
免費GPU!平民玩家的機器學習春天來了!
文-William Koehrsen
譯- Allen
近年來,資料科學呈現出了兩個明顯的趨勢:
1.越來越多的資料分析和模型訓練通過雲端計算完成
2.機器學習工作流水線(英文名稱為pipeline)自身正在通過演算法進行優化
使用Google Colab進行雲計算
如今,幾乎每個人都擁有自己的計算機。但膝上型電腦和臺式電腦一般只適用於日常性的工作。而如今機器學習要處理的資料集越來越大,對算力的要求也越來越高,利用雲端計算進行機器學習幾乎是普通使用者的不二選擇。
在本文,我們將用雲上的Jupyter Notebook來執行一個簡單的資料工作流程。使用的是Google最新的黑科技Google Colab——一個免費線上的Jupyter Notebooks(目前只有Python核心)。這個產品的出現意味著無論你身處哪裡,個人電腦是否帶在身邊,只要能聯網,就可以跑自己的機器學習模型。Google的虛擬機器上已經配置好了大部分你所需要的資料科學庫,無需配置環境就可以直接使用,而且還可以免費使用一個NVIDIA Tesla K80 GPU!!!

複製到Chrome瀏覽器,直接開啟,需要登入Google賬號。開啟之後的介面是下面這樣的,點選檔案>在雲端硬碟中儲存一份副本。然後你就可以在自己的Drive上開啟這個檔案進行編輯和執行。
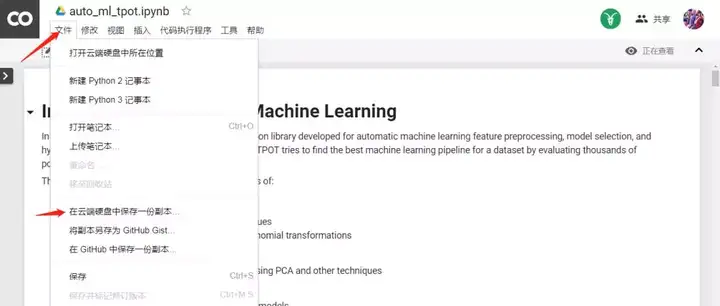
可以說,Google Colab明顯降低了利用雲端計算的門檻。不難想象,類似的線上資源在日後將會越來越容易獲得。對於已經在本地電腦用過Jupyter Notebooks的同學來說,這是一個向雲端計算過渡的好機會。
適用TPOT進行機器學習自動化
接下來,向同學們介紹另外一樣神器——機器學習自動化(縮寫為Auto-ml)。它能夠通過演算法為特定的問題設計和優化機器學習工作流水線。在本文中,機器學習流水線包括以下幾個步驟:
1.特徵預處理: 填充缺失值,縮放,構建新的特徵
2.特徵選擇:降維
3.模型選擇:對多個模型進行評估
4.調參:找到最佳的模型超引數設定
對以上的四個步驟進行組合你可以得到幾乎無限多種流水線,而每個問題的最佳解決方式都不一樣。設計一個機器學習流水線是一個非常消耗時間以及容易踩坑的過程,所以我們一般無法遍歷所有流水線,也就是說你永遠不知道你設計出來的流水線是不是最優的。這個時候,機器學習自動化出現了,它可以幫助你評估成千上萬種可能的流水線的表現,自動找出最優的(或接近最優的)解決方案。
機器學習只是資料科學的一部分,機器學習自動化並不意味著可以替代資料科學家。相反,機器學習自動化可以解放資料科學家的雙手,讓他們可以專注於更有價值的部分,比如資料收集、模型解釋等等
目前已經有許多機器學習自動化的工具——H20、auto-sklearn、Google Cloud AutoML以及接下來我要重點介紹的TPOT(Tree-based Pipeline Optimization Tool,樹型流水線優化工具)。TPOT主要是基於遺傳演算法的原理來尋找最佳的機器學習流水線。
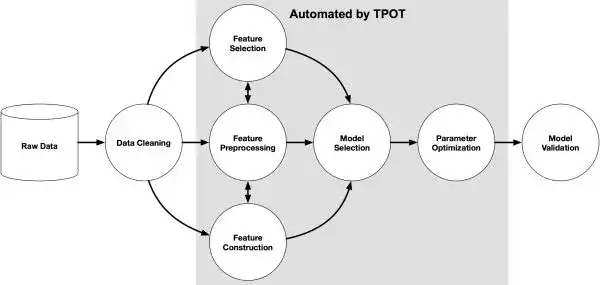
遺傳演算法對於建立機器學習模型的主要好處就是深度的探索。對於人來說,即使沒有時間的限制,也無法嘗試完所有的預處理、模型、超引數的組合,畢竟個人的知識和想象力是有限的。而遺傳演算法對於任何機器學習流水線都不會有初始的偏見(人類可能會根據自己的經驗,產生一些偏見),每一條流水線都會被客觀地評估。此外,遺傳演算法中的適應度函式使得流水線探索空間中,最有潛力的組合區域比表現差的區域探索地更為徹底,這也是遺傳演算法的一大優勢。
兩者相結合:雲上的機器學習自動化
來來來,這個實現其實很簡單!有了前面所述的背景,我們就可以愉快地在Google Colab上使用TPOT來實現機器學習的自動化。
我們接下來嘗試去解決一個監督迴歸的問題 : 通過紐約市的能源資料,我們希望預測出建築物的能源星級。筆者曾經手動地進行特徵工程、降維、模型篩選、調參,最後訓練出了一個Gradient Boosting 迴歸模型,在測試集上的平均絕對誤差是9.06。讓我們來看看自動化後得到的模型效能如何?
