
Tensorflow 原始碼分析- 從GPU OOM開始說Tensorflow的BFC記憶體管理
前言
在平臺上跑GPU訓練,結果CUDA OOM了,錯誤提示
E Internal: failed initializing StreamExecutor for CUDA device ordinal 0: Internal: failed call to cuDevicePrimary
CtxRetain: CUDA_ERROR_OUT_OF_MEMORY; total memory reported: 11711807488對會話沒有進行任何GPU相關設定,tensorflow給出建議,可以用引數控制GPU的記憶體分配
# add gpu growth flags tf_config.gpu_options.allow_growth = True tf_config.gpu_options.per_process_gpu_memory_fraction = 0.1
per_process_gpu_memory_fraction 引數
- per_process_gpu_memory_fraction 引數,這是一個控制GPU單個process的記憶體因子,這是一個筏值,通過筏值來決定獲取GPU的記憶體比,從而控制留給系統的GPU的記憶體,如果不設定,在有效記憶體足夠的情況下,tensorflow只預留給系統225M當有效記憶體小於2G的時候,而當有效記憶體大於2G的時候預留筏值0.05的有效記憶體且至少300M的記憶體,這是一種貪婪式的佔有記憶體。設定因子可以有效控制你需要的記憶體量。
int64 allocated_memory; double config_memory_fraction = options.config.gpu_options().per_process_gpu_memory_fraction(); if (config_memory_fraction == 0) { allocated_memory = available_memory; const int64 min_system_memory = MinSystemMemory(available_memory); if (min_system_memory < allocated_memory) { allocated_memory -= min_system_memory; } } else { allocated_memory = total_memory * config_memory_fraction; }
- 如果你跑在一個已經記憶體使用比較多的平臺裡,每個GPU的剩餘記憶體並不一定一樣,設定因子是基於所有process記憶體的,單個因子無法控制每個process的記憶體分配,會導致由於單個process的記憶體不夠而導致失敗。
allow_growth 引數
看到這引數也許會很奇怪,allow_growth字面意思是允許增長,也就是允許後期繼續分配記憶體?實際上在tensorflow啟動的時候,並不會真實的去申請記憶體,初始引數的生成只是為了管控後期真實允許使用,申請記憶體的大小。
在tensorflow上有一層虛擬的記憶體管理BFC
BFC記憶體分配
這是一個虛擬的記憶體分配器,實現類似Doug Lea簡單版本malloc(dlmalloc),通過合併進行記憶體碎片整理,實現'best-fit with coalescing'的演算法,要求所有的分配記憶體都必須呼叫該介面。
1 Chunk結構體
1.1 結構體
