
LevelDB原始碼分析之九:env
考慮到移植以及靈活性,LevelDB將系統相關的處理(檔案/程序/時間)抽象成Evn,使用者可以自己實現相應的介面,作為option的一部分傳入,預設使用自帶的實現。
env.h中聲明瞭:
- 虛基類env,在env_posix.cc中,派生類PosixEnv繼承自env類,是LevelDB的預設實現。
- 虛基類WritableFile、SequentialFile、RandomAccessFile,分別是檔案的寫抽象類,順序讀抽象類和隨機讀抽象類
- 類Logger,log檔案的寫入介面,log檔案是防止系統異常終止造成資料丟失,是memtable在磁碟的備份
- 類FileLock,為檔案上鎖
- WriteStringToFile、ReadFileToString、Log三個全域性函式,封裝了上述介面
下面來看看env_posix.cc中為我們寫好的預設實現
順序讀:
這就是LevelDB從磁碟順序讀取檔案的介面了,用的是C的流檔案操作和FILE結構體。需要注意的是Read介面讀取檔案時不會鎖住檔案流,因此外部的併發訪問需要自行提供併發控制。class PosixSequentialFile: public SequentialFile { private: std::string filename_; FILE* file_; public: PosixSequentialFile(const std::string& fname, FILE* f) : filename_(fname), file_(f) { } virtual ~PosixSequentialFile() { fclose(file_); } // 從檔案中讀取n個位元組存放到 "scratch[0..n-1]", 然後將"scratch[0..n-1]"轉化為Slice型別並存放到*result中 // 如果正確讀取,則返回OK status,否則返回non-OK status virtual Status Read(size_t n, Slice* result, char* scratch) { Status s; #ifdef BSD // fread_unlocked doesn't exist on FreeBSD size_t r = fread(scratch, 1, n, file_); #else // size_t fread_unlocked(void *ptr, size_t size, size_t n,FILE *stream); // ptr:用於接收資料的記憶體地址 // size:要讀的每個資料項的位元組數,單位是位元組 // n:要讀n個數據項,每個資料項size個位元組 // stream:輸入流 // 返回值:返回實際讀取的資料大小 // 因為函式名帶了"_unlocked"字尾,所以它不是執行緒安全的 size_t r = fread_unlocked(scratch, 1, n, file_); #endif // Slice的第二個引數要用實際讀到的資料大小,因為讀到檔案尾部,剩下的位元組數可能小於n *result = Slice(scratch, r); if (r < n) { if (feof(file_)) { // We leave status as ok if we hit the end of the file // 如果r<n,且feof(file_)非零,說明到了檔案結尾,什麼都不用做,函式結束後會返回OK Status } else { // A partial read with an error: return a non-ok status // 否則返回錯誤資訊 s = Status::IOError(filename_, strerror(errno)); } } return s; } // 跳過n位元組的內容,這並不比讀取n位元組的內容慢,而且會更快。 // 如果到達了檔案尾部,則會停留在檔案尾部,並返回OK Status。 // 否則,返回錯誤資訊 virtual Status Skip(uint64_t n) { // int fseek(FILE *stream, long offset, int origin); // stream:檔案指標 // offset:偏移量,整數表示正向偏移,負數表示負向偏移 // origin:設定從檔案的哪裡開始偏移, 可能取值為:SEEK_CUR、 SEEK_END 或 SEEK_SET // SEEK_SET: 檔案開頭 // SEEK_CUR: 當前位置 // SEEK_END: 檔案結尾 // 其中SEEK_SET, SEEK_CUR和SEEK_END和依次為0,1和2. // 舉例: // fseek(fp, 100L, 0); 把fp指標移動到離檔案開頭100位元組處; // fseek(fp, 100L, 1); 把fp指標移動到離檔案當前位置100位元組處; // fseek(fp, 100L, 2); 把fp指標退回到離檔案結尾100位元組處。 // 返回值:成功返回0,失敗返回非0 if (fseek(file_, n, SEEK_CUR)) { return Status::IOError(filename_, strerror(errno)); } return Status::OK(); } };
隨機讀:
class PosixRandomAccessFile: public RandomAccessFile { private: std::string filename_; int fd_; mutable boost::mutex mu_; public: PosixRandomAccessFile(const std::string& fname, int fd) : filename_(fname), fd_(fd) { } virtual ~PosixRandomAccessFile() { close(fd_); } // 這裡與順序讀的同名函式相比,多了一個引數offset,offset用來指定 // 讀取位置距離檔案起始位置的偏移量,這樣就可以實現隨機讀了。 virtual Status Read(uint64_t offset, size_t n, Slice* result, char* scratch) const { Status s; #ifdef WIN32 // no pread on Windows so we emulate it with a mutex boost::unique_lock<boost::mutex> lock(mu_); if (::_lseeki64(fd_, offset, SEEK_SET) == -1L) { return Status::IOError(filename_, strerror(errno)); } // int _read(int _FileHandle, void * _DstBuf, unsigned int _MaxCharCount) // _FileHandle:檔案描述符 // _DstBuf:儲存讀取資料的緩衝區 // _MaxCharCount:讀取的位元組數 // 返回值:成功返回讀取的位元組數,出錯返回-1並設定errno。 int r = ::_read(fd_, scratch, n); *result = Slice(scratch, (r < 0) ? 0 : r); lock.unlock(); #else // 在非windows系統上使用pread進行隨機讀,為何此時不用鎖呢?詳見下文分析 ssize_t r = pread(fd_, scratch, n, static_cast<off_t>(offset)); *result = Slice(scratch, (r < 0) ? 0 : r); #endif if (r < 0) { // An error: return a non-ok status s = Status::IOError(filename_, strerror(errno)); } return s; } };
可以看到的是,PosixRandomAccessFile 在非windows系統上使用了 pread 來實現原子的定位加訪問功能。常規的隨機訪問檔案的過程可以分為兩步,fseek (seek) 定位到訪問點,呼叫 fread (read) 來從特定位置開始訪問 FILE* (fd)。然而,這兩個操作組合在一起並不是原子的,即 fseek 和 fread 之間可能會插入其他執行緒的檔案操作。相比之下 pread 由系統來保證實現原子的定位和讀取組合功能。需要注意的是,pread 操作不會更新檔案指標。
需要注意的是,在隨機讀和順序讀中,分別用fd和FILE *來表示一個檔案。檔案描述符(file descriptor)是系統層的概念, fd 對應於系統開啟檔案表裡面的一個檔案;FILE* 是應用層的概念,其包含了應用層操作檔案的資料結構。
順序寫:
class BoostFile : public WritableFile {
public:
explicit BoostFile(std::string path) : path_(path), written_(0) {
Open();
}
virtual ~BoostFile() {
Close();
}
private:
void Open() {
// we truncate the file as implemented in env_posix
// trunc:先將檔案中原有的內容清空
// out:為輸出(寫)而開啟檔案
// binary:以二進位制方式開啟檔案
file_.open(path_.generic_string().c_str(),
std::ios_base::trunc | std::ios_base::out | std::ios_base::binary);
written_ = 0;
}
public:
virtual Status Append(const Slice& data) {
Status result;
file_.write(data.data(), data.size());
if (!file_.good()) {
result = Status::IOError(
path_.generic_string() + " Append", "cannot write");
}
return result;
}
virtual Status Close() {
Status result;
try {
if (file_.is_open()) {
Sync();
// 關閉流時,緩衝區中的資料會自動寫入到檔案
// 上面呼叫Sync()強制重新整理,是為了確保資料寫入,防止資料丟失