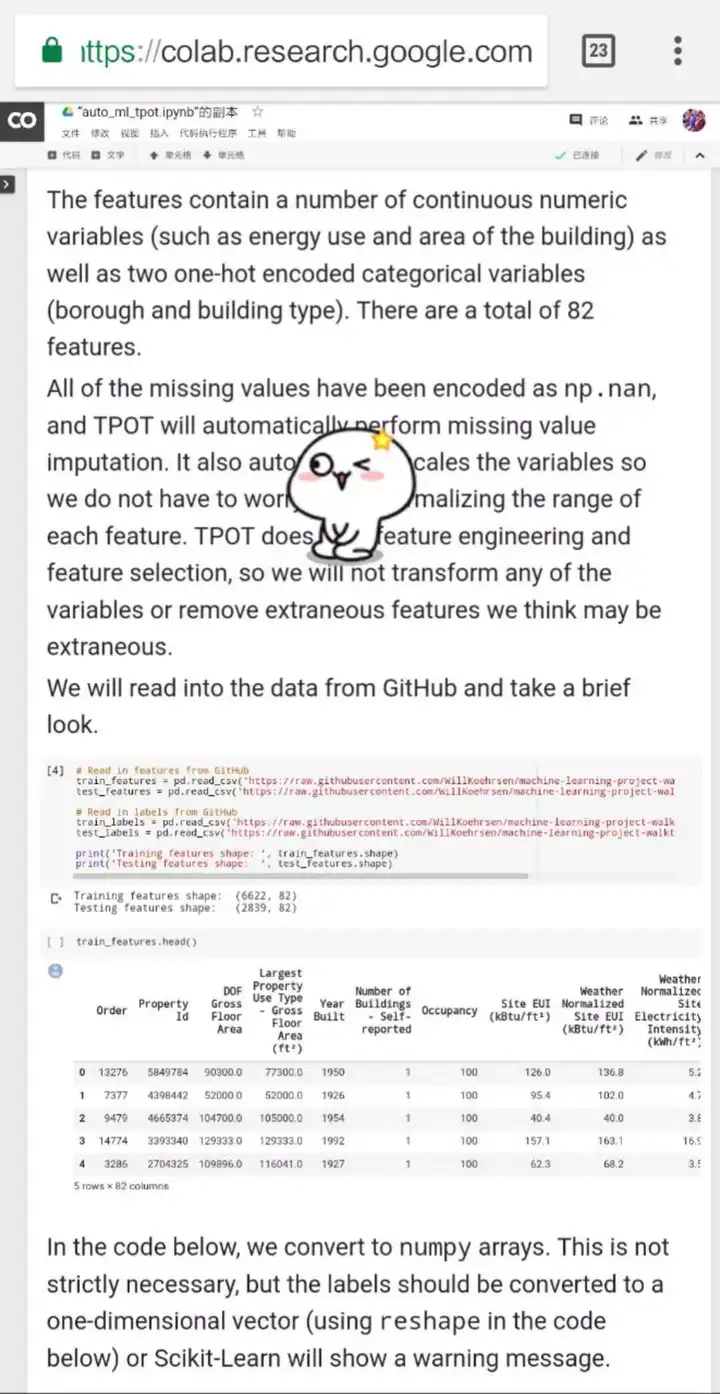
資料集包含了幾十個連續型數值變數(比如建築的能源使用量和建築面積)以及兩個獨熱編碼的分類變數(地區名與建築型別),總計有82個特徵。
首先,我們需要確定在Google Colab的環境裡面是否已經安裝了TPOT。一般來說,大多數的資料科學包都已經安裝好了,如果要新增新的包,可以使用如下的命令(記得在前面加“!”):

在讀取資料後,我們通常會填充缺失的值以及將特徵歸一化。好訊息是,除了前面所述的特徵工程、模型選擇、調參,TPOT還會自動填充缺失值和進行特徵縮放!所以,我們下一步只需要建立TPOT優化器就可以了。
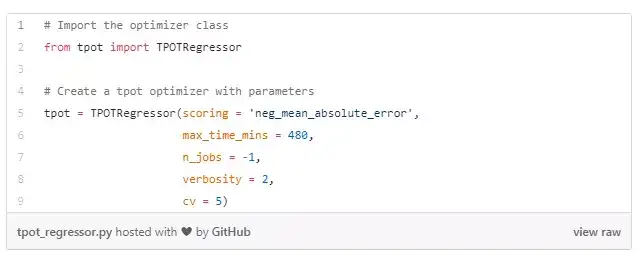
使用預設引數,TPOT優化器會建立100個流水線,每個流水線演化100代,得出這1萬個流水線的評分。使用十折交叉驗證,這意味著將有10萬次訓練要跑!即使我們使用的是Google的計算資源,但還是會有時間限制的。為了避免超出Colab伺服器的使用時限(Google只允許12個小時的連續執行時間),我們將設定TPOT的執行時間最大為8小時,儘管TPOT的一般執行時間是幾天,但是通過幾個小時的優化,我們仍然能得到不錯的模型。
我們將設定如下的引數:
● scoring = neg_mean_absolute error : 迴歸表現的評估指標
● max_time_minutes = 480: 限制執行時間為8小時
● n_jobs = -1: 使用計算機上的所有可用核心
● verbosity = 2: 訓練時顯示有限的資訊
● cv = 5: 使用5折交叉驗證(預設值為10)
當然,還有其他的引數可以設定,但是它們保留預設值也適用於大多數情況,在這裡就不再另外設定。
TPOT優化器的語法設計與Scikit-Learn模型相同,因此我們可以使用.fit方法訓練優化器。

在訓練過程中,我們獲得瞭如下的資訊:
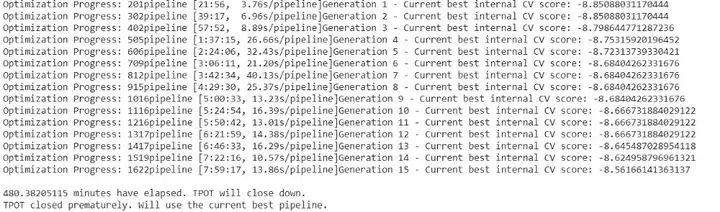
由於時間限制,每個流水線只能演化15代,這意味著我們評估了1500個不同的獨立流水線的得分,已經比我們手動嘗試要多得多了!
