
《BI那點兒事》Microsoft 聚類分析演算法——三國人物身份劃分
什麼是聚類分析? 
聚類分析屬於探索性的資料分析方法。通常,我們利用聚類分析將看似無序的物件進行分組、歸類,以達到更好地理解研究物件的目的。聚類結果要求組內物件相似性較高,組間物件相似性較低。在三國資料分析中,很多問題可以藉助聚類分析來解決,比如三國人物身份劃分。
聚類分析的基本過程是怎樣的? 
- 選擇聚類變數
在分析三國人物身份的時候,我們會根據一定的假設,儘可能選取對角色身份有影響的變數,這些變數一般包含與身份密切相關的統率、武力、智力、政治、魅力、特技、槍兵、戟兵、弩兵、騎兵、兵器、水軍等。但是,聚類分析過程對用於聚類的變數還有一定的要求:
這些變數在不同研究物件上的值具有明顯差異;
這些變數之間不能存在高度相關。
因為,首先,用於聚類的變數數目不是越多越好,沒有明顯差異的變數對聚類沒有起到實質意義,而且可能使結果產生偏差;其次,高度相關的變數相當於給這些變數進行了加權,等於放大了某方面因素對使用者分類的作用。
識別合適的聚類變數的方法:
對變數做聚類分析,從聚得的各類中挑選出一個有代表性的變數;
做主成份分析或因子分析,產生新的變數作為聚類變數。
- 聚類分析
相對於聚類前的準備工作,真正的執行過程顯得異常簡單。資料準備好後,丟到分析軟體(通常是分析服務)裡面跑一下,結果就出來了。
這裡面遇到的一個問題是,把人物分成多少類合適?通常,可以結合幾個標準綜合判斷:
1. 看拐點
2. 憑經驗或人物特性判斷
3. 在邏輯上能夠清楚地解釋
- 找出各類使用者的重要特徵
確定一種分類方案之後,接下來,我們需要返回觀察各類別三國人物在各個變數上的表現。根據差異檢驗的結果,我們以顏色區分出不同類使用者在這項指標上的水平高低。
- 聚類解釋&命名
在理解和解釋使用者分類時,最好可以結合更多的資料,例如,三國志12資料等……最後,選取每一類別最明顯的幾個特徵為其命名,就大功告成啦!
下面我們進入主題,同樣我們繼續利用上次的解決方案,依次步驟如下:

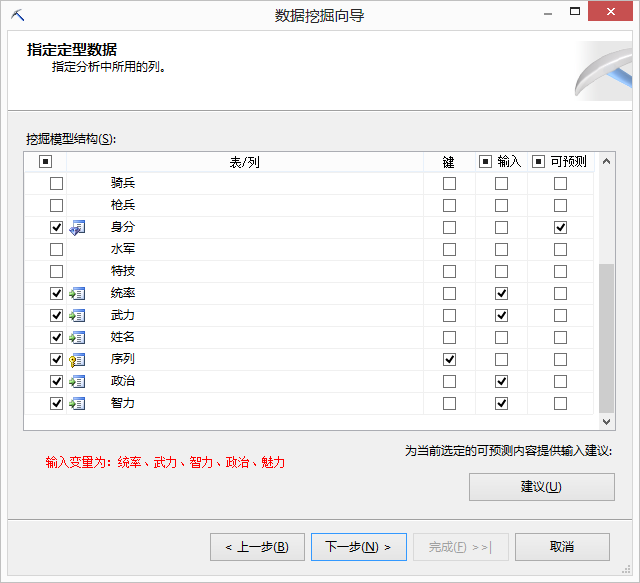

在挖掘模型中,主要是列出所建立的挖掘模型,也可以新增挖掘模型,並調整變數,變數使用情況包含Ignore(忽略)、Input(輸入變數)、Predict(預測變數、輸入變數)以及PredictOnly(預測變數),如圖所示:

而在挖掘模型上點選滑鼠右鍵,選擇“設定演算法引數”針對方法論的引數設定加以編輯,其中包含:
CLUSTER_COUNT:指定演算法所要建立的聚類的近似數目。如果無法從資料中建立聚類的近似數目,演算法便會盡可能建立聚類。若將CLUSTER_COUNT設定為0,則演算法便會使用啟發式決定所應建立的聚類數目,預設值為10。
CLUSTER_SEED:指定在模型建立的初始階段,用於隨機產生聚類的種子數。
CLUSTERING_METHOD:演算法使用的聚類方法可以是可擴充套件的EM(1)、不可擴充的EM(2)、可擴充的K-means(3)或不可擴充的K-means(4)。
MAXIMUM_INPUT_ATTRIBUTE:指定在呼叫功能選項之前,演算法可以處理輸入屬性的最大數目。將此值設定為0,會指定沒有屬性最大數目的限制。