file_.close();
}
} catch (const std::exception & e) {
result = Status::IOError(path_.generic_string() + " close", e.what());
}
return result;
}
virtual Status Flush() {
file_.flush();
return Status::OK();
}
// 手動重新整理(清空輸出緩衝區,並把緩衝區內容同步到檔案)
virtual Status Sync() {
Status result;
try {
Flush();
} catch (const std::exception & e) {
result = Status::IOError(path_.string() + " sync", e.what());
}
return result;
}
private:
boost::filesystem::path path_;
boost::uint64_t written_;
std::ofstream file_;
};檔案鎖:
class BoostFileLock : public FileLock {
public:
boost::interprocess::file_lock fl_;
};virtual Status LockFile(const std::string& fname, FileLock** lock) {
*lock = NULL;
Status result;
try {
if (!boost::filesystem::exists(fname)) {
std::ofstream of(fname, std::ios_base::trunc | std::ios_base::out);
}
assert(boost::filesystem::exists(fname));
boost::interprocess::file_lock fl(fname.c_str());
BoostFileLock * my_lock = new BoostFileLock();
my_lock->fl_ = std::move(fl);
if (my_lock->fl_.try_lock())
*lock = my_lock;
else
result = Status::IOError("acquiring lock " + fname + " failed");
} catch (const std::exception & e) {
result = Status::IOError("lock " + fname, e.what());
}
return result;
} virtual Status UnlockFile(FileLock* lock) {
Status result;
try {
BoostFileLock * my_lock = static_cast<BoostFileLock *>(lock);
my_lock->fl_.unlock();
delete my_lock;
} catch (const std::exception & e) {
result = Status::IOError("unlock", e.what());
}
return result;
}這幾個方法都非常簡單,比較晦澀的是這句:my_lock->std::move(f1),從函式名來看,是要移動f1。其實std::move是C++11標準庫在<utility>中提供的一個有用的函式,這個函式的名字具有迷惑性,因為實際上std::move並不能移動任何東西,它唯一的功能是將一個左值強制轉化為右值引用,繼而我們可以通過右值引用使用該值,以用於移動語義。從實現上講,std::move基本等同於一個型別轉換:static_cast<T&&>(lvalue);值得一提的是,被轉化的左值,其生命期並沒有隨著左右值的轉化而改變。如果讀者期望std::move轉化的左值變數lvalue能立即被析構,那麼肯定會失望了。左值與右值這兩概念是從c中傳承而來的,在c中,左值指的是既能夠出現在等號左邊也能出現在等號右邊的變數(或表示式),右值指的則是隻能出現在等號右邊的變數(或表示式)。
計劃任務:
PosixEnv還有一個很重要的功能,計劃任務,也就是後臺的compaction執行緒。compaction就是壓縮合並的意思,在LevelDB原始碼分析之六:skiplist(2)中也有提到。對於LevelDB來說,寫入記錄操作很簡單,刪除記錄僅僅寫入一個刪除標記就算完事,但是讀取記錄比較複雜,需要在記憶體以及各個層級檔案中依照新鮮程度依次查詢,代價很高。為了加快讀取速度,LevelDB採取了compaction的方式來對已有的記錄進行整理壓縮,通過這種方式,來刪除掉一些不再有效的KV資料,減小資料規模,減少檔案數量等。
PosixEnv中定義了一個任務佇列:
struct BGItem { void* arg; void (*function)(void*); };
//用的是deque雙端佇列作為底層的資料結構
typedef std::deque<BGItem> BGQueue;