一旦模型訓練好了,我們可以通過 tpot.fitted_pipeline_ 檢視最優的流水線。我們還可以將模型儲存到一個Python指令碼中:

由於我們使用的是Google Colab notebook,如果我們要從伺服器上將這個流水線下載到本地,則需要使用Google Colab的檔案管理庫:
我們可以開啟 tpot_exported_pipeline.py 檔案檢視完整的流水線:
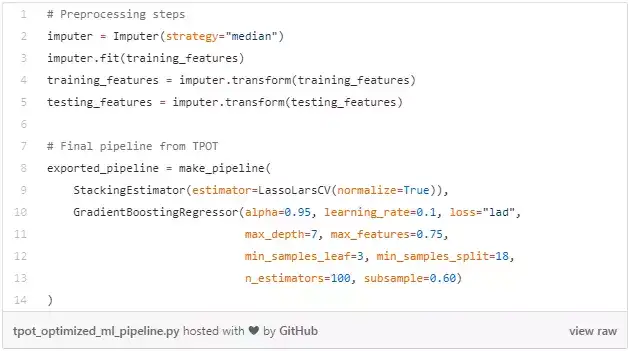
(這個檔案的下載地址在文末)
我們可以看到,優化器已經為我們填充了缺失值並且建立了一個完整的流水線!最終的預測模型是一個融合了 LassoLarsCV 和 GradientBoostingRegressor 兩種演算法的融合模型(Stacking model)。實話說,如果我自己動手訓練,可能無法得到這樣一個複雜的模型。
現在,激動人心的時刻到了,讓我們來看看模型在測試集上的表現。我們可以使用.score來獲得平均絕對誤差:
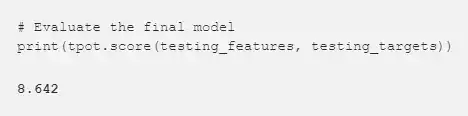
這個專案我曾經自己手動花了幾個小時完成,最終得到的Gradient Boosting Regressor 模型得到的平均絕對誤差是9.06。機器學習自動化真的顯著地提高了最終模型的表現,也大幅減少了開發時間。
總結一下
在這篇文章中,我們簡要地介紹了使用雲端計算進行機器學習以及機器學習自動化。只要你有谷歌賬號同時能聯網,那麼就可以使用Google Colab 進行開發,執行和分享機器學習工作檔案。使用TPOT,可以通過自動化的訓練和評估過程獲得最優的機器學習流水線(包括特徵預處理、模型選擇、調參).另外,我們也意識到,機器學習自動化並不會替代資料科學家,反而它會讓資料科學家能夠抽出更多的時間花在更有價值的工作中。
作為一個新誕生的事物,TPOT已經相對成熟,而且非常易於使用。大家還不趕緊運用這個方法去嘗試解決機器學習的問題(Kaggle上有很多不錯的專案)!在Google Colab 的notebook上執行一個自動化的機器學習專案,簡直未來感十足有木有,而且門檻居然如此之低,不說了,小編突然想在手機上跑下試試~
完美執行!