這是tensorflow的最小記憶體單位,由數倍256bytes(kMinAllocationSize)的連續記憶體塊組成,tensorflow的記憶體管理是基於chunk的管理。
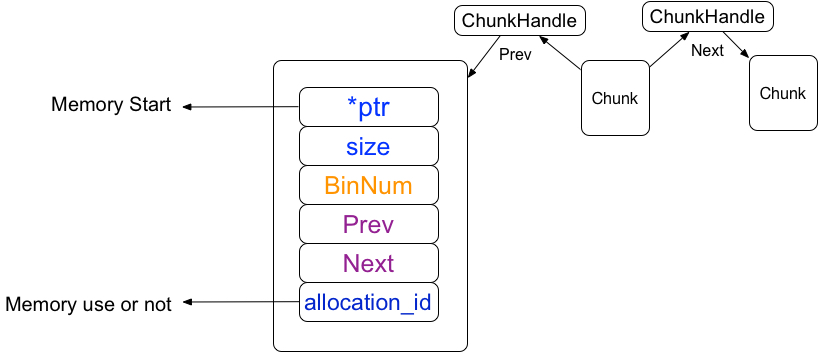
1.1.1 chunkhandle
chunkhandle是chunk陣列向量的索引,在tensorflow儲存著所有chunk的陣列向量,而陣列向量的下標就是chunkhandle
// If not kInvalidChunkHandle, the memory referred to by 'prev' is directly
// preceding the memory used by this chunk. E.g., It should start
// at 'ptr - prev->size'
ChunkHandle prev = kInvalidChunkHandle;
// If not kInvalidChunkHandle, the memory referred to by 'next' is directly
// following the memory used by this chunk. E.g., It should be at
// 'ptr + size'
ChunkHandle next = kInvalidChunkHandle;在Chunk結構體中有兩個前後chunkhandle(所有chunk陣列的索引),chunkhandle指向前後分別是相鄰的連續記憶體塊
1.1.2 ptr指標
ptr是一個記憶體指標,指向的是記憶體的啟始位置,因為chunk指向的是連續記憶體,所以只記錄它的大小
1.2 chunk的申請
Tensorflow 會儲存一個所有chunk的陣列向量,為了避免頻繁的申請和釋放chunk,被釋放的chunk會被重用,為了快速的查詢已經釋放的chunk,tensorflow又構建了已經釋放的chunk的連結串列結構,free_chunks_list_指向連結串列的頭
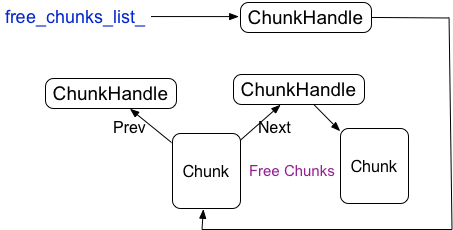
1.3 chunk的刪除
chunk是重用的,chunk的刪除需要抹去chunk裡的特性,比如ptr,當然不是釋放ptr指向的記憶體,而是將Region裡所對應該地址的chunkhandle的指向設定無效,同時將該chunk新增到已經釋放的chunk的連結串列中的頭部,free_chunks_list_指向剛釋放的chunk
2 Region
Region是一塊已經分配的連續的記憶體塊,一個region可以被拆分為多個chunk,一個chunk指向的是多個連續的256byte的記憶體塊
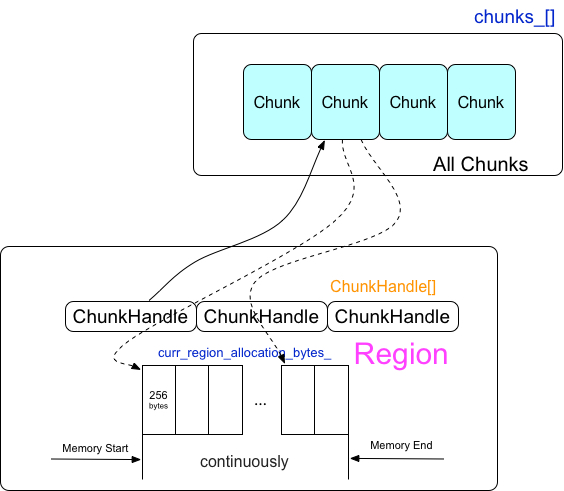
2.1 Region 的申請
在真正需要使用記憶體的時候才申請Region
size_t bytes = std::min(curr_region_allocation_bytes_, available_bytes);
void* mem_addr = suballocator_->Alloc(32, bytes);在上面程式碼中我們可以看到每次申請Region的記憶體由下面幾個引數控制:
curr_region_allocation_bytes引數
if (allow_growth) {
// 1MiB smallest initial allocation, unless total memory available
// is less.