BGQueue queue_;後臺程序一直執行queue_中的任務,由於queue_是動態的,自然需要考慮queue_空了怎麼辦,LevelDB採用的是條件變數boost::condition_variable bgsignal_,佇列空了就進入等待,直至有新的任務加入進來。而條件變數一般是要和boost::mutex mu_搭配使用,防止某些邏輯錯誤。
// BGThread函式的包裝,裡面呼叫的就是BGThread函式
static void* BGThreadWrapper(void* arg) {
reinterpret_cast<PosixEnv*>(arg)->BGThread();
return NULL;
}void PosixEnv::Schedule(void (*function)(void*), void* arg) {
boost::unique_lock<boost::mutex> lock(mu_);
// Start background thread if necessary
if (!bgthread_) {
bgthread_.reset(
new boost::thread(boost::bind(&PosixEnv::BGThreadWrapper, this)));
}
// Add to priority queue
// 將任務壓進佇列中
queue_.push_back(BGItem());
queue_.back().function = function;
queue_.back().arg = arg;
lock.unlock();
bgsignal_.notify_one();
}void PosixEnv::BGThread() {
while (true) {
// 加鎖,防止併發衝突
boost::unique_lock<boost::mutex> lock(mu_);
// 如果佇列為空,等待,直到收到通知(notification)
while (queue_.empty()) {
bgsignal_.wait(lock);
}
// 從佇列頭取出任務的函式及其引數
void (*function)(void*) = queue_.front().function;
void* arg = queue_.front().arg;
queue_.pop_front();
lock.unlock();
// 呼叫函式
(*function)(arg);
}
}EnvWrapper:
在levelDB中還實現了一個EnvWrapper類,該類繼承自Env,且只有一個成員函式Env* target_,該類的所有變數都呼叫Env類相應的成員變數,我們知道,Env是一個抽象類,是不能定義Env 型別的物件的。我們傳給EnvWrapper 的建構函式的型別是PosixEnv,所以,最後呼叫的都是PosixEnv類的成員變數,你可能已經猜到了,這就是設計模式中的代理模式,EnvWrapper只是進行了簡單的封裝,它的代理了Env的子類PosixEnv。
EnvWrapper和Env與PosixEnv的關係如下:
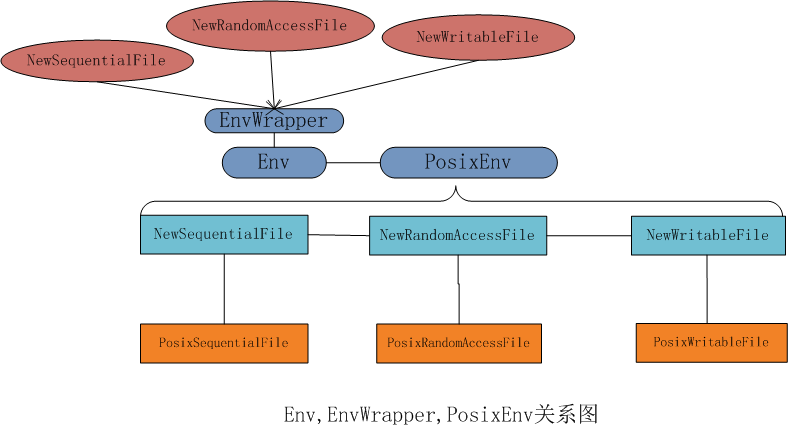
由於篇幅限制,Env中的Logger類就放在後面分析了,參考:LevelDB原始碼分析之十:LOG檔案,從env給我的收穫就是:
- 利用虛基類的特性提供了預設的實現,也開放了使用者自定義操作的許可權
- 面向物件程式設計正規化的學習,把一切操作定義成類
- 檔案的加鎖解鎖,執行緒的同步
- C的檔案流操作,對檔名的字元提取操作,建立、刪除檔案和路徑,這些都可以直接用到將來自己的專案中
相關推薦
LevelDB原始碼分析之九:env
考慮到移植以及靈活性,LevelDB將系統相關的處理(檔案/程序/時間)抽象成Evn,使用者可以自己實現相應的介面,作為option的一部分傳入,預設使用自帶的實現。 env.h中聲明瞭: 虛基類env,在env_posix.cc中,派生類PosixEnv繼承自env
LevelDB原始碼分析之六:skiplist(2)
閱讀本文可參考: LevelDB中的skiplist實現方式基本上和中的實現方式類似。它向外暴露介面非常簡單,如下: public: // Create a new SkipList object that will use "cmp" for compar
Spark原始碼分析之三:Stage劃分
Stage劃分的大體流程如下圖所示: 前面提到,對於JobSubmitted事件,我們通過呼叫DAGScheduler的handleJobSubmitted()方法來處理。那麼我們先來看下程式碼: // 處理Job提交的函式 pri
Yarn原始碼分析之MRAppMaster:作業執行方式Local、Uber、Non-Uber
基於作業大小因素,MRAppMaster提供了三種作業執行方式:本地Local模式、Uber模式、Non-Uber模式。其中, 1、本地Local模式:通常用於除錯; 2、Uber模式:為降低小作業延遲而設計的一種模式,所有任務,不
twemproxy原始碼分析之四:處理流程
很讚的註釋: * nc_connection.[ch] * Connection (struct conn) * + + + * |
ABP原始碼分析十九:Auditing
審計跟蹤(也叫審計日誌)是與安全相關的按照時間順序的記錄,它們提供了活動序列的文件證據,這些活動序列可以在任何時間影響一個特定的操作。 AuditInfo:定義如下圖中需要被Audit的資訊。 AuditedAttribute: 用於標識一個方法或一個類的所有方法都需要啟用Auditing功能