文中所提到的相關檔案下載地址:
相關推薦
免費GPU!平民玩家的機器學習春天來了!
文-William Koehrsen 譯- Allen 近年來,資料科學呈現出了兩個明顯的趨勢: 1.越來越多的資料分析和模型訓練通過雲端計算完成 2.機器學習工作流水線(英文名稱為pipeline)自身正在通過演算法進行優化 使用Google C
收藏!超全機器學習資料合集!(附下載)
最近在群裡發現一些小夥伴在尋找資料的時候總是無處可找,網上出現很多收集免費資料再去打包收錢的人,我看不慣這樣的人,所以把自己收集的檔案分享給大家。 百度雲經常抽風,如果大家遇到了失效的連結,請在評論區給我評論,我會很快的更新。 1:資料探勘:概念與技術(中文第三版) 連結: https
流程的冬天來了?不,春天來了!
2011年,Facebook前工程總監黃易山強調,Facebook的新工作流程的通常模式是“只有在事情快要不可收拾的時候,才會考慮引入新的工作流程”; 有人說,從2012年開始,網際網路風潮的來襲讓中國的流程管理好不容易在金融危機後攢起的激情火花慢慢消散; 2015年,谷歌
亞馬遜的VR購物新體驗!網購者的福利來了!
strong ear 百萬 cnblogs 發展 新功能 提前 vr技術 似的 (VR開發網2017年5月5日訊)跟蹤亞馬遜在VR中的工作可能是棘手的,因為公司在似乎涉及多個領域時,響應媒體查詢而聞名遐邇。 該公司正在通過其Lumberyard開發引擎幫助制作VR
您有一份免費的機器學習課程待領取!
本文由雲+社群發表 作者:騰訊雲學院 人人都能上手的機器學習免費實戰課程!
唐宇迪-機器學習/深度學習 系列課程福利大發送!不單優惠 還送機器學習必備實戰書籍!
機器學習 深度學習 人工智能 決勝AI就在今天 Hi同學們,給大家推薦一本機器學習的入門佳品:機器學習實戰。這本書可以說是我看過最通俗易懂的機器學習書籍了,並沒有上來直接闡述一些看著就頭疼的各種數學公式,而是以實際案例為出發點一步步帶領大家完成各個算法的建模與練習,人工智能必備No.1! 福利
11月最佳機器學習開源專案Top10!
整理 | Jane 出品 | AI科技大本營 過去一個月,我們從近 250 個機器學習開源專案中挑選出了最受大家關注的前十名。這些專案在 GitHub 上平均 Stars 數為 2713。這些專案涉及由 Google AI Research 開源的 BER
外行人都能看得懂的機器學習,錯過了血虧!
前言 只有光頭才能變強 沒錯,這篇主要跟大家一起入門機器學習。作為一個開發者,”人工智慧“肯定是聽過的。作為一個開發面試者,肯定也會見過”機器學習“這個崗位(反正我校招的時候就遇到過)。 可能還會聽過或者見過“深度學習”、“神經網路”等等這些非常火的名詞,那你對這些術語瞭解多少呢? 相信大家
12月19日雲棲精選夜讀 | 外行人都能看得懂的機器學習,錯過了血虧!