curr_region_allocation_bytes_ =
RoundedBytes(std::min(total_memory, size_t{1048576}));
} else {
curr_region_allocation_bytes_ = RoundedBytes(total_memory);
}這裡的allow_growth引數就是在前面的
tf_config.gpu_options.allow_growth = True當allow_growth關閉的時候,curr_region_allocation_bytes_就是預設的剩餘記憶體大小,也就是隻有一個Region
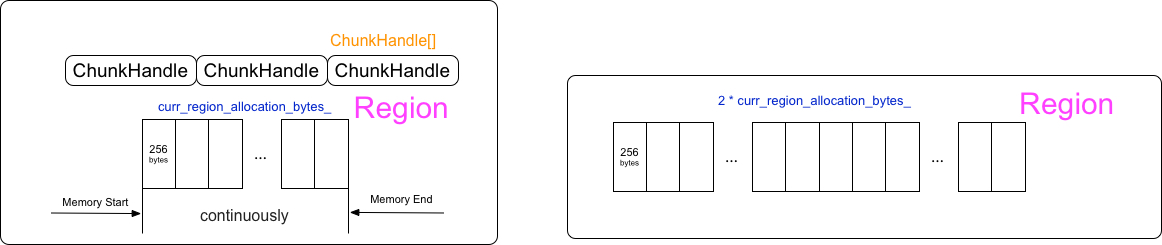
當allow_growth開啟的時候,curr_region_allocation_bytes_的值是最小為1M的多個Region,curr_region_allocation_bytes_預設以2倍的速度增長,也就是每次申請Region的記憶體是連續最小以2倍速度增長的。
如果實際需要申請的記憶體大於curr_region_allocation_bytes_的時候,以2倍的curr_region_allocation_bytes_速度增長直到滿足需要的記憶體。
bool increased_allocation = false;
while (rounded_bytes > curr_region_allocation_bytes_) {
curr_region_allocation_bytes_ *= 2;
increased_allocation = true;
}
Available_bytes引數
available_bytes 指的是剩餘的可被分配的記憶體,在初始化的時候Tensorflow會獲取GPU的有效記憶體,每次申請的記憶體會從剩餘記憶體中減去,也就是在整個運算過程中GPU的剩餘記憶體只會在程式開始的時候獲取一次,如果程式是在執行在GPU的平臺上,剩餘記憶體會不停的變化,有效的記憶體在程式開始執行的時候獲取(並沒有真的去申請),那麼在計算過程中記憶體申請很有可能出現OOM。
2.2 Region的ChunkHandle
每個Region會被以256bytes大小分割成多個chunkhandle的陣列,chunkhandle指向的就是前面章節中討論的chunk向量陣列的位置。
2.3 Region陣列
每一次的申請連續的記憶體都會生成一個Region,多個Region組成了Region向量陣列
private:
std::vector<AllocationRegion> regions_;如何定位chunk是屬於哪個Region呢?每個Region會記錄起始地址和結束地址,而chunk中會儲存chunk的起始地址,只要比較chunk的起始地址和region的地址範圍,就能確定所屬於的Region
3. Bin
在前面章節中討論了Region, Chunk,但當申請新的記憶體的時候,如何更快高效的查詢匹配的空閒chunk,這是非常重要的。查詢每個Region裡的空閒chunk,顯然是非常低效率的,tensorflow基於chunk上構建了一個全域性的bin,每個bin裡管理的是一定範圍的記憶體大小的chunk(記憶體大小範圍 (2^bin_num)*256 到 (2^(bin_num+1))*256-1的,bin_num代表的是bin的序列號)每個chunk是以256bytes數倍大小的記憶體塊,bin管理的是空閒的chunk塊。

每個Bin裡會儲存著一個空閒的free的chunk的set
typedef std::set<ChunkHandle, ChunkComparator> FreeChunkSet;
// List of free chunks within the bin, sorted by chunk size.
// Chunk * not owned.
FreeChunkSet free_chunks;- 應用程式先申請記憶體
- 計算從而確定記憶體大小所屬於的Bin
- 遍歷Bin裡面的空閒的Chunk Set,如果找不到繼續查詢更大的Bin,直到找到空閒的記憶體
- 如果依然找不到,那麼就需要真實的向驅動申請記憶體,申請curr_region_allocation_bytes_大小的記憶體塊為一個Region,同時也是一個大的chunk塊,並將這個chunk塊作為空閒塊插入回所對應的bin中空閒chunk set,然後繼續查詢。
- 如果找到,那麼需要判斷一下空閒的chunk記憶體塊是否2倍於所需要的記憶體
- 為了避免記憶體的浪費,大的空閒chunk塊會倍拆分成2個chunk塊,小的chunk塊給程式使用,而剩餘大的chunk塊重新插入回所對應的Bin的空閒chunk set
4. Chunk 的合併和拆分
為了更有效的利用記憶體,對一個較大的chunk記憶體塊進行chunk的拆分,該拆分策略前面章節裡已經介紹過,而在chunk進行釋放的時候,tensorflow會嘗試對chunk進行合併,chunk合併的策略:地址相鄰的記憶體塊才可以合併
還記得chunk的Prev,Next麼?
