國人物身份劃分
什麼是聚類分析? 聚類分析屬於探索性的資料分析方法。通常,我們利用聚類分析將看似無序的物件進行分組、歸類,以達到更好地理解研究物件的目的。聚類結果要求組內物件相似性較高,組間物件相似性較低。在三國資料分析中,很多問題可以藉助聚類分析來解決,比如三國人物身份劃分。聚類分析的基本過程是怎樣的? 選擇聚類變
naive bayes 演算法的Python實現與理解
在機器學習中,樸素貝葉斯演算法對於大家來說其實並不陌生,在我前面的部落格中,我也對樸素貝葉斯演算法的原理有所介紹,這篇文章我們一起來學習如何用Python來實現這個樸素貝葉斯演算法。 首先我們匯入numpy這個Python庫,來支援我們後續的一些數學運算。 from numpy i
樸素貝葉斯演算法(Naive Bayes)演算法的python實現 含原始碼
演算法原理不在贅述,請參考: 將程式碼儲存為.py格式,預設使用的資料是程式碼檔案所在目錄下data目錄下的 bayes_train.txt 和bayes_test.txt 兩個檔案分別作為訓練樣例和測試樣例。以上引數可以在原始碼中修改,也可以使用命令列引數傳入,參考以
Mahout分類演算法學習之實現Naive Bayes分類示例
1.簡介 (1) 貝葉斯分類器的分類原理髮源於古典概率理論,是通過某物件的先驗概率,利用貝葉斯公式計算出其後驗概率,即該物件屬於某一類的概率,選擇具有最大後驗概率的類作為該物件所屬的類。樸素貝葉斯分類器(Naive Bayes Classifier)做了一個簡單的假定:給定
常用分類問題的演算法-樸素貝葉斯分類器(Naive Bayes Classifiers)
樸素貝葉斯分類器是分類演算法集合中基於貝葉斯理論的一種演算法。它不是單一存在的,而是一個演算法家族,在這個演算法家族中它們都有共同的規則。例如每個被分類的特徵對與其他的特徵對都是相互獨立的。 樸素貝葉斯分類器的核心思想是: 1、將所有特徵的取值看成已經發生的
機器學習演算法之樸素貝葉斯(Naive Bayes)--第二篇
引言 這篇文章主要介紹將樸素貝葉斯模型應用到文字分類任務的技巧和方法。 詞袋模型(The Bag of Words Model) 對於機器學習演算法來說,特徵的選擇是一個很重要的過程。那麼如何從文字訓練集中選出好的特徵呢?在自然語言處理中,一個常見
資料探勘十大經典演算法(九) 樸素貝葉斯分類器 Naive Bayes
分類演算法--------貝葉斯定理: 樸素貝葉斯的基本思想:對於給出的待分類項,求解在此項出現的條件下各個類別出現的概率,哪個最大,就認為此待分類項屬於哪個類別。 可以看到,整個樸素貝葉斯分類分為三個階段: 第一階段——準備工作階段,這個階段的任務是為樸
機器學習演算法之樸素貝葉斯(Naive Bayes)--第一篇
引言 先前曾經看了一篇文章,一個老外程式設計師寫了一些很牛的Shell指令碼,包括晚下班自動給老婆發簡訊啊,自動衝Coffee啊,自動掃描一個DBA發來的郵件啊, 等等。於是我也想用自己所學來做一點有趣的事情。我的想法如下: 首先我寫個scrapy指令碼來
sk-learn例項-用樸素貝葉斯演算法(Naive Bayes)對文字進行分類
簡介 樸素貝葉斯(Naive Bayes)是一個非常簡單,但是實用性很強的分類模型,與基於線性假設的模型(線性分類器和支援向量機分類器)不同,樸素貝葉斯分類器的構造基礎是貝葉斯理論。 抽象一些的說,樸素貝葉斯分類器會單獨考量每一維度特徵被分類的條件概率,進而綜合這些概率並對其所在的特
《BI那點兒事》Microsoft 決策樹演算法——找出三國武將特性分佈,獻給廣大的三國愛好者們