前言 只有光頭才能變強 沒錯,這篇主要跟大家一起入門機器學習。作為一個開發者,”人工智慧“肯定是聽過的。作為一個開發面試者,肯定也會見過”機器學習“這個崗位(反正我校招的時候就遇到過)。 可能還會聽過或者見過“深度學習”、“神經網路”等等這些非常火的名詞,那你對這些術語瞭解多少呢? 相信大家這幾天在朋友圈也可
【機器學習】超詳細!上線一個機器學習專案你需要哪些準備?
Canvas是用於設計和記錄機器學習系統的模板。它比簡單的文字文件具有優勢,因為Canvas用簡
用 Python 做機器學習至關重要的庫!
用 Python 做機器學習不得不收藏的重要庫 Python通常被應用統計技術或者資料分析人員當做工作中的首選語言。資料科學家也會用python作為連線自身工作與WEB 應用程式/生產環境整合中。 Python在機器學習領域非常出色
每週一書:290頁《機器學習導論》分享!
隨著計算機技術的發展,我們現在已經擁有儲存和處理海量資料以及通過計算機網路從遠端站點訪問資料的能力。目前大多數的資料存取裝置都是數字裝置,記錄的資料也很可靠。 機器學習不僅僅是資料庫方面的問題,它也是人工智慧的組成部分。為了智慧化,處於變化環境中的系統必須具備學習的能力
超詳細!如何準備機器學習競賽?
點選上方藍色字型,關注我們Kaggle 是一個流行的資料科學競賽平臺,作為一個競賽平臺,Kagg
機器學習第5周!
教輔說這周的作業是史上最難,果不其然,我花了好久好久才完成….好吧其實也沒有很難,就一開始的cost function卡了很久,後面倒是挺順利的,簡單地調了幾遍就過了,現在第五週完成了,還有1個小時第六週就過期了。。。路漫漫,是真的。 1. cost fu
拜託,別再問怎麼深入學習分散式架構了!
由於分散式系統所涉及到的領域眾多,知識龐雜,很多新人在最初往往找不到頭緒,不知道從何處下手來一步步學習分散式架構。 本文試圖通過一個最簡單的、常用的分散式系統,來闡述分散式系統中的一些基本問題。 負載均衡 分散式快取 分散式檔案系統/CDN 分散式RPC 分散
阿里深度學習框架開源了!無縫對接TensorFlow、PyTorch
阿里巴巴內部透露將開源內部深度學習框架 X-DeepLearning的計劃,這是業界首個面向廣告、推薦、搜尋等高維稀疏資料場景的深度學習開源框架,可以與TensorFlow、PyTorch 和 MXNet 等現有框架形成互補。 X-Deep Learning(下文簡稱XDL)由阿里巴巴旗下大資料營銷平臺阿里
重磅邀請函來了!首屆騰訊雲加社群開發者大會免費報名!
2018年12月15日,首屆“騰訊雲+社群開發者大會”即將在北京隆重舉行,騰訊雲邀請廣大開發者共同探討雲端新技術、新能力。屆時,騰訊雲將邀請超過40位行業內的技術專家,超過1000名開發者參與本次盛會,分享行業經驗,沉澱雲端技術。 本次大會的戰略合作伙伴英特爾也將亮相,展示雙方在資
為什麼某個問題可以用機器學習方法來解決?
不知道大家有沒有想過,基於歷史資料去預測未知資料的問題,為什麼我們就知道這種問題可以用機器學習來解決? 偶爾看到了《統計學習方法概論》裡的一個小節,小節的內容我認為可以解答這個問題。總而言之就是,這是一種假設,即假設他可以用機器學習方法來解決,同時假設學習模型是存在的。該小
重磅邀請函來了!首屆“騰訊雲+社群開發者大會”免費報名!
歡迎大家前往騰訊雲+社群,獲取更多騰訊海量技術實踐乾貨哦~ 2018年12月15日,首屆“騰訊雲+社群開發者大會”即將在北京隆重舉行,騰訊雲邀請廣大開發者共同探討雲端新技術、新能力。屆時,騰訊雲將邀請超過40位行業內的技術專家,超過1000名開發者參與本次盛會,分享行業經驗,沉澱雲端技術。 自騰訊組織架構調
有了深度學習,傳統的機器學習演算法沒落了嗎,還有必要去學習嗎?
深度學習在最近兩年非常火爆,它迅速地成長起來了,並且以其瘋狂的實證結果著實令我們驚奇。 但深度學習是否真的就取代了傳統或者其他機器學習演算法了呢?那麼,傳統的機器學習還有必要去學習嗎?首先來看一位同學的