BFCAllocator::ChunkHandle h_neighbor = c->next;
new_chunk->prev = h;
new_chunk->next = h_neighbor;
c->next = h_new_chunk;在chunk拆分的時候,就是相鄰的chunk塊,在split一個大的Chunk成兩個chunk塊的時候, 新的chunk塊prev會指向另一個chunk塊, next指向原來大的chunk塊的鄰居,同時大chunk塊的鄰居prev指向新的chunk塊。
在釋放chunk的時候,會檢查prev和next,如果prev,next指向的chunk沒有被使用,那麼就會嘗試合併。
相關推薦
Tensorflow 原始碼分析- 從GPU OOM開始說Tensorflow的BFC記憶體管理
前言在平臺上跑GPU訓練,結果CUDA OOM了,錯誤提示E Internal: failed initializing StreamExecutor for CUDA device ordinal 0: Internal: failed call to cuDeviceP
tensorflow原始碼分析(1)
variable類: 通過例項化Variable類可以新增一個變數到graph,在使用變數之前必須對變數顯示的初始化,初始化可以使用assign為變數賦值也可以通過變數本身的initializer方法。 &nb
Tensorflow 原始碼分析-會話與執行緒池之間的關係
1. Tensorflow 的sessionFactory建立新的會話,tensorflow使用了多工廠模式,在不同的場景下使用不同的工廠, 使用什麼工廠模式由傳遞進來的SessionOptions來決定。1.1 註冊工廠Tensorflow 提供了可以註冊多會話工廠的模式,
Vue學習之原始碼分析--從template到DOM(Vue.js原始碼角度看內部執行機制)(九)
從new一個Vue物件開始 let vm = new Vue({ el: '#app', /*some options*/ }); 很多同學好奇,在new一個Vue物件的時候,內部究竟發生了什麼? 究竟Vue.js是如何將data中的資
tensorflow原始碼分析(一)
轉自昂鈦客AI已關注工程一:tensorflow/tensorflow1、 整體工程的系統架構下圖是TF的系統架構,從底向上分為裝置管理和通訊層、資料操作層、圖計算層、API介面層、應用層。其中裝置管理和通訊層、資料操作層、圖計算層是TF的核心層。第一層是底層裝置通訊層,負責
Android call setting 原始碼分析 從頂層到底層(上)
... byte[] data; data = rr.mp.marshall(); rr.mp.recycle();
【Deep Learning】YOLO_v1 的 TensorFlow 原始碼分析
本文是對上一篇文章的繼續補充,在這裡首先說明,這個 TensorFlow 版本的原始碼 來自於 hizhangp/yolo_tensorflow,經過部分細節的調整執行在我的裝置上,我使用的環境是Win10+GPU+OpenCV 3.3 + Python3.
SpringMVC之請求處理原始碼分析從service到doDispatch(一)
說明:本文所用的SpringMVC版本為4.3.4.RELEASE,應用伺服器為TomCat8.0.33。 前面幾篇文章我們簡單的分析了一下SpringMVC初始化的過程,接下來的這幾篇文章我們從原始碼的角度分析一下SpringMVC對請求的處理過程。這一篇文章我們來分析請
8.原始碼分析---從設計模式中看SOFARPC中的EventBus?