MAXIMUM_STATES:指定演算法所支援屬性狀態的最大數目。如果屬性擁有的狀態數目大於狀態的最大數目,演算法會使用屬性最常用的狀態並將其他的狀態視為遺漏。
MINIMUM_SUPPORT:此引數指定每個聚類中的最小案例數目。
MODELLING_CARDINALITY:此引數指定聚類處理期間建構的範例模型數目。
SAMPLE_SIZE:指定如果CLUSTERING_METHOD引數設定為可擴充的聚類方法時,演算法使用在每個行程上的案例數目。將SAMPLE_SIZE設定為0會導致整個資料集在單一程序中聚類,如此可能會造成記憶體和效率的問題。
STOPPING_TOLERANCE:指定用來決定何時到達聚合以及演算法完成建立模型的值。當聚類概率的整體變更小於SHOPPING_TOLERANCE除以模型大小的比率時,就到達聚合。
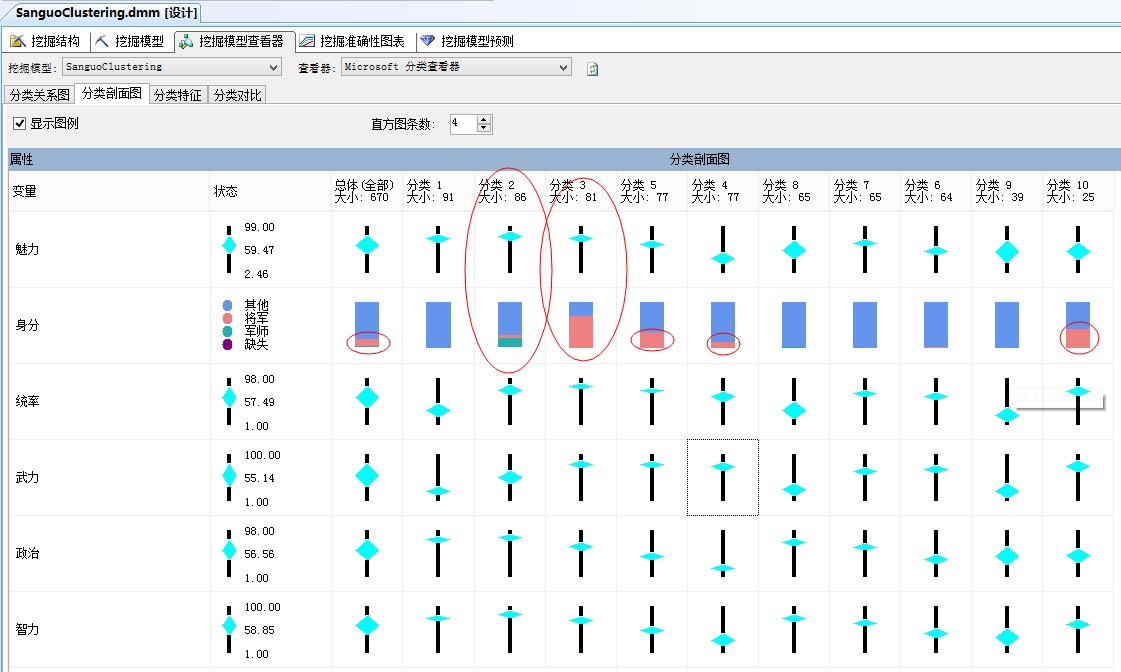
挖掘模型檢視器則是呈現此聚類分析結果,其中聚類圖表則是表現各類關聯性的強弱,對於資料的分佈進一步加以瞭解。而在每一聚類結點上,點選右鍵,再出現的選單上選擇“鑽取”,則可以瀏覽屬於這一類的樣本資料特徵。
從“分類剖面圖”瞭解因變數與自變數間的關聯性強弱程度,如圖
“分類特性”主要是呈現每一類的特性,見圖

在“分類對比”上,主要就是呈現出兩類間特性的比較,如圖
參考文獻:
Microsoft 聚類分析演算法
http://msdn.microsoft.com/zh-cn/library/ms174879.aspx
相關推薦
《BI那點兒事》Microsoft 聚類分析演算法——三國人物身份劃分
什麼是聚類分析? 聚類分析屬於探索性的資料分析方法。通常,我們利用聚類分析將看似無序的物件進行分組、歸類,以達到更好地理解研究物件的目的。聚類結果要求組內物件相似性較高,組間物件相似性較低。在三國資料分析中,很多問題可以藉助聚類分析來解決,比如三國人物身份劃分。聚類分析的基本過程是怎樣的? 選擇聚類變
Microsoft Naive Bayes 演算法——三國人物身份劃分
Microsoft樸素貝葉斯是SSAS中最簡單的演算法,通常用作理解資料基本分組的起點。這類處理的一般特徵就是分類。這個演算法之所以稱為“樸素”,是因為所有屬性的重要性是一樣的,沒有誰比誰更高。貝葉斯之名則源於Thomas Bayes,他想出了一種運用算術(可能性)原則來理解資料的方法。對此演算法的另一個
《BI那點兒事》Microsoft 順序分析和聚類分析演算法
Microsoft 順序分析和聚類分析演算法是由 Microsoft SQL Server Analysis Services 提供的一種順序分析演算法。您可以使用該演算法來研究包含可通過下面的路徑或“順序”連結到的事件的資料。該演算法通過對相同的順序進行分組或分類來查詢最常見的順序。下面是一些順序示例:
《BI那點兒事》Microsoft 線性迴歸演算法
Microsoft 線性迴歸演算法是 Microsoft 決策樹演算法的一種變體,有助於計算依賴變數和獨立變數之間的線性關係,然後使用該關係進行預測。該關係採用的表示形式是最能代表資料序列的線的公式。例如,以下關係圖中的線是資料最可能的線性表示形式。 關係圖中的每個資料點都有一個與該資料點與迴歸線之間距離關
《BI那點兒事》Microsoft 神經網路演算法