R語言與資料分析之九:時間內序列--HoltWinters指數平滑法
今天繼續就指數平滑法中最複雜的一種時間序列:有增長或者降低趨勢並且存在季節性波動的時間序列的預測演算法即Holt-Winters和大家分享。這種序列可以被分解為水平趨勢部分、季節波動部分,因此這兩個因素應該在演算法中有對應的引數來控制。 Holt-Winters演算法中提供
leveldb原始碼分析之sst檔案格式
轉載:http://luodw.cc/2015/10/21/leveldb-09/之前leveldb分析,講解了leveldb兩大元件memtable和log檔案。這篇文章主要分析leveldb將記憶體資料寫入磁碟檔案,這些磁碟檔案的格式,下一篇文章再分析原始碼。leveld
Dubbo原始碼分析之四:服務的呼叫
在呼叫服務之前,先得獲得服務的引用。 ReferenceBean 就是服務的引用。它實現了一個FactoryBean介面,在我們需要一個服務時,FactoryBean介面的getObject() 方法會被呼叫。 public Object getObje
libjingle原始碼分析之三:P2P
摘要 本文主要介紹了libjingle庫中的P2P模組。 概述 在libjingle中,P2P模組並非一個完全獨立的模組,它的實現依賴於Jingle協議,需要通過libjingle中的其它模組獲取必要的資訊和支援。P2P模組的內部結構及與
另闢蹊徑Ceph原始碼分析之3:解析ceph pg_temp(ceph 臨時pg)
什麼是pg_temp 假設一個PG通過crush演算法對映到的三個osd是[0,1,2],此時,如果osd0出現故障,導致crush演算法重新分配該PG的三個osd是[3,1,2],此時,osd3為該PG的主osd,但是osd3為新加入的osd,並不
netty原始碼分析 之九 handler
學習完前面的channel,回頭來學習handler 會感覺到很簡單的. handler 這個包裡面的類實現 ChannelHandlerAdapter codec我們最後來看,先看其他 logging LoggingHandler 為log的輸出類, 定義
Spring Cloud原始碼分析之Eureka篇第六章:服務註冊
在文章《Spring Cloud原始碼分析之Eureka篇第四章:服務註冊是如何發起的 》的分析中,我們知道了作為Eureka Client的應用啟動時,在com.netflix.discovery.DiscoveryClient類的initScheduledT
Spring Cloud原始碼分析之Eureka篇第八章:服務註冊名稱的來歷
關於服務註冊名稱 服務註冊名稱,是指Eureka client註冊到Eureka server時,用於標記自己身份的標誌,舉例說明,以下是個簡單的Eureka client配置: server: port: 8082 spring: applicatio
【搞定Java併發程式設計】第17篇:佇列同步器AQS原始碼分析之共享模式
AQS系列文章: 1、佇列同步器AQS原始碼分析之概要分析 2、佇列同步器AQS原始碼分析之獨佔模式 3、佇列同步器AQS原始碼分析之共享模式 4、佇列同步器AQS原始碼分析之Condition介面、等待佇列 通過上一篇文章的的分析,我們知道獨佔模式獲取同步狀態(或者說獲取鎖
【搞定Java併發程式設計】第16篇:佇列同步器AQS原始碼分析之獨佔模式
AQS系列文章: 1、佇列同步器AQS原始碼分析之概要分析 2、佇列同步器AQS原始碼分析之獨佔模式 3、佇列同步器AQS原始碼分析之共享模式 4、佇列同步器AQS原始碼分析之Condition介面、等待佇列 本文主要講解佇列同步器AQS的獨佔模式:主要分為獨佔式同步狀態獲取
【搞定Java併發程式設計】第15篇:佇列同步器AQS原始碼分析之概要分析
AQS系列文章: 1、佇列同步器AQS原始碼分析之概要分析 2、佇列同步器AQS原始碼分析之獨佔模式 3、佇列同步器AQS原始碼分析之共享模式 4、佇列同步器AQS原始碼分析之Condition介面、等待佇列 先推薦兩篇不錯的博文: 1、一行一行原始碼分析清楚Abstract
【搞定Java併發程式設計】第18篇:佇列同步器AQS原始碼分析之Condition介面、等待佇列
AQS系列文章: 1、佇列同步器AQS原始碼分析之概要分析 2、佇列同步器AQS原始碼分析之獨佔模式 3、佇列同步器AQS原始碼分析之共享模式 4、佇列同步器AQS原始碼分析之Condition介面、等待佇列 通過前面三篇關於AQS文章的學習,我們深入瞭解了AbstractQ
以太坊的儲存層技術分析之二:以太坊和LevelDB的介面
LevelDB使用者介面非常簡單,主要就是Put(k,v),Get(k),Delete(k)。以太坊封裝了LevelDB介面,見如下類詳細程式碼: ---------------------------------------------------------------
elasticsearch原始碼分析之索引操作(九)
上節介紹了es的node啟動如何建立叢集服務的過程,這節在其基礎之上介紹es索引的基本操作功能(create、exist、delete),用來進一步細化es叢集是如果工作的。 客戶端部分的操作就不予介紹了,詳細可以參照elasticsearch原始碼分析之客戶