我們在前面分析客戶端引用的時候會看到如下這段程式碼: // 產生開始呼叫事件 if (EventBus.isEnable(ClientStartInvokeEvent.class)) { EventBus.post(new ClientStartInvokeEvent(request)); } 這裡用
ReentrantLock 原始碼分析從入門到入土
回答一個問題 在開始本篇文章的內容講述前,先來回答我一個問題,為什麼 JDK 提供一個 synchronized 關鍵字之後還要提供一個 Lock 鎖,這不是多此一舉嗎?難道 JDK 設計人員都是沙雕嗎? 我聽過一句話非常的經典,也是我認為是每個人都應該瞭解的一句話:你以為的並不是你以為的。明白什麼意思麼?不
[原始碼分析] 從原始碼入手看 Flink Watermark 之傳播過程
[原始碼分析] 從原始碼入手看 Flink Watermark 之傳播過程 0x00 摘要 本文將通過原始碼分析,帶領大家熟悉Flink Watermark 之傳播過程,順便也可以對Flink整體邏輯有一個大致把握。 0x01 總述 從靜態角度講,watermarks是實現流式計算的核心概念;從動態角度說,w
[原始碼分析] 從例項和原始碼入手看 Flink 之廣播 Broadcast
# [原始碼分析] 從例項和原始碼入手看 Flink 之廣播 Broadcast ## 0x00 摘要 本文將通過原始碼分析和例項講解,帶領大家熟悉Flink的廣播變數機制。 ## 0x01 業務需求 ### 1. 場景需求 對黑名單中的IP進行檢測過濾。IP黑名單的內容會隨時增減,因此是可以隨時動
[原始碼分析] 從FlatMap用法到Flink的內部實現
# [原始碼分析] 從FlatMap用法到Flink的內部實現 ## 0x00 摘要 本文將從FlatMap概念和如何使用開始入手,深入到Flink是如何實現FlatMap。希望能讓大家對這個概念有更深入的理解。 ## 0x01 Map vs FlatMap 首先我們先從概念入手。 自從*響應式程式
TensorFlow訓練模型,指定GPU訓練,設定視訊記憶體,檢視gpu佔用
1 linux檢視當前伺服器GPU佔用情況:nvidia-smi 週期性輸出GPU使用情況: (如設定每3s顯示一次GPU使用情況) watch -n 3 nvidia-smi 效果如下: 2 指定GPU訓練,使用CUDA_VISIBLE_DEVICES來指定
【React Native】原始碼分析之Native UI的封裝和管理
ReactNative作為使用React開發Native應用的新框架,隨著時間的增加,無論是社群還是個人對她的興趣與日遞增。此文目的是希望和大家一起欣賞一下ReactNative的部分原始碼。閱讀原始碼好處多多,讓攻城獅更溜的開發ReactNative應
netty原始碼解解析(4.0)-23 ByteBuf記憶體管理:分配和釋放
ByteBuf記憶體分配和釋放由具體實現負責,抽象型別只定義的記憶體分配和釋放的時機。 記憶體分配分兩個階段: 第一階段,初始化時分配記憶體。第二階段: 記憶體不夠用時分配新的記憶體。ByteBuf抽象層沒有定義第一階段的行為,但定義了第二階段的方法: public abstract
從0開始的jieba分詞原始碼分析_1_從cut開始
從一個函式入口逐步分析分詞的整個過程,最後對關鍵函式做了簡化實現,附在最後供大家參考 分析 尋根 import jieba jieba.cut("sentence") 查詢cut的引用: dt =
TensorFlow 從入門到精通(二):MNIST 例程原始碼分析
按照上節步驟, TensorFlow 預設安裝在 /usr/lib/python/site-packages/tensorflow/ (也有可能是 /usr/local/lib……)下,檢視目錄結構: # tree -d -L 3 /usr/lib/pyt
【spring】原始碼分析 一 從ContextLoaderListener開始·
原始碼環境 : idea + spring 4.3.4 +tomcat7 + gradle附 : 基於 java 註解的 配置元資料 的 web.xml 配置做參考(spring 3.0 後支援)<?xml version="1.0" encoding="UTF-8"
原始碼分析系列 | 從零開始寫MVC框架
1. 前言 前段時間在網上無意中上參與了一節騰訊課堂的公開課,裡面講到了一些分析思路,感覺挺有意思,也學習到了別人的一些講課技巧,正好自己也打算對過往知識網路做個整理回顧,計劃後面開展一系列原始碼分析教程,本章先從一個入門簡單的手寫MVC框架入門