Microsoft神經網路是迄今為止最強大、最複雜的演算法。要想知道它有多複雜,請看SQL Server聯機叢書對該演算法的說明:“這個演算法通過建立多層感知神經元網路,建立分類和迴歸挖掘模型。與Microsoft決策樹演算法類似,在給定了可預測屬性的每個狀態時, Microsoft神經網路演算法計算輸入屬性
《BI那點兒事》Microsoft 決策樹演算法——找出三國武將特性分佈,獻給廣大的三國愛好者們
根據遊戲《三國志11》武將資料,利用決策樹分析,找出三國武將特性分佈。其中變數包括統率、武力、智力、政治、魅力、身分。變數說明:統率:武將帶兵出征時的部隊防禦力。統帥越高受到普通攻擊與兵法攻擊越少。武力:武將帶兵出征時的部隊攻擊力,武力越高發動兵法或者普通攻擊時對地方部隊的傷害就越高;並且當發動單挑時雙方武將
《BI那點兒事》SSRS圖表和儀表——雷達圖分析三國超一流謀士、統帥資料(圖文並茂)
雷達圖分析三國超一流謀士、統帥資料,獻給廣大的三國愛好者們,希望喜歡三國的朋友一起討論,加深對傳奇三國時代的瞭解 建立資料環境: -- 抽取三國超一流謀士TOP 10資料 DECLARE @t1 TABLE ( [姓名] NVARCHAR(255) , [統率]
《BI那點兒事》運用標準計分和離差——分析三國超一流統帥綜合實力排名 絕對客觀,資料說話
資料分析基礎概念:標準計分: 1、無論作為變數的滿分為幾分,其標準計分的平均數勢必為0,而其標準差勢必為1。2、無論作為變數的單位是什麼,其標準計分的平均數勢必為0,而其標準差勢必為1。公式為: 離差:離差就是應用標準計分所得的數值。1、無論作為變數的滿分為幾分,其離差的平均數勢必為50,而其標準差勢必為1
《BI那點兒事》Microsoft 決策樹演算法
Microsoft 決策樹演算法是由 Microsoft SQL Server Analysis Services 提供的分類和迴歸演算法,用於對離散和連續屬性進行預測性建模。對於離散屬性,該演算法根據資料集中輸入列之間的關係進行預測。它使用這些列的值(也稱之為狀態)預測指定為可預測的列的狀態。具體地說,該演
《BI那點兒事》三國資料分析系列——蜀漢五虎上將與魏五子良將武力分析,絕對的經典分析
獻給廣大的三國愛好者們,希望喜歡三國的朋友一起討論,加深對傳奇三國時代的瞭解 資料分析基礎概念:集中趨勢分析是指在大量測評資料分佈中,測評資料向某點集中的情況。總體(population)是指客觀存在的,並在同一性質的基礎上結合起來的許多個別單位的整體,即具有某一特性的一類事物的全體,又叫母體或全域。簡單地
《BI那點兒事》三國人物智力分佈狀態分析
獻給廣大的三國愛好者們,希望喜歡三國的朋友一起討論,加深對傳奇三國時代的瞭解資料分析基礎概念:資料分為“不可測量”的資料和“可測量”的資料。不可測量的資料稱為“分類資料”(Category Data或Categorical Data。),而可測量的資料稱為“數值資料”(Numerical Data)。組中值:
《BI那點兒事》Microsoft 時序演算法——驗證神奇的斐波那契數列