根據遊戲《三國志11》武將資料,利用決策樹分析,找出三國武將特性分佈。其中變數包括統率、武力、智力、政治、魅力、身分。變數說明:統率:武將帶兵出征時的部隊防禦力。統帥越高受到普通攻擊與兵法攻擊越少。武力:武將帶兵出征時的部隊攻擊力,武力越高發動兵法或者普通攻擊時對地方部隊的傷害就越高;並且當發動單挑時雙方武將
樸素貝葉斯分類器的應用 Naive Bayes classifier
upload dia get 等號 分布 eat 實現 維基 5.5 一、病人分類的例子 讓我從一個例子開始講起,你會看到貝葉斯分類器很好懂,一點都不難。 某個醫院早上收了六個門診病人,如下表。 癥狀 職業 疾病 打噴嚏 護士 感冒 打噴嚏
【黎明傳數==>機器學習速成寶典】模型篇05——樸素貝葉斯【Naive Bayes】(附python代碼)
pytho res tex 機器學習 樸素貝葉斯 spa 什麽 之一 類別 目錄 先驗概率與後驗概率 什麽是樸素貝葉斯 模型的三個基本要素 構造kd樹 kd樹的最近鄰搜索 kd樹的k近鄰搜索 Python代碼(sklearn庫) 先
【Spark MLlib速成寶典】模型篇04樸素貝葉斯【Naive Bayes】(Python版)
width pla evaluate 特征 mem order 一個數 ble same 目錄 樸素貝葉斯原理 樸素貝葉斯代碼(Spark Python) 樸素貝葉斯原理 詳見博文:http://www.cnblogs.com/itmor
機器學習實戰三(Naive Bayes)
需要 blog bag puts list tps foo 實戰 簡單的 機器學習實戰三(Naive Bayes) 前兩章的兩種分類算法,是確定的分類器,但是有時會產生一些錯誤的分類結果,這時可以要求分類器給出一個最優的猜測結果,估計概率。樸素貝葉斯就是其中一種。 學過概率
naive bayes classifier in data mining
lis list www. problem chap div explain pos problems https://www-users.cs.umn.edu/~kumar001/dmbook/slides/chap4_naive_bayes.pdf -- textbo
機器學習分類實例——SVM(修改)/Decision Tree/Naive Bayes
nature console 內容 sign dal 一次 .html not cat 機器學習分類實例——SVM(修改)/Decision Tree/Naive Bayes 20180427-28筆記、30總結 已經5月了,畢設告一段落了,該準備論文了。前天開會老師說
基於Naive Bayes算法的文本分類
二進制 貝葉斯分類 根據 分詞 步驟 矩陣 get choose 類型 理論 什麽是樸素貝葉斯算法? 樸素貝葉斯分類器是一種基於貝葉斯定理的弱分類器,所有樸素貝葉斯分類器都假定樣本每個特征與其他特征都不相關。舉個例子,如果一種水果其具有紅,圓,直徑大概3英寸等特征,該
機器學習---樸素貝葉斯分類器(Machine Learning Naive Bayes Classifier)
垃圾郵件 垃圾 bubuko 自己 整理 href 極值 multi 帶來 樸素貝葉斯分類器是一組簡單快速的分類算法。網上已經有很多文章介紹,比如這篇寫得比較好:https://blog.csdn.net/sinat_36246371/article/details/601
樸素貝葉斯算法(Naive Bayes)
ive log 分布 做了 規模 line clas 獨立 輸入數據 1. 前言 說到樸素貝葉斯算法,首先牽扯到的一個概念是判別式和生成式。 判別式:就是直接學習出特征輸出\(Y\)和特征\(X\)之間的關系,如決策函數\(Y=f(X)\),或者從概率論的角度,求出條件分