斐波那契數列指的是這樣一個數列 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, 233,377,610,987,1597,2584,4181,6765,10946,17711,28657,46368斐波那契數列的發明者,是義大利數學家列昂納多·斐波那契(Leonar
《BI那點兒事》資料探勘各類演算法——準確性驗證
準確性驗證示例1:——基於三國志11資料庫 資料準備: 挖掘模型:依次為:Naive Bayes 演算法、聚類分析演算法、決策樹演算法、神經網路演算法、邏輯迴歸演算法、關聯演算法提升圖: 依次排名為: 1. 神經網路演算法(92.69% 0.99)2. 邏輯迴歸演算法(92.39% 0.99)3. 決策
《BI那點兒事》淺析十三種常用的資料探勘的技術
一、前沿 資料探勘就是從大量的、不完全的、有噪聲的、模糊的、隨機的資料中,提取隱含在其中的、人們事先不知道的但又是潛在有用的資訊和知識的過程。資料探勘的任務是從資料集中發現模式,可以發現的模式有很多種,按功能可以分為兩大類:預測性(Predictive)模式和描述性(Descriptive)模式。在應用
《BI那點兒事》資料探勘初探
什麼是資料探勘? 資料探勘(Data Mining),又稱資訊發掘(Knowledge Discovery),是用自動或半自動化的方法在資料中找到潛在的,有價值的資訊和規則。 資料探勘技術來源於資料庫,統計和人工智慧。 資料探勘能夠做什麼 對企業中產生的大量的資料進行分析,找出其中潛藏的規
《BI那點兒事》資料流轉換——查詢轉換
查詢轉換通過聯接輸入列中的資料和引用資料集中的列來執行查詢。是完全匹配查詢。在源表中查詢與字表能關聯的所有源表記錄。準備資料。源表 T_QualMoisture_Middle_Detail字典表 T_DIC_QualProcess資料流任務設計圖: 設計步驟: (adsbygo
《BI那點兒事》資料流轉換——多播、Union All、合併、合併聯接
建立測試資料: CREATE TABLE FactResults ( Name VARCHAR(50) , Course VARCHAR(50) , Score INT ) INSERT INTO FactResults
《BI那點兒事》資料探勘的主要方法
一、迴歸分析目的:設法找出變數間的依存(數量)關係, 用函式關係式表達出來。所謂迴歸分析法,是在掌握大量觀察資料的基礎上,利用數理統計方法建立因變數與自變數之間的迴歸關係函式表示式(稱迴歸方程式)。迴歸分析中,當研究的因果關係只涉及因變數和一個自變數時,叫做一元迴歸分析;當研究的因果關係涉及因變數和兩個或兩個
《BI那點兒事—資料的藝術》理解維度資料倉庫——事實表、維度表、聚合表
事實表 在多維資料倉庫中,儲存度量值的詳細值或事實的表稱為“事實表”。一個按照州、產品和月份劃分的銷售量和銷售額儲存的事實表有5個列,概念上與下面的示例類似。 Sate Product Mouth Units Dollars
《BI那點兒事》資料流轉換——OLE DB 命令轉換
OLE DB命令對資料流中的資料行執行一個OLE DB命令。它針對資料表中的每一行進行更新操作,可以事先將要更新的資料存放在表中。或者針對一個有輸入引數的儲存過程,可以將這些引數存放在一個數據表中,不用每次都輸入引數。示例資料準備: CREATE TABLE SourceParametersForSt